深入理解linux网络技术内幕读书笔记(三)--用户空间与内核的接口
Table of Contents
概论
procfs (/proc 文件系统)
- 允许内核以文件的形式向用户空间输出内部信息。
- 可以通过cat, more和> shell重定向进行查看与写入。
sysctl (/proc/sys目录)
此接口允许用户空间读取或修改内核变量的值。
两种方式访问sysctl的输出变量:
- sysctl 系统调用
- procfs
编程接口
/proc/sys/中的文件和目录都是依ctl_table结构定义的。ctl_table结构的注册和除名是通过在kernel/sysctl.c中定义的register_sysctl_table和unregister_sysctl_table函数完成。
- ctl_table结构
1: struct ctl_table 2: { 3: const char *procname; /* proc/sys中所用的文件名 */ 4: void *data; 5: int maxlen; /* 输出的内核变量的尺寸大小 */ 6: mode_t mode; 7: struct ctl_table *child; /* 用于建立目录与文件之间的父子关系 */ 8: struct ctl_table *parent; /* Automatically set */ 9: proc_handler *proc_handler; /* 完成读取或者写入操作的函数 */ 10: void *extra1; 11: void *extra2; /* 两个可选参数,通常用于定义变量的最小值和最大值ֵ */ 12: };
一般来讲,/proc/sys下定义了以下几个主目录(kernel, vm, fs, debug, dev),其以及它的子目录定义如下:
1: static struct ctl_table root_table[] = { 2: { 3: .procname = "kernel", 4: .mode = 0555, 5: .child = kern_table, 6: }, 7: { 8: .procname = "vm", 9: .mode = 0555, 10: .child = vm_table, 11: }, 12: { 13: .procname = "fs", 14: .mode = 0555, 15: .child = fs_table, 16: }, 17: { 18: .procname = "debug", 19: .mode = 0555, 20: .child = debug_table, 21: }, 22: { 23: .procname = "dev", 24: .mode = 0555, 25: .child = dev_table, 26: }, 27: /* 28: * NOTE: do not add new entries to this table unless you have read 29: * Documentation/sysctl/ctl_unnumbered.txt 30: */ 31: { } 32: };
sysfs (/sys 文件系统)
sysfs主要解决了procfs与sysctl滥用的问题而出现的。
ioctl 系统调用
一切均从系统调用开始,当用户调用ioctl函数时,会调用内核中的 SYSCALL_DEFINE3 函数,它是一个宏定义,如下:
1: #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__)【注意】宏定义中的第一个#代表替换, 则代表使用’-’强制连接。
SYSCALL_DEFINEx之后调用__SYSCALL_DEFINEx函数,而__SYSCALL_DEFINEx同样是一个宏定义,如下:
1: #define __SYSCALL_DEFINEx(x, name, ...) \ 2: asmlinkage long sys##name(__SC_DECL##x(__VA_ARGS__)); \ 3: static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__)); \ 4: asmlinkage long SyS##name(__SC_LONG##x(__VA_ARGS__)) \ 5: { \ 6: __SC_TEST##x(__VA_ARGS__); \ 7: return (long) SYSC##name(__SC_CAST##x(__VA_ARGS__)); \ 8: } \ 9: SYSCALL_ALIAS(sys##name, SyS##name); \ 10: static inline long SYSC##name(__SC_DECL##x(__VA_ARGS__))中间会调用红色部分的宏定义, asmlinkage 会通知编译器仅从 栈 中提取该函数的参数,
上面只是阐述了系统调用的一般过程,值得注意的是,上面这种系统调用过程的应用于最新的内核代码中,老版本中的这些过程是在syscall函数中完成的。
我们就以在网络编程中ioctl系统调用为例介绍整个调用过程。当用户调用ioctl试图去从内核中获取某些值时,会触发调用:
1: SYSCALL_DEFINE3(ioctl, unsigned int, fd, unsigned int, cmd, unsigned long, arg) 2: { 3: struct file *filp; 4: int error = -EBADF; 5: int fput_needed; 6: 7: filp = fget_light(fd, &fput_needed); //根据进程描述符获取对应的文件对象 8: if (!filp) 9: goto out; 10: 11: error = security_file_ioctl(filp, cmd, arg); 12: if (error) 13: goto out_fput; 14: 15: error = do_vfs_ioctl(filp, fd, cmd, arg); 16: out_fput: 17: fput_light(filp, fput_needed); 18: out: 19: return error; 20: }之后依次经过 file_ioctl-—>vfs_ioctl 找到对应的与socket相对应的ioctl,即sock_ioctl.
1: static long vfs_ioctl(struct file *filp, unsigned int cmd, 2: unsigned long arg) 3: { 4: ........ 5: if (filp->f_op->unlocked_ioctl) { 6: error = filp->f_op->unlocked_ioctl(filp, cmd, arg); 7: if (error == -ENOIOCTLCMD) 8: error = -EINVAL; 9: goto out; 10: } else if (filp->f_op->ioctl) { 11: lock_kernel(); 12: error = filp->f_op->ioctl(filp->f_path.dentry->d_inode, 13: filp, cmd, arg); 14: unlock_kernel(); 15: } 16: ....... 17: }从上面代码片段中可以看出,根据对应的文件指针调用对应的ioctl,那么socket对应的文件指针的初始化是在哪完成的呢?可以参考socket.c文件下sock_alloc_file函数:
1: static int sock_alloc_file(struct socket *sock, struct file **f, int flags) 2: { 3: struct qstr name = { .name = "" }; 4: struct path path; 5: struct file *file; 6: int fd; 7: .............. 8: file = alloc_file(&path, FMODE_READ | FMODE_WRITE, 9: &socket_file_ops); 10: if (unlikely(!file)) { 11: /* drop dentry, keep inode */ 12: atomic_inc(&path.dentry->d_inode->i_count); 13: path_put(&path); 14: put_unused_fd(fd); 15: return -ENFILE; 16: } 17: ............. 18: }alloc_file函数将socket_file_ops指针赋值给socket中的f_op.同时注意 file->private_data = sock 这条语句。
1: struct file *alloc_file(struct path *path, fmode_t mode,const struct file_operations *fop) 2: { 3: ......... 4: 5: file->f_path = *path; 6: file->f_mapping = path->dentry->d_inode->i_mapping; 7: file->f_mode = mode; 8: file->f_op = fop; 9: 10: file->private_data = sock; 11: ........ 12: }而socket_file_ops是在socket.c文件中定义的一个静态结构体变量,它的定义如下:
1: static const struct file_operations socket_file_ops = { 2: .owner = THIS_MODULE, 3: .llseek = no_llseek, 4: .aio_read = sock_aio_read, 5: .aio_write = sock_aio_write, 6: .poll = sock_poll, 7: .unlocked_ioctl = sock_ioctl, 8: #ifdef CONFIG_COMPAT 9: .compat_ioctl = compat_sock_ioctl, 10: #endif 11: .mmap = sock_mmap, 12: .open = sock_no_open, /* special open code to disallow open via /proc */ 13: .release = sock_close, 14: .fasync = sock_fasync, 15: .sendpage = sock_sendpage, 16: .splice_write = generic_splice_sendpage, 17: .splice_read = sock_splice_read, 18: };从上面分析可以看出, filp-> f_op->unlocked_ioctl 实质调用的是sock_ioctl。
OK,再从sock_ioctl代码开始,如下:
1: static long sock_ioctl(struct file *file, unsigned cmd, unsigned long arg) 2: { 3: ....... 4: sock = file->private_data; 5: sk = sock->sk; 6: net = sock_net(sk); 7: if (cmd >= SIOCDEVPRIVATE && cmd <= (SIOCDEVPRIVATE + 15)) { 8: err = dev_ioctl(net, cmd, argp); 9: } else 10: #ifdef CONFIG_WEXT_CORE 11: if (cmd >= SIOCIWFIRST && cmd <= SIOCIWLAST) { 12: err = dev_ioctl(net, cmd, argp); 13: } else 14: #endif 15: ....... 16: default: 17: err = sock_do_ioctl(net, sock, cmd, arg); 18: break; 19: } 20: return err; 21: }首先通过file变量的private_date成员将socket从sys_ioctl传递过来,最后通过执行sock_do_ioctl函数完成相应操作。
1: static long sock_do_ioctl(struct net *net, struct socket *sock, 2: unsigned int cmd, unsigned long arg) 3: { 4: ........ 5: err = sock->ops->ioctl(sock, cmd, arg); 6: ......... 7: } 8: 9: 那么此时的socket中的ops成员又是从哪来的呢?我们以IPV4为例,都知道在创建socket时,都会需要设置相应的协议类型,此处的ops也是socket在创建inet_create函数中遍历inetsw列表得到的。 10: 11: static int inet_create(struct net *net, struct socket *sock, int protocol, 12: int kern) 13: { 14: struct inet_protosw *answer; 15: ........ 16: sock->ops = answer->ops; 17: answer_prot = answer->prot; 18: answer_no_check = answer->no_check; 19: answer_flags = answer->flags; 20: rcu_read_unlock(); 21: ......... 22: }那么inetsw列表又是在何处生成的呢?那是在协议初始化函数inet_init中调用inet_register_protosw(将全局结构体数组inetsw_array数组初始化)来实现的,
1: static struct inet_protosw inetsw_array[] = 2: { 3: { 4: .type = SOCK_STREAM, 5: .protocol = IPPROTO_TCP, 6: .prot = &tcp_prot, 7: .ops = &inet_stream_ops, 8: .no_check = 0, 9: .flags = INET_PROTOSW_PERMANENT | 10: INET_PROTOSW_ICSK, 11: }, 12: { 13: .type = SOCK_DGRAM, 14: .protocol = IPPROTO_UDP, 15: .prot = &udp_prot, 16: .ops = &inet_dgram_ops, 17: .no_check = UDP_CSUM_DEFAULT, 18: .flags = INET_PROTOSW_PERMANENT, 19: }, 20: { 21: .type = SOCK_RAW, 22: .protocol = IPPROTO_IP, /* wild card */ 23: .prot = &raw_prot, 24: .ops = &inet_sockraw_ops, 25: .no_check = UDP_CSUM_DEFAULT, 26: .flags = INET_PROTOSW_REUSE, 27: } 28: };很明显可以看到, sock-> ops->ioctl 需要根据具体的协议找到需要调用的ioctl函数。我们就以TCP协议为例,就需要调用 inet_stream_ops 中的ioctl函数——inet_ioctl,结构如下:
1: int inet_ioctl(struct socket *sock, unsigned int cmd, unsigned long arg) 2: { 3: struct sock *sk = sock->sk; 4: int err = 0; 5: struct net *net = sock_net(sk); 6: 7: switch (cmd) { 8: case SIOCGSTAMP: 9: err = sock_get_timestamp(sk, (struct timeval __user *)arg); 10: break; 11: case SIOCGSTAMPNS: 12: err = sock_get_timestampns(sk, (struct timespec __user *)arg); 13: break; 14: case SIOCADDRT: //增加路由 15: case SIOCDELRT: //删除路由 16: case SIOCRTMSG: 17: err = ip_rt_ioctl(net, cmd, (void __user *)arg); //IP路由配置 18: break; 19: case SIOCDARP: //删除ARP项 20: case SIOCGARP: //获取ARP项 21: case SIOCSARP: //创建或者修改ARP项 22: err = arp_ioctl(net, cmd, (void __user *)arg); //ARP配置 23: break; 24: case SIOCGIFADDR: //获取接口地址 25: case SIOCSIFADDR: //设置接口地址 26: case SIOCGIFBRDADDR: //获取广播地址 27: case SIOCSIFBRDADDR: //设置广播地址 28: case SIOCGIFNETMASK: //获取网络掩码 29: case SIOCSIFNETMASK: //设置网络掩码 30: case SIOCGIFDSTADDR: //获取某个接口的点对点地址 31: case SIOCSIFDSTADDR: //设置每个接口的点对点地址 32: case SIOCSIFPFLAGS: 33: case SIOCGIFPFLAGS: 34: case SIOCSIFFLAGS: //设置接口标志 35: err = devinet_ioctl(net, cmd, (void __user *)arg); //网络接口配置相关 36: break; 37: default: 38: if (sk->sk_prot->ioctl) 39: err = sk->sk_prot->ioctl(sk, cmd, arg); 40: else 41: err = -ENOIOCTLCMD; 42: break; 43: } 44: return err; 45: }
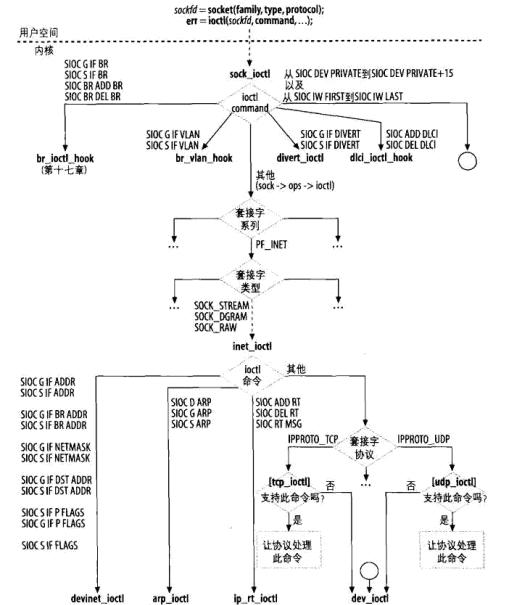
图:ioctl命令的分派
netlink 套接字
netlink已经成为用户空间与内核的IP网络配置之间的首选接口,同时它也可以作为内核内部与多个用户空间进程之间的消息传输系统.
在实现netlink用于内核空间与用户空间之间的通信时,用户空间的创建方法和一般的套接字的创建使用类似,但内核的创建方法则有所不同,
下图是netlink实现此类通信时的创建过程:

下面分别详细介绍内核空间与用户空间在实现此类通信时的创建方法:
● 用户空间:
创建流程大体如下:
① 创建socket套接字
② 调用bind函数完成地址的绑定,不过同通常意义下server端的绑定还是存在一定的差别的,server端通常绑定某个端口或者地址,而此处的绑定则是 将 socket 套接口与本进程的 pid 进行绑定 ;
③ 通过sendto或者sendmsg函数发送消息;
④ 通过recvfrom或者rcvmsg函数接受消息。
【说明】
◆ netlink对应的协议簇是AF_NETLINK,协议类型可以是自定义的类型,也可以是内核预定义的类型;
1: #define NETLINK_ROUTE 0 /* Routing/device hook */ 2: #define NETLINK_UNUSED 1 /* Unused number */ 3: #define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */ 4: #define NETLINK_FIREWALL 3 /* Firewalling hook */ 5: #define NETLINK_INET_DIAG 4 /* INET socket monitoring */ 6: #define NETLINK_NFLOG 5 /* netfilter/iptables ULOG */ 7: #define NETLINK_XFRM 6 /* ipsec */ 8: #define NETLINK_SELINUX 7 /* SELinux event notifications */ 9: #define NETLINK_ISCSI 8 /* Open-iSCSI */ 10: #define NETLINK_AUDIT 9 /* auditing */ 11: #define NETLINK_FIB_LOOKUP 10 12: #define NETLINK_CONNECTOR 11 13: #define NETLINK_NETFILTER 12 /* netfilter subsystem */ 14: #define NETLINK_IP6_FW 13 15: #define NETLINK_DNRTMSG 14 /* DECnet routing messages */ 16: #define NETLINK_KOBJECT_UEVENT 15 /* Kernel messages to userspace */ 17: #define NETLINK_GENERIC 16 18: /* leave room for NETLINK_DM (DM Events) */ 19: #define NETLINK_SCSITRANSPORT 18 /* SCSI Transports */ 20: #define NETLINK_ECRYPTFS 19 21: 22: /* 如下这个类型是UTM组新增使用 */ 23: #define NETLINK_UTM_BLOCK 20 /* UTM block ip to userspace */ 24: #define NETLINK_AV_PROXY 21 /* av proxy */ 25: #define NETLINK_KURL 22 /*for commtouch*/ 26: 27: #define MAX_LINKS 32上面是内核预定义的20种类型,当然也可以自定义一些。
◆ 前面说过,netlink处的绑定有着自己的特殊性,其需要绑定的协议地址可用以下结构来描述:
1: struct sockaddr_nl { 2: sa_family_t nl_family; /* AF_NETLINK */ 3: unsigned short nl_pad; /* zero */ 4: __u32 nl_pid; /* port ID */ 5: __u32 nl_groups; /* multicast groups mask */ 6: };其中成员nl_family为AF_NETLINK,nl_pad当前未使用,需设置为0,成员nl_pid为 接收或发送消息的进程的 ID ,如果希望内核处理消息或多播消息,
就把该字段设置为 0,否则设置为处理消息的进程 ID.,不过在此特别需要说明的是,此处是以进程为单位,倘若进程存在多个线程,那在与netlink通信的过程中如何准确找到对方线程呢?
此时nl_pid可以这样表示:
1: pthread_self() << 16 | getpid()pthread_self函数是用来获取线程ID,总之能够区分各自线程目的即可。 成员 nl_groups 用于指定多播组 ,bind 函数用于把调用进程加入到该字段指定的多播组, 如果设置为 0 ,表示调用者不加入任何多播组 。
◆ 通过netlink发送的消息结构:
1: struct nlmsghdr { 2: __u32 nlmsg_len; /* Length of message including header */ 3: __u16 nlmsg_type; /* Message content */ 4: __u16 nlmsg_flags; /* Additional flags */ 5: __u32 nlmsg_seq; /* Sequence number */ 6: __u32 nlmsg_pid; /* Sending process port ID */ 7: };其中nlmsg_len指的是消息长度,nlmsg_type指的是消息类型,用户可以自己定义。字段nlmsg_flags 用于设置消息标志,对于一般的使用,用户把它设置为0 就可以,
只是一些高级应用(如netfilter 和路由daemon 需要它进行一些复杂的操作), 字段 nlmsg_seq 和 nlmsg_pid 用于应用追踪消息,前者表示顺序号,后者为消息来源进程 ID 。
● 内核空间:
内核空间主要完成以下三方面的工作:
① 创建netlinksocket,并注册回调函数,注册函数将会在有消息到达netlinksocket时会执行;
② 根据用户请求类型,处理用户空间的数据;
③ 将数据发送回用户。
【说明】
◆ netlink中利用netlink_kernel_create函数创建一个netlink socket.
1: extern struct sock *netlink_kernel_create(struct net *net, 2: int unit,unsigned int groups, 3: void (*input)(struct sk_buff *skb), 4: struct mutex *cb_mutex, 5: struct module *module);net字段指的是网络的命名空间,一般用&init_net替代; unit 字段实质是 netlink 协议类型,值得注意的是,此值一定要与用户空间创建 socket 时的第三个参数值保持一致 ;
groups字段指的是socket的组名,一般置为0即可;input字段是回调函数,当netlink收到消息时会被触发;cb_mutex一般置为NULL;module一般置为THIS_MODULE宏。
◆ netlink是通过调用API函数netlink_unicast或者netlink_broadcast将数据返回给用户的.
1: int netlink_unicast(struct sock *ssk, struct sk_buff *skb,u32 pid, int nonblock)ssk字段正是由netlink_kernel_create函数所返回的socket;参数skb指向的是socket缓存, 它的 data 字段用来指向要发送的 netlink 消息结构 ; 参数 pid 为接收消息进程的 pid ,
参数 nonblock 表示该函数是否为非阻塞,如果为 1 ,该函数将在没有接收缓存可利用时立即返回,而如果为 0 ,该函数在没有接收缓存可利用时睡眠 。
【引申】内核发送的netlink消息是通过struct sk_buffer结构来管理的,即socket缓存,linux/netlink.h中定义了
1: #define NETLINK_CB(skb) (*(struct netlink_skb_parms*)&((skb)->cb))来方便消息的地址设置。
1: struct netlink_skb_parms { 2: struct ucred creds; /* Skb credentials */ 3: __u32 pid; 4: __u32 dst_group; 5: kernel_cap_t eff_cap; 6: __u32 loginuid; /* Login (audit) uid */ 7: __u32 sessionid; /* Session id (audit) */ 8: __u32 sid; /* SELinux security id */ 9: };其中pid指的是发送者的进程ID,如:
1: NETLINK_CB(skb).pid = 0; /*from kernel */◆ netlink API函数sock_release可以用来释放所创建的socket.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号