
机器学习十大算法系列
1.线性回归 (Linear Regression)
2.逻辑回归 (Logistic Regression)
3.决策树 (Decision Tree)
4.支持向量机(SVM)
5.朴素贝叶斯 (Naive Bayes)
6.K邻近算法(KNN)
7.K-均值算法(K-means)
8.随机森林 (Random Forest)
9.降低维度算法(Dimensionality Reduction Algorithms)
10.Gradient Boost和Adaboost算法
1.线性回归 (Linear Regression)
https://www.cnblogs.com/pinard/p/6004041.html
梯度下降(Gradient Descent)小结
http://www.cnblogs.com/pinard/p/5970503.html
最小二乘法小结
http://www.cnblogs.com/pinard/p/5976811.html
Lasso回归算法: 坐标轴下降法与最小角回归法小结
http://www.cnblogs.com/pinard/p/6018889.html
先来解释一下什么是回归。假设现在有一些数据点,我们用一条直线对这些点进行拟合,这个拟合过程就叫做回归。 线性回归是利用连续性变量来估计实际数值(例如房价,呼叫次数和总销售额等)。我们通过线性回归算法找出自变量和因变量间的最佳线性关系,图形上可以确定一条最佳直线。这条最佳直线就是回归线。这个回归关系可以用Y=aX+b 表示。




2.逻辑回归 (Logistic Regression)
https://www.cnblogs.com/pinard/p/6029432.html
逻辑回归是一个分类算法,它可以处理二元分类以及多元分类。虽然它名字里面有“回归”两个字,却不是一个回归算法。那为什么有“回归”这个误导性的词呢?个人认为,虽然逻辑回归是分类模型,但是它的原理里面却残留着回归模型的影子,本文对逻辑回归原理做一个总结。






3.决策树 (Decision Tree)
https://www.cnblogs.com/pinard/p/6050306.html
https://www.cnblogs.com/pinard/p/6053344.html
决策树算法在机器学习中算是很经典的一个算法系列了。它既可以作为分类算法,也可以作为回归算法,同时也特别适合集成学习比如随机森林。本文就对决策树算法原理做一个总结,上篇对ID3, C4.5的算法思想做了总结,下篇重点对CART算法做一个详细的介绍。选择CART做重点介绍的原因是scikit-learn使用了优化版的CART算法作为其决策树算法的实现。







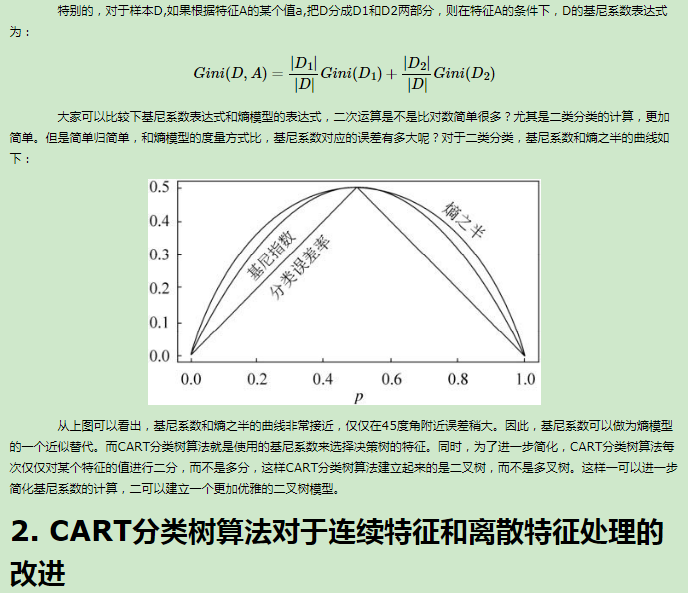







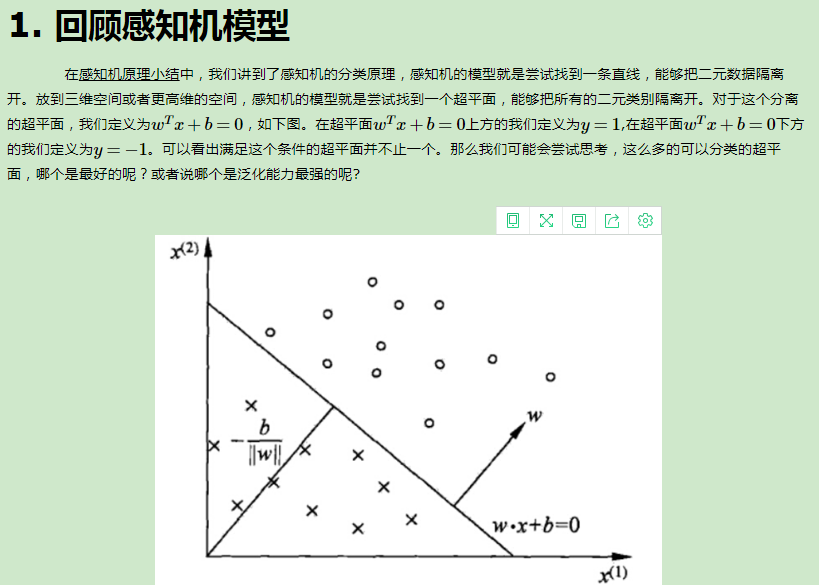
4.支持向量机(SVM)
https://www.cnblogs.com/pinard/p/6097604.html
支持向量机(Support Vecor Machine,以下简称SVM)虽然诞生只有短短的二十多年,但是自一诞生便由于它良好的分类性能席卷了机器学习领域,并牢牢压制了神经网络领域好多年。如果不考虑集成学习的算法,不考虑特定的训练数据集,在分类算法中的表现SVM说是排第一估计是没有什么异议的。
SVM是一个二元分类算法,线性分类和非线性分类都支持。经过演进,现在也可以支持多元分类,同时经过扩展,也能应用于回归问题。本系列文章就对SVM的原理做一个总结。本篇的重点是SVM用于线性分类时模型和损失函数优化的一个总结。


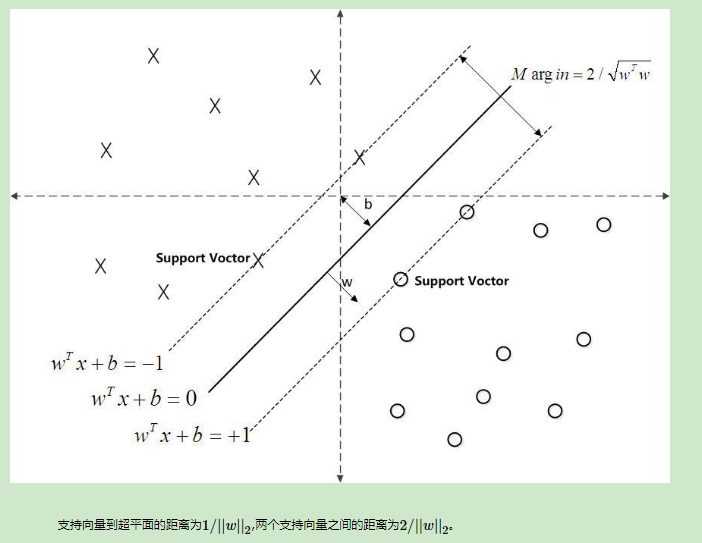







http://www.cnblogs.com/pinard/p/6100722.html
在支持向量机原理(一) 线性支持向量机中,我们对线性可分SVM的模型和损失函数优化做了总结。最后我们提到了有时候不能线性可分的原因是线性数据集里面多了少量的异常点,由于这些异常点导致了数据集不能线性可分,本篇就对线性支持向量机如何处理这些异常点的原理方法做一个总结。

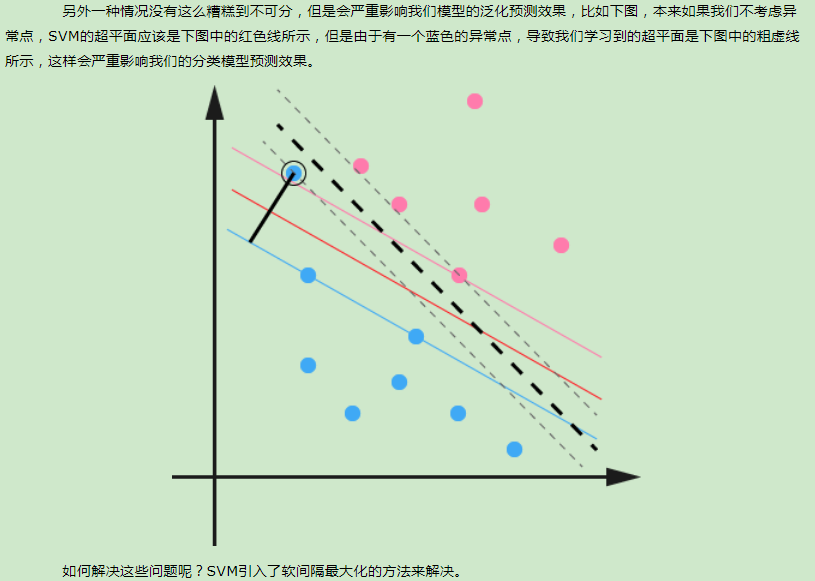


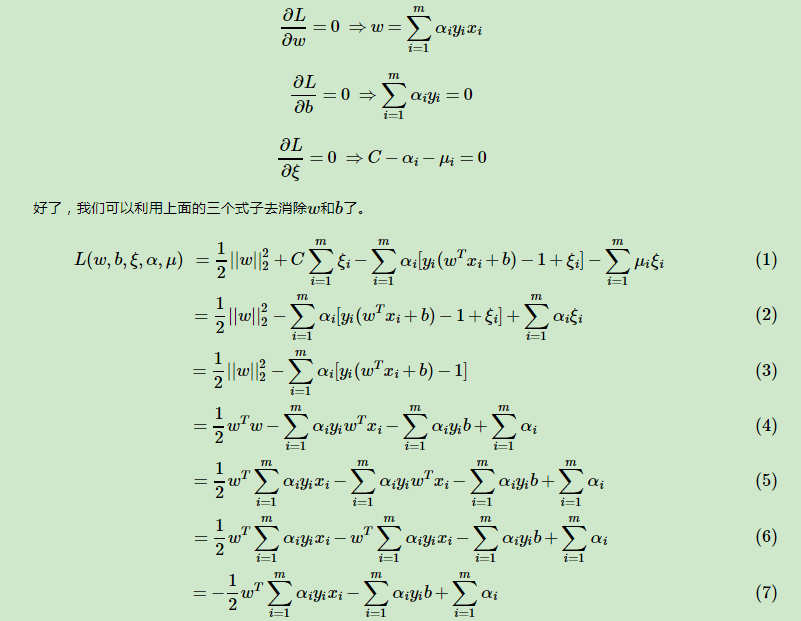



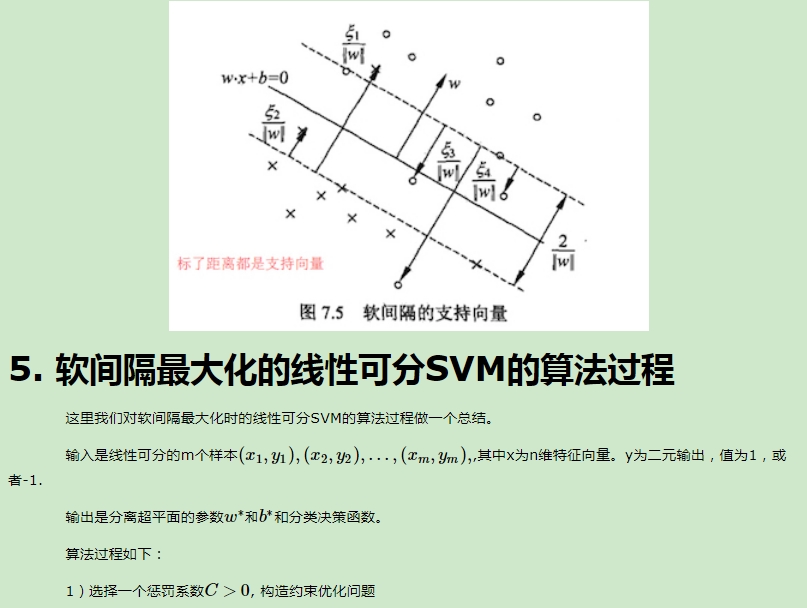



http://www.cnblogs.com/pinard/p/6103615.html
在前面两篇我们讲到了线性可分SVM的硬间隔最大化和软间隔最大化的算法,它们对线性可分的数据有很好的处理,但是对完全线性不可分的数据没有办法。本文我们就来探讨SVM如何处理线性不可分的数据,重点讲述核函数在SVM中处理线性不可分数据的作用。






http://www.cnblogs.com/pinard/p/6111471.html
在SVM的前三篇里,我们优化的目标函数最终都是一个关于αα向量的函数。而怎么极小化这个函数,求出对应的αα向量,进而求出分离超平面我们没有讲。本篇就对优化这个关于αα向量的函数的SMO算法做一个总结。










http://www.cnblogs.com/pinard/p/6113120.html
在前四篇里面我们讲到了SVM的线性分类和非线性分类,以及在分类时用到的算法。这些都关注与SVM的分类问题。实际上SVM也可以用于回归模型,本篇就对如何将SVM用于回归模型做一个总结。重点关注SVM分类和SVM回归的相同点与不同点。

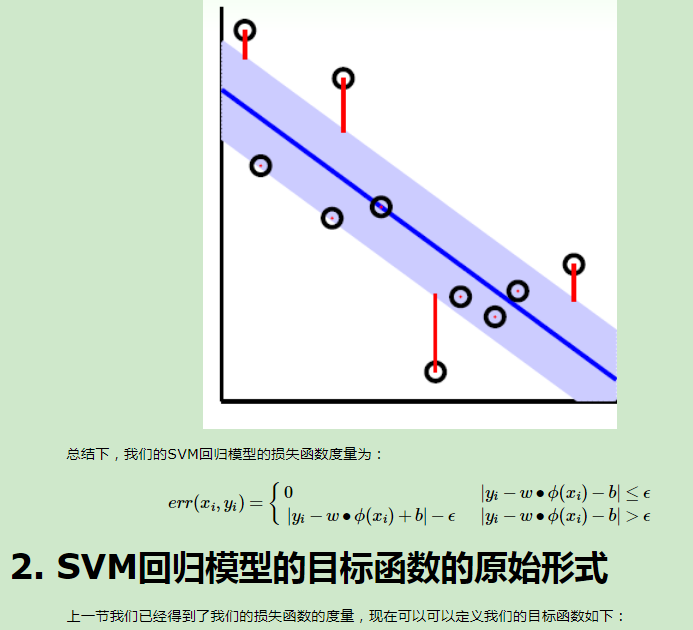





5.朴素贝叶斯 (Naive Bayes)
https://www.cnblogs.com/pinard/p/6069267.html









6.K邻近算法(KNN)
https://www.cnblogs.com/pinard/p/6061661.html
K近邻法(k-nearest neighbors,KNN)是一种很基本的机器学习方法了,在我们平常的生活中也会不自主的应用。比如,我们判断一个人的人品,只需要观察他来往最密切的几个人的人品好坏就可以得出了。这里就运用了KNN的思想。KNN方法既可以做分类,也可以做回归,这点和决策树算法相同。
KNN做回归和分类的主要区别在于最后做预测时候的决策方式不同。KNN做分类预测时,一般是选择多数表决法,即训练集里和预测的样本特征最近的K个样本,预测为里面有最多类别数的类别。而KNN做回归时,一般是选择平均法,即最近的K个样本的样本输出的平均值作为回归预测值。由于两者区别不大,虽然本文主要是讲解KNN的分类方法,但思想对KNN的回归方法也适用。由于scikit-learn里只使用了蛮力实现(brute-force),KD树实现(KDTree)和球树(BallTree)实现,本文只讨论这几种算法的实现原理。其余的实现方法比如BBF树,MVP树等,在这里不做讨论。



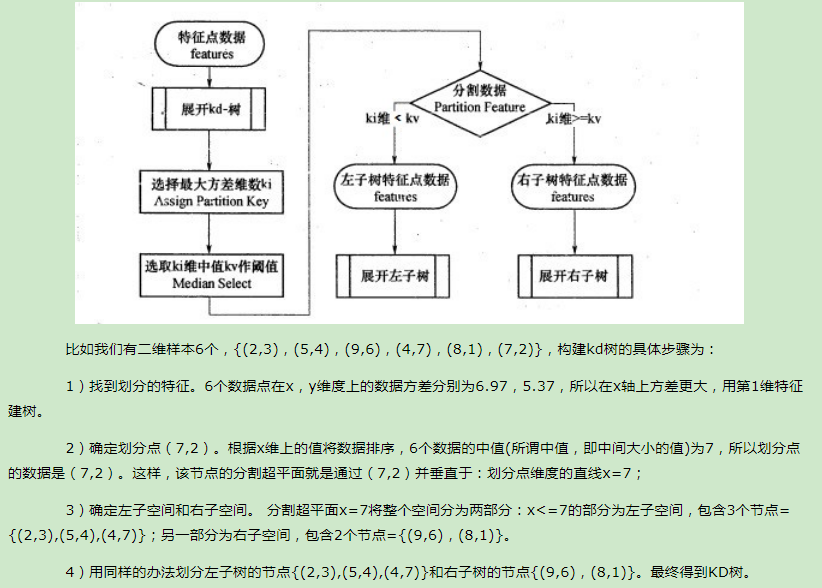


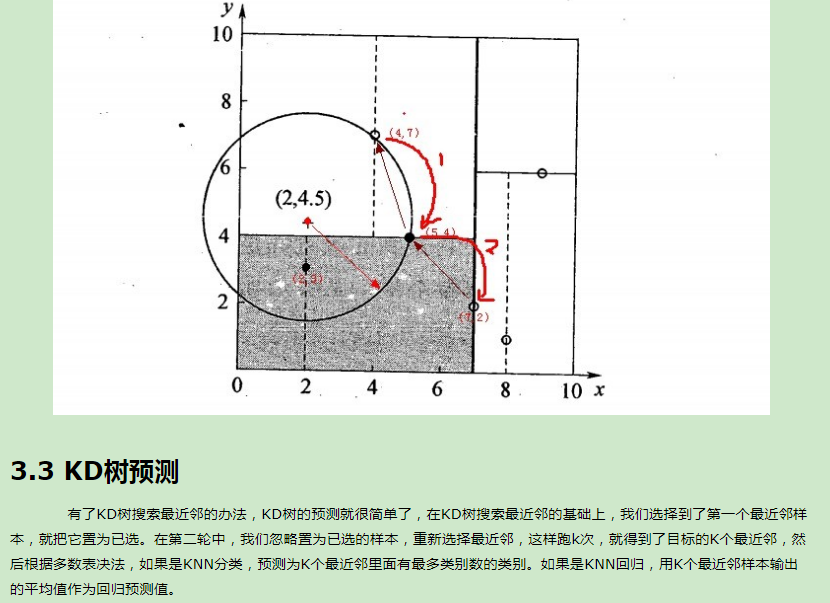




7.K-均值算法(K-means)
http://www.cnblogs.com/pinard/p/6164214.html
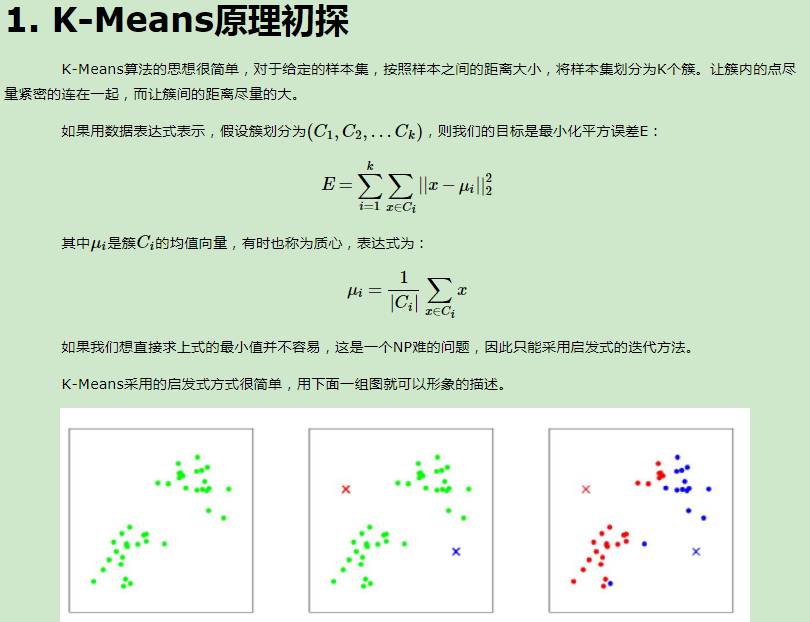
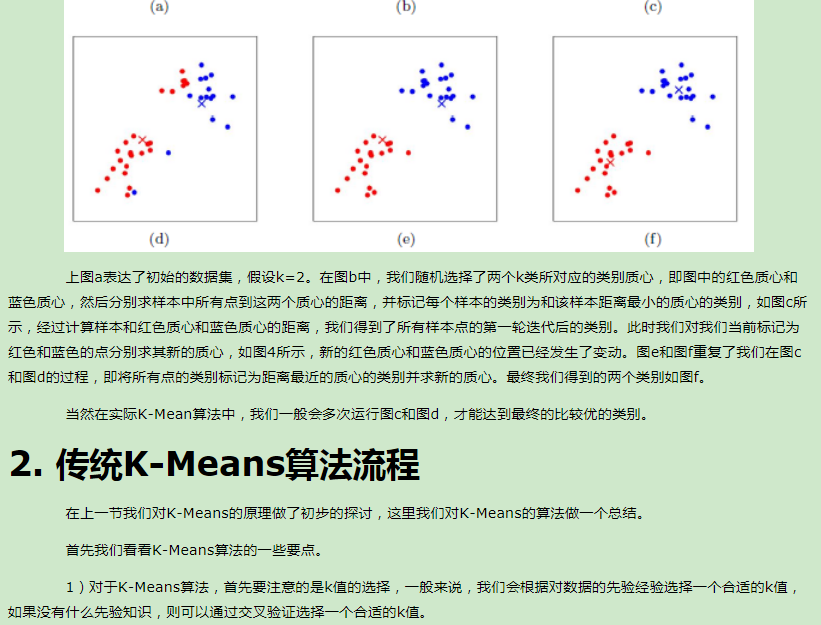
K-Means算法是无监督的聚类算法,它实现起来比较简单,聚类效果也不错,因此应用很广泛。K-Means算法有大量的变体,本文就从最传统的K-Means算法讲起,在其基础上讲述K-Means的优化变体方法。包括初始化优化K-Means++, 距离计算优化elkan K-Means算法和大数据情况下的优化Mini Batch K-Means算法。




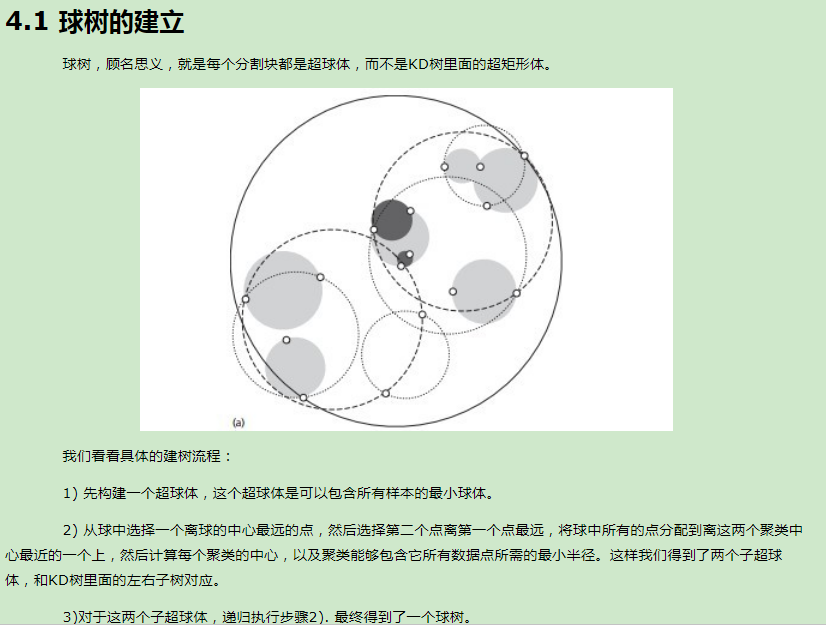
8.随机森林 (Random Forest)
https://www.cnblogs.com/pinard/p/6156009.html
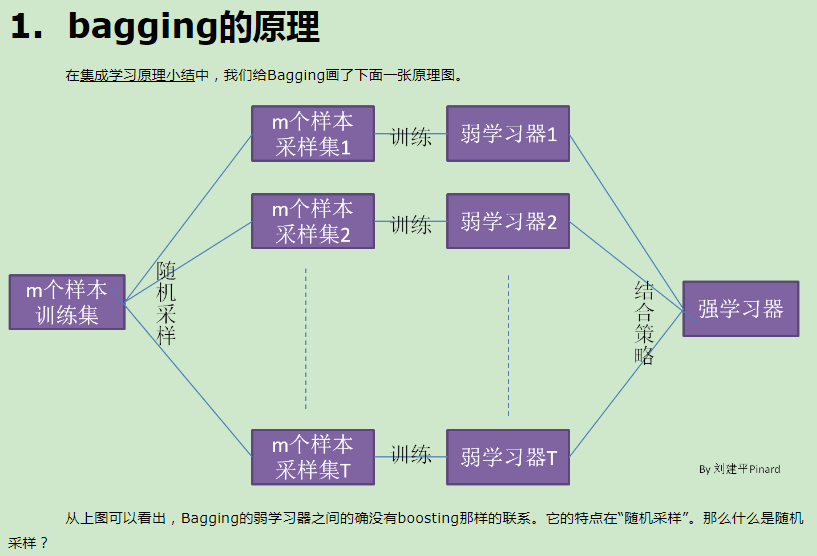
在集成学习原理小结中,我们讲到了集成学习有两个流派,一个是boosting派系,它的特点是各个弱学习器之间有依赖关系。另一种是bagging流派,它的特点是各个弱学习器之间没有依赖关系,可以并行拟合。本文就对集成学习中Bagging与随机森林算法做一个总结。
随机森林是集成学习中可以和梯度提升树GBDT分庭抗礼的算法,尤其是它可以很方便的并行训练,在如今大数据大样本的的时代很有诱惑力。






9.降低维度算法(Dimensionality Reduction Algorithms)
https://www.cnblogs.com/pinard/p/5970503.html
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法。这里就对梯度下降法做一个完整的总结。









10.Gradient Boost算法
https://www.cnblogs.com/pinard/p/6140514.html
在集成学习之Adaboost算法原理小结中,我们对Boosting家族的Adaboost算法做了总结,本文就对Boosting家族中另一个重要的算法梯度提升树(Gradient Boosting Decison Tree, 以下简称GBDT)做一个总结。GBDT有很多简称,有GBT(Gradient Boosting Tree), GTB(Gradient Tree Boosting ), GBRT(Gradient Boosting Regression Tree), MART(Multiple Additive Regression Tree),其实都是指的同一种算法,本文统一简称GBDT。GBDT在BAT大厂中也有广泛的应用,假如要选择3个最重要的机器学习算法的话,个人认为GBDT应该占一席之地。









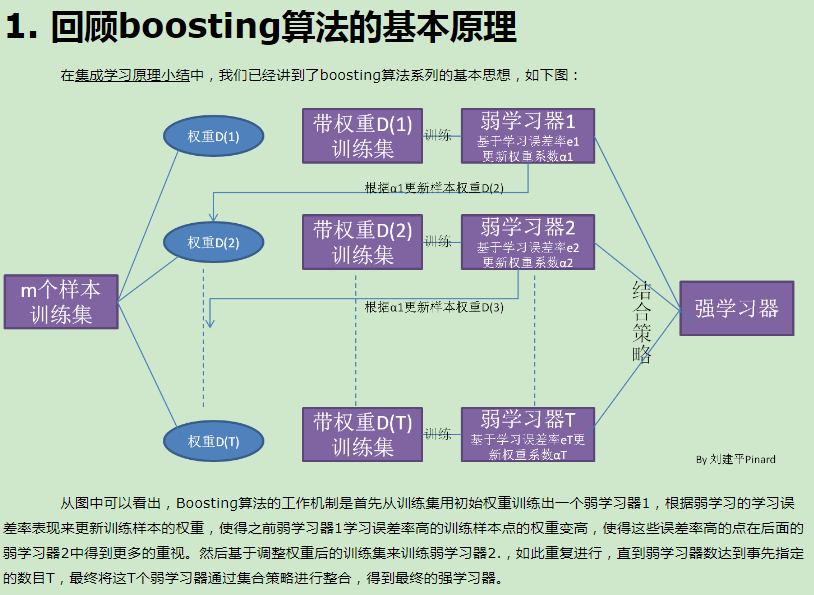
11.Adaboost算法
https://www.cnblogs.com/pinard/p/6133937.html
在集成学习原理小结中,我们讲到了集成学习按照个体学习器之间是否存在依赖关系可以分为两类,第一个是个体学习器之间存在强依赖关系,另一类是个体学习器之间不存在强依赖关系。前者的代表算法就是是boosting系列算法。在boosting系列算法中, Adaboost是最著名的算法之一。Adaboost既可以用作分类,也可以用作回归。本文就对Adaboost算法做一个总结。












 浙公网安备 33010602011771号
浙公网安备 33010602011771号