20199114 《网络攻防实践》 综合实践
- 1 实验目的
- 2 论文内容及论文原理
- 3 论文优缺点分析
- 4论文研究方向分析
- 5论文重现
- 5.1 环境的准备
- 5.2 环境搭建
* 5.2.1 ubuntu配置
* 5.2.2 llvm+clang配置
* 5.2.3 libpng和zlib安装 - 5.3 perf fuzz和AFL搭建
- 5.4 perf fuzz工作原理
* 5.4.1 AFL原理
* 5.4.2 插桩原理
* 5.4.3 llvm 模式
* 5.4.4 fuzzing 策略 - 5.5 perf fuzz实践
* 5.5.1 perf fuzz和AFL对插入排序进行算法脆弱性漏洞检测
* 5.5.2 perf fuzz和AFL在微基准libxml2进行程序漏洞检测
* 5.5.3 perf fuzz在自己程序上进行程序漏洞检测
- 6实验思考
- 7 学习总结和建议意见
1 实验目的
本实验目的是通过实践,巩固所学有关渗透挖掘的相关理论知识,以Fuzing技术中发掘C语言程序中存在的一些漏洞,寻找出软件中的性能问题。 通过对这些漏洞的探索,来了解程序的设计和运行的具体机制;同时也从这个实验得到相关的经验教训,为今后渗透测试相关方面的学习打下基础。
1.1论文选择
本次实践用到的论文: PerfFuzz: Automatically Generating Pathological Inputs是2018年发表在ISSTA一篇有关fuzzing技术的文章,并且是该年度的最佳论文(见图1-1)。 其提出了一种全新的自动形成程序最坏输入的方法PerfFuzzing,无需任何领域知识就可以利用输入在程序上进行病理行为测试。
论文的作者均来自美国加州大学伯克利分校,分别为Caroline Lemieux,Rohan Padhye,Koushik Sen,Dawn Song。
图1-1 ISSTA 年度最佳论文
1.2 论文的背景及意义
随着信息科技革命热潮在全球的快速兴起, 信息技术已经影响到个人、社会和国家的方方面面。与此同时, 各种安全事件也层出不穷, 成为全世界面临的主要问题之一。攻击者借助某个漏洞肆意地传播恶意病毒和文件, 漏洞所导致的蠕虫、网马、僵尸网络 等各种网络攻击事件给世界各国的社会和经济带来严重危害。
而软件中的性能漏洞问题是众所周知的难以检测和修复。意外的性能问题会导致严重的项目故障,并造成麻烦的安全问题。例如,DoS(拒绝服务)会攻击目标算法复杂性漏洞,当出现最坏情况下的输入时,将导致运行程序耗尽计算资源。更进一步的软件缺陷会导致软件运行时出现一些设计时的非预期行为,非但不能完成预期的功能,反而会出现意料之外的执行状况。这种预期之外的行为轻则会损害程序的预期功能,重则会导致程序崩溃而不能正常运行,更为严重的情况下,与安全相关的程序缺陷可以被恶意程序利用,使程序宿主机器受到侵害,以至于泄露与程序本身完全无关的信息,如银行账号等私密数据。
因此软件测试、漏洞挖掘和漏洞分析等在信息安全领域具有重大的理论研究意义和实际应用价值。
1.3 论文研究现状
目前大量的研究集中在通过观察或统计分析动态收集的性能剖面来诊断性能问题。已有的检测性能问题的研究大多数假设已有一定规模的输入来执行候选程序以进行性能分析。这些输入来源包括:
- 人工编写的性能测试,
- Benchmark
- 在使用过程中常用的输入,
- 用户遇到性能问题发送的输入。
这些输入源要么只强调平均情况下的行为且受到人为偏见和错误的影响,要么只能在损害已经发生时才能获得。
而一种对开发人员在缓解这些问题方面有用的特定类型的输入是Pathological inputs(病理输入)。 Pathological inputs是那些在程序的不同组件中造成最坏算法复杂度的输入。
还有一种发现软件错误的测试技术为fuzzing test,其优点为
1. 其测试目标是二进制可执行代码,比基于源代码的白盒测试方法适用范围更广泛;
2. Fuzzing是动态实际执行的,不存在静态分析技术中存在的大量的误报问题;
3. Fuzzing原理简单,没有大量的理论推导和公式计算,不存在符号执行技术中的路径状态爆炸问题;
4. Fuzzing自动化程度高,无须在逆向工程过程中大量的人工参与。这篇论文则根据了病理输入和fuzzing技术这一概念,提出了一种自动生成病理输入的方法Perf Fuzz,其不需要任何关于程序的领域知识。
1.4 论文研究方法
通过四个常用于fuzzing的C程序来测试PerfFuzz在中发现hot spots(热点)的能力。并且从宏基准和微基准两个层面来评估Perf Fuzz。这两个层面评估的过程还采用了与其他工具对比,分别是传统基于覆盖率的fuzzing工具--AFL和有相似的反馈导向的fuzzing工具--SlowFuzz,进而证明Perf Fuzz的优越。
1.5 论文主要贡献
(1)提出了Perf Fuzz,一种用于在各种程序组件中锻炼Pathological inputs的算法。并发布Perf Fuzz作为开源工具。
(2)在产生Pathological inputs的效果方面与传统的覆盖引导模糊工具AFL进行了比较。
(3)在产生Pathological inputs的效果方面与具有相似的反馈导向的fuzzing工具SlowFuzz进行了比较。
(4)人工分析PERFFUZZ发现的hot spots,并描述各种不同的输入特征如何影响不同的系统组件。
2 论文内容及论文原理
2.1 概述
首先对具体的程序进行静态分析(如图2-1),其主要包含以下几个函数和执行过程:add_word函数(第22-40行)、compute_hash函数(第14-20行)、为该字找到一个现有的条目(第28–37行)、找到这样的条目计数递增(第31行)、没找到将创建一个计数为1的新条目(第39行)。
,程序将花费它的大部分时间都在compute_hash函数中。2.如果输入包含许多不同的单词(例如来自服务器日志的电子邮件地址),则固定大小的hashtable中的hash冲突频率会急剧增加。对于这样的输入,该程序将大部分时间花费在函数add_word中,遍历循环中第28-37行的条目链表。
2.2 Perf Fuzzing 算法
算法概念:Perf Fuzzing算法是基于覆盖引导的灰盒AFL算法改进的。
算法目标: 生成与某些程序组件相关的高性能值的输入。(程序组件简化为CFG edges边缘,执行计数就是他们的值)。同时使各种值最大化来适应不同程序组件:在Malloc语句中分配的字节数、字节数;内存加载/存储指令中的缓存丢失或页面故障;跨系统组件的I/O操作数量等。
2.2.1算法流程
如图2-2。
(1)用给定的种子输入初始化一组输入,称为父输入。
(2)从父输入中选择一个输入,使某些CFG边缘的执行计数最大化。
(3)从选择的父输入中,通过执行一个或多个随机突变生成更多的输入,称为子输入。这些突变包括随机翻转输入字节,插入或删除字节序列,或在父输入集中提取另一个输入的随机部分,并将其拼接在父输入中的随机选择的位置。
(4)对于每个子输入,运行测试程序并收集每个CFG边缘的执行计数。 如果子程序执行某些边缘的次数超过到目前为止看到的任何其他输入(即它使该边缘的执行计数最大化),那么将其添加到父输入的集合中。
(5)从步骤2重复,直到达到时限。
。 这些种子输入用于初始化一组父输入,表示为P(第1行)。集合中p是产生新突变输入的基础。Perf Fuzz然后考虑集合中的每个输入p(第4行)和一定的概率选择其是否进行突变。对于当前受青睐可以最大化性能值的输入,选择概率为1,否则为就降低概率。 每次选择父输入进行模糊处理时,Perf Fuzz都会生成的多个新子输入(第6行)。 它通过改变所选的父输入突变(第7行)生成这些子句。 产生的子输入的数量和用于产生它们的突变操作和AFL是一样的。然后,PERF FUZZ使用每个新生成的子输入执行正在测试的程序(第8行)。 在执行过程中,Perf Fuzz收集反馈,其中包括代码覆盖信息(例如执行了哪些CFG边缘)以及与感兴趣的 程序组件相关的值(例如每个CFG边缘执行了多少次)。 如果执行导致新的代码覆盖(NewCov)或如果它使某些组件的值最大化(NewMax),则相应的输入被添加到用于未来的Parent 输入集(第10行)。 探索新的覆盖是探索不同的程序行为的关键,要最大化的程序组件、性能值而不仅仅是CFG边缘及其命中计数。
2.2.3算法中的定义
定义1: 性能图 : K → V, 其中K是与程序组件相对应的一组键,V是与性能相对应的一组有序值。K一般小于V。
定义2: 求对于某个program components的执行次数最大值。
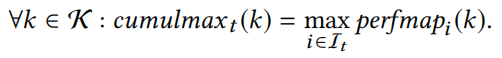
定义3: 这个时间点的输入i的执行次数大于之前所有执行次数的最大值。这个输入i让程序执行了更多次,更可能引发性能问题。
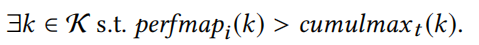
定义4: 输入i最大化组件k性能值当且仅当性能属性注册了目前观测到的最大值:
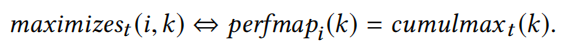
定义5: 输入i使某个组件K\mathcal{K}K的执行次数达到最大。
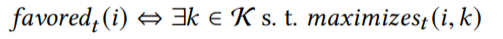
定义6: 子集选择概率

定义7: maximum path length是所有输入经过的最长执行路径:
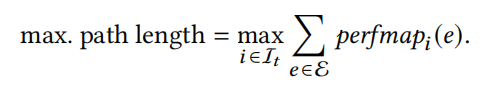
定义8: maximum hot spot是控制流图的边中执行次数最多的边的执行数:
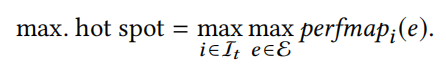
2.2.4算法其他细节
Perf Fuzz是建立在American Fuzzy Lop(AFL)之上的,这是一种最先进的覆盖引导突变模糊技术。因此,许多实现细节都是从AFL继承的。
子输入方法: Perf Fuzz使用了与AFL相同的启发式输入,这些启发式方法包括为具有更广泛代码覆盖的输入可以生成更多的子类型。
突变输入: 在我们的评估中,PerfFuzz只执行havoc(破坏)突变,其工作如下:
在随机位置的位/字节翻转;在随机位置将字节设置为随机或有趣(0,MAX_INT) 值;字节块的删除/克隆;交叉突变(只有当PERF FUZZ最近没有发现新的覆盖范围或最大化输入时,这个阶段才会运行)。
新的计划覆盖范围: Perf Fuzz保存具有新最大值(定义3)的输入和实现新代码覆盖的输入。Perf Fuzz使用了相同的AFL的新代码覆盖定义。AFL将仪器插入到程序中,该程序为程序的控制流图(CFG)中的每个边缘分配一个伪唯一ID。在程序执行过程中,仪器使用8位计数器来跟踪每个CFG边缘被遍历的次数。 AFL将每个CFG边缘的命中次数简化为8个桶中的一个:1次,2次,3次,4-7次,8-15次,16-31次,32-127次,或128-255次。然后,如果输入有访问一个新的CFG边缘,或者击中一个已知的CFG边缘一个新的桶数次,则有新的覆盖范围。但是Pref Fuzz中新的覆盖范围不代表最大的边缘执行次数,反之亦然。
性能图: 对于每个e,perfmap表示为当输入i时,程序执行e的总次数。把每个e执行次数求和计算总路径长度,若很长则同时保存对应的输入i。
2.2.5 算法评估
选择四个现实世界大小不同的C程序作为主要评估的基准:
(1)libpng-1.6.34,
(2)libjpeg-turbo-1.5.3,
(3)zlib-1.2.11,
(4)libxml2-2.9.7。
对于这些基准,文章在500字节的最大文件大小上运行 Perf Fuzz(以及与之比较的工具)6小时(们重复运行20次,以考虑结果的可变性)。
对于发现最坏情况下不同输入大小的最坏算法复杂性的函数评估(第5.1.2节),使用了三个微基准:
(1)插入排序(因为它是作为slow Fuzz存储库中的默认示例提供的),
(2)使用PCRE库将输入字符串匹配到URL Regex,
(3)WF-0.41,一个简单的字频计数工具,在FeodraLinux存储库中找到。
2.3 与slow fuzz对比
2.3.1 主要区别
slow Fuzz是一种模糊测试工具,其主要目标是产生输入触发算法复杂性漏洞。与Perf Fuzz一样,slow Fuzz也是C/C++程序的输入格式不可知的Fuzzing工具。
区别1: 在于slow Fuzz的目标是一维的,他只是最大化程序的总执行路径长度。因此,可以与基于覆盖导向的多目标最大化的PerfFuzz进行很好地对比。
区别2: Perf Fuzz从一个选定的父输入产生许多(通常至少数千,通常是数万)输入。Slow Fuzz反而为每个亲本产生一个突变体。前者将输入优先排序然后fuzz,但slow Fuzz随机选择父输入然后fuzz。
区别3: Perf Fuzz将AFL的havoc应用于输入。slow Fuzz了解哪些突变在过去成功地产生有效输入,并更经常地应用这些突变。
2.3.2 比较方法
文章在两个方面比较了Perf Fuzz和slow Fuzz。
- 在上述四个宏观基准上评估Perf Fuzz和slow Fuzz的能力:最大限度地提高总执行路径长度以及最大热点。
- 文章比较了Perf Fuzz和slow Fuzz在微基准中找到显示最坏情况下算法复杂性的输入的能力,这些微基准已知具有最坏情况的二次复杂度。
2.3.3 运行结果
最大化执行次数:
图2-3显示了Perf Fuzz和slow Fuzz在6小时运行中在最大化总路径长度(左边)和最大热点(右边)方面取得的进展。 图中的线条表示平均值超过20,而阴影区域代表95%的置信区间,用t分布计算(用于根据小样本来估计呈正态分布且方差未知的总体的均值)。

图2-3 Perf Fuzz vs. SlowFuzz在宏基准对比
从图中可以清楚地看出,Perf Fuzz始终找到在两个评估指标上优于slow Fuzz的输入。 最大路径长度PerfFuzz是slow Fuzz的1.9到24.7倍,最大热点则高5到69倍。尽管事实上,slow Fuzz产生更多的输入(libxml上快1.7倍,libjpeg上快17.7倍),结果表明在寻找热点方面perf fuzz更快,甚至超越了slow fuzz擅长的找最大热点。
算法复杂性漏洞
考虑了三个微基准:
(1)8位整数数组上的插入排 序,这是slow Fuzz库中提供的唯一基准;
(2)将输入字符串与正则表达式匹配以使用PCRE库验证URL;
(3)WF-0.41,来自Fedora Linux存储库的字频计数程序。
每个微基准都在平均情况下的运行时间复杂度和输入的大小上是线性相关的,最坏情况下的复杂度是二次的。
对于这些基准中的每一个,我们将输入大小的上限在10到60个字节之间变化,间隔为10字节。然后在微基准上运行每个工具,持续时间固定:插入排序 10分钟,PCRE和WF60分钟。对于每个输入长度,我们执行20次运行以考虑可变性。最后,我们测量了在这些运行中产生的所有输入上观察到的最大路径长度。图2-4显示了这些运行的结果:点绘制了平均最大路径长度,而线显示了95%的置信区间。
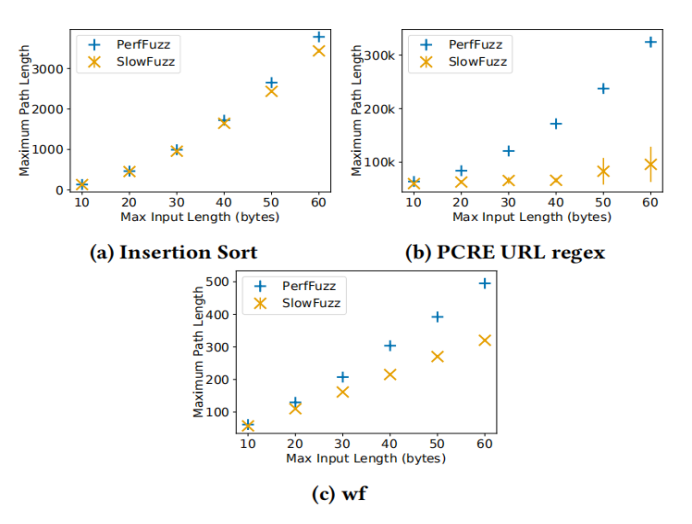
图2-4 Perf Fuzz vs. SlowFuzz在微基准对比
从图中可以看出对于输入长度10和20,Perf Fuzz始终发现最坏的情况, 图a还显示,对于较大的输入大小,Perf Fuzz还需要和Slow Fuzz作更多比较。总的来说,这两个工具都发现了这个基准的最坏情况二次时间复杂度。在图b中,看到了由Perf Fuzz和slow Fuzz在PCRE URL基准上发现的最坏情况输入之间的主要区别。Perf Fuzz发现输入导致最坏情况的二次复杂性,而Slow Fuzz只发现一个轻微的超线性曲线。
一个由PERF FUZZ找到的在50字节运行中具有最大路径长度的输入的例子是:fhftp://ftp://ftp://ftp //f.m.m.m.m.m.m.m.m.m.m
而种子输入是一个空字符串,Perf Fuzz没有提供任何URL语法知识。另一方面,slow Fuzz在自动发现子字符串(如输入字符串中的ftp)方面有困难。可能是因为它的一维目标函数,它不允许它在regex匹配算法中取得增量进展,除非总路径长度增加。
WF是一个更难的基准,因为最坏的行为只有在输入字符串映射中的不同单词触发相同的哈希表桶。Perf Fuzz在给定的时间预算中,输入更接近最坏情况下的时间复杂性。比如找到t <81>v ^?@t <80>!^?@t <80>!t t^Rn t t t t t t t t t,首先,一些哈希桶中插入一个小单词。然后,接下来的几个单词具有完全相同的哈希代码,并插入到该桶中的链表的前面。而slow fuzzing找到的输入就没有这种结构。
总的来说,我们看到,在相同的时间约束下,PerfFuzz能够找到比slow Fuzz更长的路径的输入,并且在发现接近最坏情况下的算法复杂度的输入方面优于slow Fuzz。
2.3.4 结果分析
贪婪的方法来最大化总路径长度很可能被卡在局部极大值中。相反,PerfFuzz保存新生成的输入,即使总路径长度低于到目前为止发现的最大值,只要某些CFG边缘的执行计数增加。因此,PerfFuzz的多维目标允许它更好地实现总路径
长度的全局最大化。
2.4 与基于覆盖指导的AFL比较
2.4.1 主要区别
PERF FUZZ是基于AFL的,但是两者之间最大的不同为PERF FUZZ是多目标的,也就是不仅仅关注于代码覆盖率还关注他所提出的NewMax。
2.4.2 比较方法
同之前一样,首先,在上述四个宏观基准上评估Perf Fuzz和AFL的能力:执行CFG边缘的最大数以及最大热点。
2.4.3 运行结果
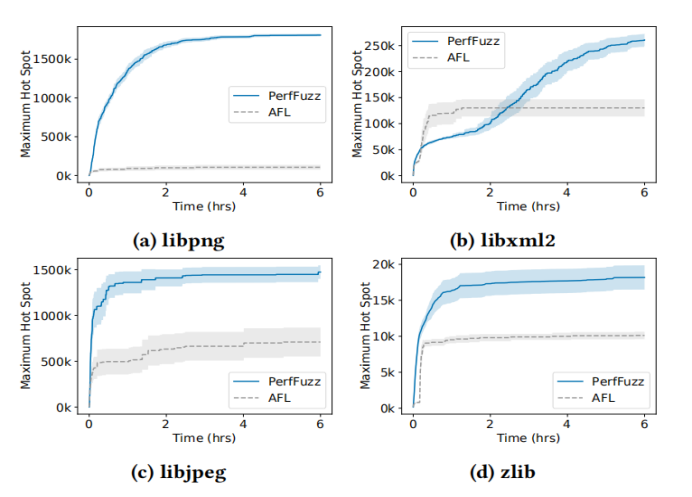
图2-5 Perf Fuzz vs. AFL在宏基准找到最大热点对比
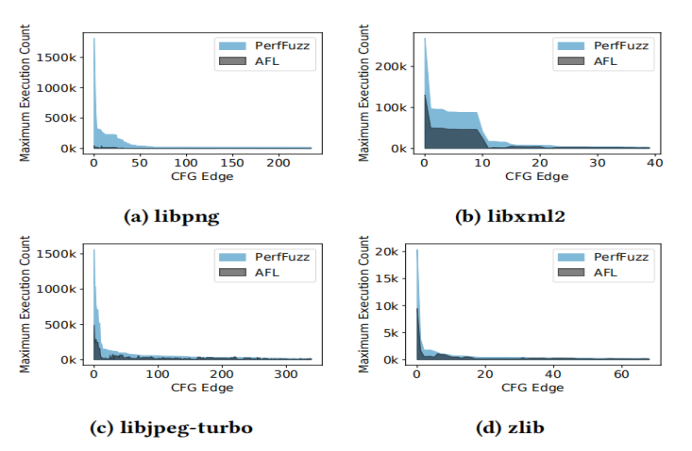
图2-6 Perf Fuzz vs. AFL在宏基准找到最大边缘执行次数对比
2.4.3 结果分析
如图2-5所示。
- 在 libpng、libjpeg-turbo和zlib基准, Perf Fuzz迅速找到了一个执行计数显著较高的热点。
- 对于libxml2基准,AFL最初发现一个执行量较高的热点,但很快就会出现停滞另一方面,PERF FUZZ发现了一个热点,在6小时后执行次数超过之前2倍。总的来说,图2-4表明,PerfFuzz的性能图反馈对其产生病理输入的能力有显著的影响,最大热点有2到18倍的执行次数。
特别是,图2-6显示了PerfFuzz在程序中的所有热点上发现的最大执行计数高于AFL发现的最大执行计数。我们在20次重复运行中绘制了这个度量的中位数。 为了清晰起见,通过PerfFuzz实现的计数对CFG边缘进行排序,并截断数据,以只显示那些执行计数在PerfFuzz发现的最大热点的2个数量级内的边缘。证实了Perf Fuzz的收益不仅限于程序中的最大热点。在四个基准中,有453条绘制的edges,PerfFuzz生成的输入比AFL生成的输入多2倍的执行,238条边比PerfFuzz生成的输入多10倍的执行。
2.5 个案研究
在四个宏基准上手动分析PerfFuzz生成的输入也就是在每个运行中查看热点所在的位置以及不同的输入特性如何影响这些热点。
在每次运行结束时,Perf Fuzz输出它的一组受欢迎的输入,这些输入至少最大化一个CFG边缘的执行计数以及它最大化的每个CFG边缘的执行计数。图2-7显示了这个输出的一个例子:它是从一次运行的PerfFuzz在libpng基准上得到的结果,显示前3个有利的输入在前3个CFG边缘的执行计数。
图中,可以直接查看源代码的位置,以查看每个输入执行的哪些特性。

图2-7 libpng下不同输入对应的CFG边缘执行次数

图2-8 libpng中不同输入锻炼不同的热点特征
图2-8是pngrutil.c的一个片段,这个代码片段显示了两个不同的热点, 因此,这些热点只能通过不同的输入来执行。如表1所示,对应于单色图像当像素深度为1时,输入#9189最大限度地增加了内环的执行次数(图中第3715行)。另一方面,对于具有16个彩色条目的图像,输入#10520最大限度地执行像素深度为4的内环(图中第3842 行),其他输入强调代码的完全不同部分。例如,表1中的输入#10944使循环中CFG边缘与PNG图像的高度成正比的执行计数最大化。通过快速浏览三个受欢迎的输入, PerfFuzz能够发现一些关键特征,这些特征对独立于文件大小的PNG图像解析性能有影响, 例如在标题中声明的图像的几何尺寸和颜色深度。研究表明,由Perf Fuzz生成的输入导致特殊的热点被发现。表明PerfFuzz成功地产生了针对各种程序功能的输入。
3 论文优缺点分析
3.1 论文优点
论文整体结构严谨,实验逻辑缜密。论文主要优点在于思路非常值得借鉴,引入自定的NewMax参数,虽然perf fuzz技术方面主要是基于AFL技术进行的改进,但是加入了NewMax参数,也就是某个的输入触发某一个CFG组件新的最大化执行次数后。让perf fuzz从AFL单目标(仅仅关注代码覆盖率)变成了多目标(还关注NewMax参数)。也就是某个的输入触发某一个CFG组件新的最大化执行次数后则将此输入也保存下来作为父基因。这种做法虽然相较于AFL看起来变动不大,但是执行起来的效果非常好,突变的输入对程序可以产生显著的影响。比AFL的单目标提升了十几倍的效率,实现了多快好省,这种思路非常值得借鉴。
同时文中测量CFG边缘的执行计数,而不是总运行时间。有助于助于确保测量是准确和确定性的。
3.2 论文缺点
PerfFuzz与许多其他基于遗传算法风格模型的输入生成技术一样,完全依赖启发式产生实现其测试目标的输入,即测试病理程序行为。 结合Perf Fuzz是一种动态技术,这意味着Perf Fuzz不能保证找到程序中的所有热点或它发现的每个热点的绝对最坏情况,只能是相对的。
4论文研究方向分析
方向一: PERF FUZZ的一个重要特征是与相对于以前使用贪婪方法只考虑总路径长度增加的工具slow fuzz对比,它保存了变异的输入即最大化任何CFG边缘的执行计数的输入,即使对某些地方进行了舍弃如突变减少了总执行路径长度。因此利用这个发现可以得到启发尽可能多地保留有必要的输入,如果这些输入达成了新的自定条件,比如将可以引入CFG边缘平均执行次数概念的将平均执行次数多的输入也保存下来形成父亲基因,说不定有奇效,类比作者引入NewMAX参数等,仅仅相对于AFL改变了一点就可以产生更多的有效输入。
方向二: 作者在文中已经发现了不同特征可以测试不同的CFG边缘也就是程序组件,并且文章开头用了一个C程序进行了静态分析。那么能否把这两者结合?也就是先采用静态分析的方法对程序易暴露的瓶颈进行分析,有针对性地对设计输入、减少后期工作量。
方向三: 文章中发现的受青睐的输入都是一些奇怪的字符,正常情况下难以触发的。那么能否将这些受青睐的输入保存下来形成基因库文件,输入进以后相同类型的程序测试,可以让突变时间更少且更有效。
方向四: 能否利用神经网络,比如对GAN神经网络改造。输入是图像类的时候,生成一个和正常输入图像偏差特别大的图像,并进行打分。越偏差大的输入越被青睐。这样的输入放入Perf fuzz或者其他fuzz工具中作为初始输入进一步降低后期突变量,甚至突破局部最优。
5论文重现
5.1 环境的准备
表5.1电脑配置
| 项目 | 内容 |
|---|---|
| 电脑型号 | HP Pavilion Gaming Notebook |
| 电脑系统 | Windows 10家庭中文版 64Bit |
| 电脑CPU | Intel(R)core(TM)i5-6300HQ @2.3GHz |
| 电脑GPU | NVIDIA GeForce GTX 950M// 4G显存 |
| 电脑内存 | Samsung DDR3 1600//8G内存 |
表5.2运行环境及实验工具
| 项目 | 内容 |
|---|---|
| 虚拟机 | VMware 15.5 PRO |
| 虚拟机CPU | 4核@2.3GHz |
| 虚拟机GPU | Samsung DDR3 1600//8G内存 |
| 编程环境 | Python 3.7.5 |
| 运行软件 | Perf fuzz,AFL、Slowfuzz |
| 虚拟化工具 | llvm_mode、qemu_mode |
| 编译器 | gcc9.2.1,clang10.0.1 |
5.2 环境搭建
5.2.1 ubuntu配置
-
首先对ubuntu中软件源进行换源,便于后面更新下载速度更快。(后面确实省事很多)
备份并替换/etc/apt/sources.list的源内容,将原文件做一个备份。
命令:cp /etc/apt/sources.list /etc/apt/sources.list.bak -
更改源文件内容
在终端输入命令:sudo vim /etc/apt/sources.list将清华大学源替换进去
![]()
图5-1 换源结点 -
修改完后还需要更新使其生效:sudo apt-get update
5.2.2 llvm+clang配置
-
首先下载clang/llvm源码
git clone https://gitee.com/wangwenchaonj/llvm-project.git
![]()
图5-2 下载llvm-project -
更新工具链(重点是cmake工具,其是一个跨平台的Makefile 生成工具,之后的perf fuzz代码编译都得靠他)
sudo apt install gcc
sudo apt install g++
sudo apt install make
sudo apt install cmake -
下载完成后(下载慢,大概需要一个小时耐心等待),进入llvm-project文件夹,使用目前clang/llvm最新的稳定发布版本分支进行编译(都是10.0的后缀)。而论文中用的版本是clang3.8已经过于久远,在我的64位Ubuntu上也安装不了,只能安装新的10.0.
cd llvm-project
git checkout release/10.x -
编译安装,千万注意要在当前目录下新建一个文件夹进行编译,不然会编译失败。并且顺带安装了标准库libcxx(绝对要下载)还有libcxxabi(千万不要遗漏):
mkdir build
cd build
cmake -G "Unix Makefiles" -DCMAKE_BUILD_TYPE=Release --enable-optimized --enable-targets=host-only ../llvm -DLLVM_ENABLE_PROJECTS="clang;libcxx;libcxxabi;compiler-rt;clang-tools-extra;openmp;lldb;lld"
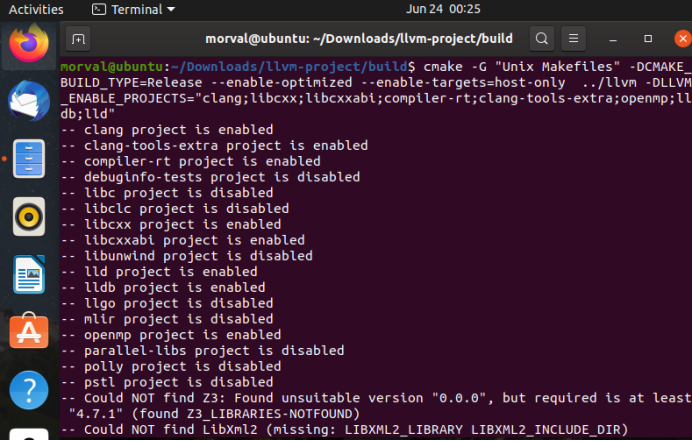
图5-3 cmake编译
- 开始编译,用的两个cpu核心(编译较慢,大概需要三个小时,后面的安装较快一个小时左右)
make -j2
make install
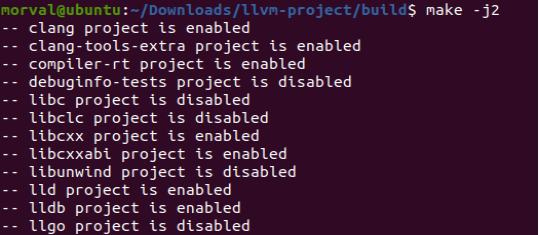
图5-4 make脚本编译

图5-5 安装编译文件
-
输入clang --version,查看安装是否成功
![]()
图5-6 查看clang版本 -
修改编译器为clang/llvm,并将clang,clang++,gcc,g++添加为环境变量。
which clang
which clang++
export CC=/usr/local/bin/clang
export CXX=/usr/local/bin/clang++
export CXXFLAGS=-stdlib=libc++
export CC=/usr/local/bin/gcc
export CXX=/usr/local/bin/g++

5.2.3 libpng和zlib安装
- 下载源码解压wget https://sourceforge.net/projects/libpng/files/zlib/1.2.8/zlib-1.2.8.tar.gz/download -o zlib-1.2.8.tar.gz
- 进行编译 ./configure make make check sudo make install

图5-7 编译zlib
- 在make install这一步,由于要把zlib安装到/usr/local/lib 路径下libz.a是一个静态库,为了使用zlib的接口,我们必须在连接我们的程序时,libz.a链接进来。只需在链接命令后加-lz /usr/llocal/lib/libz.a 即可。
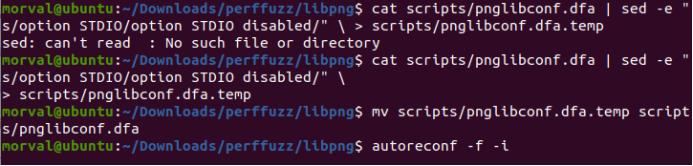
- 编译libpng,tar xzf libpng.tgzcd libpng,禁用CRC检查。
cat scripts/pnglibconf.dfa | sed -e "s/option STDIO/option STDIO disabled/" > scripts/pnglibconf.dfa.temp
mv scripts/pnglibconf.dfa.temp scripts/pnglibconf.dfa
![]()
图5-8 编译libpng - ./configure CC="clang" CFLAGS="$FUZZ_CXXFLAGS",进行编译。
6.afl-clang ./libpng/contrib/gregbook/readpng.c -I ./build/include/libxml2/ -lm -lz -o readpng - 开始fuzz
./afl-fuzz -i
/home/morval/Downloads/perffuzz/dictionaries/png.dict
-o /home/morval/Downloads/perffuzz/libpng/out -x /home/morval/Downloads/perffuzz/testcases/images/png -o read
5.3 perf fuzz和AFL搭建
-
从github上下载perf fuzz源码。
Git clone https://github.com/carolemieux/perffuzz
![]()
图5-9 源码文件 -
在ubuntu机器上构建,运行进行编译。
make -
构建PerfFuzz的检测编译器,运行以下代码就构建好perf fuzz了。
cd llvm_mode
make
cd ..
![]()
图5-10 构建perffuzz

5.4 perf fuzz工作原理
5.4.1 AFL原理
由于peffuzz就是基于AFL的,所以两者的原理是类似的。 其 fuzz 方案如下图所示。在此过程中 AFL 会维护一个语料库队列 queue,包含了初始测试用例及变异后有新状态产生的测试用例,对应的变异操作分为确定性策略和随机性策略两类,而状态的分析,即边界覆盖率的统计工作,需依赖插桩来完成。
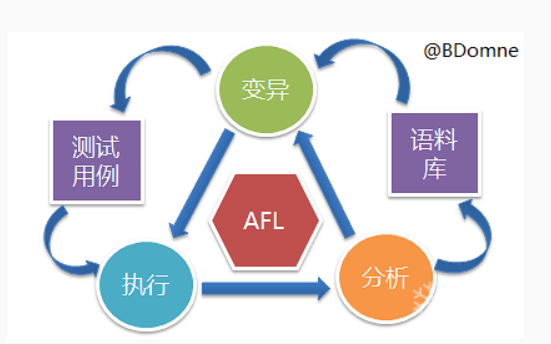
图5-11 AFL运行原理
5.4.2 插桩原理
插桩,它指的是通过注入探针代码来实现程序分析的技术。 接下来我们重点关注什么是新状态,如图 1 所示,蓝色块代表程序执行过程中的基本块,黄色块代表相应的用于统计的探针代码,因而我们可以完整记录程序的执行路径,即:A -> C -> F -> H -> Z。另外,在 AFL 中为了更方便的描述边界(edge),将源基本块和目的基本块的配对组合称为 tuple,即下图路径中有 4 个 tuple(AC,CF,FH,HZ)。通过记录 tuple 信息就可以统计边界覆盖率了。 新的 tuple 出现或已有 tuple 中出现新的命中组则视为产生新状态,相应的测试用例将被归入到语料库中。

图5-12 插桩过程
在 AFL 中一共有三种不同模式的插桩操作,如下图,其中普通模式和 llvm 模式是针对目标程序提供源码的情况,显然相较汇编级的普通模式插桩,编译级的 llvm 模式插桩包含更多优化,在性能上会更佳些,而对仅提供二进制文件的目标程序则需借助 qemu 模式,其性能是最低的。
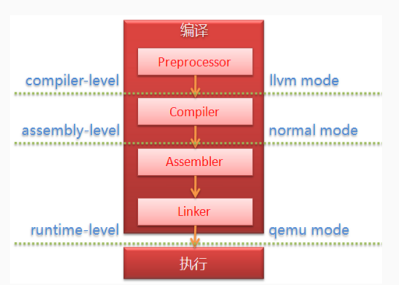
图5-13 插桩技术
5.4.3 llvm 模式
该模式之所以能进行编译级插桩主要还是得益于 LLVM 优秀的架构设计,简言之,代码首先由编译器前端 clang 处理后得到中间代码 IR,再经过各 pass 工作节点的优化和转换,最终交给编译器后端生成机器码:

图5-14 llvm模式
5.4.4 fuzzing 策略
在 AFL 中用到的 fuzzing 策略分为两类,即确定性策略和随机性策略。其中确定性策略又分为位翻转、字节翻转、算术加减、整数替换、字典替换和字典插入, 目的是为了生成更多简洁有效的测试用例,不过由于此类策略比较耗时,因此测试用例只会进行一轮这样的操作。而如果一个测试用例在执行完随机性策略后仍未产生新状态,则会将其与另一测试用例随机拼接后再次交由随机性策略处理如havoc、splicing等等。在perffuzz中只用到havoc突变。
对于各变异操作,基本的处理流程如下:

图5-15 变异处理流程
5.5 perf fuzz实践
5.5.1 perf fuzz和AFL在宏基准插入排序进行算法脆弱性漏洞检测
- 首先编译基准 ./afl-clang-fast insertion-sort.c -o isort

图5-16 编译基准
2. 为PerfFuzz做一些种子。
mkdir isort-seeds
head -c 64 /dev/zero > isort-seeds/zeroes
图5-17 输入种子为zeros
- 运行PerfFuzz,./afl-fuzz -p -i isort-seeds -o isort_perf_test/ -N 64 ./isort @@。跳出afl控制面板。
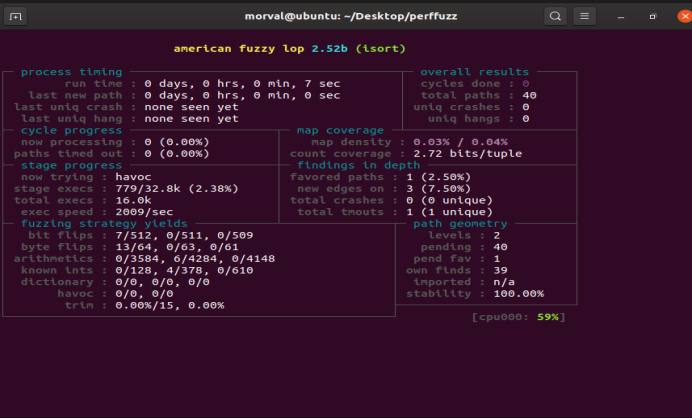
图5-18 运行面板
含义:
① Process timing:Fuzzer运行时长、以及距离最近发现的路径、崩溃和挂起经过了多长时间。
② Overall results:Fuzzer当前状态的概述。(有发现的测试用例(“路径”)数量,独特的错误,可以实时探索测试用例,崩溃和挂起)
③ Cycle progress:我们输入队列的距离。
④ Map coverage:目标二进制文件中的插桩代码所观察到覆盖范围的细节。
⑤ Stage progress:Fuzzer现在正在执行的文件变异策略、执行次数和执行速度。
⑥ Fuzzing strategy yields:关于突变策略产生的最新行为和结果的详细信息。
⑦ Path geometry:有关Fuzzer找到的执行路径的信息。
⑧ CPU load:CPU利用率
4. 运行AFL同样进行插入排序,./afl-fuzz -i isort-seeds -o isort_afl_test/ -N 64 ./isort @@。跳出afl控制面板。
5. 将perffuzz和AFL都运行6个小时,接近实验中的运行时间,并比较插入排序的结果。如下图。
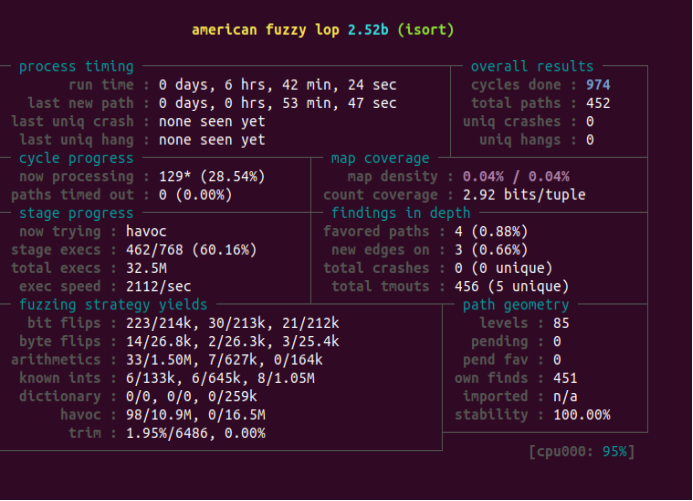
图5-19 perffuzz在插入排序上运行结果
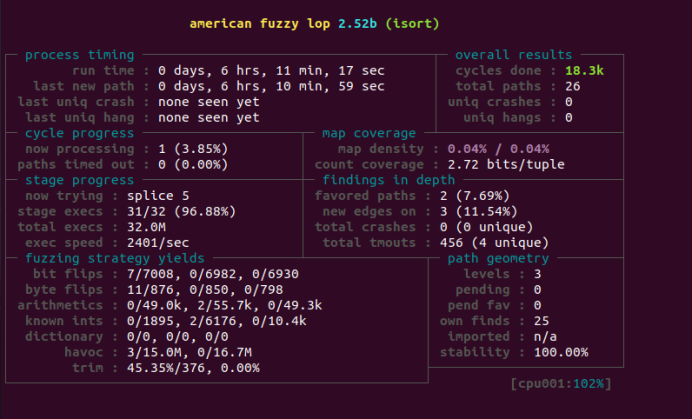
图5-20 AFL在插入排序上运行结果
数量total paths(这是一个不正确的称呼;应该是是保存的输入的数量)持续增加。可以通过运行以下命令来查看已保存的输入是否正在走向最坏的情况。

图5-21 运行输出文件夹
for i in isort_perf_test/queue/id*; do ./isort $i | grep comps; done

图5-22 perffuzz保存的输入
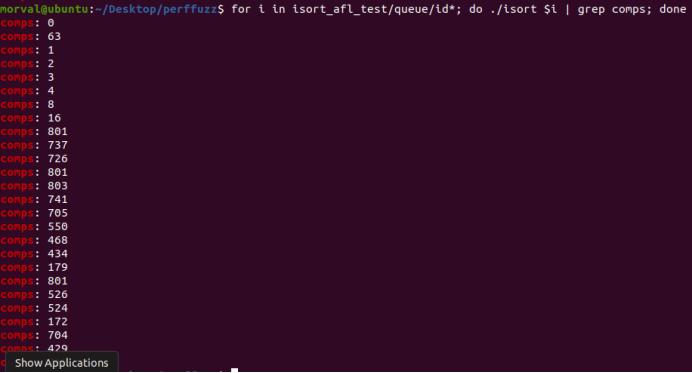
图5-23 AFL保存的输入
仅运行常规afl。total_paths很快看到大约20个左右的峰值,并且周期数增加了很多。对保存的输入进行的比较可能也会少得多。运行时打印的最大比较数:
小于在isort_perf_test/queue。中看到的输入值。
利用自带的afl_plot可以画出图像,afl-plot afl_state_dir graph_output_dir。
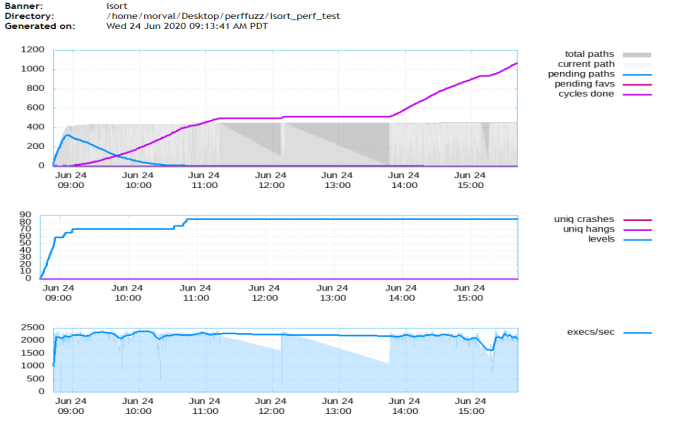
图5-24 perffuzz的运行速度、保存的输入
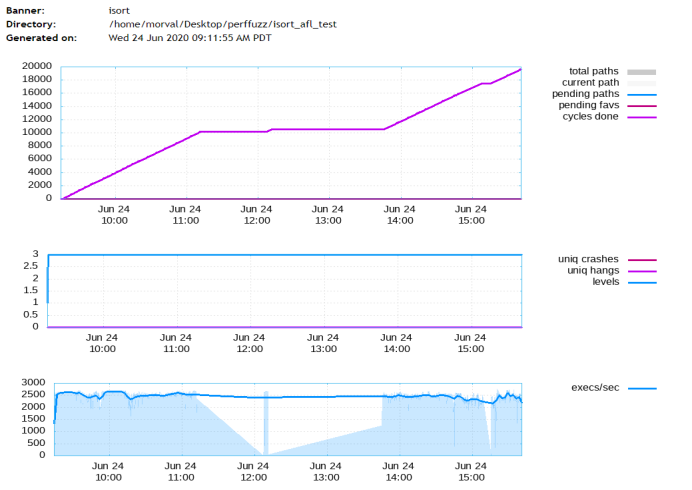
图5-25 AFL的运行速度、保存的输入(总路径长度)
首先是路径覆盖的变化,当pending fav的数量变为零并且total paths数量基本上没有再增长时,说明fuzzer有新发现的可能性就很小了。
5.5.2 perf fuzz和AFL在微基准libxml2进行程序漏洞检测
- 搭建libxml2环境
- 首先安装autoconf ibtool automake 这三个库是libxml2不可缺少的库。

图5-26 安装依赖库
3. https://github.com/Dor1s/libfuzzer-workshop/tree/master/lessons/08上下载libxml2源代码。解压。
tar xvf libxml2.tgz cd libxml2
4. 配置编译器CC=/home/morval/Downloads/perffuzz/afl-clang-fast CXX=/home/morval/Downloads/perffuzz/afl-clang-fast++
图5-27 配置编译器
5. 编译脚本./autogen.sh CC=/home/morval/Downloads/perffuzz/afl-clang-fast CXX=/home/morval/Downloads/perffuzz/afl-clang-fast++ --prefix=/home/morval/Downloads/perffuzz/libxml2/build/ --with-python-install-dir=/home/morval/Downloads/perffuzz/libxml2/build/
6. 编写测试程序harness.c

图5-28 harness.c
-
开始插桩,AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I ./build/include/libxml2/ -L ./build/lib -lxml2 -lz -lm -o harness。
![]()
图5-29 插桩 -
运行,创建一个初始的flie(in)文件(论文中未给出初始文件,所以是自己设定的),输出结果为out。
echo 111 > in/1
afl-fuzz -m none -i in -o out -x /home/morval/Downloads/perffuzz/dictionaries/xml.dict ./harness @@ -
值得注意运行过程会有很多错误,比如静态库衔接网上也不一定能找到解决办法,那就只能自己写代码的。
-
开始编译程序。
![]()
图5-30 插桩 -
Perfuzz程序输出。
![]()
图5-31 perffuzz -
AFL程序输出。
![]()
图5-32 AFL输出 -
运行6个小时后,输出结果对比。
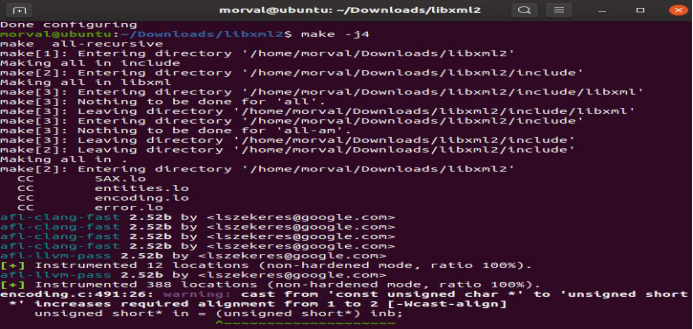


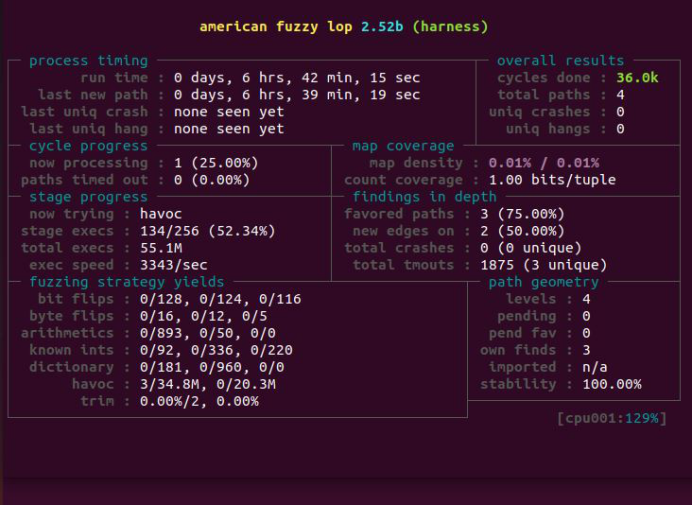
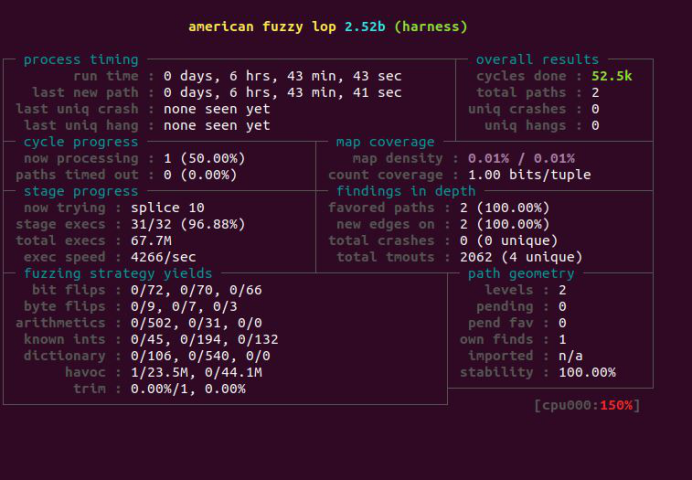
图5-33 输出结果对比
- 画出图像进行对比。
afl-plot afl_state_dir graph_output_dir。
![]()
图5-34 图像输出代码
![]()
图5-35 Perffuzz图像输出
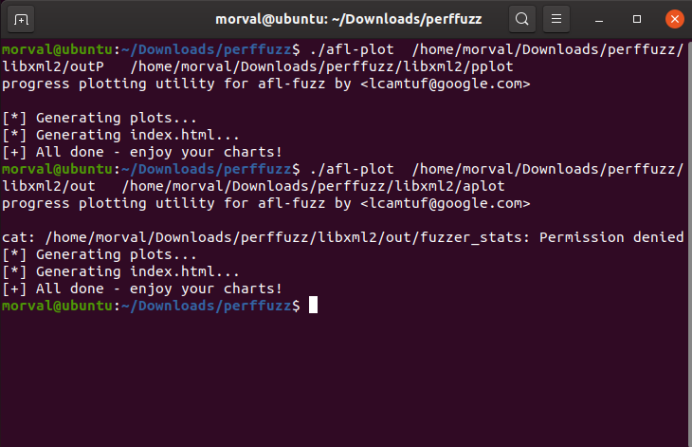
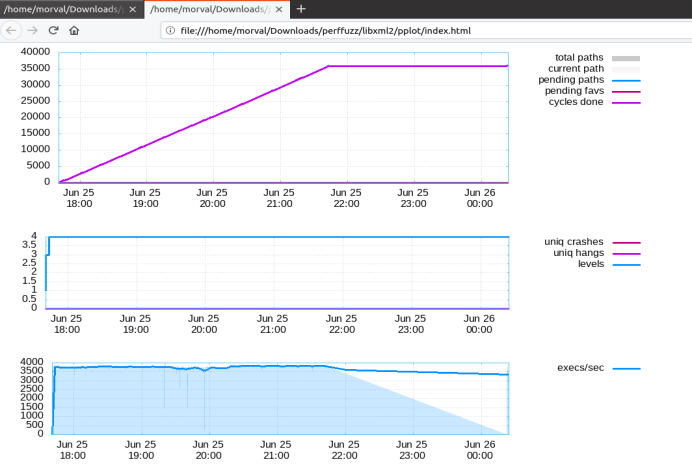
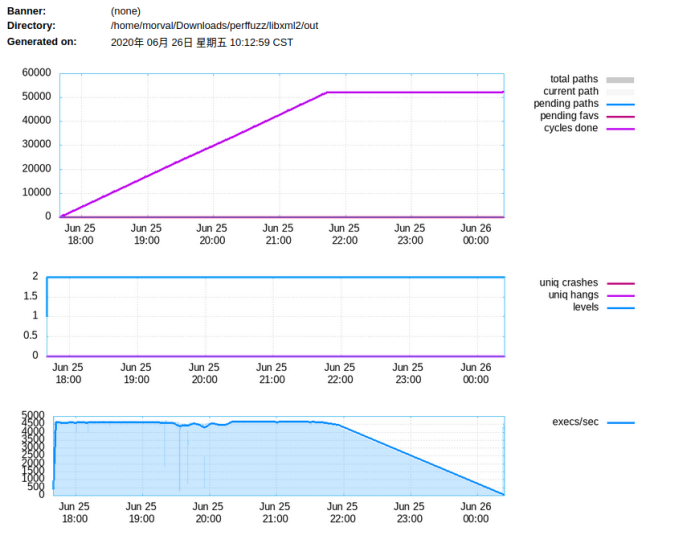
图5-36 AFL图像输出
5.5.3 perf fuzz在自己程序上进行程序漏洞检测
-
自己编写一个简单的字符输入C程序。
![]()
图5-37 test.c -
利用./afl-clang-fast test.c -o test进行插桩。
![]()
图5-38 插桩 -
创建一个文件,这里用论文中给出的例子the quick brown fox jumps over the lazy dog。在perffuzz目录下生成testcase文件夹。
![]()
图5-39 输入语句 -
Perffuzz开始运行,编译器选择clang-fast, ./afl-fuzz -p -i testcase -o output/perffuzz ./test @@
![]()
图5-40 开始编译
中间需要代码将处理的指令不发送到系统日志存到本地。
开始运行才6秒就找到了一个crash输入确实很快了。
![]()
图5-41 Perffuzz运行 -
AFL开始运行, ./afl-fuzzt -i testcase -o output/perffuzz ./test @@,可以看到AFL运行时间比Perffuzz长,循环次数多但是也未能找到crash输入。
![]()
图5-42 AFL运行
两者运行半小时后结果
![]()
图5-43 Perffuzz运行半小时
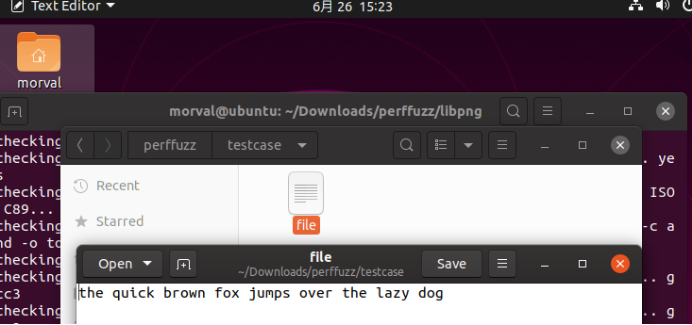


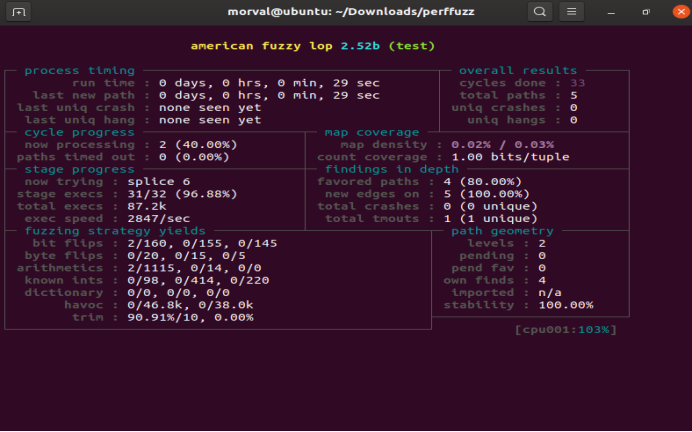
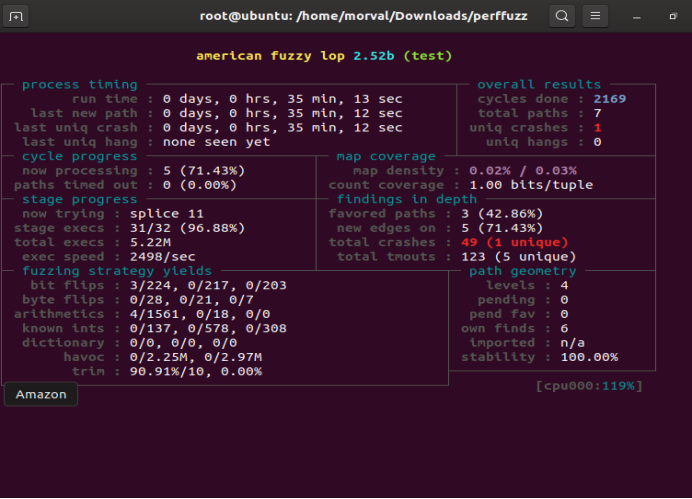
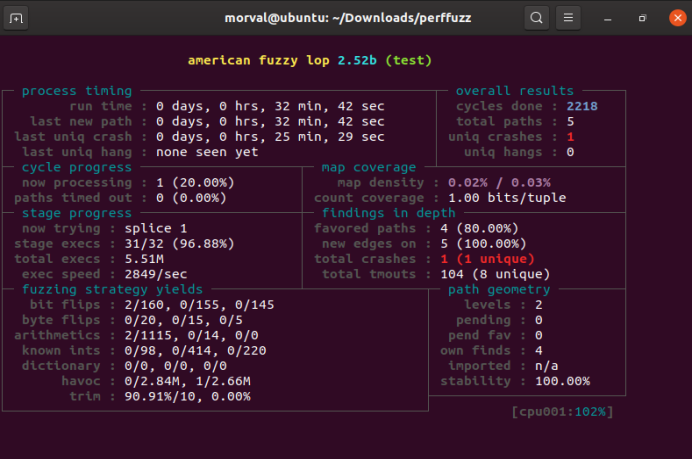
图5-44 AFL运行半小时
6. 明显可以看出perffuzz在寻找病理输入方面速度更快。利用plot生成图表。
7. ./afl-plot /home/morval/Downloads/perffuzz/output/perffuzz/ /home/morval/Downloads/perffuzz/output/perffuzz/plot

图5-45 perffuzz运行半小时输出图
8. ./afl-plot /home/morval/Downloads/perffuzz/output/af/ /home/morval/Downloads/perffuzz/output/afl/plot

图5-46 AFL运行半小时输出图
6实验思考
6.1 实验总结
通过以上的实验对比可以大致看出论文中的思想,结论也是相符合的,perffuzz确实能够在运行更少循环的过程中,产生更多的有利输入,重现验证了文中结论。 探索一个全新的领域,需要了解的不仅仅是论文上的知识,还需要在额外查很多资料。论文中一共12页的内容,看起来费劲做起来也麻烦。这次实验做了很多时间,论文中也没有给出具体的测试代码,实践中间还遇到了各种错误。实验难度很大,成功构建Perffuzz和AFL两个环境,也尝试了构建slowfuzz但是相关文献太少,构建的时候,遇到的问题很多,比如编译过程代码系统崩溃、卡死、库文件找不到等等。 百度、google也解决不了,只能自己啃基层的知识多学习多看。虽然累但是收获也是不少的,最重要的就是学会了如何利用工具对程序进行渗透测试,并且可以自己编写一部分渗透代码。同时对于底层的知识了解了很多,不断找出错误原因的过程也就是不断学习的过程,收获还是很多的。
6.2 实验中遇到的问题
这次实验中遇到了很多问题,这里仅仅选一些有意义且记忆深刻的问题。
问题一: ubuntu系统中apt-get速度慢?
问题一解答: 更换清华/others镜像源。
问题二: cmake编译出偏差?
问题二解答: 由于更换镜像源工具包可能不全或者不是最新,比如Cmake只有3.10.* 版本,最新版本是3.14.* 差别大,在后期编译中不知不觉就造成了问题。
问题三: 安装llvm和clang,编译时间过长且出错?
问题三解答: 安装llvm和clang时一定要注意自己虚拟机用的几核心处理器。Make -j* 不能超过自己核心线程数,否则就容易编译中断且多次开始后容易编译报错。只能清除前面数据,花费几个小时再次编译。
问题四: 经常出现collect2:ld returned 1 exit status
问题四解答: 主要有这几种原因
- 编译成功的例子在后台执行,有时一闪而过,如果再次build ,则会提示上述错误。
解决方法:直接关闭对应进程或者关机。 - 没有编译成功的情况下,最常见情况是程序本身需要include的头文件被遗漏了
解决方法:细心查找基类所用的头文件,include之后即可。 - .h文件中相关的函数在cpp文件中没有定义,或者说函数的声明(.h中)与定义(.cpp中)不一致
解决方法: 查找遗漏的函数,根据需要,具体的定义。将函数名修改一致。
问题五: 安装zlib和libpng过程中虚拟机重启打不开,运行命令报错。
问题五解答:/usr/local/lib/libz.so.1动态库衔接出错,只能把这个文件删除才能正常开机。删除步骤如下:虚拟机按住alt、ctrl、f2进入命令行模式,以root权限登陆,并cd到对应文件夹删除文件。
6.3 实验问答
6.3.1 实验问题
问题1: 执行测试程序的输入一般有什么来源?
问题2: fuzzing test的优点?
问题3: 代码分析主要有哪两种类型?
问题4: Perf Fuzz是建立在哪项技术之上的?
问题5: Perf Fuzz算法流程?
问题6: 突变输入的方法?
问题7: Perf Fuzz算法用了什么突变输入类型?
问题8: Perf Fuzz与slow fuzz的主要区别?
问题9: Perf Fuzz与AFL的主要区别?
问题10: AFL中新覆盖代码判定过程?
6.3.2 实验解答
问题1解答: (1)人工编写的性能测试,(2)Benchmark,(3)在使用过程中常用的输入,(4)用户遇到性能问题发送的输入。(5)病理输入。
问题2解答:(1)其测试目标是二进制可执行代码,比基于源代码的白盒测试方法适用范围更广泛;(2)Fuzzing是动态实际执行的,不存在静态分析技术中存在的大量的误报问题;(3)Fuzzing原理简单,没有大量的理论推导和公式计算,不存在符号执行技术中的路径状态爆炸问题;(4)Fuzzing自动化程度高,无须在逆向工程过程中大量的人工参与。
问题3解答: 动态分析和静态分析。
问题4解答: 建立在基于覆盖引导AFL算法之上。
问题5解答:
(1)用给定的种子输入初始化一组输入,称为父输入。
(2)从父输入中选择一个输入,使某些CFG边缘的执行计数最大化。
(3)从选择的父输入中,通过执行一个或多个随机突变生成更多的输入,称为子输入。这些突变包括随机翻转输入字节,插入或删除字节序列,或在父输入集中提取另一个输入的随机部分,并将其拼接在父输入中的随机选择的位置。
(4)对于每个子输入,运行测试程序并收集每个CFG边缘的执行计数。 如果子程序执行某些边缘的次数超过到目前为止看到的任何其他输入(即它使该边缘的执行计数最大化),那么将其添加到父输入的集合中。
(5)从步骤2重复,直到达到时限。
问题6解答: bitflip,按位翻转,1变为0,0变为1
arithmetic,整数加/减算术运算
interest,把一些特殊内容替换到原文件中
dictionary,把自动生成或用户提供的token替换/插入到原文件中
havoc,中文意思是“大破坏”,此阶段会对原文件进行大量变异,
splice,中文意思是“绞接”,此阶段会将两个文件拼接起来得到一个新的文件
问题7解答: 主要是havoc,若实在没有新输入的时候则采用splice。
问题8解答:
区别1:在于slow Fuzz的目标是一维的,他只是最大化程序的总执行路径长度。因此,可以与基于覆盖导向的多目标最大化的PerfFuzz进行很好地对比。
区别2:Perf Fuzz从一个选定的父输入产生许多(通常至少数千,通常是数万)输入。Slow Fuzz反而为每个亲本产生一个突变体。前者将输入优先排序然后fuzz,但slow Fuzz随机选择父输入然后fuzz。
区别3:Perf Fuzz将AFL的havoc应用于输入。slow Fuzz了解哪些突变在过去成功地产生有效输入,并更经常地应用这些突变。
问题9解答:PERF FUZZ是基于AFL的,但是两者之间最大的不同为PERF FUZZ是多目标的,也就是不仅仅关注于代码覆盖率还关注文中所提出的NewMax参数。
问题10解答: AFL将仪器插入到程序中,该程序为程序的控制流图(CFG)中的每个边缘分配一个伪唯一ID。在程序执行过程中,仪器使用8位计数器来跟踪每个CFG边缘被遍历的次数。 AFL将每个CFG边缘的命中次数简化为8个桶中的一个:1次,2次,3次,4-7次,8-15次,16-31次,32-127次,或128-255次。然后,如果输入有访问一个新的CFG边缘,或者击中一个已知的CFG边缘一个新的桶数次,则有新的覆盖范围。
7 学习总结和建议意见
7.1 学习总结
这学期的课程难但是值得。以为上学期Linux内核分析已经很难,没想要网络攻防又给我结结实实地上了一课。回顾之前的内容,从网络攻防的概念讲起。第一次动手搭建了网络攻防环境(这也是之后各种实验的基础),让我确实感受到了虚拟机的用处。
从信息收集、嗅探到踩点攻击,留后门、清除程序。完整的攻击过程在linux和windows上都做过,虽然都是运用一些现成的工具如nmap、Nessus、wireshark、metasploit等,但是学会使用并分析攻击数据已经是很难忘的学习过程了。老师的课程安排其实刚开始我是不理解的,每周的博客,每周的实践着实是一个沉重的负担,需要花费大量时间自学,课下琢磨。但是回首发现,确实实践才是最快成长的办法。对于网络攻防,不仅仅掌握了工具的运用还学会理解攻击的原理等等。
感谢老师提供的新的课堂教学模式,让我在网络攻防方面初窥门径。
7.2 学习建议
每周课堂实践如果出新的内容,我想对于大家都是一个很大的心理压力。我想可否将实践内容对工具的使用减少一点,或者挑几个重要的实践做一做,精讲里面的原理,攻击思路方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号