UNIX环境高级编程第五章笔记
流和FILE对象
标准输入、标准输出和标准出错
缓冲
打开流
读和写流
定位流
临时文件
内存流
流和FILE对象
标准I/O库建立在流的概念上。当使用标准I/O库打开一个文件进行读写时,会创建一个流,该流与将要打开的文件进行关联,通过对抽象流的读写来间接读写文件。
标准I/O文件流可以用于ASCII单字节字符集,也能用于多字节字符集,比如wchar。默认标准I/O文件流是未定向的,也即没有确定单字符的字节个数,如果我们使用单字节I/O函数来读写,那么文件流将被设定为单字节,反之使用多字节I/O函数来读写,那么文件流就设定为多字节。
fwide函数用来设定流的定向
include <wchar.h>
include <stdio.h>
int fwide (FILE * fp , int mode);
参数:
mode可选正数(宽定向)负数(字节定向) 零(不设置流的定向)
返回值:
流为宽定向则返回正值
流为字节定向则返回负值
未定向则返回0
标准输入、标准输出和标准出错
UNIX系统的shell中会默认为进程打开3个文件描述符:标准输入、标准输出和标准错误。但它们是文件描述符的可阅读宏,ISO C标准I/O是无法使用的,为此ISO C标准I/O定义了三个另外的名字来引用它们,分别是:stdin、stdout、strerr。它们在头文件<stdio.h>中被定义。实际上STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO分别对应stdin、stdout、strerr。
缓冲
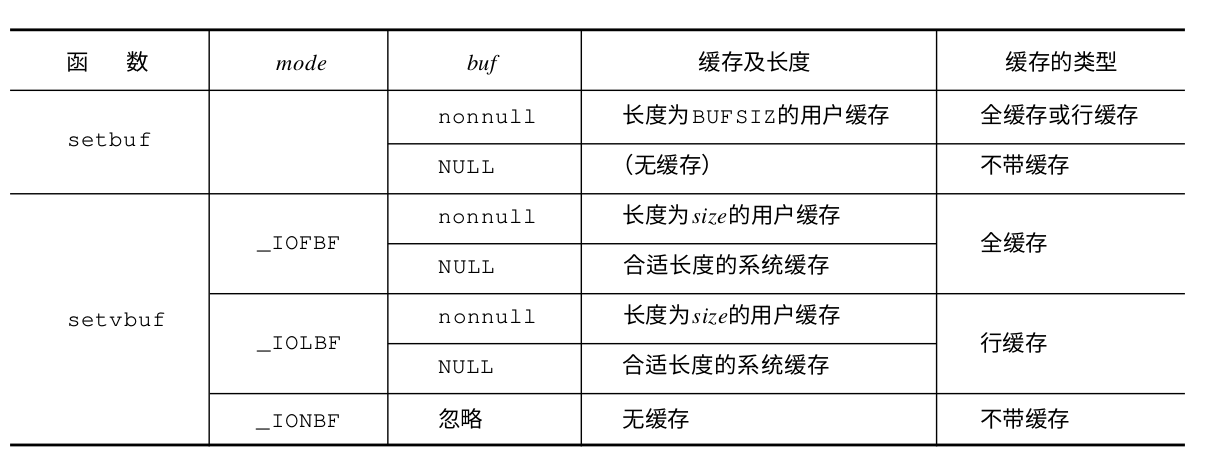
对于UNIX系统来说,标准I/O库最终还是建立在系统的read和write系统调用上的。而UNIX系统的read和write系统调用是不带缓冲的,所以为了提供效率,标准I/O库提供了缓冲管理。标准I/O库的缓冲有三种类型:
- 全缓冲:只有标准I/O库的缓冲区满了才进行实际的I/O操作,或者调用fflush( )函数来强制I/O;
- 行缓冲:一旦遇到换行符就执行I/O操作;
- 不带缓冲:不使用缓冲区,每次读写都进行I/O操作。
标准明确规定标准错误是不允许全缓冲的,可以是行缓冲或不带缓冲的。但几乎所有的实现都是不带缓冲的。标准还规定标准输入和标准输出在指向交互式设备时不允许全缓冲。
对于一个给定的流,我们可以利用标准I/O库提供的两个函数来更改默认的缓冲区
include <stdio.h>
void setbuf (FILE* __stream, char* __buf);
int setvbuf (FILE* __stream, char* __buf, int __modes, size_t __n);
参数:
mode可取值 _IOFBF全缓冲_IOLBF行缓冲_IONBF不带缓冲
对于setbuf来说,它没有返回值,它仅仅用来关闭流的缓冲区。而setvbuf可以用来设置缓冲区类型,比如全缓冲或者无缓冲,另外我们还能自定义我们自己的缓冲区用于给定的流。setvbuf成功返回0,出错返回非0,。对于这两个函数来说,它们都必须针对一个已存在的流来操作。
需要注意的是,setvbuf( )函数存在一个陷阱,如果我们调用该函数时,传给给__buf参数的缓冲区是一个数组地址而非一个动态分配的内存地址,那么在主调函数返回时,数组地址所指向的缓冲区由于是一个局部的自动变量,因此该数组会被销毁从而导致缓冲区不可用,如果不关闭流,那么流会继续写这一段内存,进而导致内存错误。因此此种情况下,必须在主调函数返回前关闭流。
任何时候,我们都可以强制来刷新流的缓冲区。其头文件及函数原型如下:
include <stdio.h>
int fflush (FILE *__stream);
打开流
标准I/O库提供了3个函数用于打开一个流。其头文件及函数原型如下:
include <stdio.h>
FILE *fopen (const char * __filename, const char * __modes);
FILE *freopen (const char * __filename, const char * __modes, FILE * __stream);
FILE *fdopen (int __fd, const char *__modes);
fopen函数打开指定路径的文件;
freopen函数在指定流上关联指定的文件,如流已经打开,则重新打开;如流已定向,则清除定向。该函数通常用来重定向标准输入、标准输出和标准错误;
fdopen函数将一个已有的文件描述符与一个标准I/O流关联。该函数常在创建管道或者网络socket得到的描述符上。
对于UNIX函数来说,其不分区二进制和文本模式,因为它们的区别在于上层应用如何解释,与内核无关。

读和写流
一旦通过打开流关联了文件,我们就可以使用该流来间接读写文件。读写的方式有以下三种:
每次一个字符的I/O:一次读或写一个字符,该方式属于文本模式;
每次一行的I/O:一次读或写一行,直到遇到换行符,该方式属于文本模式;
直接I/O:每次读写特定大小特定数量的对象,这种方式是二进制模式。
用于每次一个字符I/O输入函数如下:
include <stdio.h>
int getc (FILE *__stream);
int fgetc (FILE *__stream);
int getchar (void);
对于getc( ),标准明确指出可以实现为宏,但实际在gcc中并没有实现为宏,只是定义了一个宏替换。这三个函数都是文本模式的,因为它们一次性都只读取一个unsigned char,然后转换为int,它们在读取一个字符之后,流自动移动到下一个字符,然后再次调用这些函数时会返回相对于上一次字符的下一个位置上的字符。
从流中读取数据之后,流会移动到下一个字符处,这是自动的,我们可以用一个函数将之前读取的字符再送回流中。其头文件及函数原型如下:
include <stdio.h>
int ungetc (int __c, FILE *__stream);
该函数可以将之前读出的字符再送回至流中,并且使流的位置恢复至上一个。它不能回送EOF字符,一次也只能回送一个。该函数的典型应用场合是切词算法,例如要实现某种形式的搜索引擎,会对用户的输入进行切词分析,算法会经常需要查看下一个字符是什么,能否组合成一个词语,然后再决定如何处理字符,是送回还是继续读取。
每次一个字符I/O
include <stdio.h>
int putc (int c, FILE *__stream);
int fputc (int c, FILE *__stream);
int putchar (int c);
它们成功返回 c,失败返回EOF。这三个函数也都是文本模式的,因为它们一次性都只写入一个unsigned char,如果你传递一个值超过256的int类型实参给函数,那么超出范围的会被截断。
每次一行I/O
下面两个函数提供每次输入一行的功能。其头文件及函数原型如下:
include <stdio.h>
int fputs (const char* __s, FILE* __stream);
int puts (const char* __s);
对于gets( )函数,应该弃用。因为它可能导致缓冲区溢出,这是1988年因特网蠕虫病毒爆发的一个诱因。
下面两个函数提供每次输出一行的功能。其头文件及函数原型如下:
include <stdio.h>
char *gets (char __s);
char fgets (char __s, int __n, FILE __stream);
以上4个函数在跨平台时,需要考虑不同平台换行的表示方式。当然它们也是文本模式的输入和输出。
二进制I/O
前面介绍的函数都是文本模式的,之所以是文本模式是因为程序的解释方式,前面的函数都是把读或写的内容当做字符来处理的,因此它们是文本模式的。标准I/O库还提供了二进制模式的库函数。其头文件及函数原型如下:
include <stdio.h>
size_t fread (void* __ptr, size_t __size, size_t __n, FILE* __stream);
size_t fwrite (const void* __ptr, size_t __size, size_t __n, FILE* __s);
两个函数的返回值都是读或写的对象数量。其中__size是对象的大小,也即sizeof计算得到的大小;__n是对象的数量。
定位流
对于标准I/O库定义的流概念,我们可以像对待UNIX系统中文件描述符那样,也认为它有一个类似文件偏移量的东西,可以用来更改流中内容的指示位置。ISO C定义了两个具有可移植的函数。其头文件及函数原型如下:
include <stdio.h>
int fgetpos (FILE* __stream, fpos_t* __pos);
int fsetpos (FILE* __stream, const fpos_t* __pos);
除了上面两个可移植的函数之外,UNIX系统的各实现也有两组4个函数可以用于定位流。其头文件及函数原型如下:
include <stdio.h>
long int ftell (FILE *__stream);
int fseek (FILE *__stream, long int __off, int __whence);
off_t ftello (FILE *__stream);
int fseeko (FILE *__stream, __off_t __off, int __whence);
这两组函数的区别是偏移量的类型。
还有一个用来将流设置到文件的起始位置的函数。其头文件及函数原型如下:
include <stdio.h>
void rewind (FILE *__stream);
实现细节
标准I/O库最终还是需要调用UNIX系统I/O库的各函数,每一个标准I/O流都关联一个文件描述符,UNIX系统提供了一个功能用于获取标准I/O流所关联的文件描述符。其头文件及函数原型如下:
include <stdio.h>
int fileno(FILE *__stream);
该函数没有出错返回,它只能返回对应的描述符。
临时文件
临时文件
ISO C标准I/O提供两个函数用来创建临时文件。其头文件及函数原型如下:
include <stdio.h>
char *tmpnam (char *__s);
FILE *tmpfile (void);
上面的函数中tmpnam( )已被废弃,因为它有一个时间窗口的问题,会导致安全问题。取而代之的是新的两个函数。其头文件及函数原型如下:
include <stdlib.h>
char *mkdtemp (char *__template);
int mkstemp (char *__template);
内存流
标准I/O库把数据缓存存放于内存中,因此每次一个或每次一行的I/O非常有效。当使用FILE文件流对象时,前面提供的标准库函数都是建立在打开一个文件的基础上的,标准库还提供了一个函数用于创建流,然而该函数并不将流关联到一个指定的文件上,而是关联到一块内存用于读写。其头文件及函数原型如下:
include <stdio.h>
FILE *fmemopen (void *__s, size_t __len, const char *__modes);
函数成功返回流指针,失败返回NULL。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号