RAG项目实战:基于图文PDF的多模态问答RAG项目(二)之文档解析和分块
按照一中的调研思路,这一部分记录关于建立文档库的相关操作和反思:这里主要做的工作包括:pdf解析、pdf数据清洗、chunk以及入库。
I. 进行pdf文件解析,注意:为了符合比赛规则,先基于页码进行分割然后再进行chunk。
这部分由于比赛方推荐了MinerU,我计划先使用这个工具进行尝试。
一、MinerU学习及使用:
1. MinerU概述:
1)介绍:
MinerU 是由上海人工智能实验室下属的 OpenDataLab 团队于2024年7月推出的开源文档智能提取工具,旨在高效地将复杂的多模态PDF文档(包含文本、公式、表格、图像、页眉页脚、脚注等)转换为结构清晰、机器可读的 Markdown 或 JSON 格式,从而为大模型训练和AI应用提供高质量的数据语料支持。
2)配置要求:
要使用mineru的全部功能对硬件的配置要求比较高,之前我用ragflow跑文件解析也确实消耗了大量的时间,这里应该需要做一些并行优化。
2. 安装:参考:https://opendatalab.github.io/MinerU/zh/quick_start/
minerU存在不同性能的:
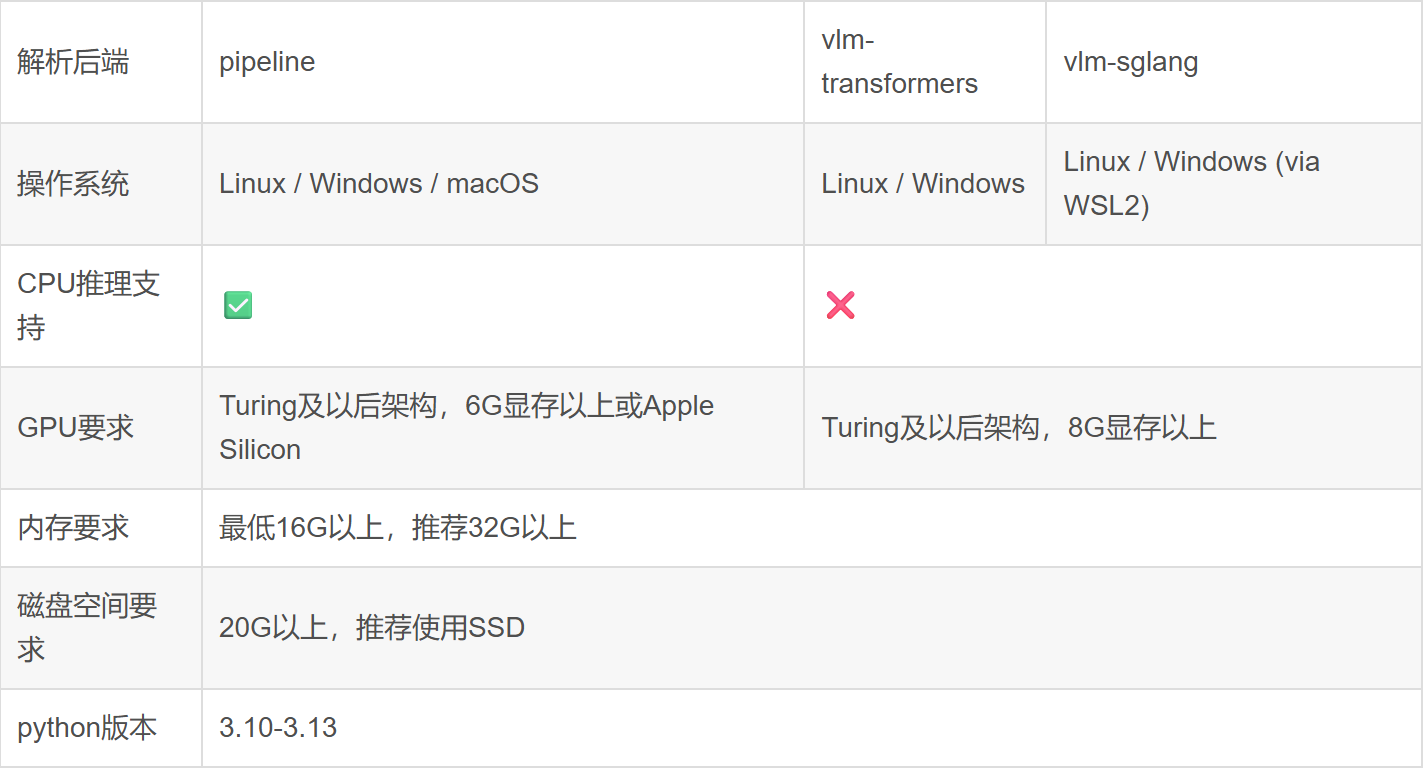
安装[core]版本:mineru[core]包含除vllm加速外的所有核心功能,兼容Windows / Linux / macOS系统,适合绝大多数用户。 如果您有使用vllm加速VLM模型推理,或是在边缘设备安装轻量版client端等需求,可以参考文档扩展模块安装指南。
使用uv安装需要先安装uv:
pip install --upgrade pip -i https://mirrors.aliyun.com/pypi/simple pip install uv -i https://mirrors.aliyun.com/pypi/simple uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
需要先使用uv init生成一个pyproject.toml文件,记得加入:
[tool.setuptools]
py-modules = []
然后安装mineru[core]:
uv pip install -U "mineru[core]" -i https://mirrors.aliyun.com/pypi/simple
vllm的安装:这一步比较麻烦,后续有时间的话再花费时间来做这一块。(可以提速,目前我的知识库数据量是120+个pdfs)
补充知识:
1)uv:是一种新的python包管理工具和项目工作流工具,比pip要快10-100倍
3. 调用:⭐
这里参考了https://www.cnblogs.com/mgtpez/p/19030149/datawhale-learn-rag里的文档解析代码,发现minerU可以通过sdk的方法进行调用,具体函数逻辑mineru的官方文档并没有写,所以需要开发人员自己去看代码研究。我这里总结一下参考代码里使用的主要函数:
(待补充完善)
过程中的问题:
1)需要更换模型源:huggingface需要FQ。
在脚本中加入:
import os os.environ["MINERU_MODEL_SOURCE"] = "modelscope"
4. 实现逻辑思考:
代码结合mineru的pdfs处理思路是识别文档、图片和表格,并识别pdfs的布局,在布局的基础上进行了分块:json文件的内容是这样的:
实际上是对整个pdf的布局进行了内容识别:对应可视化的pdfs layout如下:
# json文件: [ { "type": "text", "text": "商业化成绩显著,产品矩阵持续拓宽艾力斯(688578.SH)深度报告", "text_level": 1, "bbox": [ 97, 87, 616, 136 ], "page_idx": 0 },.... ]
上述参数bbox的意味是在layout里的一个边界箱的坐标信息。

最终把每一页的内容转换成了html格式的文件,这里是按照上述的布局分析结果进行的拼接。(这里应该也有优化空间)
注意:文字解析,图片解析成了图片标题、图片地址(图片内容理解如何做?),表格解析做成的是按照每一行进行读取的markdown格式。
思考1:mineru自动进行了chunk吗?这里如果后续要调整的话,如何调整?-> 没有进行chunk,mineru是基于布局的分块,就是上图显示的。
思考2:原理上mineru实现了文档不同块之间的关联性分析了吗?需要对mineru的原理进行学习,or 具体学习它分析页面布局之后的结果。
思考3:文档解析和入库后续可以做工程上的并行优化。
思考4:markdown对于大模型来说就好理解了?
II. 分块操作
1. 不同的分块策略:https://mp.weixin.qq.com/s/xR9Bjczplqtcl0IIBiu1jA
1)有简单的分块就是直接对文本进行token数目指定,overlap指定。
2)语义分块:
3)递归分块:
4)段落分块、页面分块、智能体分块等等。
2. 实验操作
按照调研的经验和baseline提供的做法先仅按照页面分块。
分成的块的最后格式是字典形式(包含metadata等)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号