ElasticSearch学习系列(七)分词
分词里面有两个名词:Analysis、Analyzer
Analysis
文本分析是把全文本转换一系列单词的过程,叫成分词。
Analyzer
分词器(有内置的分词器,也有相应的插件,尤其是针对中文)
由以下三部分组成:
1.Character Filters 过滤特殊字符串
2.Tokenizer 单词切分
3.Token Filters 切分后的加工
二、使用 _analyzer API
1.standard分词器
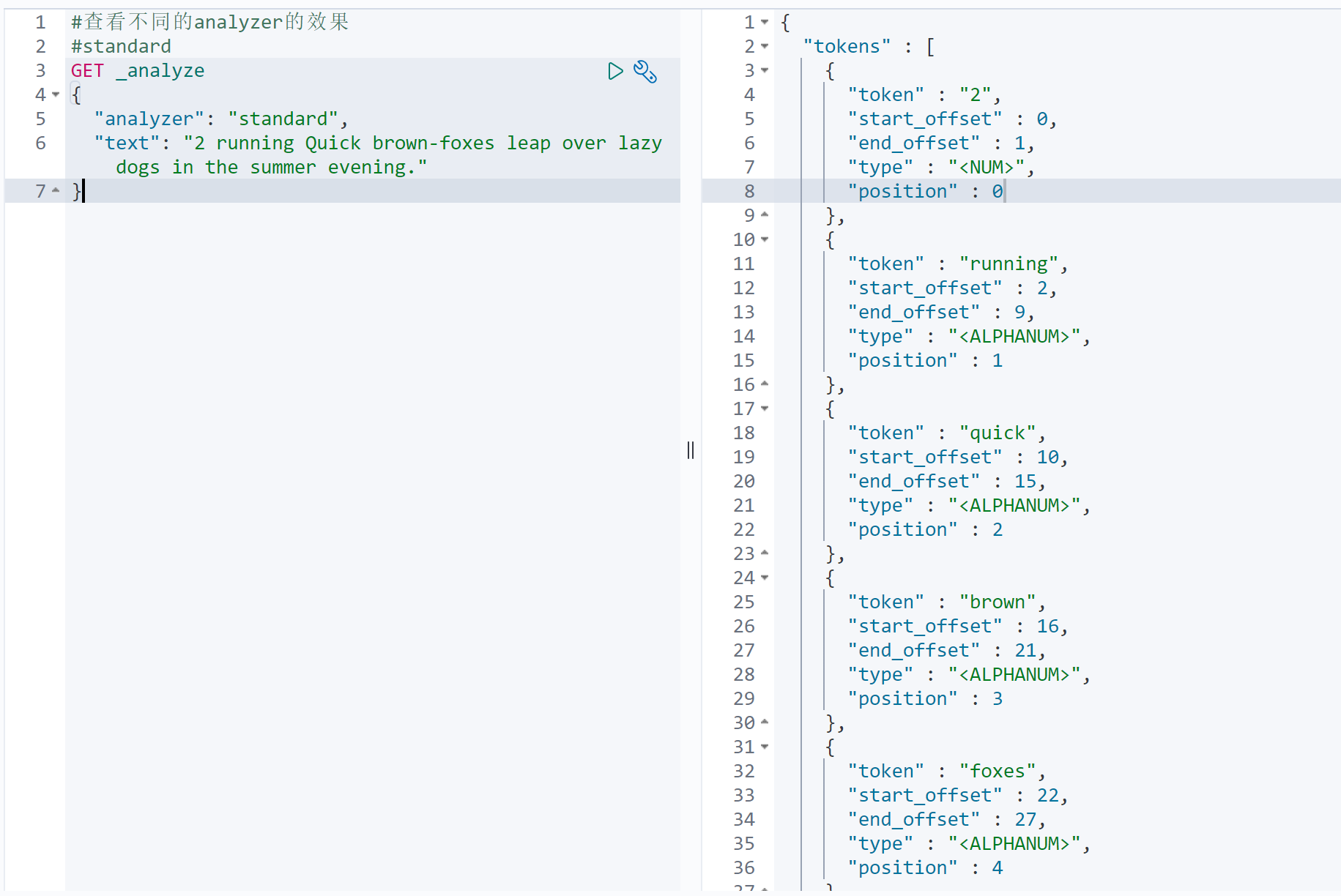
可以看到单词以空格,非字符的方式分割,并转换小写。
2.simple分词器

可以看到,只保留字母。
3.whitespace分词器
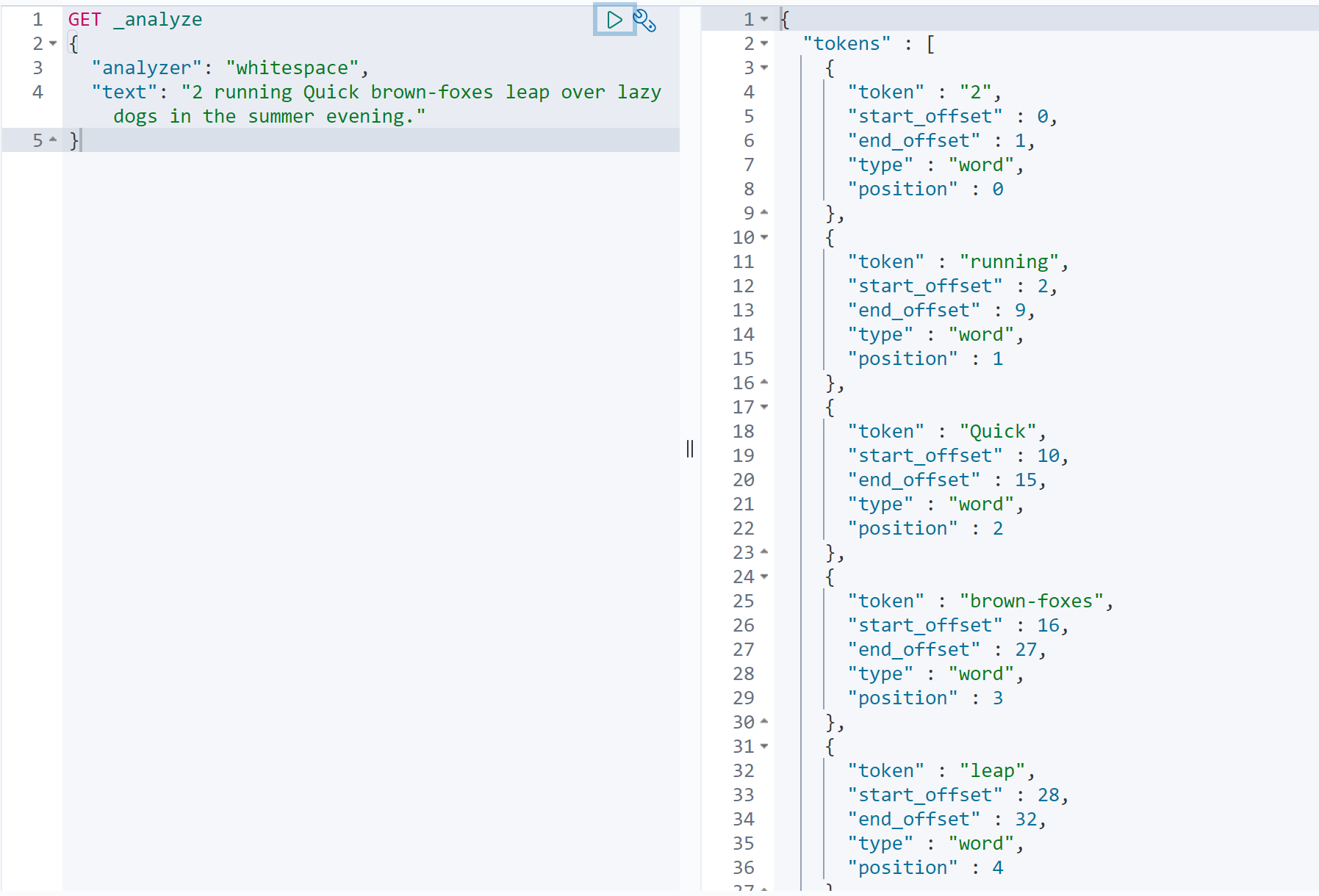
可以看到只是以简单的空格切分。
4.stop分词器

可以看到,stop分词器多了一个 token filters环节,把 a,the ,in 等修饰词给过滤掉了。
5.keyword 分词器(不分词)
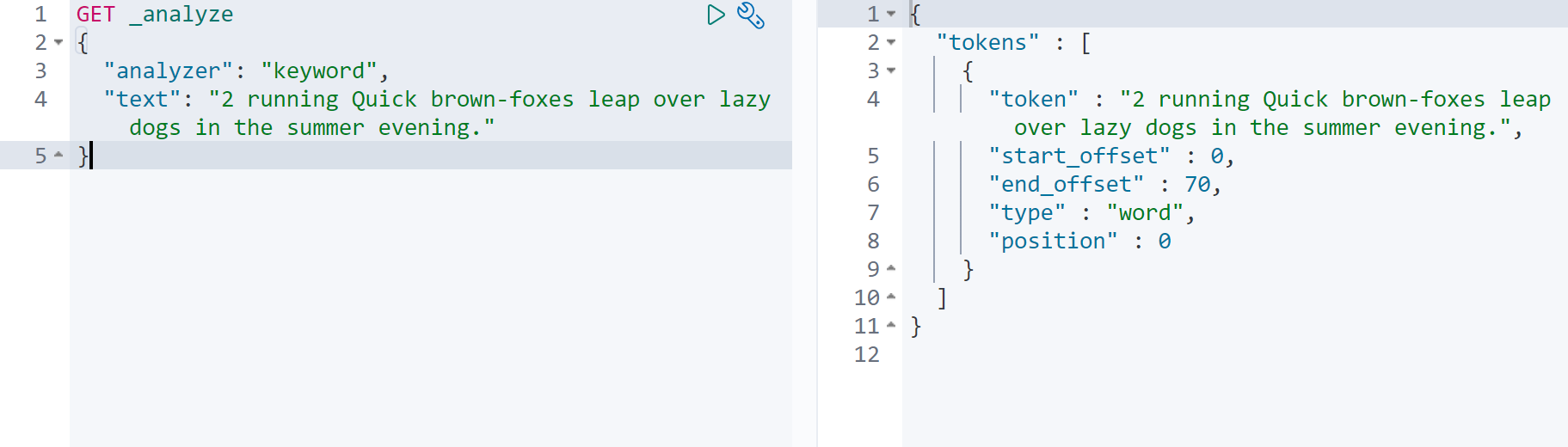
当不需要分词时,可以设置为 keyword。
6.正则表达式分词 pattern
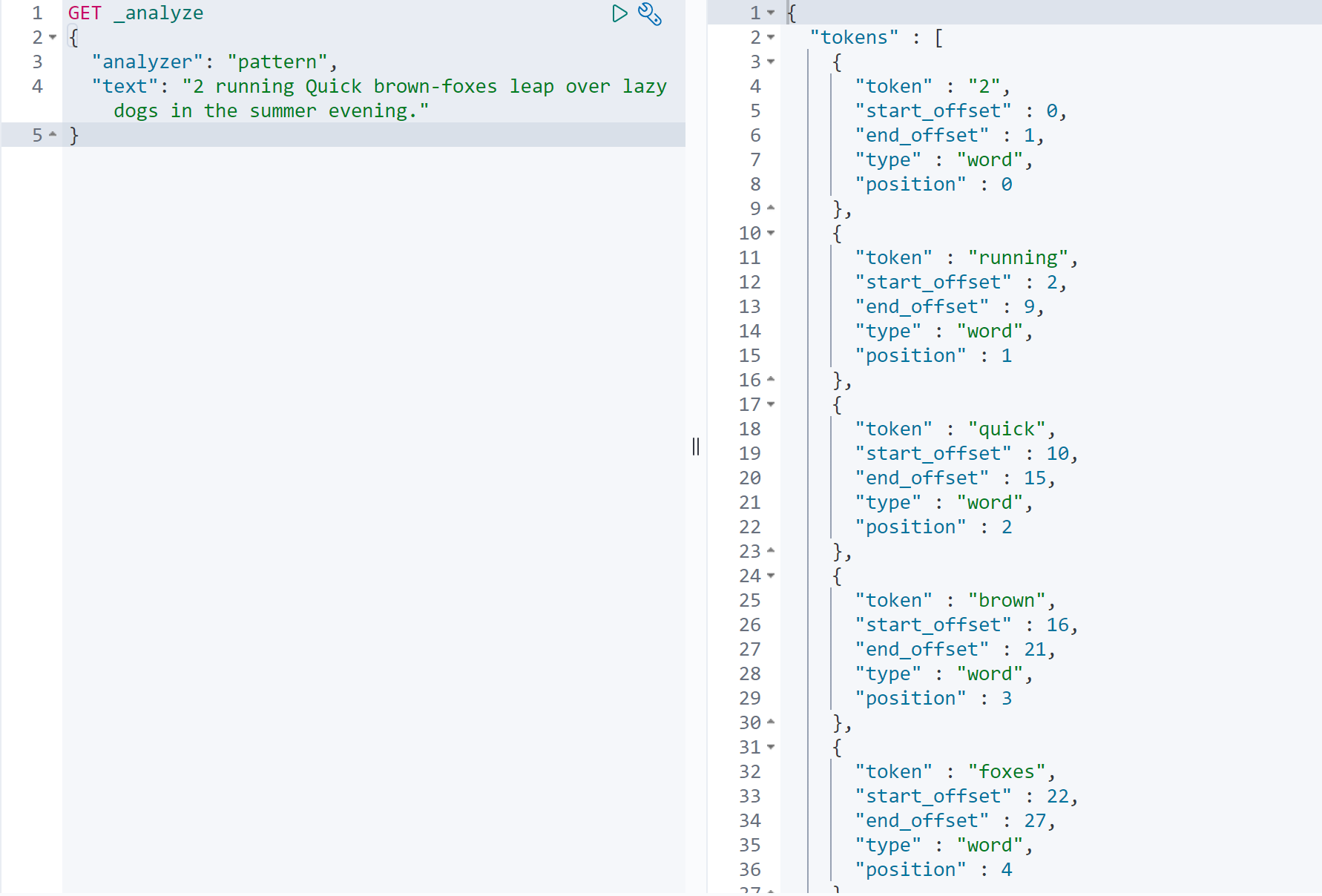
默认是 \W+,非字符的符号进行分隔,在Token Filters环节 做了小写转换,和修饰词过滤。
7.language 分词器
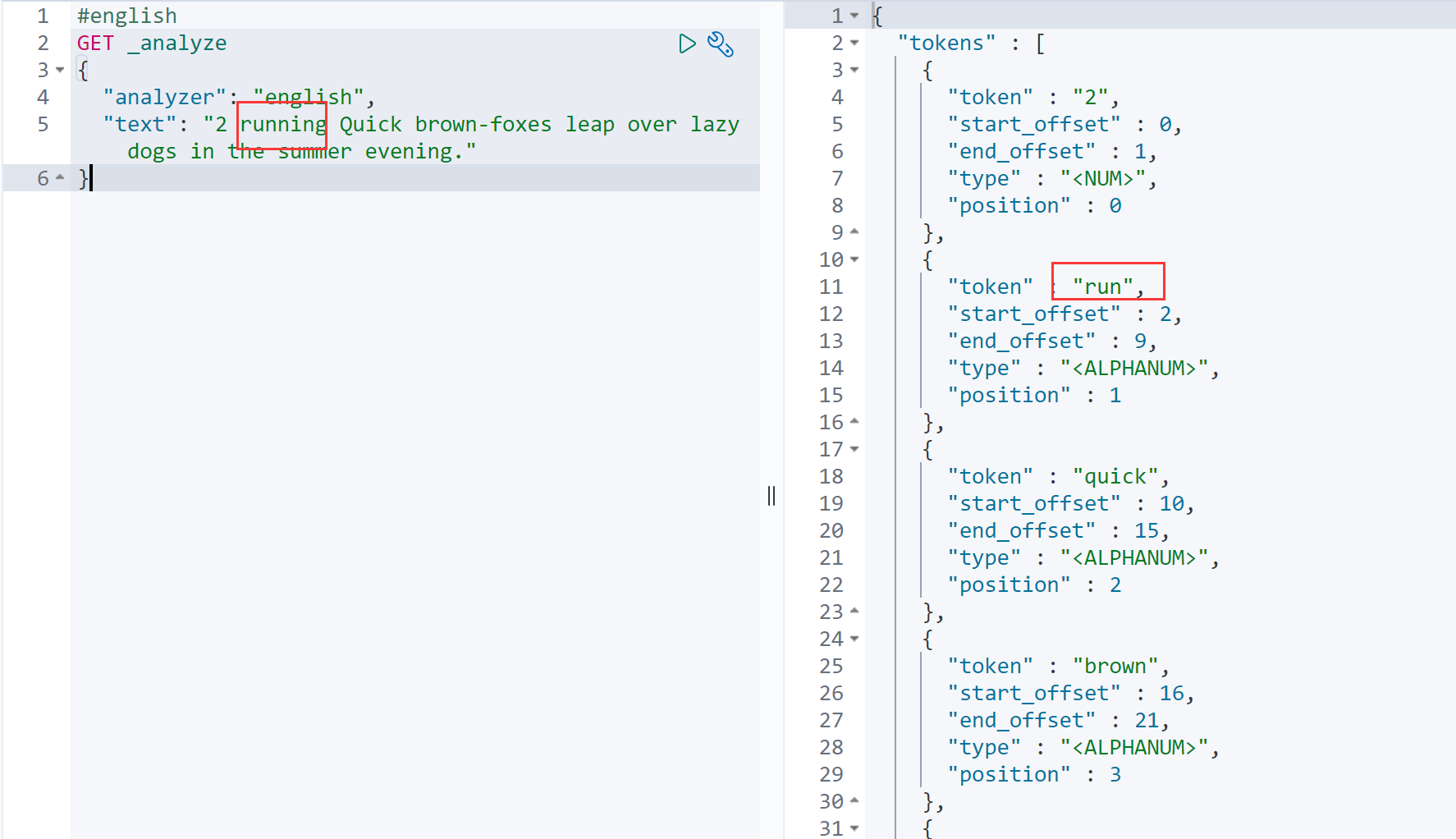
三、中文分词
icu_analyzer的安装
1.因为我是docker for windows 则通过如下命令进入docker容器内部。

bin/elasticsearch-plugin install analysis-icu

安装好之后,重启Docker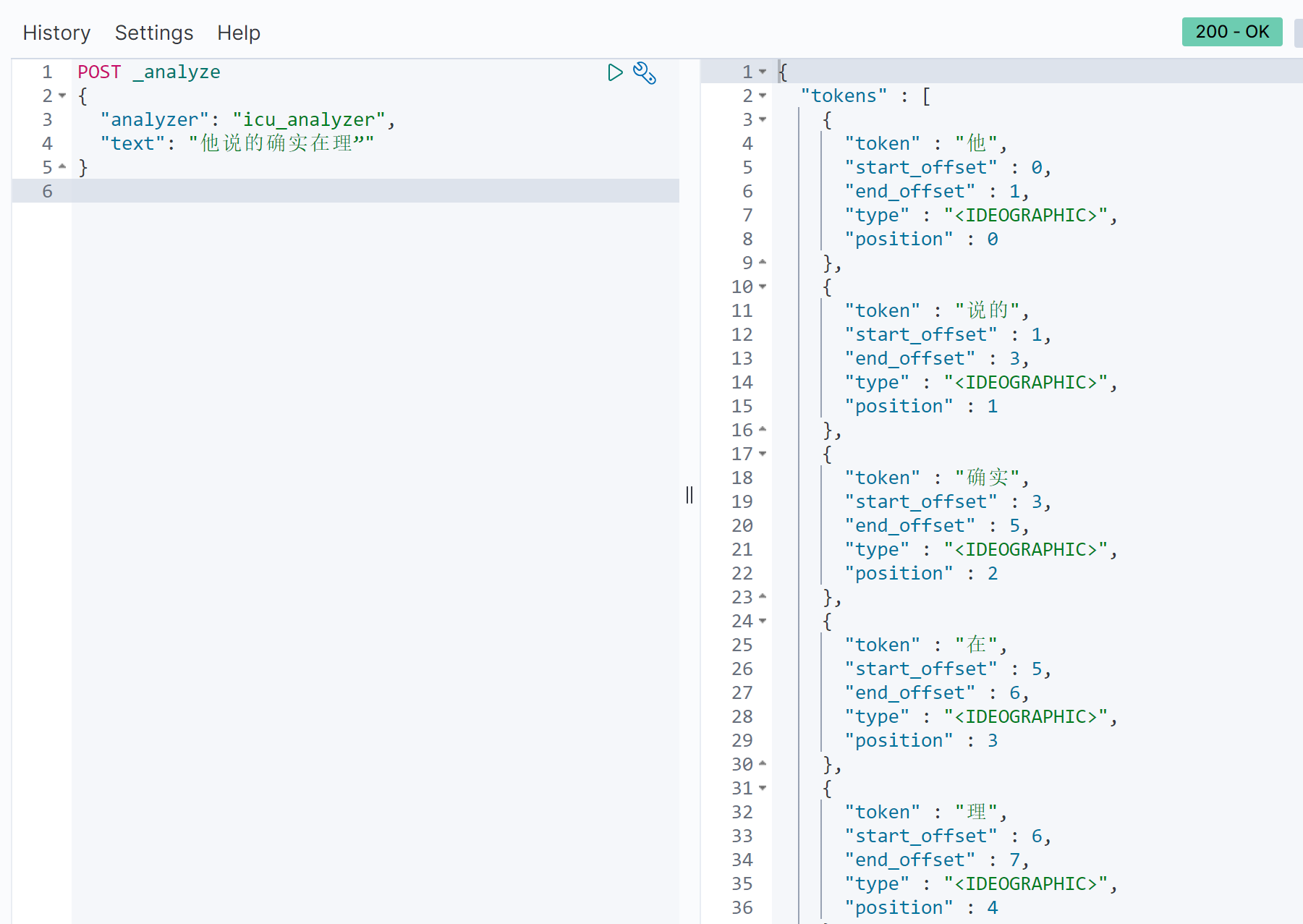
但还是有一些问题,比如在理。
社区里面有 ik,THULAC 中文分词插件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号