
Input & Output
《Java Core》ed.11 学习笔记
最重要的事情:输入和输出都是相对于CPU来说的,输入是把数据输入给CPU,输出是CPU把数据输出到别的地方
Input/Output Streams
JavaAPI中,从input stream对象中读取字节序列,向output stream对象中写入字节序列。这些源和目的地可以是文件、也可以是网络连接,甚至是一块内存。抽象类InputStream和OutputStream形成了输入输出相关类的基础
面向字节的输入输出流对于处理用Unicode存储的数据不方便,因此,另外一个继承自Reader和Writer类的继承层次是用来处理Unicode字符的,读写操作都是基于两字节的char类型(码元)
读写字节
abstract int read()
这个方法读1个字节然后返回一个被读的字节,如果到了输入源的尾部,则会返回-1。这个类的实现类的设计者提供了很多有用的功能(FileInputStream/System.in)
InputStream也有非抽象方法(读取一个字节数组/跳过一定数量字节)。Java9之后,多了一个从流中一次获取所有字节数据的方法readAllBytes();
这些方法调用了read()方法,所以子类必须要实现read()方法
OutputStream也定义了抽象方法abstract void write(int b),向输出目的地写入1个字节数据,也有直接写入一个字节数组数据的API。transferTo方法(Java 9)将输入流中所有数据转移到输出流
无论是read还是write方法,在读完和写完之前都是阻塞(block)状态的,这意味着,如果输入流无法立刻被访问(网络连接问题),当前线程会阻塞,其它线程在等待输入流重新可用之前就有机会做其它事情
available方法可以检查现在可以被用来读取的字节数
int bytesAvailable = in.available();
if (bytesAvailable > 0)
{
var data = new byte[bytesAvailable];
in.read(data);
}
上面的代码不会出现阻塞
在读或写结束的时候,通过close方法来关闭流,在关闭输出流时,所有缓冲区(等待后续数据组成更大的数据包)的字节会被刷新掉(输入到目的地)。如果一直不关闭流,有可能一部分数据无法输出,也可以手动flush
Java9方法 int readNBytes(byte[] b, int off, int len),直到数组读满前都会阻塞进程
所有的流
Java有超过60种不同的输入输出流类型
DataInputStream和DataOutputStream可以以二进制的形式读写所有基本数据类型。ZipInputStream和ZipOutputStream可以读写ZIP压缩格式数据
Writer和Reader的继承层次和InputStream OutputStream类似
输入输出流中有4个额外接口:Closeable(实现了java.lang.AutoCloseable接口,所以可以使用try-with-resource方式) Flushable Readable Appendable。前两个就是close和flush()方法的接口
Readable接口有int read(CharBuffer cb)方法,CharBuffer类的方法可以序列化和随机读写。它表示内存中的缓冲或者一个内存映射文件(之后还有解释)
Appendable接口有两个方法用来追加单个字符和字符序列
Appendable append(char c)
Appendable append(CharSequence c)
CharSequence接口描述了char值序列的基本属性。String CharBuffer StringBuilder StringBuffer Writer实现了这个接口
组合输入输出流(过滤器)
java.io下的类解释相对路径一律是从用户工作目录开始,这个目录可以通过System.getProperty("user.dir");获得
使用java.io.File.separator而不是字符
可以通过结合多个流来将字节数据处理成各种其它的数据。举例:如果想从文件中读取数据,可以创建一个FileInputStream给到DataInputStream的构造器当参数
流可以多层嵌套(BufferedInputStream缓冲流的作用是,如果不缓冲,每次read方法都会请求操作系统来读出1个字节,而一次读出一块数据明显是更高效的)
在需要跟踪中间输入流的时候(读取输入时,可能想看看下一个字节数据是不是想要的),这时可以使用PushbackInputStream
PushbackInputStream的理解
这个流中的unread()方法可以把一个字节扔到pushback的缓冲区,此时再使用read()方法会访问到这个字节。所以在使用的时候,unread()之后要接一个read()。这个流的场景是可以过滤一些间隔符之类的固定格式的数据,当作下一个流处理的源
怎么写入文本输出
使用PrintWriter来输出文本,这个类中的方法可以以文本格式打印字符串和数字。使用文件名和字符编码当参数的构造器可以将输出打印到文件中
在输出流对象打印出的字符会转换为字节存入文件,换行符和系统有关,通过System.getProperty("line.separator")来获取系统分隔符
如果writer设置为autoflush模式,那么在println()被调用时,所有缓冲区的字符会被发送到它们的目的地(打印writer总是缓冲的)默认不是自动刷新。通过构造器里的对应参数来开关自动刷新
print方法不抛出遗产。可以使用checkError方法来看输出流是否出问题了
怎么读取文本输入
最简单的访问任意文本的方式是Scanner,可以通过任意输入流来构造Scanner对象
// java 9
// 使用这种方式可以读取短文本文件
var content = new String(Files.readAllBytes(path), charset);
// java 9
List<String> lines = Files.readAllLines(path, charset);
// 如果文件过大,可以懒加载(处理行)
try (Stream<String> lines = Files.lines(path, charset))
{
. . .
}
// 可以使用Scanner来读取Token(被分隔符划分的字符串),默认分隔符是空格。接收任何非Unicode字母当分隔符
Scanner in = ...;
in.useDelimiter("\\PL+");
// 获取所有Token
Stream<String> words = in.tokens();
// 用next获取Token
while (in.hasNext())
{
String word = in.next();
...
}
Java早期使用BufferedReader来处理文本,现在这个类中的lines方法也可以获取Stream<String>,但是这个类没有读数字的方法
以文本格式保存对象
使用PrintWriter将对象的toString方法返回的字符串打印到文件中是一种方式。对应来说,要读出对象就按行读取,然后用分隔符把字符串解析(String.split())回到对象
字符编码
在处理字符时,它们是通过什么编码方式成为字节数据。在Java中,使用Unicode标准来处理字符,一个字符(码点)是21-bit的整数。常用的编码方式是UTF-8,它包括了所有英文字母,并且只占一个字节
另一个常用编码方式是UTF-16,将每个Unicode码编码成1个或2个16-bit的值,Java的String是使用的这个编码方式。UTF-16编码方式有两种形式(big-endian little-endian)即从大到小和从小到大。一个文件可以以字节顺序标识开头来标明用的哪种形式(16-bit数0xFEFF),一个reader可以使用这个值判断,然后丢弃这个值
编码方式太多,所以在写入和读取数据的时候要尽量指定编码方式(在读网页的时候,要看Content-Type头)
平台编码可以通过Charset.defaultCharset。Charset.availableCharsets会返回一个Map,key是名字,value是Charset对象
StandardCharsets类中的静态成员变量(Charset类型)
// 获取字符集对象
Charset shiftJIS = Charset.forName("Shift-JIS");
Java10之后,java.io包允许指定字符编码
有些方法的默认编码是平台编码(UTF-8)
读写二进制数据
处理文本格式的数据很方便,因为它是可以直接阅读的内容,但是传输效率不如字节数据(二进制)高
DataInput和DataOutput接口
DataOutput接口定义了一系列方法writeChars writeInt等,这些方法的输出是不可读的,(写整型数是固定4字节,不管其真是数字占多少位)。对于每个给定类型的数据所占的空间都是一样的,在读入的时候也比转成文本要快
在内存中保存浮点数和整数的方式有两种(正序和倒序),Java统一正序,所以平台独立。而C/C++保存文件可能会跟平台(处理器)有关
writeUTF方法使用修改版本的8-bit UTF编码格式写入字符串数据。码元先用UTF-16的方式表示,然后结果使用UTF-8的规则编码。在0xFFFF之后的编码会有不同(相比直接UTF-8),这是为了兼容Unicode还没有升到16-bit的虚拟机
因为没有其它地方用这种修改版的UTF-8,所以只有在写入专为JVM工作的字符串才用writeUTF(),其它用途使用writeChar()
DataInput和DataOutput接口实现的方法互为镜像。且DataInputStream实现了这个接口(输出同上)
随机访问文件
RandomAccessFile类让你从文件的任何位置开始读写数据。磁盘文件是随机访问的,但是和网络socket有关的输入输出流不是。可以使用随机访问的方式打开只读文件和读写文件(在构造器的第二个参数传入'r','rw')
在用随机访问方式打开文件之后,这个文件不能被删除
随机访问文件有一个文件指针,用来指定要被读或写的下一个字节的位置,seek()方法可以被用来设置文件指针到文件的任意一个字节数据的位置(参数范围是0-文件字节数)
getFilePointer返回当前文件指针的位置。写的方法是覆盖写法,而不是插入
RandomAccessFile实现了DataInput和DataOutput接口
length()方法可以返回整个文件的字节大小
读取字符、整数、浮点数这种固定大小的值比较简单,如果想读取固定大小的字符串,要写帮助方法(思路是使用readChar和writeChar,即将字符串分解成字符处理)
ZIP压缩包
zip压缩包有一个头用来存储信息(每个文件的文件名,压缩方法等),Java中可以使用ZipInputStream来读取zip压缩包。需要查看包里每个独立的文件?(entries)。getNextEntry方法返回一个类型为ZipEntry的对象来描述这个entry。从流中读取到最后,然后调用closeEntry方法来读取下一个entry。在读完最后一个entry不要关闭整个流
var zin = new ZinInputStream(new FileInputStream());
ZipEntry ze;
while((ze = zin.getNextEntry) != null) {
process
ze.closeEntry();
}
zin.close();
如果要写入数据到zip压缩包,使用ZipOutputStream,创建ZipEntry,参数是文件名和其它信息(文件日期和解压方法)
var fout = new FileOutputStream("test.zip");
var zout = new ZipOutStream(fout);
for all files {
ZipEntry ze = new ZipEntry(filename);
zout.writeEntry(ze);
send data to ze
zout.closeEntry();
}
zout.close();
JAR文件是有特殊entry(manifest)的ZIP文件,对应的有JarInputStream和JarOutputStream
ZIP流中的字节数据不需要是文件,允许来自网络连接。且读取压缩形式的数据不需要担心其被解压
对象输入/输出流和序列化
如果存储相同类型的数据,应该使用固定长度的记录格式。然而自己创建的对象基本不是相同类型。例如一个数组声明为Employee类型,但是存储的可能是Manager对象
保存和加载序列化对象
要保存一个对象,首先创建一个ObjectOutputStream对象
var out = new ObjectOutputStream(new FileOutputStream("xxx"));
Manager m = new Manager();
Employee e = new Employee();
out.writeObject(m);
out.writeObject(e);
要加载回一个对象,首先获取一个ObjectInputStream
var in = new ObjectInputStream(new FileInputStream("xxx"));
var e = (Employee) in.readObject();
var e1 = (Employee) in.readObject();
这个类如果想通过输入输出流来保存和加载对象,需要实现Serializable接口。ObjectInputStream和ObjectOutputStream实现了DataInputStream和DataOutputStream,所以可以通过readInt等方法来读写基本数据类型
有一种场景需要考虑:如果一个对象作为其它几个对象共享的对象,那么会发生什么。首先不能保存每个对象的内存地址(重新加载之后内存地址完全不一样)。实际上是序列号解决了这个问题(每个对象有有一个对应的序列号,因此叫做对象序列化机制)
例如:两个Manager对象都有一个共同的秘书Employee对象,那么存在文件中大概是,秘书对象序列号为1,经理对象的秘书字段都是秘书(employee)1
当第一次碰到任何一个对象引用,那么存到文件中,之后再碰到则写入其它信息(之前已经存过序列号为x的对象)。当读入对象时,做的事情相反
写入对象的内容不包含该类以及其超类的静态成员、transient成员
理解对象序列化文件格式
这节主要是讲把对象写入文件之后,文件的组成结构。这里简单记录一下即可,感觉
实际意义不大
本章所有数字都是16进制数
- 每个文件以两字节的魔术数开头
AC ED - 之后是对象序列化格式的版本号,当前是
00 05 - 根据存储顺序存储的一系列对象(如果是Unicode的字符串,保存的是修改过的
UTF-8编码的字符) - 保存了对象,其对应的类信息也会被保存
- 类名,唯一序列号(数据成员类型和方法签名的指纹),描述序列化方法的
flag,数据字段的描述信息(指纹:按标准方式排列类、超类、接口、字段类型、方法签名,然后通过SHA来生成) SHA通常是20字节大小,Java选取前8个字节,这也可以保证类有变动,指纹基本上也会变Externalizable接口,实现此接口的类可以提供自定义的读写方法来代替它们的实例字段的输出
需要记住的事情:
- 序列化的格式包括所有对象的字段的类型
- 每个对象都被给与了序列号
- 一个对象重复出现会被存储为相同序列号的引用
修改默认的序列化机制
有些数据字段是不应该被序列化的,例如只对native方法有意义的存储文件句柄的整数值。这种信息在后续反序列化出对象时或者在另一台机器上反序列化就完全没用了,甚至可能会导致native方法崩溃
如果要防止它们被序列化,只需要用关键字transient来标记字段,如果它们属于不可序列化的类,也需要使用此关键字标记
根据这个机制可以自定义readObject和writeObject方法来定义读写对象,接收一个对象输入输出流
defaultWriteObject()这个方法比较特殊,它只能在序列化类的writeObject方法中被调用,将所有的非transient字段写入文件
每个类可以定义自己的机制,实现Externalizable接口,readExternal(ObjectInputStream) writeExternal(ObjectOutputStream)。这两个方法是保存和读取这个对象的全部信息,包括超类的数据。在写入对象时,序列化机制在输出流几乎不记录对象的类,在读取externalizable对象时,对象输入流通过无参构造器初始化对象,然后调用readExternal方法
readObject和writeObject方法是私有的,供序列化机制使用。此外readExternal方法潜在允许改变创建出来的对象
序列化单例和类型安全的枚举
在序列化和反序列化被假定为唯一的对象(单例和枚举)需要特别注意
举例
public class Orientation {
public static final Orientation HORIZONTAL = new Orientation(1);
public static final Orientation Vertical = new Orientation(2);
private int value;
private Orientation(int value) {this.value = value;}
}
这个类的构造器是私有的,所以用这个类创建的任何对象都只能是其两个静态常量,此时如果直接实现序列化接口然后写入到一个文件,在读出的时候如果执行if(orientation == Orientation.HORIZONTAL)结果是false。即使构造器是私有的,序列化机制也可以用来构造出新对象
如果要解决这个问题,可以另外新写一个方法,对读出的对象进行一个比较然后选取一个常量枚举返回
if (value == 1) return Orientation.HORIZONTAL;
if (value == 2) return Orientation.Vertical;
版本
如果使用序列化来保存对象,那么需要考虑程序升级之后(类签名改变)和旧对象文件的兼容性
通过JDK的程序serialver可以得到某个类的序列号(serialVersionUID)。然后在类中声明一个静态成员变量,使用这个值来初始化。这个序列号代表新版本的类和旧版本兼容。此后序列化不再计算这个类的序列号而是使用这个变量。如果类的字段发生了变化(数量、类型),那么输入流中会尽力将对象改变成新版本的对象,如果同名字段类型不同,输入流不会进行进行类型转换。如果旧对象有新对象不需要的字段,那么输入流会忽略。如果当前版本有新的字段,那么输入流会设置成默认值
注意:
- 如果只是短期的持久化,那么不需要考虑添加版本管理(序列号)
- 扩展了一个序列化的类但是不需要序列化它的实例,那么忽略IDE的警告(
@SuppressWarnings("serial")),这比设定了序列号但是忘记改更安全
使用序列化来克隆
这是一个tricky,使用序列化可以使用深拷贝的方式创建新对象。即不把对象写入到文件中(使用ByteArrayOutputStream 字节数组接收数据),然后马上读出
这种方式很慢!!!(流资源开销)
操作文件
Path接口和Files类包含了在用户的机器上有关文件操作的所有功能,它们关注的是文件在硬盘上的存储。这两个接口/类是在Java7加入的(比Java1.0的File类好用的多)
Paths
Path是一系列文件夹的名称(可能会跟文件名),构造Path对象的第一个部分必须是根目录(windows的盘符),以根目录为第一个部分的Path是绝对路径,否则是相对路径
Path absolute = Paths.get("/home", "harry");
Path relative = Paths.get("myprog", "conf", "user.properties");
静态方法Paths.get接收一些字符串最后用分隔符(根据系统选择)连接起来。这个方法也可以传入一个完整的文件路径
一个Path并不需要绑定一个真正存在的文件(只是一堆名字)
组合或resolve路径是常见操作,p.resolve(q)根据以下情况返回一个path
- 如果q是绝对路径,返回q
- 否则,结果是
p then q即拼接两个路径
resolveSibling方法可以用参数给的路径替换掉当前路径的最后一个子路径(sibling的含义)
对应resolve方法还有relativise方法,它可以将两个路径的共同路径转为..,然后拼接上方法参数的非公共路径的子路径(参数路径必须和调用方法的路径对象类型相同(相对、绝对))
Path aPath = Paths.get("F:", "tmp", "sb.txt");
Path oPath = Paths.get("F:", "tmp", "xdd", "dv.dat");
Path finalPath = aPath.relativize(oPath);
// ..\xdd\dv.dat
System.out.println(finalPath);
normalize方法移除了冗余的..和.
toAbsolutePath方法返回绝对路径,以根目录开头(开发过程中是以工作目录为基本目录)
getParent() getFileName() getRoot()这些方法见名知意
Path接口有toFile()方法,File类有toPath()方法
读写文件
Files类可以快速实现对文件的一般操作
Files.readAllBytes(path)读取文件全部内容。var content = new String(prev, charset)将其转为字符串。Files.readAllLines(path, charset),返回一个List<String>
Files.write(path, content.getBytes(charset)是写入数据,追加写入使用Files.write(path, charset, StandardOpenOption.APPEND),Files.write(path, lines)可以直接写多行(换行符)
上述方法是为了处理长度适中的文本数据,如果文件过大或者是二进制数据,还是使用输入输出流的方式比较好
创建文件和文件夹
创建一个文件夹(参数中除了最后一部分,其它部分都不能不存在)
Files.createDirectory(path);
创建一个文件夹(中间不存在文件夹也创建)
Files.createDirectories(path);
创建一个空文件(如果文件存在会抛出异常,检查存在和创建是原子性的,如果文件不存在,那么这个操作在所有其它能做这个操作的动作之前完成)
Files.createFile(path);
创建临时文件、临时文件夹(用的时候细看API吧)
Files.createTempFile
Files.createTempDirectory
复制、移动和删除文件
复制一个文件
Files.copy(fromPath, toPath);
移动一个文件(先复制后删除)
Files.move(fromPath, toPath);
如果目标文件存在,那么复制或移动会失败,如果想覆盖目标文件,可以使用REPLACE_EXISTING,如果想复制文件的所有属性过去,使用COPY_ATTRIBUTES,将这两个常量当作参数传入即可
移动操作可以使用ATOMIC_MOVE来保证原子性
可以将输入流复制进一个路径(文件),将一个路径(文件)复制进一个输出流
Files.copy(inputStream, path);
Files.copy(path, outStream);
删除文件
// 如果文件不存在,抛出异常
Files.delete(path);
// 删除可以这样做
boolean deleted = Files.deleteIfExists(path);
文件操作选项有一堆常量标志,需要再查看
获取文件信息
检查一个文件是否具有某种属性,返回boolean
exists()
isHidden()
isReadable() isWritable() isExecutable()
isRegularFile() isDirectory() isSymbolicLink()
size()方法返回文件的大小字节数。getOwner方法返回文件的拥有者,返回值是java.nio.file.attribute.UserPrincipal的实例
其它的功能看API即可
遍历文件夹(entries)
Files.list方法会读取一个路径下的所有目录(懒读入),读取目录需要系统资源,所以要记得把资源关闭
try(Stream<Path> entries = Files.list(path)) {
...
}
list方法不遍历子目录,要遍历所有子目录(及其后代),可以使用walk方法,此方法可以传入参数来控制深度,这个方法接收(FOLLOW_LINKS)作为参数来追踪符号链接
使用文件夹流(Directory Stream)
Files.walk方法会创建一个Stream<Path>对象,当需要更细粒度的控制时,使用Files.newDirectoryStream方法,它返回一个DirectoryStream对象(需要关闭系统资源),它并不是java.util.stream.Stream的子接口,它是专门用于遍历文件夹的,且是Iterator的子接口(可以使用foreach)
try(DirectoryStream<Path> entries = Files.newDirectoryStream(dir)) {
for (entry: entries) {
...
}
}
可以通过glob pattern来过滤文件(API可查)
Files.walkFileTree(Paths.get("/"))方法可以定义访问每个文件/文件夹的具体行为(使用FileVisitor<Path>接口实现)(这部分内容用时再看)
ZIP文件系统
ZIP也是一种文件系统(目录树结构)
FileSystem fs = FileSystems.newFileSystem(Paths.get(zipname), null)
这就构建了一个包含ZIP包中所有文件的文件系统对象
Files.copy(fs.getPath(sourceName), target);
遍历ZIP中所有的文件,可以使用Files.walkFileTree(fs.getPath("/"), new SimpleFileVisitor<Path>() {...});。具体实现跟上一节描述的差不多
Memory-Mapped文件
很多操作系统可以利用虚拟内存来”map“文件或文件块到内存。然后这些文件访问就可以像内存中的数组一样,比传统文件操作更快
内存映射文件的性能
计算37M的rt.jar的CRC32校验码。性能比较
随机访问 < 普通输入流 < 缓冲流 < 内存映射文件
对于顺序读取一般大小的文件,不需要使用内存映射文件
java.nio做内存映射非常简单
- 获取一个
channel(对应文件)(对磁盘文件的抽象,使其可以访问操作系统的特性--例如内存映射,文件锁,文件间的快速数据转换)FileChannel channel = FileChannel.open(path, options); - 通过调用
channel对象的map()方法来获取一个ByteBuffer对象,指定想映射的文件区域和映射模式(FileChannel.MapMode规定)(多线程读写的结果依赖于操作系统) - 通过
ByteBuffer和Buffer中的方法来操作数据 Buffer支持顺序访问也支持随机访问,一个buffer是由get和put方法来控制的(get是读,put是写)
Buffer的数据结构
一个buffer是一个相同类型的值的数组,Buffer是一个抽象类,它有很多实现类(略)(StringBuffer不是)
结构图如下:
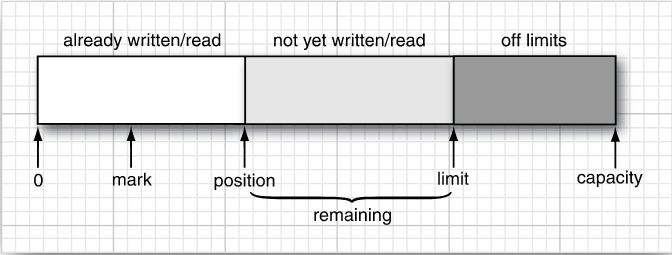
4个标志点:
- 0--position:已经被读或写的部分
- position--limit:还没被读或写
- limit--capacity:超出限制
- mark:用来重复读或写
- remaining:剩下的
capacity:不会改变
position:下一个读或写的值
limit:超过此位置的读或写无意义
开始,position=0,limit=capacity,不断put值之后,达到capacity,就该变成读模式了,调用flip方法设置limit为当前position,然后position设为0,然后调用get(当remaining方法返回true),读完所有的值之后,调用clear来准备进入写模式,它设position为0并且limit为capacity
如果要重读buffer,使用rewind或者mark/reset(API详解)
然后,可以用channel的值来填充buffer,也可以把buffer的值写到channel
文件锁
解决多线程同时修改同一个文件的冲突问题
例如两个进程修改同一个文件,那么一个进程锁住文件之后,第二个进程决定是等待释放锁还是直接跳过
要锁住一个文件,使用
FileChannel channel = FileChannel.open(path);
// tryLock() 非阻塞式 没锁返回null
// 阻塞式
FileLock lock = channel.lock();
还有方法可以锁文件的一部分(API详解)
shared参数,如果是false,那么锁读和写,否则只锁写,即多个进程可以同时读文件(不是所有操作系统都支持这个共享锁FileLock.isShared方法可以查看是否支持的状态)
要注意解锁操作,最佳实践是使用try-with-resource,即
try(FileLock lock = channel.lock()) {
...
}
文件锁是依赖系统实现的,有几点注意:
- 一些系统中,即使应用没获得锁,还是可以修改其它应用获得锁的文件
- 一些系统中,无法同时锁一个文件并且映射到内存
- 所有的文件锁都被JVM持有,所以一个虚拟机启动的两个程序,不能同时持有一个文件的两把锁
- 一些系统中,关闭一个channel会释放这个JVM持有的文件上的所有锁。应该避免一个上锁的文件上开多个channel
- 在网络文件系统上锁一个文件的行为高度依赖系统,最好避免
正则表达式
正则表达式是用来定位匹配某些特定模式的字符串的
正则表达式语法
[Jj]ava.+
解释如下
- 第一个字母是J或j
- 后三个字母是ava
- 剩下的字符串包含一个或多个任意字符
语法实在太多,就不放了,实际用的时候有工具(网站)
匹配字符串
测试一个给定字符串是否符合某个规则
- 创建一个
Pattern字符串Pattern pattern = Pattern.compile(patternString) - 获取一个
Matcher对象,Matcher matcher = pattern.matcher(input); if(matchr.matches())
input是任何实现了CharSequence接口的对象(StringBuffer String CharBuffer),在compile方法中可以指定其它标志(flag-API详解)
如果想在流中匹配模式
Stream<String> strings = ...;
Stream<String> result = strings.filter(pattern.asPredicate());
如果正则中包含组,Matcher对象可以显示出组的边界(start(groupIdx) end(groupIdx)) group(groupIdx)直接拿出匹配到的字符
其它功能待使用再看
多次匹配
一次只找匹配的一个或多个字串。Matcher类的find方法可以找到写一个匹配的值,如果返回true,使用start end group进行后续操作
也可调用results()方法,返回Stream<MatchResult>对象,然后再进行操作。Scanner.findAll()返回的也是这个对象,操作同上
通过分隔符拆分
Pattern.split方法可以去掉分隔符,返回剩下的token(数据),返回值是一个数组。如果有很多token,可以使用splitAsStream方法,返回一个流对象供操作。如果不在乎是懒拉取(数据)还是预编译,可以直接使用String.split(正则)。如果是文件,可以使用Scanner的useDelimiter方法,参数是正则表达式,然后调用tokens()方法
替换匹配串
Matcher的replaceAll方法将所有正则匹配的串替换为给定串
替换串可以包括在正则中组的引用。$n代替第n组,${name}代替有名字的组。如果包含$可以使用转义
matcher.replaceAll(Matcher.quoteReplacement(str))可以忽略所有所有的$和\
在这个方法里可以提供一个替换方法(参数是MatchResult,返回值是字符串)
replaceFirst只能替换第一个匹配的串

 浙公网安备 33010602011771号
浙公网安备 33010602011771号