stl 容器的存储结构
参考:
1. 概述
这篇文章主要记录 stl 常见容器的存储结构。
2. 空间配置器(allocator)
创建 stl 容器对象的时候,都会指定一个默认空间配置器,此空间配置器承担了容器内元素空间的申请和释放。
同时,stl 为了避免小内存频繁的申请和释放造成内存碎片化问题,设计了一级空间配置器(class __malloc_alloc_template)和二级空间配置器(class __default_alloc_template)。
2.1 配置器接口类(class simple_alloc)
无论是第一级还是第二级空间配置器,都由 class simple_alloc 类进行包装,所有容器都是直接使用 class simple_alloc 及其提供的接口(stl 源码剖析 2.2.4节):

可以看到,通过 simple_alloc::allocate() 函数进行内存分配时,传递的参数为 n*sizeof(T),即将 n 个容器成员转化为 bytes 数再传递给一级/二级空间配置器。
2.2 一级空间配置器类(class __malloc_alloc_template)
一级空间配置器较为简单,内存申请和释放直接按需使用 malloc() 和 free() 接口。
2.3 二级空间配置器类(class __default_alloc_template)
当容器申请的内存容量小于等于 128 Bytes 时,就会调用二级空间配置器。
2.3.1 自由链表结构(free list)
二级空间配置器使用一个指针数组,数组长度固定为 16,数组每个槽位是一个 union obj 类型的指针,这称之为 free list 数组结构(stl 源码剖析 2.2.6节):

其中 union obj 结构定义如下(stl 源码剖析 2.2.6节):

采用联合体的意义是,当此结构正在被使用时,联合体作为申请空间的内存块可以直接使用;当此结构没有被使用时,union obj* free_list_link 成员又能作为内存块指针,指向下一个内存块。
free list 数组中每个槽位是一个 free list 结构,即未使用的 union obj 结构形成的内存块组成的链表(stl 源码剖析 2.2.10节):
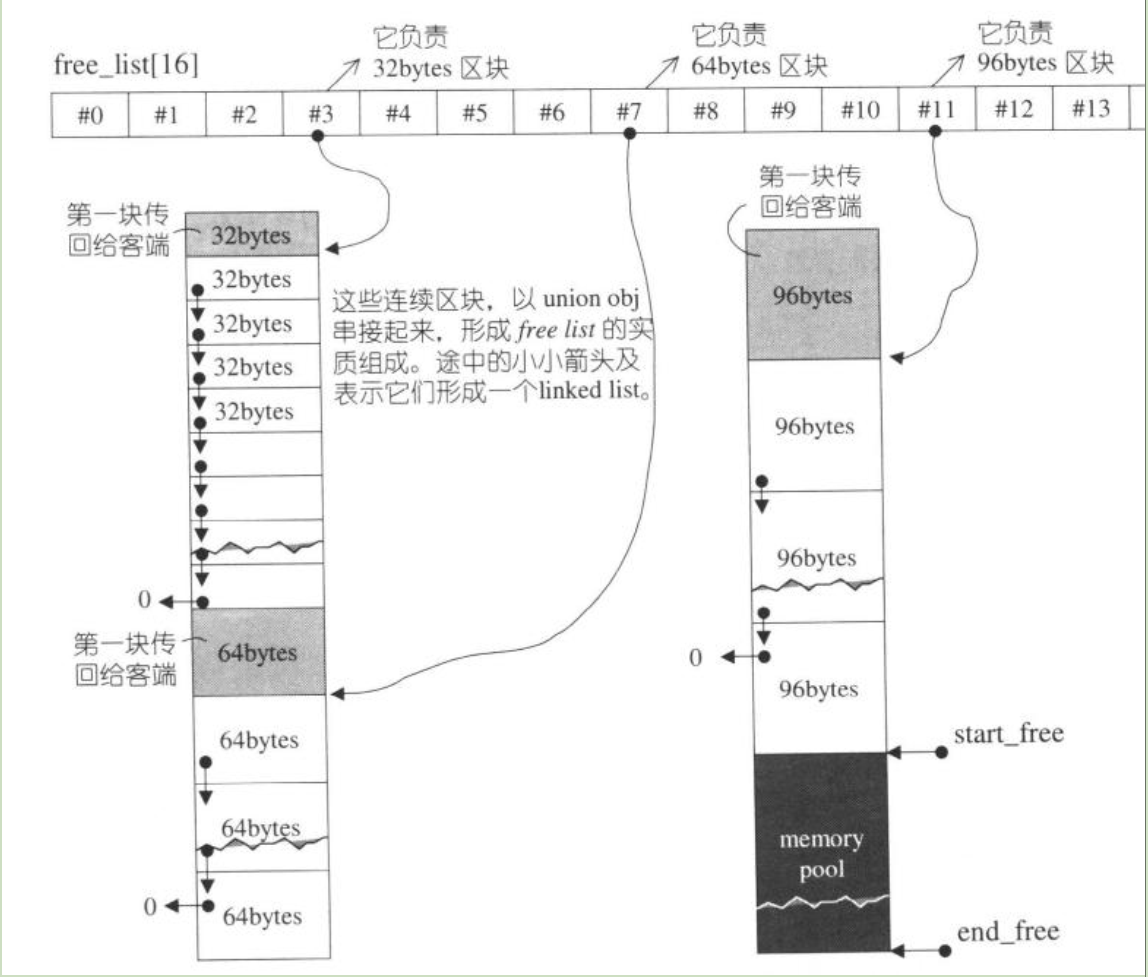
每个槽位负责的内存块大小是固定的。
2.3.2 申请内存
当容器申请内存时,总是通过 simple_alloc::allocate() 函数先转换为 bytes 大小,再传递给二级空间配置器。
其次,由于 free list 数组结构只有 16 个槽位,每个槽位负责的内存块大小是固定的,所以对于申请的空间大小,空间配置器总是返回大于等于目标大小的内存块。
对于目标内存大小,配置器需要计算出从哪个 free list 槽位中分配(stl 源码剖析 2.2.6节):


初始时,free list 数组都是空指针(stl 源码剖析 2.2.6节):

所以第一次调用配置器,需要调用 refill() 函数来填充 free list 数组中的对应槽位(其它槽位等待需要时再填充,stl 源码剖析 2.2.9节):

这里可以看到,具体的内存申请工作是由 chunk_alloc() 函数完成的,这将在下面内存池中介绍。
refill() 函数填充时,一次申请了 20 个目标内存块,申请内存图示如下(stl 源码剖析 2.2.7节):
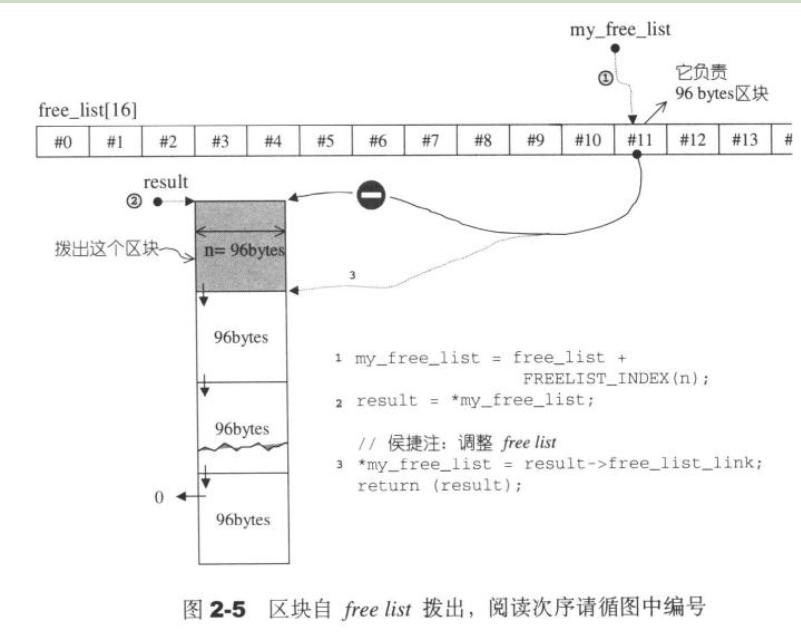
上图中,11 号槽位的指针指向第二个内存块,并返回第一个内存块。
2.3.3 释放内存
内存释放即 free list 回收内存块(stl 源码剖析 2.2.8节):

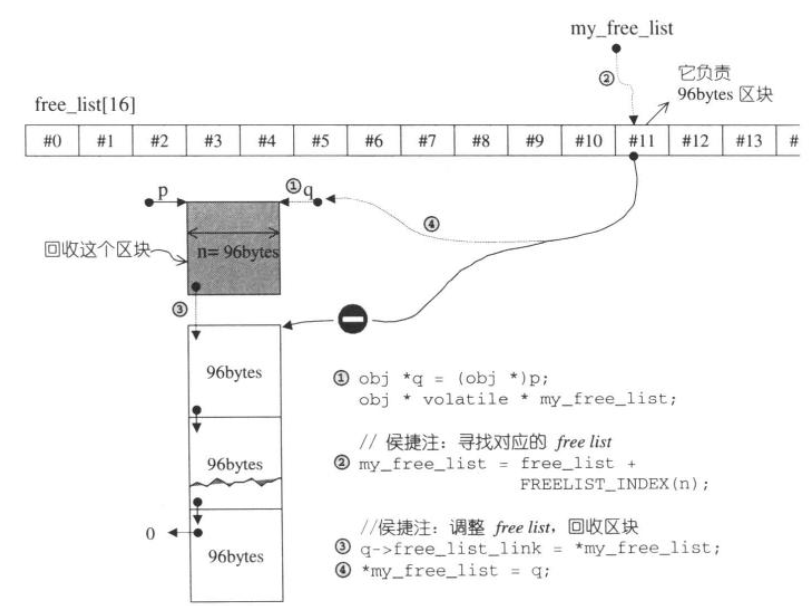
需要注意的是,释放掉的内存并不会被内存池回收,只是回收到 free list 链表。
2.3.4 内存池
前面提到,具体的内存申请工作是由 chunk_alloc() 函数完成的,而此函数会调用 malloc() 申请系统内存。
chunk_alloc() 函数每次调用 malloc() 会申请一大片连续内存,并维护两个指针,分别为 end_free 和 start_free,即指向内存的起始和结束区域。
同时维护一个 size_t 类型的变量 heap_size,用于累计 chunk_alloc() 函数申请的内存总大小(stl 源码剖析 2.2.10节):

在上层调用 chunk_alloc() 函数的时候,会根据剩余内存大小(end_free - start_free) 返回需要的内存,剩余的内存继续等待其它内存分配调用。
因为二级空间配置器每次都是拿小内存,所以为了避免内存碎片化,这里预先申请大块内存空间,然后按需分块返回。小块内存最后也是返回到 freelist 里面,并没有 free 掉。
如果剩余内存不足以返回至少一个需要的内存块大小,就会调用 malloc() 函数申请新的连续内存片(stl 源码剖析 2.2.10节):

且申请的大小为 2 倍需要的内存大小 + (heap_size >> 4),这远远多于本次调用需要的内存大小。
从上可以看到,free list 主要用于维护固定大小的块内存,而内存池用于维护连续的系统内存片,给 free list 提供不同大小的内存块。
需要注意的是,根据内存池的分配机制,可以看到 free list 中每个槽位中的每个内存块之间,内存不一定是连续的,只能保证每个内存块本身内存是连续的,而内存块之间不一定连续。
2.4 配置器类都是 static 成员
注意到,不管是配置器接口类(class simple_alloc),还是一级空间配置器(class __malloc_alloc_template)或二级空间配置器(class __default_alloc_template),其内部成员函数和成员变量都是 static 静态的。
例如 std::vector 中使用空间配置器的一个示例为(stl 源码剖析 4.2.5节):
template<class T, class Alloc=alloc>
class vector {
typedef simple_alloc<value_type, Alloc> data_allocator;
iterator allocate_and_fill(size_type n, const T& x) {
..
iterator result = data_allocator::allocate(n);
..
}
};
vector 内部并没有实例化任何 simple_alloc 类对象,而是直接调用 simple_alloc::allocate() 类静态函数,由于所有成员变量也是静态的,所以静态成员函数也可以调用类静态成员变量。
配置器如此使用的一个结果是,一个可执行程序,所有容器都是用的同一份二级配置器的 free_list,而不是每个容器对应一个。
关于所有容器共享 free_list 的讨论,参见: https://www.boost.org/sgi/stl/alloc.html 。
3. vector
3.1 数据结构
vector 是线性存储空间,即一片连续的内存区域。如果容器内元素为 T,那么整个存储空间占用 vector::capacity * sizeof(T) 个字节的大小。
其存储空间的管理指针(stl 源码剖析 4.2.4 节):

其存储空间示例(stl 源码剖析 4.2.4 节):
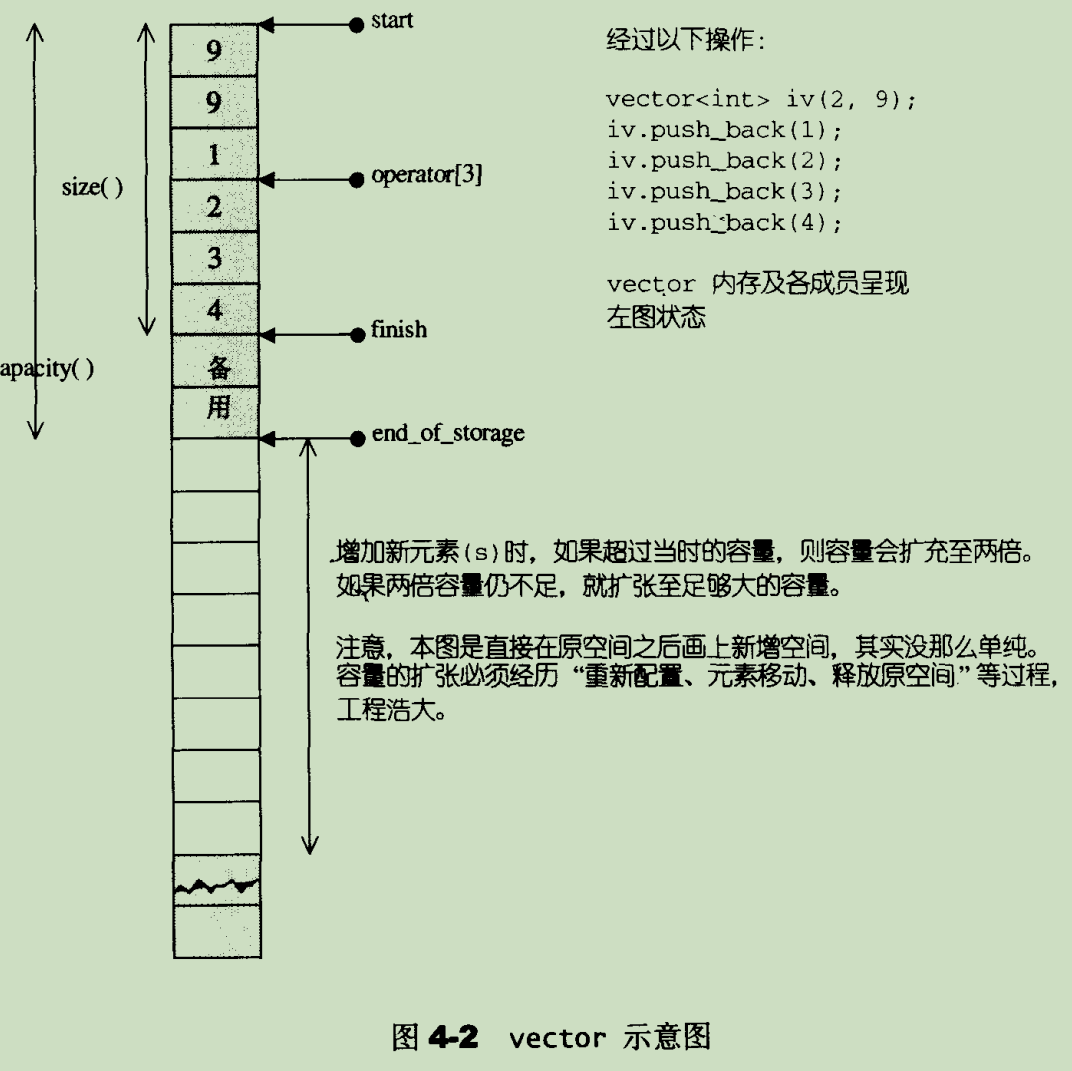
3.2 插入元素
vector 的空间配置器(stl 源码剖析 4.2.5 节):
typedef simple_alloc<value_type, Alloc> data_allocator;
vector 支持 vector(int n) 构造函数,通过变量 n,使得 start=0, finish=0, end_of_storage=n。
以 push_back() 为例,当 finish != end_of_storage 时,直接在剩余空间上构造一个新对象(调用容器元素的拷贝构造或移动构造函数)。
当线性存储空间用完时,需要申请新的线性空间(stl 源码剖析 4.2.6 节):

接着将原线性空间的内容拷贝到新的线性空间中,并更新 start、finish 和 end_of_storage 变量。
由于新旧空间不在一块内存,所以旧的迭代器在插入元素后可能会失效。
4. list
4.1 数据结构
list 中的元素存储在 node(节点)中(stl 源码剖析 4.3.2 节):

list_node 是一个双向链表,双向意味着链表头节点可以直接指向尾节点,使得 list 成为一个循环链表。
list 类中有一个 list_node 指针,指向链表的头节点(stl 源码剖析 4.3.4 节):

4.2 内存管理
4.2.1 初始化
list 的空间配置器(stl 源码剖析 4.3.5 节):
typedef simple_alloc<list_node, Alloc> list_node_allocator;
可见,list 每次配置以一个 list_node 为单位。
list 支持 list() 构造函数,此时会构造一个空的 list_node(stl 源码剖析 4.3.5 节):
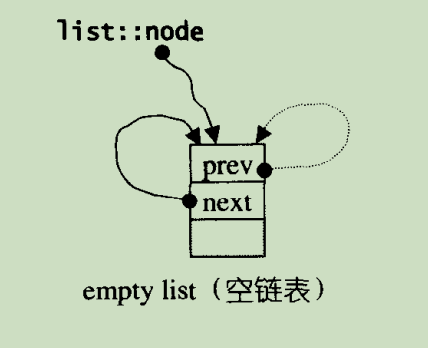
4.2.2 元素插入
list 可以在任意位置插入新元素,插入元素后,之前的迭代器始终有效(stl 源码剖析 4.3.5 节):
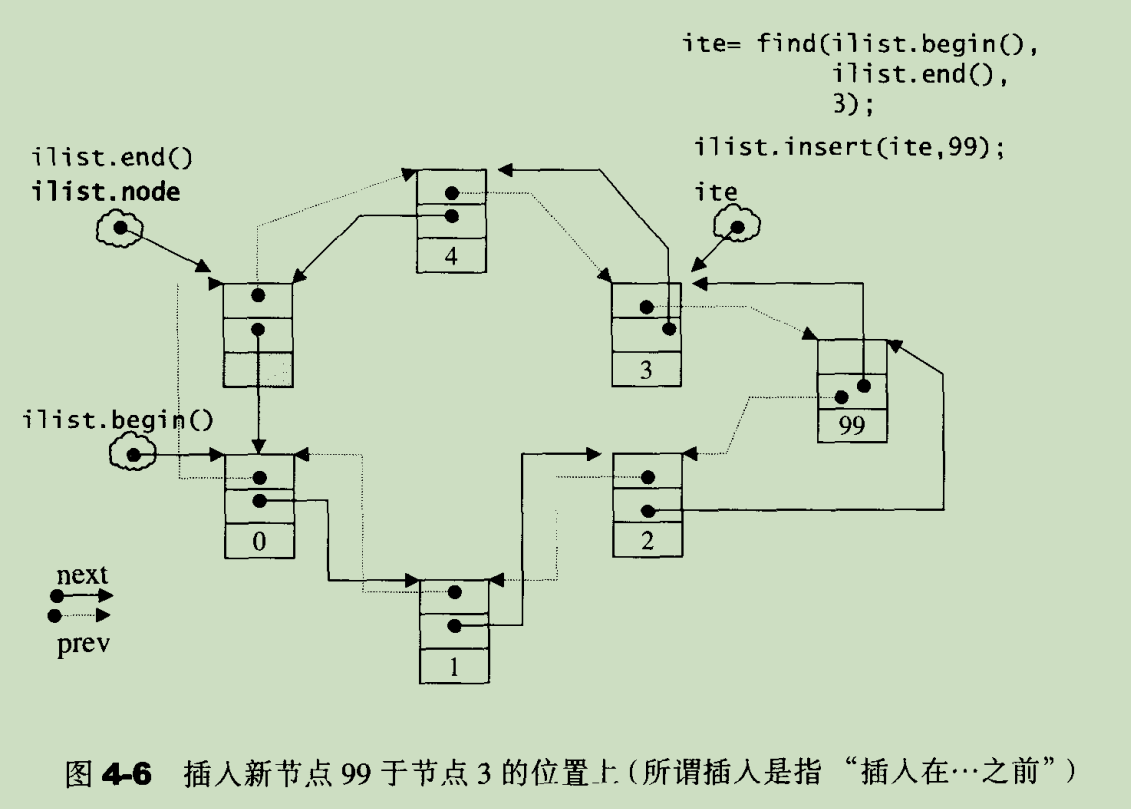
注意上图中,list::begin() 和 list::end() 迭代器的位置,且 list::end() 迭代器指向的是一个空节点(即不包含元素,只是一个标靶)。
4.3 迭代器
list 提供的是 bidirectional iterator 即双向迭代器,提供 ++ 和 -- 操作。
值得一提的是,list::size() 的时间复杂度为 O(n),即需要遍历所有元素(stl 源码剖析 4.3.4 节):

5. deque
5.1 数据结构
deque 区别于 queue,在队列头和尾都能高效的插入和删除元素。此外,虽然 deque 也提供了 insert() 接口,但是效率较差。
vector 也能实现在头尾插入或删除元素,但是在头部插入或删除元素会引发内部存储空间所有元素的移动,效率较差。
deque 存储元素的方式较为复杂,其维护了一个类似 bitmap 的 map 区域,map 中每个槽位都指向一段连续的线性空间。同时,需要一个指针的指针指向 map 区域,以及记录 map 区域槽位的大小。stl 源码剖析中称此设计为中控器(stl 源码剖析 4.4.2 节):
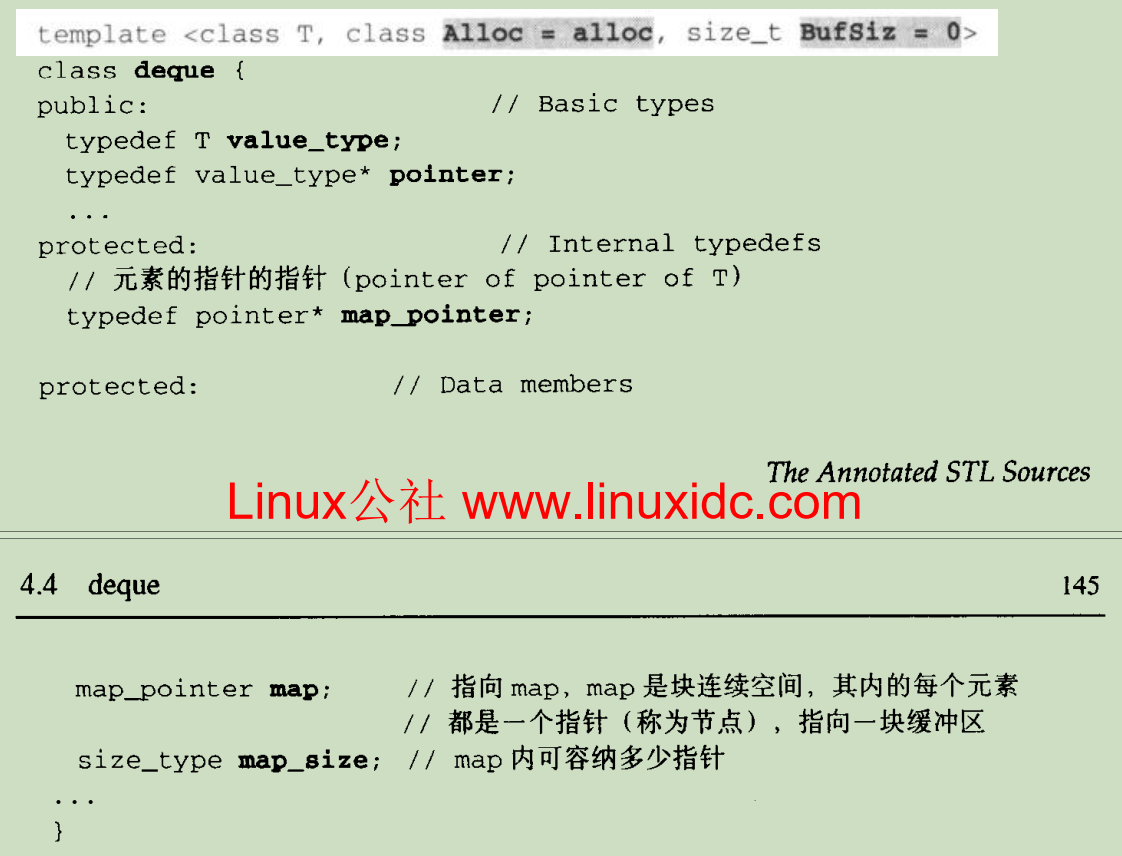
5.2 迭代器
deque 提供 ramdon access iterator,即可以通过 deque::operator[] 来任意访问容器内元素。
由于 deque 是由多个线性存储区组合而成的,所以 class __deque_iterator 中定义了如下关联 deque 存储区的变量(stl 源码剖析 4.4.3 节):

图示如下(stl 源码剖析 4.4.3 节):
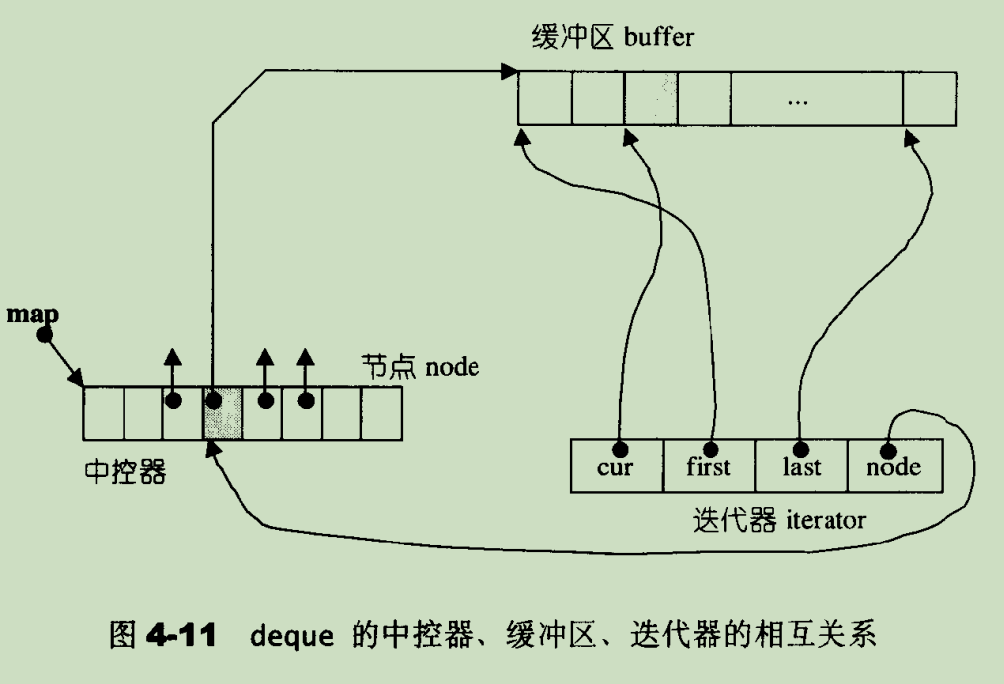
另外需要注意的是,迭代器的 ++、-- 操作会涉及到跨线性存储区。
5.3 内存管理
5.3.1 初始化
list 的空间配置器(stl 源码剖析 4.4.6 节):
// 配置容器元素
typedef simple_alloc<value_type, Alloc> data_allocator;
// 配置 map 内槽位指针
typedef simple_alloc<value_type, Alloc> map_allocator;
创建一个 deque 对象如下:
deque<int, alloc, 32> ideq(20, 9);
在上面的创建语句中,元素类型为 int 型,每个 map 槽位指向的缓冲区大小为 32 bytes,并初始化 20 个值为 9 的元素。
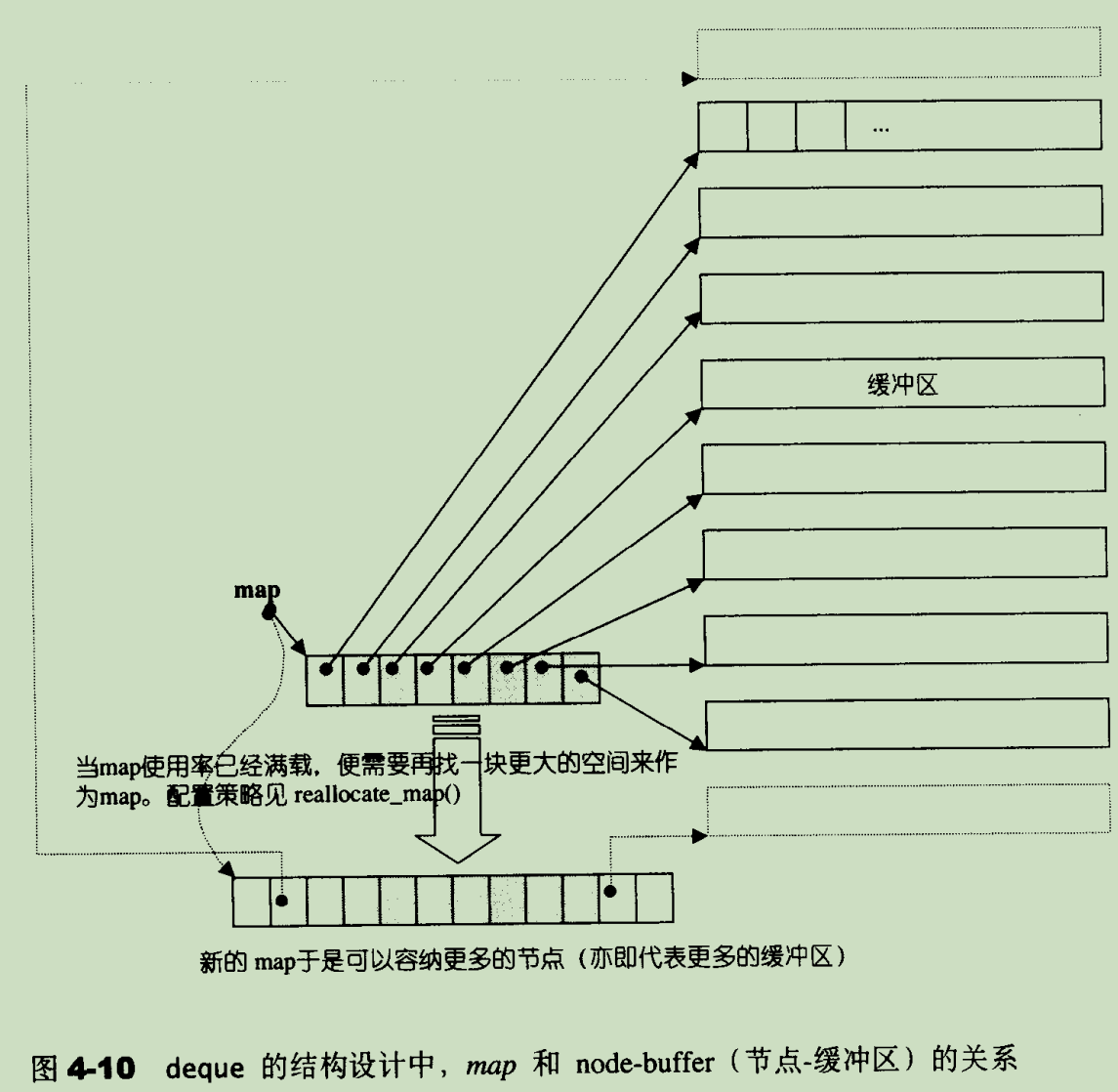
创建 deque 对象最重要的一步是创建 map 中控器,此任务由 deque::create_map_and_nodes() 函数负责(stl 源码剖析 4.4.5 节):

可以看到,map 中槽位的个数最小为 8+2=10,创建 map 后,初始化数据从 map 的中间槽位开始插入,这样做的目的是保留 deque 两端插入的高效性。且每需要一个槽位,才会创建槽位指向的缓冲区,图示如下:
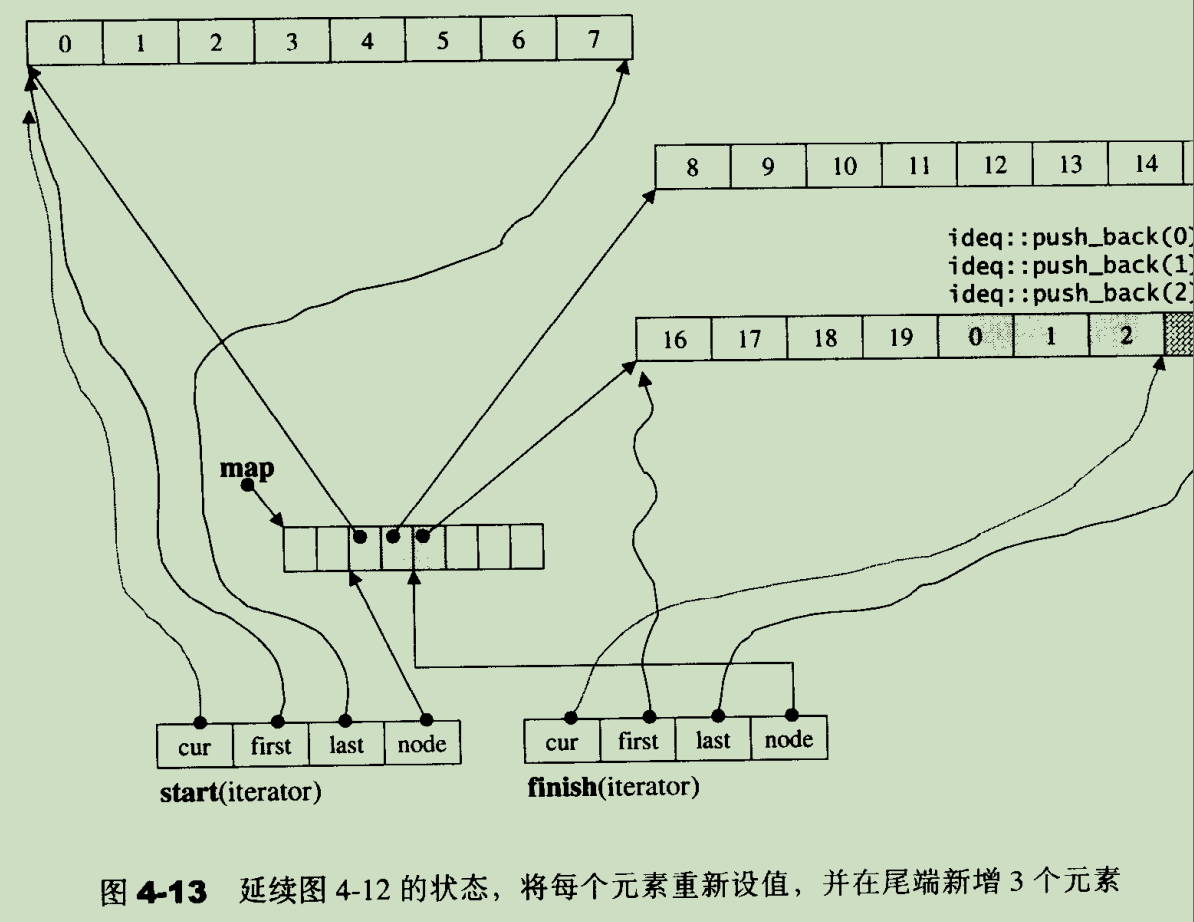
5.3.2 元素插入
当不断调用 deque::push_back() 导致一个缓冲区满后,需要创建一个新槽位和一个新的缓冲区:
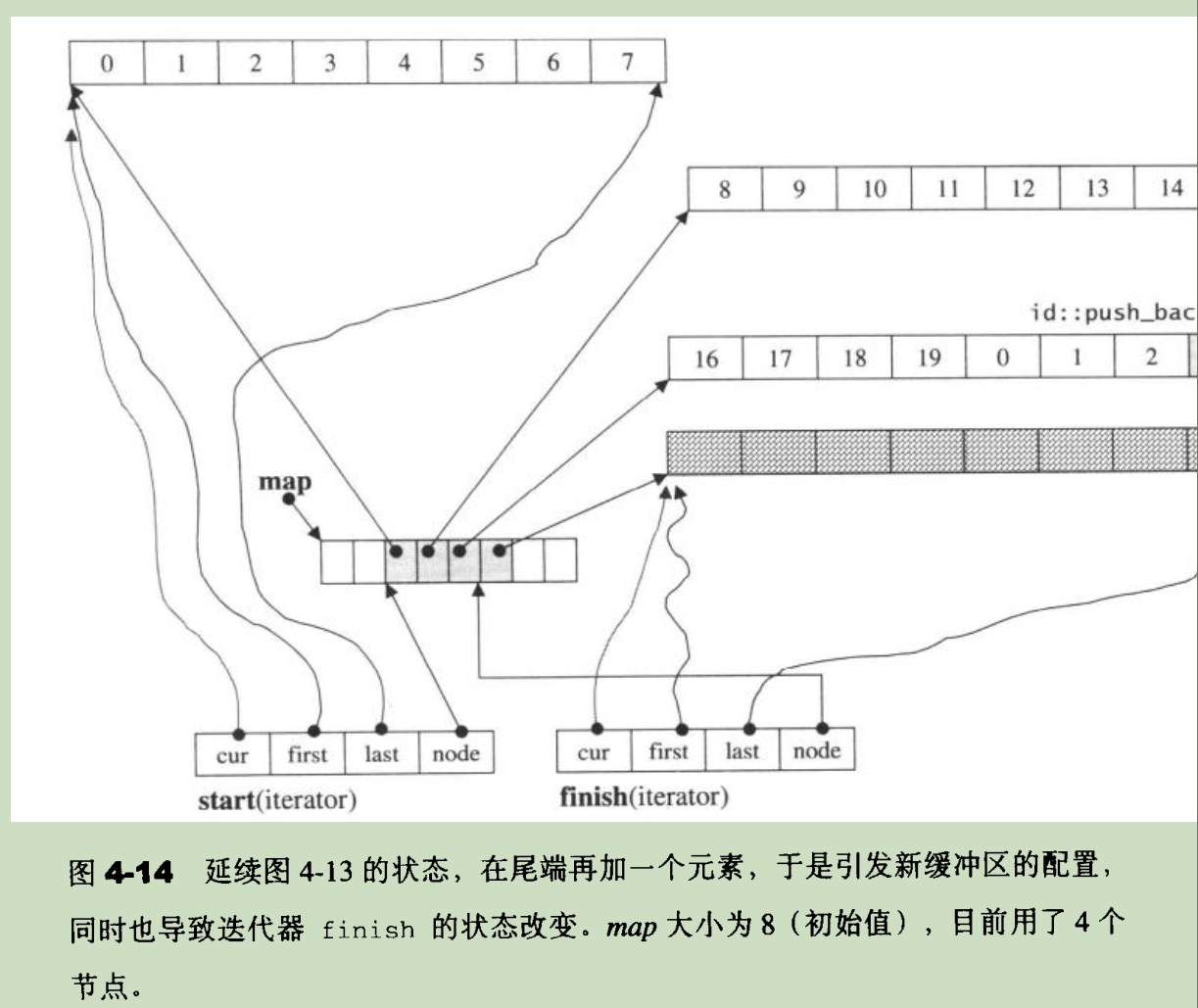
如果 map 的所有槽位都使用完毕了,则需要重新分配一个新的 map,新分配的 map 槽位数最小为 2*map_size+2,即原来 map 槽位数的两倍,再加上 2。分配 map 完毕后,需要将原来 map 的内容拷贝到新 map 的中间区域。
重新创建 map 由 deque::reallocate_map() 函数负责:

6. heap
6.1 数据结构
heap 是一种优先级队列,底层数据结构是一颗完全二叉树(complete binary tree)。
完全二叉树是指除了最底层的叶子节点,都是填满的,而最底层的叶子节点又从左至右不能有空隙。
由于 heap 不需要对数据进行完全排序,所以采用完全二叉树的好处是数据插入和取极值都能获得 O(logn) 的平均时间复杂度。
完全二叉树是一种组织数据的方式,但是 heap 的数据并不是直接存储在树的每个节点中的。而是存储在顺序容器中,例如 vector(stl 源码剖析 4.7.1 节):
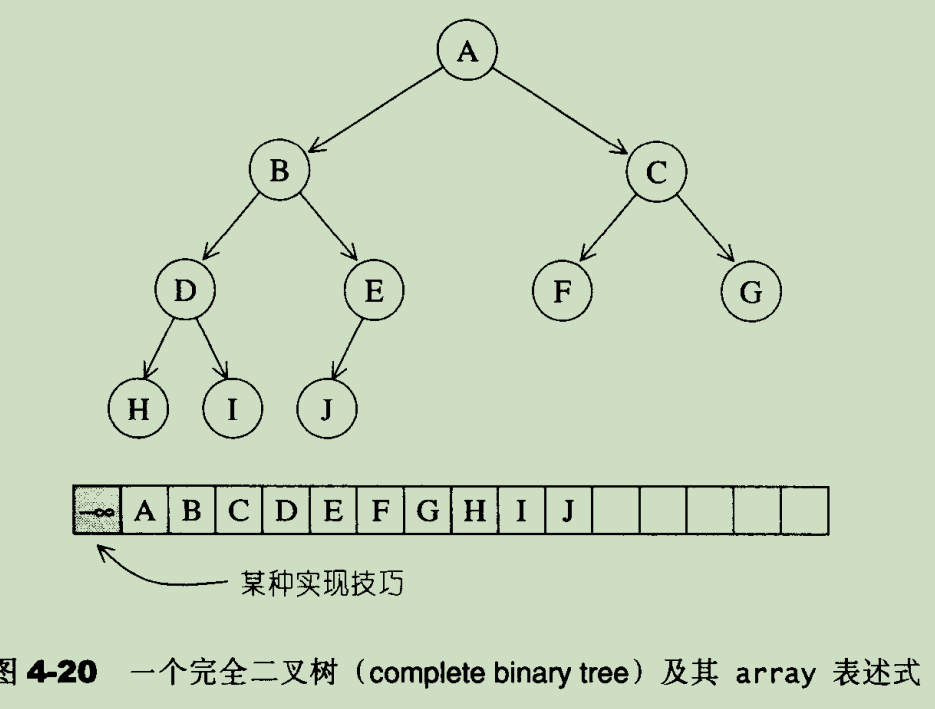
仔细观看 vector 中存储数据的方式,正是二叉树层次遍历的结果。那么就会有如下性质:
- 一个节点在 vector 中的索引为 i,那么左子节点的索引为 2i,右子节点的索引为 2i+1
- 最后一个非叶子节点的索引为 heap::size()/2,heap::size() 返回 heap 中的元素个数
6.2 迭代器
不提供迭代器。
6.3 元素插入和取极值
优先级队列的初始化分为建堆和调整堆,元素插入和取出后也需要调整堆。具体算法可以参见 https://www.cnblogs.com/chengxiao/p/6129630.html 。
6.4 priority_queue
基于 heap 实现的配接器。
7. rb-tree
红黑树是一种平衡二叉搜索树,提供二叉搜索树有序的特征(中序遍历有序),且不会退化成链表(平衡,增删改查都能提供 O(logn) 的平均时间复杂度)。
7.1 数据结构
rb-tree 插入元素的时候必须满足二叉搜索树的特征。其次,必须维持平衡性(stl 源码剖析 5.2 节):
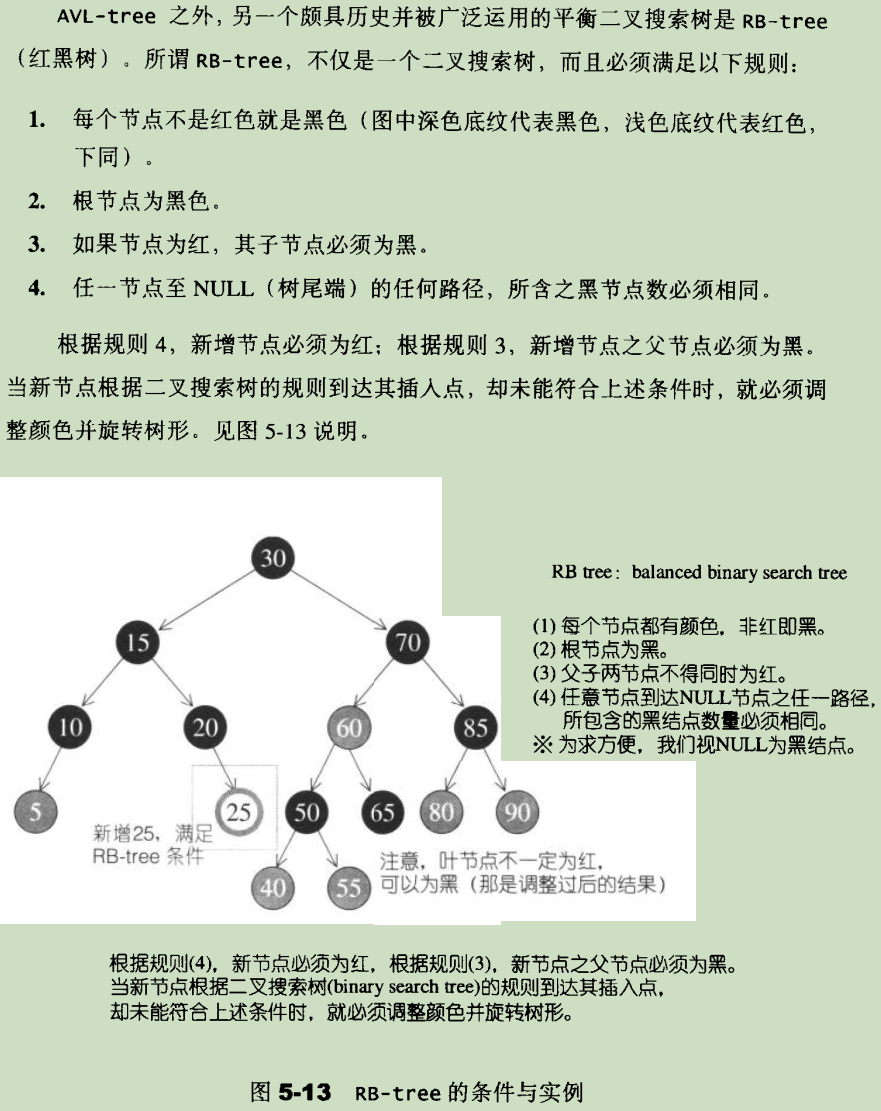
rb-tree 通过以上规则维持平衡性。实际上还有一种 avl-tree,也提供自平衡特性,它的平衡性规则定义比较简单,即任何节点的左右子树高度差不能超过 1。
rb-tree 的数据存储在树的节点之中,且由于迭代器提供了遍历的功能,每个节点需要有指向其父节点的指针(stl 源码剖析 5.2.3 节):

7.2 迭代器
rb-tree 的迭代器是一种 bidirectional iterator(双向迭代器),即提供 ++、-- 操作,但是不提供随机访问的操作。
rb-tree 设计了一个 header 节点,此节点并不存储元素,而是时刻通过 header::parent 指针指向 root 节点;header::left 指向最左子节点;header::right 指向最右子节点(stl 源码剖析 5.2.5 节):

一个 rb-tree 与 header 节点的关系如下:
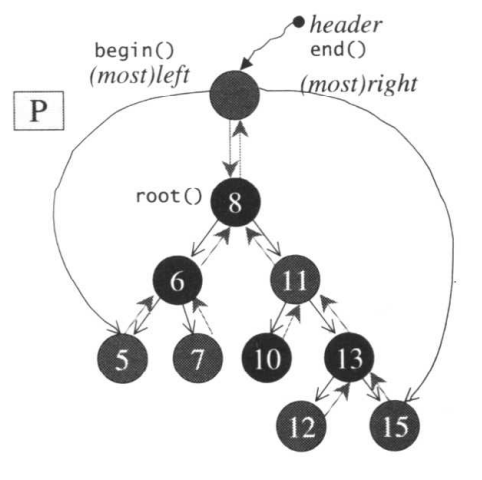
借助 header 节点,那么 tree::begin() = header::left,tree::end() = header(符合 stl 容器左闭右开的规则)。
7.2.1 迭代器失效
rb-tree 删除当前迭代器,会使得当前迭代器失效,其它迭代器继续有效。
这里有一个陷阱就是如果在 for 循环中继续使用被删除的迭代器,那么会引发严重错误(tree::erase(iter) 并不会返回下一个有效迭代器),因此,for 循环中删除迭代器的安全做法是:
for (auto& iter = map.begin(); iter != map.end(); ) {
if ( 满足某些条件 ) {
auto tmpIter = iter;
iter++;
map.erase(tmpIter);
// map.erase(iter++) 或者这样
} else {
iter++;
}
}
7.3 map、multimap
map 容器是基于 rb-tree 的配接器,要求 key 值唯一。
multimap 容器是基于 rb-tree 的配接器。不同于 map,multimap 不要求 key 值唯一。
multimap 提供了 multimap::equal_range(key) 接口来查找所有 key 值等于目标的节点,并返回 [start, end) 迭代器区间,multimap 不提供 operator[key] 重载接口。
7.4 set、multiset
都是于 rb-tree 的配接器。与 map 的区别是 key-value 相同。
8. hash_table
8.1 数据结构
hash_table 类似一种字典结构,它将 key 值利用 hash function 映射到存储索引,由于计算 key 的存储索引是 O(1) 时间复杂度的,所以 hash_table 在数据增删改查上具有平均 O(1) 的时间复杂度。
hash_table 一般利用 vector 作为底层存储结构,key 值会被映射到 vector 的索引。
由于 hash function 计算不同的 key 值有可能会映射到同一个索引,这种情况称为 hash 冲突。
得到存储索引后并不是直接将其存储即可,因为存在 hash 冲突的问题,所以下面介绍数据的存储组织方法(也叫解决 hash 冲突的方法)。
8.1.1 线性探测(linear probing)
首先需要介绍负载系数(loading factor)的概念,负载系数等于容器内元素个数除以容器大小。
假设现在有一个接受 int 型 key 的 hash function 如下:
hash_function(key) {
index = key % 10;
return index;
}
且底层存储容器 vector 的大小是固定的,线性探测法的原理是,如果索引所在的槽位已经被使用了,那么将会顺序查找下一个可用的存储槽位(stl 源码剖析 5.7.1 节):
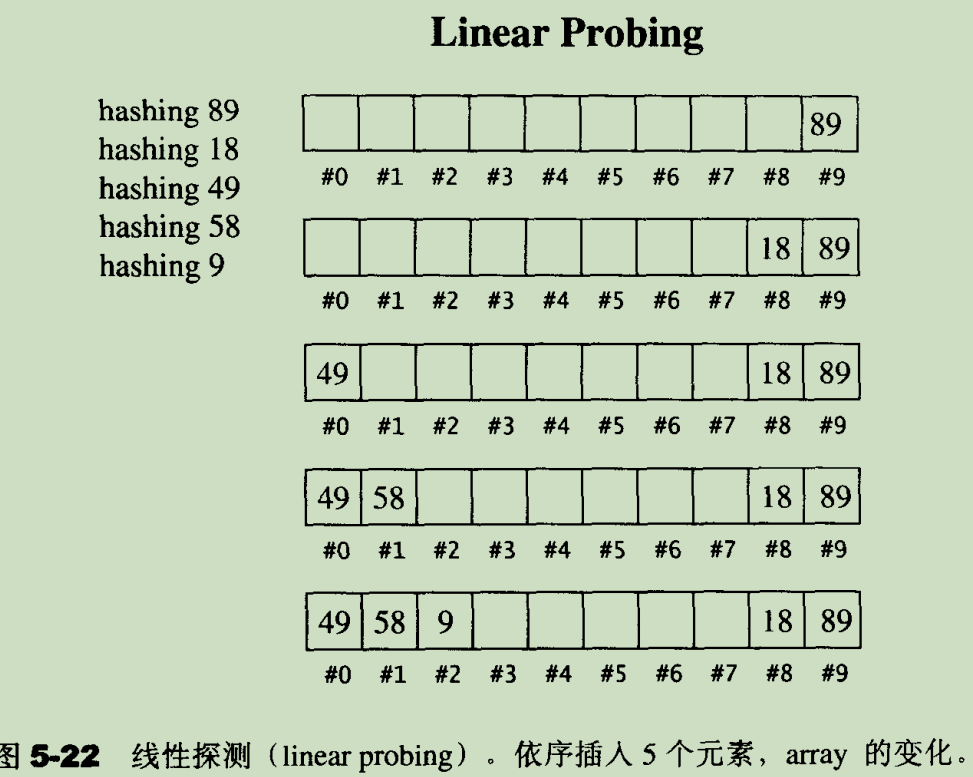
此方法的问题是,出现 hash 冲突时,顺序查找使得平均时间复杂度变得过大。
且容器内元素越多,hash 冲突概率越大,顺序查找下一个可用槽位时间复杂度越高,即数据插入的时间复杂度增长越来越大于负载系数的增长,这种现象称为主集团(primary clustering)问题。
8.1.2 二次探测(quadratic probing)
二次探测法解决主集团问题的方法是利用一个碰撞方程(stl 源码剖析 5.7.1 节):
F(i) = i^2
如果 hash function 计算的位置为 H,且已经被使用,那么二次探测法将依次尝试 H+12、H+22、H+3^2 ... H+i^2,而线性探测的碰撞方程实际上是 H+1、H+2、H+3 ... H+i。
一个示例如下(stl 源码剖析 5.7.2 节):
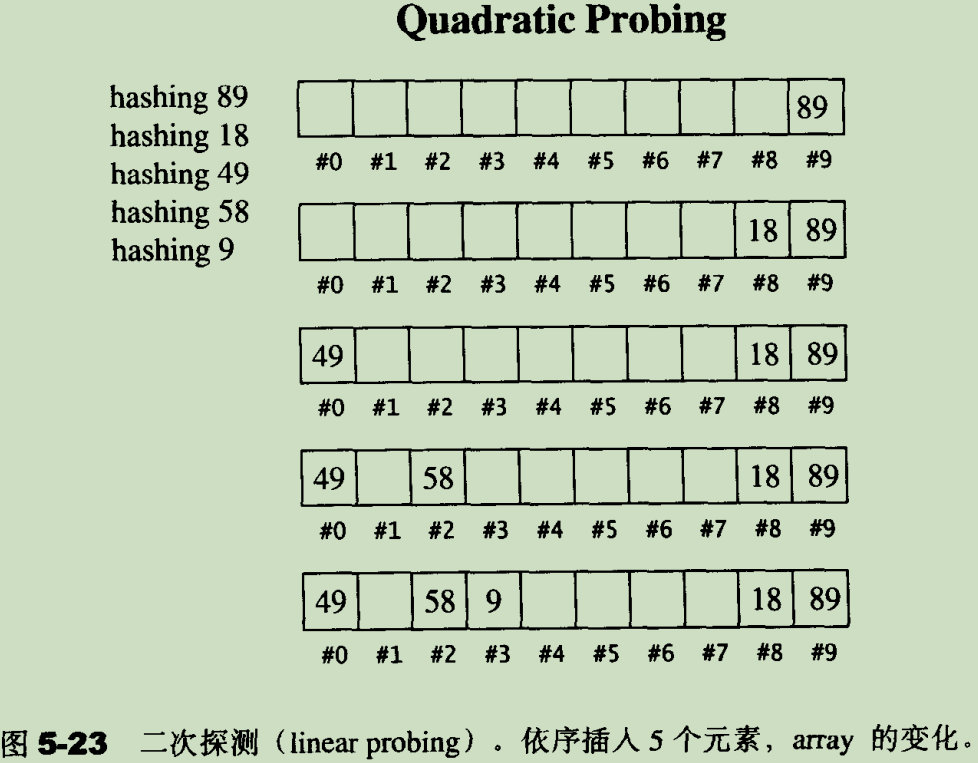
但是,这样还不够,二次探测还有如下约束:
- 底层存储容器的大小为质数
- 保持负载系数为 0.5 以下
通过以上规则,二次探测法就能解决主集团问题,每插入一个新元素,探测次数不超过 2(当然,这里需要严格的数学证明,stl 源码剖析 并未给出证明,具体还需要查阅网上的其它资料)。
8.1.3 开链(separate chaining)
开链法将底层存储容器 vector 中每个槽位称为桶(bucket),桶中存储的是一个链表,每个链表节点结构如下(stl 源码剖析 5.7.2 节):

一个 hash_table 的存储示例如下(stl 源码剖析 5.7.2 节):
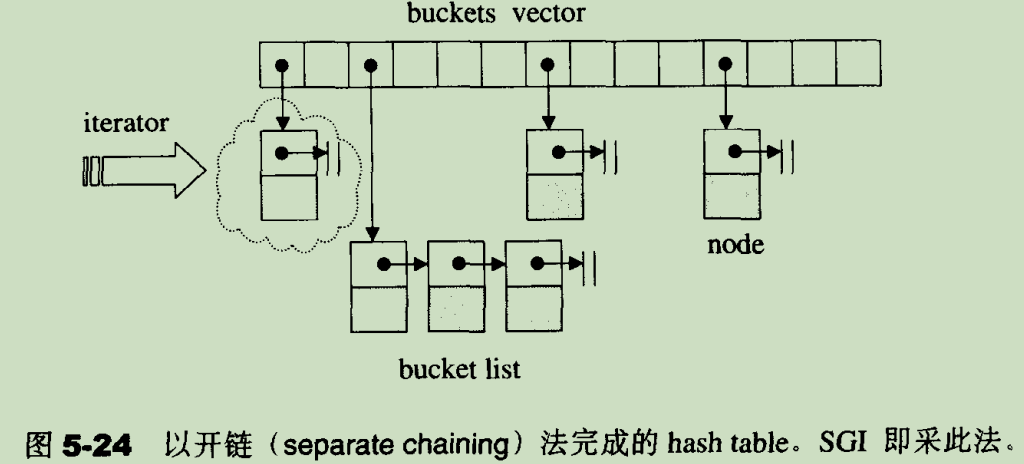
当 hash 冲突时,元素被插入到同一个桶的最后一个链表节点中。
hash_table 中 vector 的大小(capacity,非 size)并不是让其自由生长,而是只能取预定的质数大小(stl 源码剖析 5.7.4 节):

每次扩充 vector 时,都会从质数列表中选出第一个大于等于目标大小的质数。
8.2 元素插入
在进行元素插入的时候,会判断是否需要扩充 vector 的大小(stl 源码剖析 5.7.5 节):

vector 需要扩充的判断依据是(stl 源码剖析 5.7.5 节):

vector 扩容后,hash_table 迭代器会失效,所有元素需要进行 re-hash 操作(但是之前通过 std::pair<key, value>& 持有的引用继续有效,参看 https://www.zhihu.com/question/60911582/answer/2463034030)。
8.3 迭代器
hash_table 的迭代器是 forward iterator 即前向迭代器,只提供 ++ 操作,不提供 -- 操作。
迭代器向前行进的时候,如果当前 node->next 为空,这个时候需要跳到下一个有效的槽位,处理如下(stl 源码剖析 5.7.3 节):

8.4 hash function
对于输入的 key 值,hash_table 通过调用 bkt_num() 函数来的到 key 对应的桶索引。
bkt_num() 函数是一个重载函数,提供多个版本,最终都会调用如下版本(stl 源码剖析 5.7.5 节):
// 接收键值和 buckets 个数
size_type bkt_num_key(const key_type& key, size_t n) {
return hash(key) % n;
}
即通过 hash function 取得一个整数值,然后对 vector 存储容器大小取余,即得到 key 对应的桶索引。
stl 提供了很多内建的 hash function,例如对于 char* 型的字符串,hash function 如下(stl 源码剖析 5.7.7 节):

对于自定义类型作为 key,就需要在创建 hash_table 的时候提供自定义 hash function。
9. string
9.1 数据结构
string 在不同编译器版本上有不同的实现,总体来说分为 3 种(参考 Linux多线程服务端编程:使用muduo C++网络库 12.7章):
- eager copy,即每个 string 对象一份字符串拷贝
- copy-on-write,即 COW,写时拷贝
- short-string-optimization,即 SSO,短字符串优化
9.1.1 eager copy
采用类似 vector 的 3 指针结构(Linux多线程服务端编程:使用muduo C++网络库 12.7.1章):

内存结构图示如下:
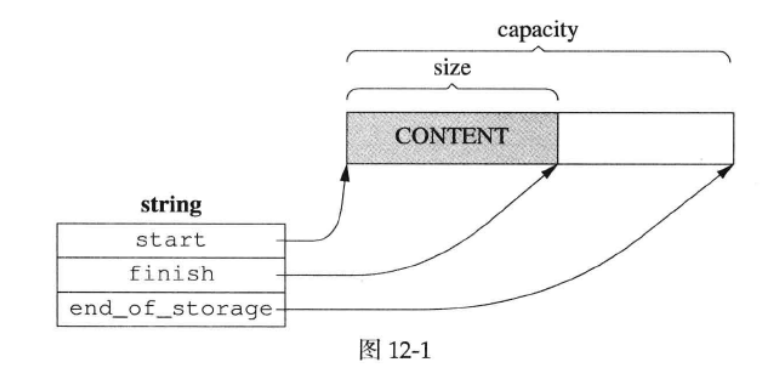
即分配一片堆内存用于存储字符串,再使用 3 个成员变量来管理空间。
string 的扩容也与 vector 类似,即每次 2 倍原来的 capacity 大小。
9.1.2 COW (GCC5.0 起,编译器已经不再支持使用此方法)
类定义如下(Linux多线程服务端编程:使用muduo C++网络库 12.7.2章):

内存结构图示如下:
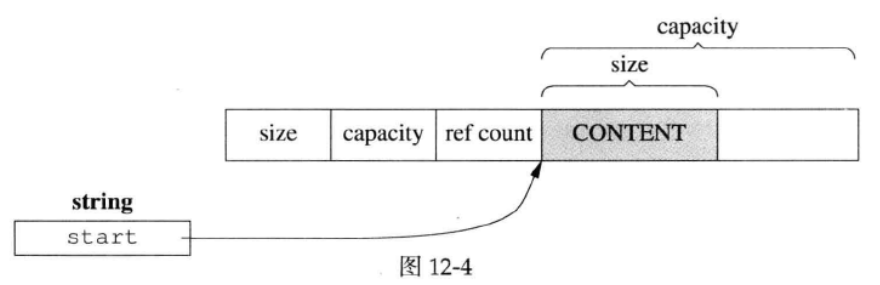
string 对象使用一个成员变量指向一片堆空间,堆空间除了存储有 size、capacity 内存管理信息外,还存有 ref_count 即引用计数器。
ref_count 是一个原子变量,在多线程场景下实现计数器的线程安全。
注意,这里的线程安全概念即类似 shared_ptr 的线程安全:
- 多线程通过 String& 或 String * 的方式,修改同一个 String 对象,不是线程安全的
- 多线程修改不同的 String 对象,这些不同的 String 对象内部管理的是同一份数据,是线程安全的
- 参考 https://www.zhihu.com/question/56836057 文章中的 _M_release() 函数
通过写时拷贝,使得多个 string 对象通过拷贝构造或拷贝赋值操作共享同一片堆空间,在其中一个 string 对象发生写行为时,会将共享内存区域拷贝出来。
但是写时拷贝机制在某些情况下会存在问题,考虑如下代码(https://stackoverflow.com/questions/12199710/legality-of-cow-stdstring-implementation-in-c11):
std::string s("str");
const char* p = s.data();
{
std::string s2(s);
(void) s[0];
}
std::cout << *p << '\n'; // p is dangling
s2 通过拷贝构造与 s 共享同一片内存存储区域,但是 s[0] 操作是一个写操作,会引发 s 拷贝独立的存储空间,这会使得指针 p 称为空悬指针。
9.1.3 SSO
类定义如下(Linux多线程服务端编程:使用muduo C++网络库 12.7.3章):

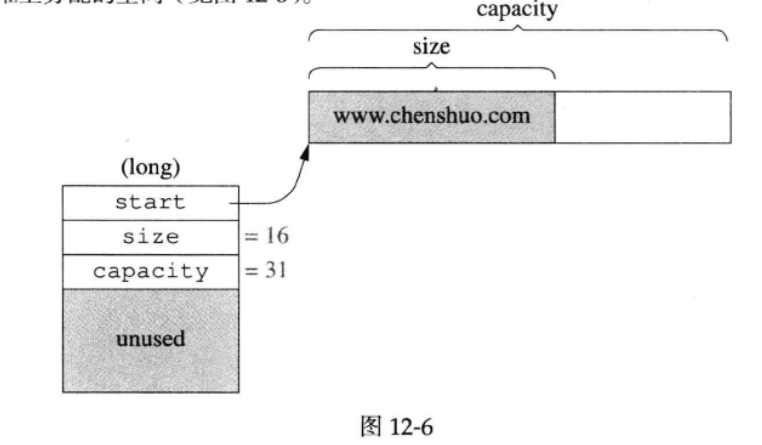
这里定义了一个联合体,在存储不超过 15 字节长度的字符串时,联合体用于存储字符串,capacity 字段不需要使用;当字符串长度超过 15 字节时,联合体用于表示 capacity,然后申请一片堆内存用于存储字符串。
短字符存储如下图所示(Linux多线程服务端编程:使用muduo C++网络库 12.7.3章):
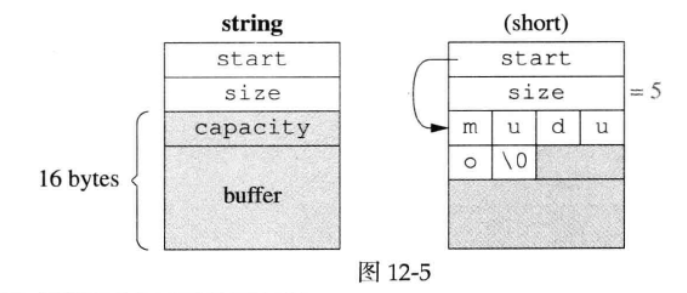
长字符存储如下图所示(Linux多线程服务端编程:使用muduo C++网络库 12.7.3章):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号