操作系统概念第四章笔记
文章目录
概述
每个线程是CPU使用的一个基本单元。它包括线程ID,程序计数器,寄存器组和堆栈。
与同一进程其他线程共享代码段,数据段和其他操作系统资源。
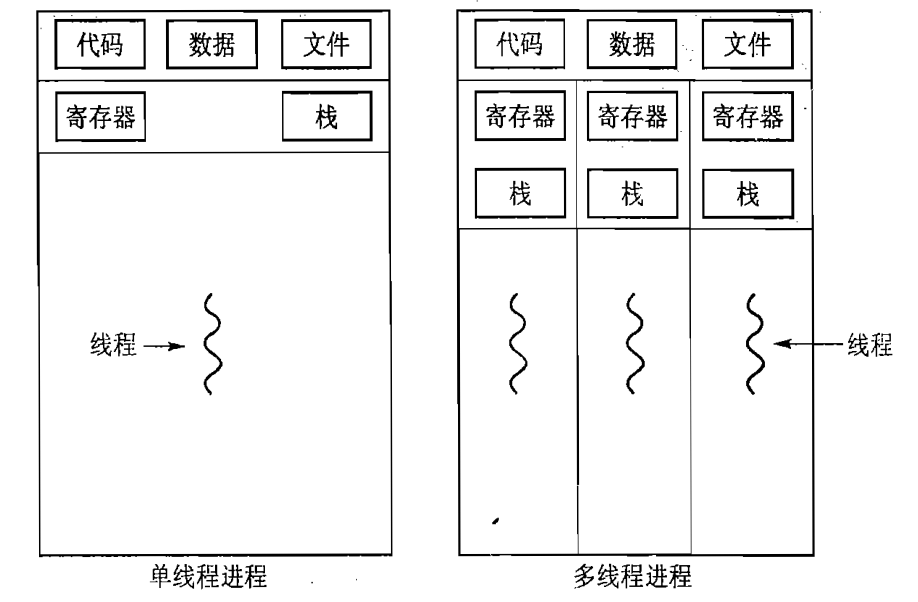
多线程编程的优点:
- 响应性:如果一个交互程序采用多线程,那么即使部分阻塞或者进行冗长操作,它仍可以继续执行,增加对用户的响应程序。
- 资源共享:进程只能通过共享内存或消息传递的技术共享资源,而线程默认共享它们所属进程的内存和资源。可以减少通信的消耗。
- 经济:进程创建所需的内存和资源分配非常昂贵。而线程能够共享所属进程的内存和资源,所以创建和切换线程更加经济。
- 可伸缩性:对于多处理器体系结构,多线程的优点更大。因为线程可在多处理核上并行运行。
在处理器系统上采用多个用户级线程与在单处理器系统的单线程相比并没有很好的性能
一个包括多用户线程的多线程系统无法在多处理器系统上同时使用不同的处理器。操作系统只能看到单一的进程且不会调度在不通过
处理器上的不同进程的线程。
多核编程
多核和多处理器系统:无论多个计算核是在多个CPU芯片上还是在单个CPU芯片上,都成为多核或多处理器系统。
每个处理核心同一时间只能处理同一个线程
多核系统编程有五个方面的挑战:
- 识别任务:分析应用程序,查找区域以便分为独立的,并发的任务。
- 平衡:在识别可以并行运行任务相比,还应确保任务执行同等价值的工作。有些情况下,贡献少的任务也单独占用一个内核来工作,这样就不值得了。
- 数据分割:不仅任务要分割,数据也需要分割成单独的部分。
- 数据依赖:任务访问的数据必须分析多个任务之间的依赖关系。
- 测试与调试:测试与调试比单线程的应用程序更加困难。
并行类型
通常,有两种类型的并行,数据并行(data parallelism)与任务并行(task parallelism)
- 数据并行注重将数据分布于多个计算核上。
- 任务并行涉及将任务分配到多个计算核上,每个线程都执行一个独特的操作。不同线程可以操作相同数据,也可以操作不同数据。
一般情况下,应用程序混合使用这两种方法
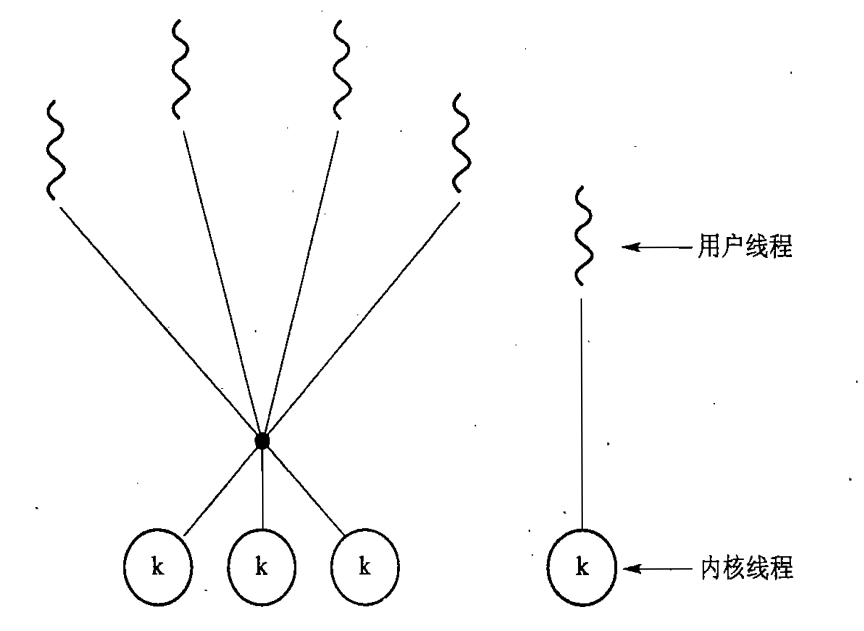
1.用户线程和内核线程
有两种不同方法提供线程支持,用户层的用户线程和内核层的内核线程
用户级线程是指不需要内核支持而在用户程序中实现的线程,它的内核的切换是由用户态程序自己控制内核的切换,不需要内核的干涉。但是它不能像内核级线程一样更好的运用多核CPU。
用户级线程优点:
线程的调度不需要内核直接参与,控制简单。
可以在不支持线程的操作系统中实现。
同一进程中只能同时有一个线程在运行,如果有一个线程使用了系统调用而阻塞,那么整个进程都会被挂起,可以节约更多的系统资源。
用户级线程缺点:
一个用户级线程的阻塞将会引起整个进程的阻塞。
用户级线程不能利用系统的多重处理,仅有一个用户级线程可以被执行。
内核级线程:切换由内核控制,当线程进行切换的时候,由用户态转化为内核态。切换完毕要从内核态返回用户态。可以很好的运用多核CPU,就像Windows电脑的四核八线程,双核四线程一样。
内核级线程优点:
当有多个处理机时,一个进程的多个线程可以同时执行。
由于内核级线程只有很小的数据结构和堆栈,切换速度快,当然它本身也可以用多线程技术实现,提高系统的运行速率。
内核级线程缺点:
线程在用户态的运行,而线程的调度和管理在内核实现,在控制权从一个线程传送到另一个线程需要用户态到内核态再到用户态的模
式切换,比较占用系统资源。(就是必须要受到内核的监控)
两者关联性
它们之间的差别在于性能。
内核支持线程是OS内核可感知的,而用户级线程是OS内核不可感知的。
用户级线程的创建、撤消和调度不需要OS内核的支持。
用户级线程执行系统调用指令时将导致其所属进程被中断,而内核支持线程执行系统调用指令时,只导致该线程被中断。
在只有用户级线程的系统内,CPU调度还是以进程为单位,处于运行状态的进程中的多个线程,由用户程序控制线程的轮换运行在
有内核支持线程的系统内,CPU调度则以线程为单位,由OS的线程调度程序负责线程的调度。
用户级线程的程序实体是运行在用户态下的程序,而内核支持线程的程序实体则是可以运行在任何状态下的程序。
多线程模型
多对一模型
多对一模型映射多个用户线程到一个内核线程。
如果一个线程执行阻塞系统调用,那么整个进程都会被阻塞。又因为任一时间只有一个线程可以访问内核,所以多个进程不能并行运行到多处理器系统上。
一对一模型
一对一模型映射每个用户线程到一个内核线程。
该模型在一个线程执行阻塞系统调用时,能允许另一个线程继续执行,所以它提供了更好的并发功能,
它也允许多个线程并行运行在多处理器系统上。
唯一的缺点是,创建一个用户线程就要创建一个相应的内核线程,这会增加开销,影响应用程序的性能。
多对多模型
多对多模型,多路复用多个用户级线程到同样数量或更少数量的内核线程。
内核线程的数量可能与特定应用程序或特定机器有关
开发人员可以创建任意多的用户线程,并且相应内核线程能在多处理器系统上并发执行。而且,当一个线程执行阻塞系统调用,内核可以调度另一个进程来执行。
双层模型
多对多模型的一种变种仍然多路复用多个用户级线程到同样数量或更少数量的内核线程,但也允许绑定某个用户线程到一个内核线程。
线程库
线程库为程序员提供创建和管理线程的API。
实现线程库的主要方法有两种:
- 第一种方法:在用户空间中提供一个没有内核支持的库。调用库内的一个函数只是导致了用户空间内的一个本地函数的调用,而不是系统调用。
- 第二种方法:实现由操作系统直接支持的内核级的一个库。调用库中的一个API函数通常会导致对内核的系统调用
目前使用的三种主要线程库是:POSIX Pthreads, Windows, Java.
多线程创建策略
- 同步线程
父线程创建了一个或多个子线程后,在恢复执行之前应该等待所有子线程终止
- 异步线程
父线程创建了一个子线程后,父线程就恢复自身的执行,这样就和子线程并发执行,通常这样的线程之间没有数据共享
隐式多线程
随着多核处理的日益增多,出现了拥有数百甚至数千线程的应用程序。设计这样的应用程序不起一个简单的事情,所以,为了解决这些困难并且更好支持设计多线程程序,出现一种隐式策略(implicit threading):
有一种方法是将多线程的创建与管理交给编译器和运行时库来完成。
线程池
先举一个例子,假设服务器每收到一个请求就会创建一个单独线程来处理请求。这样就会有潜在的问题。
第一个问题就是创建线程也是需要时间,第二个问题更为严重,如果允许所有并发请求都通过新进程来处理,那么我们没有限制系统内的并发执行线程的数量。无限制的线程可能耗尽系统资源,如CPU时间和内存。
这时候就可以使用线程池(thread tool)。
线程池的主要思想是:在进程开始时创建一定数量的线程,并加到池中以等待工作。当服务器收到请求时,它会唤醒池内的一个线程(如果有可用线程),并将需要服务的请求传递给它。一旦线程完成了服务,就会回到池中再等待工作。如果池内没有可用线程,那么服务器就会等待,知道有空线程为止。
线程池有以下三个优点:
- 用现有线程服务请求比等待创建一个线程更快
- 线程池限制了任何时候可用线程的数量。这对那些不能支持大量并发线程的系统非常重要
- 将要执行任务从创建任务的机制中分离出来,允许我们采用不同策略运行任务。
OpenMP
OpenMP为一组编译指令和API,用于编写C,C++,Fortran等语言的程序。它支持共享内存环境下的并行编程。
OpenMP识别并行区域(parallel region),即可并行运行的代码块。
include <omp.h>
include <stdio.h>
int main ()
{
#pragma omp parallel /创建和系统处理核一样多的线程/
{
printf(" l love study");
}
pragma opm parallel for /*openmp 会把这个for循环的任务分给多个线程
{
for(i = 0; i< n ; i++)
c[i] = a[i] + b[i];
}
}
大中央调度
大中央调度(Grand Central Dispatch ,GCD),是Apple Mac OS X和iOS操作系统的一种技术。
它允许应用程序开发人员将某些代码区段并行运行。
多线程会遇到的一些问题
fork()和exec()
如果程序中的某个线程调用了fork(),那么新进程复制所有线程还是复制该线程,这取决与UNIX系统,有的两种都支持但也有的只
支持一个
如果一个线程调用了exec()那么exec()指定的程序会取代整个进程
信号处理
UNIX信号(signal)用于通知进程某个特定事件已经发生。
信号的接收可以是同步的,也可以是异步的。
不管怎样,所有信号,都遵循相同的模式:
- 信号是由特定事件的发生而产生的。
- 信号被传递给某个进程。
- 信号一旦收到就应处理。
信号处理程序分为两种:
- 缺省的信号处理程序
- 用户定义的信号处理程序
每个信号都有一个缺省信号处理程序(default signal handler),在处理信号时,由内核来运行。
这种缺省动作可以通过用户定义处理程序(user-defined signal handler)来改写。
如果一个进程有多个线程,那么信号应被传递到哪里去呢?一般有以下四种选择:
- 传递信号到信号所适用的线程
- 传递信号到进程内的每个线程
- 传递信号到进程内的某些线程
- 规定一个特殊线程接受该进程的所有信号
这取决于产生信号的种类
线程撤销
线程撤销(thread cancellation) 是在线程完成之前终止线程。
如用户按下网页浏览器的按钮,以停止进一步加载网页。加载网页可能需要多个线程,每个图像都是在一个单独线程中被加载的。当用户按下浏览器的停止按钮时,所有加载网页的线程被撤销。
需要撤销的线程,称为目标线程(target thread)。目标线程的撤销有两种情况:
- 异步撤销:一个线程立即终止目标线程
- 延迟撤销:目标线程不断检查它是否应终止,这允许目标线程有机会有序终止自己。
线程本地存储
同一进程的线程共用进程的内存与数据,但线程也会有自己独有的数据,称这种数据为线程本地存储(Thread-Local Storage, TLS)
调度程序激活
内核与线程库间可能需要通信,如多对多模型与双层模型。这种协调允许动态调整内核线程的数量,以便确保最优性能。
轻量级进程(LightWeight Process, LWP):许多系统在实现多对多或双层模型时,在用户和内核线程之间增加一个中间数据结构。这种数据结构就是轻量级进程。
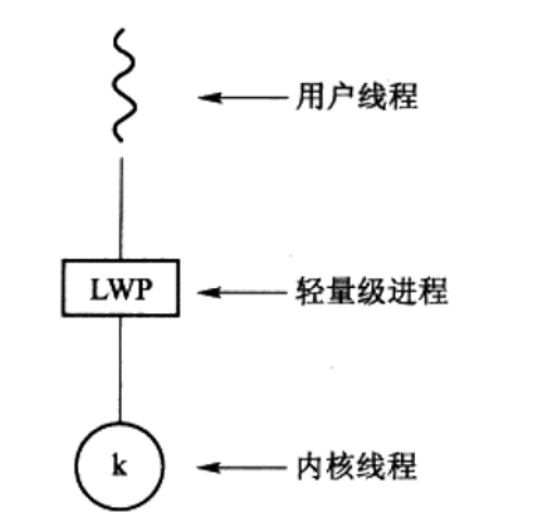
对于用户级线程库,LWP表现为虚拟处理器,以便应用程序调度并运行用户线程。
每个LWP与一个内核线程相连,而只有内核线程才能通过操作系统调度以便运行于物理处理器。如果内核线程阻塞,LWP也会阻塞,上面的用户线程也会阻塞。
为了运行高效,应用程序可能需要一定数量的LWP。通常,每个并发的,阻塞的系统调用需要一个LWP。
假设一个应用程序为CPU密集型,并且运行在单个处理器上,在这种情况下,同一时间只有一个线程可以运行,所以只需要一个LWP就够了。
但是,一个IO密集型的应用程序可能需要多个LWP来执行。假设有5个不同的文件读请求可能同时发生,就需要5个LWP。因为每个都需要等待内核I/O的完
成。如果只有4个LWP,那么第五个请求就必须等待一个LWP从内核中返回。
调度器激活(scheduler activation):用户线程库与内核之间的一种通信方案。
工作流程如下:
-
内核提供一组虚拟处理器(LWP)给应用程序,而应用程序可以调度用户线程到任何一个可用虚拟处理器。
-
此外,内核应将有关特定事件通知应用程序。
这个步骤叫做回调(upcall),它有线程库通过** 回调处理程序(upcall handler) **来处理。
-
当一个应用程序的线程要阻塞时,内核向应用程序发出一个回调,通知它有一个线程将会阻塞并且标识特定线程。
-
内核分配一个新的虚拟处理器给应用程序,应用程序在这个新的虚拟处理器上运行回调处理程序,保存阻塞线程的状态,并释放阻塞线程运行的虚拟处理器。
-
回调处理程序调度另一个适合在新的虚拟处理器上运行的线程
-
当阻塞线程等待的事件发生时,内核向线程库发出另一个回调,通知它先前阻塞的线程现在有资格运行了。
该事件的回调处理程序也需要一个虚拟处理器,内核可能分配一个新的虚拟处理器,或抢占一个用户线程并在其虚拟处理器上运行回调处理程序。
在阻塞线程有资格运行后,应用程序在可用虚拟处理器上运行符合条件的线程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号