


20-防盗链---抓取梨视频
https://pearvideo.com/
首先分析网页,查看网页源代码,发现并没有视频标签
/
/
/
这个是二次请求后从开发者工具的html代码那里看到的路径(注意一定播放视频后才能看到)
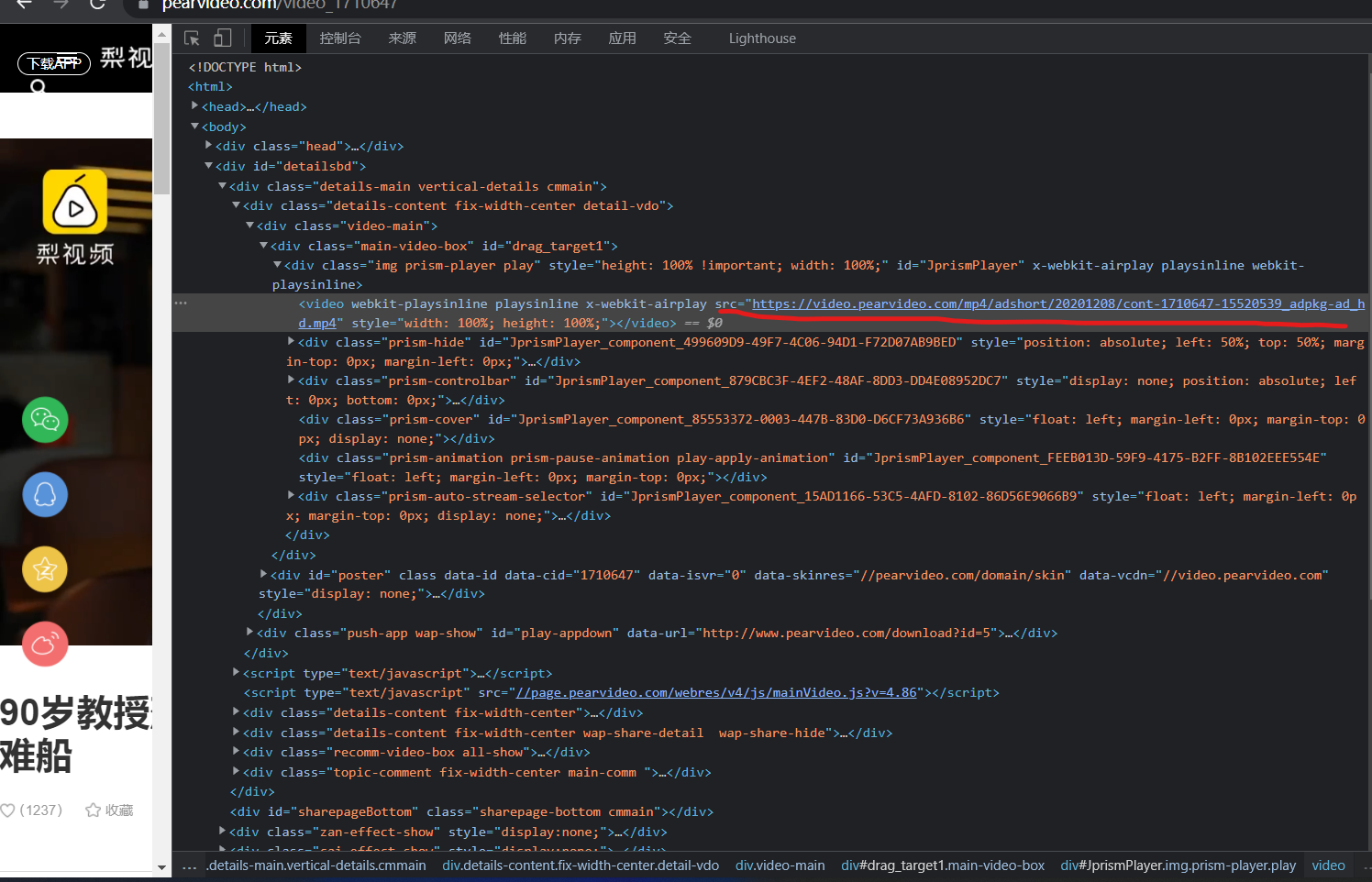
/
/
这个是打开XHR,查看而此请求返回的json后的url
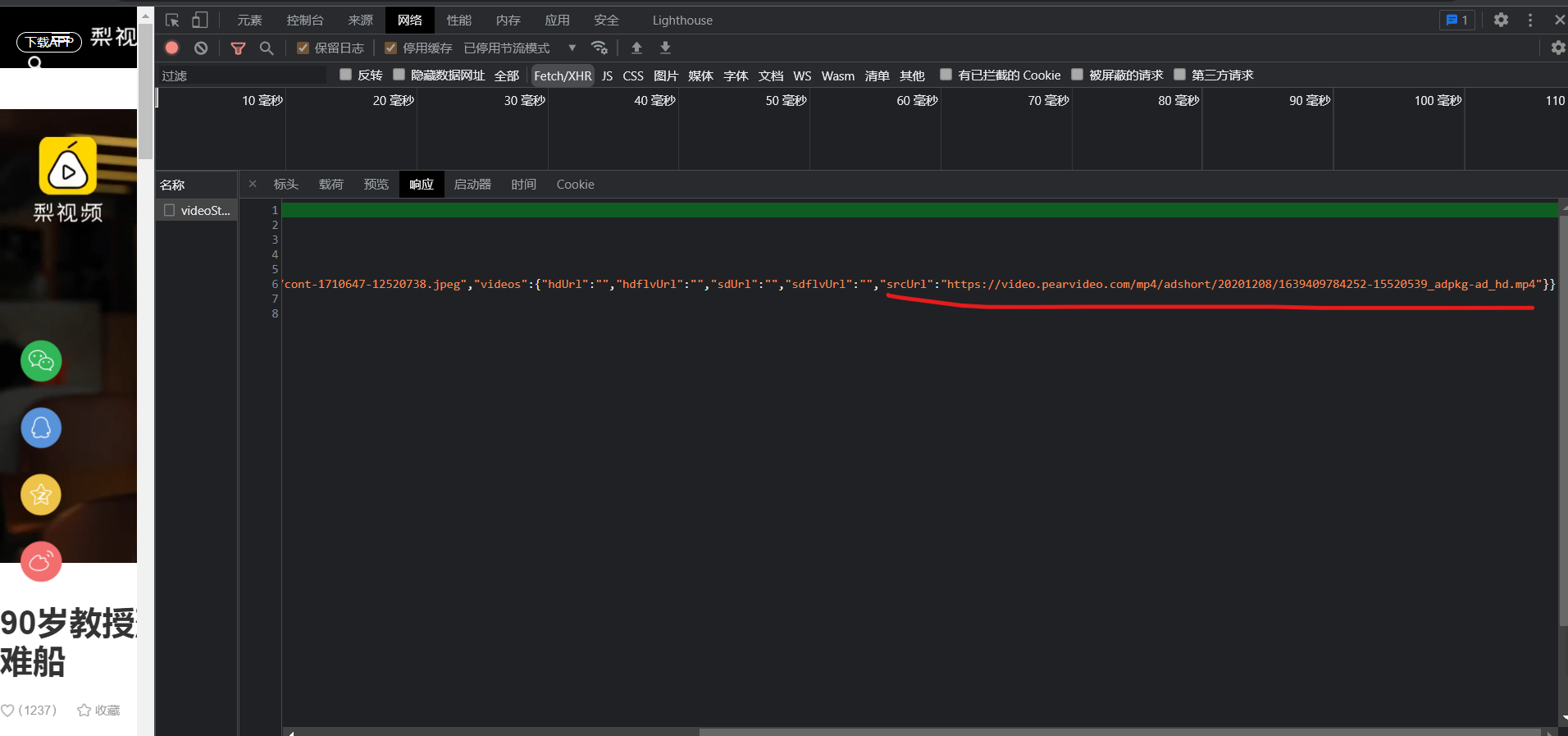
分析之后,发现通过srcURL访问视频,报错404。经过分析我们可以把srcURL的1639406989748这一串数字,替换成cont-1710647即可正常访问。

我们首先发送请求,希望通过获取text中的数据,进而获取url数据,但是找不到,显示文章下线。
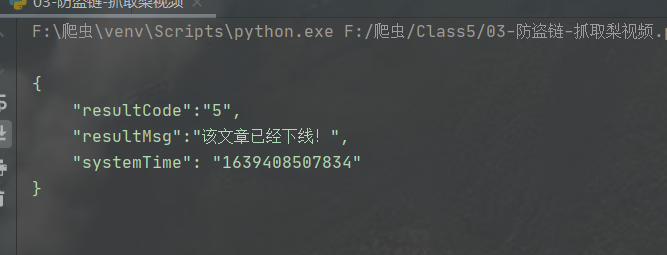
这肯定是做了反爬的
/
/
/
/
/
我们首先加一个user-agent看看行不行,发现并没有作用
/
/
/
/
我们通过开发者工具注意到:请求头里面有一个Referer,即防盗链
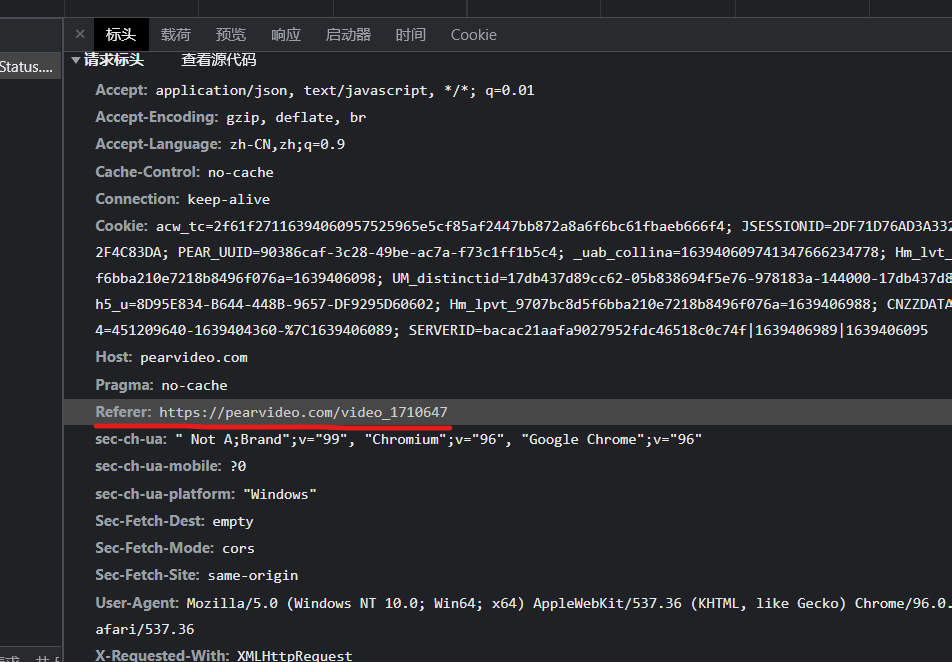
这个东西是用来溯源的,即看我们的请求从哪里发出,如果是Referer中的路径,那就没问题,我们没加,所以报错。
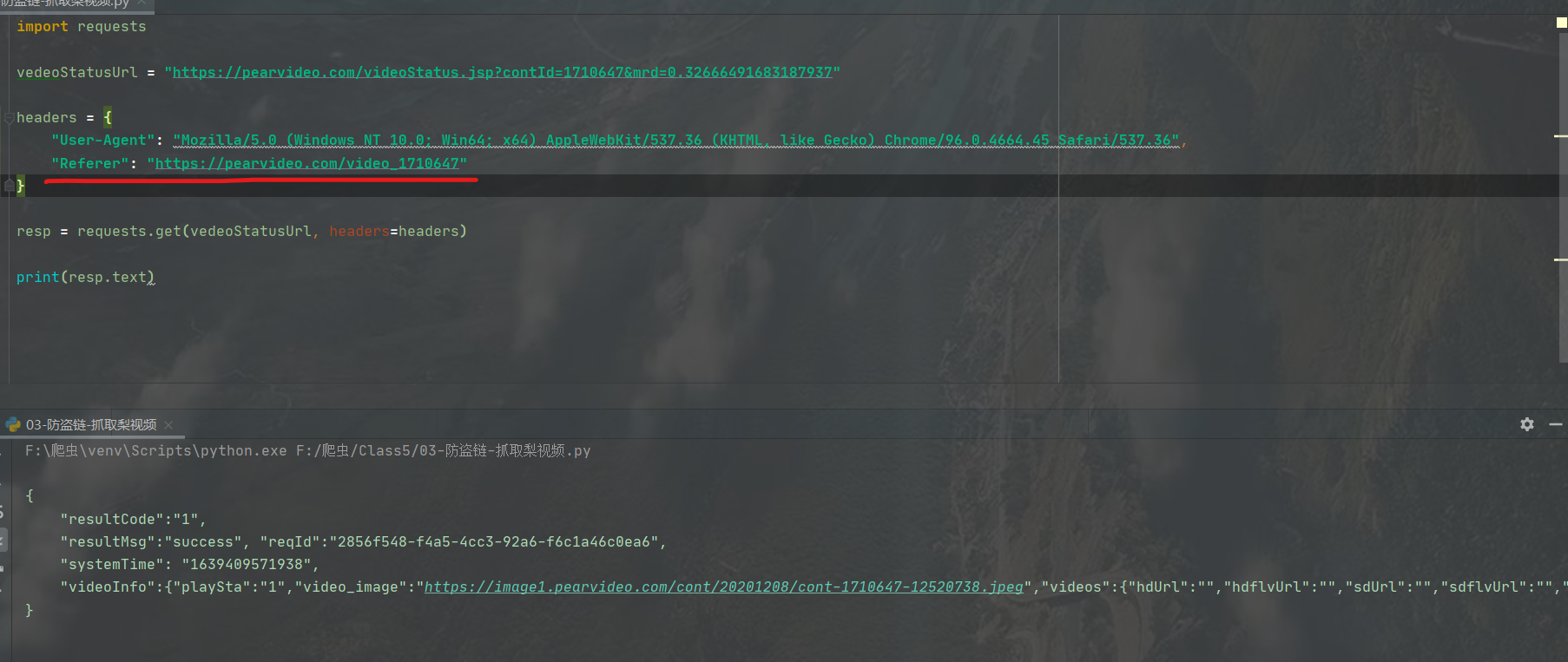
/
/
/
/
/
/
import requests
url = "https://pearvideo.com/video_1710647"
contId = url.split("_")[1]
vedeoStatusUrl = f"https://pearvideo.com/videoStatus.jsp?contId={contId}&mrd=0.32666491683187937"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36",
# 防盗链:溯源
"Referer": "https://pearvideo.com/video_1710647"
}
resp = requests.get(vedeoStatusUrl, headers=headers)
# 将相应的json数据保存到字典中
dict = resp.json()
systemTime = dict['systemTime']
srcUrl = dict['videoInfo']['videos']['srcUrl']
# 进行替换,得到正确的路径
srcUrl = srcUrl.replace(systemTime, f"cont-{contId}")
# print(srcUrl)
# 下载视频
with open("a.mp4", mode="wb") as f:
f.write(requests.get(srcUrl).content)
print("over")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号