机器学习:对象检测和定位算法 RCNN 和 YOLO
定位和检测
把图片里的物体找到并框起来
比如把图片中的车子找到并框起来
比如人脸识别,对于全身照,要先把脸部找出来,然后再做识别
甚至要求找出图片的多种物体,比如自动驾驶,需要同时检测到红绿灯、行人、车辆、路面状况等
通常要输出:是否找到、类别 (one-hot)、画框 (中心点的 X 和 Y,以及宽度 W 和高度 H)
直接用神经网络
训练集:要找出物体的图片
标签:是否找到、类别、位置坐标 (X,Y,W,H)
网络:CNN 层,后面接两个并行的独立的全连接层,一个用于分类,一个用于回归计算位置
缺点:计算量太大,收敛时间太长,难以训练,效果差
滑动窗口
先训练一个能对图片分类的 CNN
训练集尽可能只有目标对象,比如图片里只有车,并且这车填满整张图,而不是图的一小部分
给定一张要找出物体的图片
用一个框,在图片上滑动,每次取一部分,作为输入传到 CNN
如果能识别到物体,那就把类别及概率记下 (CNN 的输出是分类概率 - softmax)
由于目标大小是不确定的,还需要用不同大小的框去滑动
最后在所有能识别到物体的框中,选取概率最高的那个框
将该框的分类,以及该框的中心点和高和宽作为位置输出
缺点:计算量还是太大,因为要用的框实在是太多了,而且这些框还有大量的重叠的地方
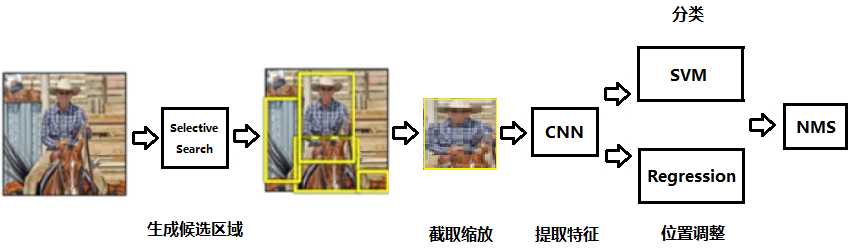
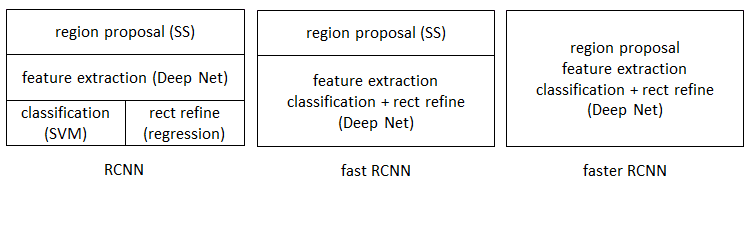
R-CNN (Region CNN)
2014 年,为了解决框太多的问题而提出来的,步骤如下
- 输入图像
- 生成候选区域,比如 2K 个候选区域 (BBox - Bounding Box)
- 对每个候选区域的图像,缩放到 CNN 网络的要求,然后放入 CNN 网络提取特征
- 将提取的特征,如 4096 维特征,放入分类器(每个分类一个 SVM 分类器),判别是否属于该类
- 对于识别出分类的框,采用 NMS 非极大抑制算法,剔除有重复的框
- 将提取的特征,以及框的位置,使用回归器修正候选框位置
- 最终输出所有检测到的 (x,y,长,宽,分类)
训练样本需要标注 BBox
如何选择候选框?使用 Selective Search 算法
- 首先将图像分割成许多的小区域
- 计算所有相邻区域的相似度 (颜色相近,纹理相近)
- 合并相似度高的区域,并重新计算新的相似度
- 不断重复直到没有区域可以合并了
- 输出所有存在过的区域(不仅是合并后的区域)
NMS 非极大抑制算法
- 对于属于某个类别的框,比如检测出车的所有框,按给出的概率从大到小排序
- 挑选最大概率的框,剩下概率更低的框分别与这个框计算 IoU (Intersection over Union,交集除以并集)
- IoU 超过某个值的就说明重复比较多,把概率小的框删除
- 在仍然存在的框中,挑选概率第二高的,重复上面的步骤 2 和 3
- 对所有类别都做这个操作
这样就去掉了重复较大的框,注意每类别可能有多个框,比如图片中有多辆车,多个人
由于 Selective Search 挑选出来的框,可能有偏差,比如偏左,偏上,偏小,偏大,等等,需有修正
通过回归器计算,输入是特征值,输出是要移动的距离,要缩放的大小
候选框经过缩放、移动后,和真实的 BBox 比较计算损失,经过训练后回归器就可以用于精修位置
缺点:
- 训练太慢,要 80 多小时
- 检测也慢,要 40 多秒钟
- 输入大小固定,导致图片需要变形
还需要改进
Fast R-CNN
RCNN 最大的问题在于要做多次 CNN 计算,如果有 2000 个框就是 2000 次
Fast R-CNN 只进行一次 CNN 特征提取,就是对整张图做 CNN,得到特征图 Feature Map,候选区域选择依然用 Selective Search 和 RCNN 一样,但是得到的候选框,不需要再做 CNN 了,而是根据映射关系,直接从特征图上提取就可以,比如原图 200 x 200,特征图 20 x 20,某个候选框位于原图从(20,20)开始,长宽各 40 ,对应的就是特征图上从 (2,2)开始,长宽各 4 的特征框,把这个特征框的特征直接取出后,用于分类和位置精修
Fast R-CNN 还用了一个 ROI(Region of Interest)Pooling,在特征图选择之后,ROI 将保证分类器和回归器的输入是大小固定的,正常的池化层大小步长是固定的,而 ROI 不是,而是按对输出大小的要求决定,比如要求输出是 10 x 10,那么 20 x 20 的输入,池化的大小是 2 x 2 步长是 2,而 30 x 30 的输入,池化的大小可以是 3 x 3,步长是 3,这样不管输入图片大小多少,特征图的大小多少,最终分类器和回归器的输入大小是固定的
后面用分类器判断分类,用回归器修改位置,用非极大抑制算法剔除重复区域
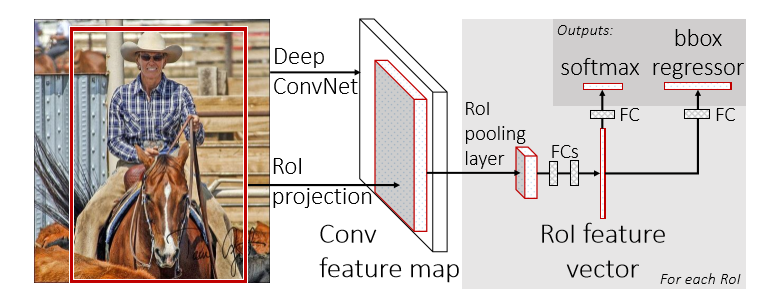
RCNN 的分类和回归,用 SVM 和回归算法,Fast R-CNN 则都是用神经网络处理
对比 RCNN,Fast RCNN 的训练时间从 80 多小时减少到 9 小时,检测时间从 40 多秒减少到 2 秒
Fast-RCNN 的缺点是信息损失:首先,在特征映射部分,坐标缩放如果不能整除,就会损失部分信息,对于小的候选框影响比较大;其次,在 ROI Pooling 部分,由于强行控制池化大小和步长,同样会有信息的损失
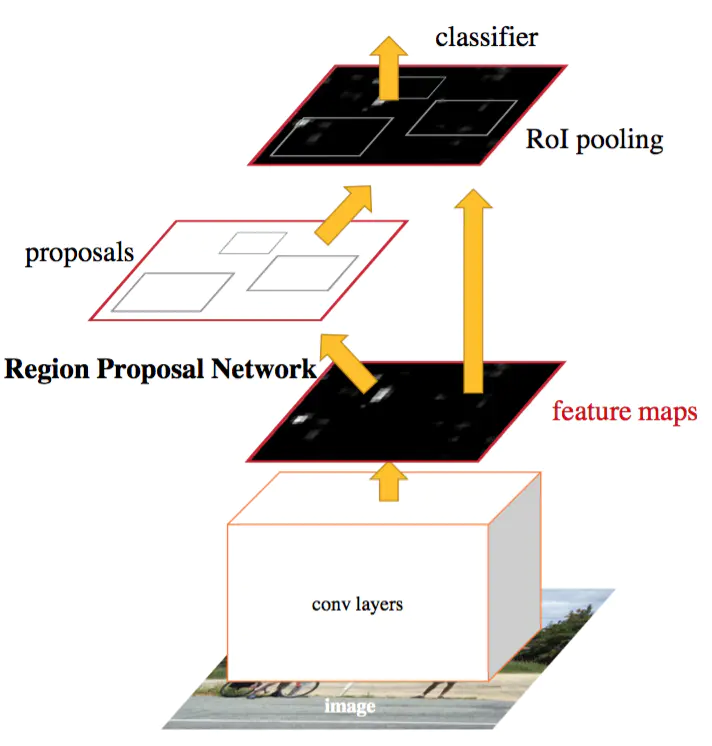
Faster R-CNN
Fast R-CNN 依然要用 Selective Search 生成候选框,这是比较花时间的,而且无法用 GPU 运算
既然 feature map 是输入图片的特征,那么其实可以在 feature map 上选择候选框,并且可以让 CNN 选择
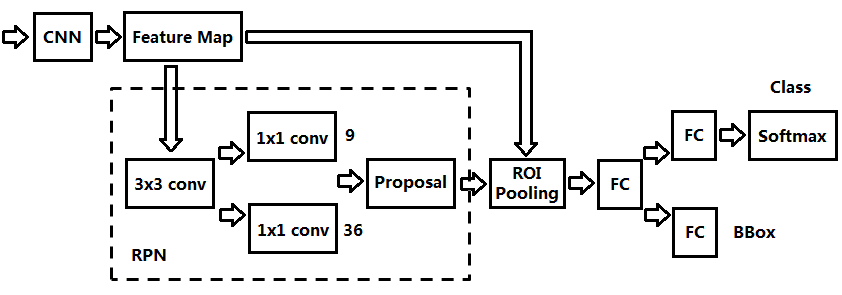
这个用于选择候选框的网络叫 RPN(Region Proposal Network)
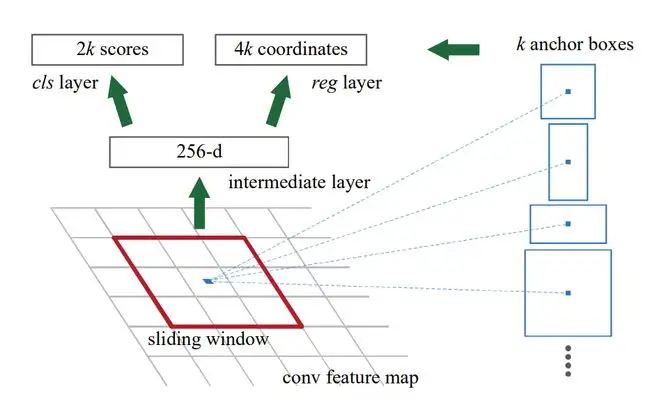
RPN 先对 feature map 使用 256 个 3x3 的卷积核进行计算
每次卷积计算(上图红色框),形成一个 256 维的 1 x 1 特征数据
这个新的特征数据,将用于预测,以红色框中的蓝色点为中心,所预设的 K 个大小的框,是否有物体,以及要修改的偏移
这里的 K 个预设好的框,也叫 anchor boxes,在作者的实现里为 K 为 9 个
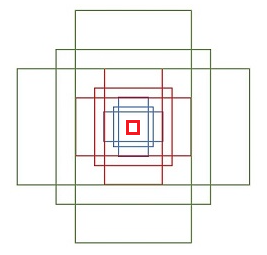
这 9 个 anchor box 的大小和位置,是一开始就设计好的,如下图所示
anchor box 共分 3 组,绿色组 3 个,红色组 3 个,蓝色组 3 个
每组分别由 3 个长宽分别约为 1:2,1:1,2:1 的 anchor box 组成
并且绿色的长宽是红色长宽的两倍,红色长宽是蓝色长宽的两倍
最里面的红色框,代表卷积核,也就是上图红色框,所对应的原始图的区域
在作者的 demo 中,feature map 是 16 倍压缩,也就是红色框卷积核代表的区域是 48 x 48
而最小的正方体 anchor 为 128 x 128,最大的正方体 anchor 为 512 x 512
如果用的输入图是 800 x 600,已经能覆盖多数区域了
对这个 256 维数据,再并行地做两个卷积计算
分别是用 2 x K = 18 个 1 x 1 x 256 的卷积核,以及 4 x K = 36 个 1 x 1 x 256 的卷积核,进行计算
产生 18 个结果,以及 36 个结果
其中 18 个分数代表这 9 个 anchor box 的背景分数和前景分数,如果前景的可能性较大,那就要对其检测
而 36 个位置代表 9 个 anchor box 的调整信息,包括要变化的 x,y,width,height 四个值
红色框卷积核不断滑动,产生了所有需要检测的区域,实际上会有密密麻麻一堆框,能检测到多数物体了
然后就和 Fast RCNN 一样了,将要检测的区域映射到特征图相应的位置,取出区域特征后,再做 ROI 池化确保大小固定,再全连接,再分别送入分类器和位置精修器,得到检测结果,再用非极大抑制算法剔除重复区域,得到最终结果
这里有个疑问,卷积核大小只是 3 x 3,对应的原图区域也就 48 x 48,但卷积结果却可以用来判断比这个区域大,甚至大很多的 anchor box,是否是前景物体,以及要修正的位置,听起来很奇怪,但作者却强调是可行的,打个比方,当我们在某个区域看到一个人脸图片,我们就可以判断出完整的人的图片的大小是多少,以及如何移动缩放这个区域使得它包含完整的人的图片,哪怕判断出的完整图片不对,比如这个人的下半身被其他东西遮住了看不到,但这没关系,这样这个推荐框在后面进一步分类时得分偏低,会被非极大抑制算法剔除,所以说这也有道理,这个能力可能确实是可以学习到的,但外面最大的框,和卷积核处理的区域大小差这么大,居然也能处理,感觉还是有点怪
Faster RCNN 可以认为是 RPN + Fast RCNN
再次强调,anchor box 是预先设计的,在训练的时候预先标注好实际 box 框,以及该框是前景还是后景,以及 anchor box 相对于该实际 box 要平移缩放的参数,等等,可以改变 anchor 数量 k,anchor 大小,等等,再重新训练
(样本不标注 anchor box,而是 anchor box 与实际 box 的偏移缩放,系统学习如何把 anchor box 调整到实际 box)
这样,目标检测的四个步骤(候选区域生成,特征提取,分类,位置精修)被统一到一个深度网络框架内
RPN 不仅本身就快,还可以用 GPU,检测速度更快,可以去到 0.2 秒
缺点:小目标效果不好
产生 anchor 的代码参考
http://t.zoukankan.com/yanshw-p-15543509.html
YOLOv1 (You Only Look Once)
RCNN 属于 Region Based 方法,也叫两阶段(2 stages)方法
就是需要做两次扫描,先找到可能存在物体的区域,再对这些区域进行分类判断
而 YOLO 属于 Region Free 方法,也叫单阶段(1 stages)方法
只需要扫描一次,就可以找出图片中的物体和位置
这也是为什么算法名字叫 You Only Look Once
Faster CNN 在获取候选区域的时候,已经能判断该区域有没有物体,以及该物体的大概位置,那能不能同时把物体的分类,更精确的位置也给计算出来,YOLO 就是这种思想,所以只需要一个阶段
YOLO 有多个版本
YOLOv1 网络

这里 64-s-2 代表这 64 个卷积核的步长是 2,没指定的就是 1
写着多个卷积核的是串联,比如 128 个 1x1 卷积核,再接 256 个 3x3 卷积核
YOLO 将图片划分为 SxS 个 grid 网格,每个网格会有 B 个中心点在该网格内的 Bounding Box,但 Box 的大小不局限于该 grid,而是可以跨越多个 grid,就是实际上不是对小网格识别,而是对中心落在某个网格的、面积可能跨越多个网格的框进行识别(和 Faster RCNN 类似但这 B 个 Bounding Box 不是事先规划好,而直接就是最终输出的框)
如下图,共有 7 x 7 = 49 个网格,蓝色 Box 的中心点落在第 5 行的第 2 列网格,所以这个 Box 由这个网格生成检测
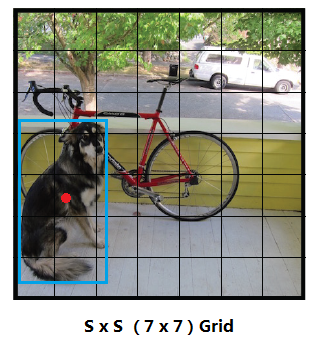
每个 Bounding Box 输出 (x,y,w,h,p)5 个参数,其中 x 和 y 是 box 中心点相对于 grid 的左上角的位置,w 和 h 是 box 的长宽相对于图片长宽的大小,p 是该 box 有物体的概率,这样取值的目的是归一化
假设
box 的中心点是 \(\small x_{b}\),\(\small y_{b}\),大小是 \(\small w_{b}\),\(\small h_{b}\)
grid 的左上角是 \(\small x_{g}\),\(\small y_{g}\),大小是 \(\small w_{g}\),\(\small h_{g}\)
图片大小是 \(\small w_{t}\),\(\small h_{t}\)
那么
\(\large x = \frac{x_{b} - x_{g}}{w_{g}}\) \(\large y = \frac{y_{b} - y_{g}}{h_{g}}\)
\(\large w = \frac{w_{b}}{w_{t}}\) \(\large h = \frac{h_{b}}{h_{t}}\)
加上
\(\large p(obj)\) 表示 box 有物体的概率
这样每个 box 就有 5 个输出值
box 的输出不包括类别,类别属于 grid 的输出,v1 版本中一个 grid 只能输出一个分类,表示为
\(\large p(class | obj)\) 在有物体的前提下属于 class 的概率
假设分类总数 C,那么总的输出大小是
\(\large S \times S \times (B \times 5 + C)\)
作者设计 S=7,B=2,C=20,所以 \(\small 7 \times 7 \times (2 \times 5 + 20) = 7 \times 7 \times 30\),这就是上面网络图中最后一层输出的大小
后面还需要挑选合适的 Box,先是把概率太低的去掉,然后采用 NMS 非极大抑制算法,和 RCNN 一样,如果有多个相同分类的 Box 的面积重复较多,也就是 Box 间的 IoU 比较大,那么需要把概率相对低的 Box 去掉,只留下概率最高的作为输出,NMS 分数的计算方法如下,相同分类且 IoU 较大的 Box 就比较这个分数,只保留最大的
\(\large p(obj) \times p(class | obj)\)
标记样本的 Y 的时候,如果一个 grid 没有物体,那就把该 grid 的所有输出(共 $\small B \times 5 + C $ 位)都标记为 0,如果有物体,就挑选其中一个物体(因为 YOLOv1 每个 box 只能找出一个分类),然后把该 grid 的所有 box 的 x,y,w,h 都标记成这个选中的物体,该 grid 的所有 box 的 p 都标记成 1,而 grid 的分类 C 的相应位置为 1,其他位置为 0
这样经过训练,系统就学到了如何在输入图片的各个 Grid 寻找 Box 以及分类的能力,能学到这样的能力,主要由网络设计(卷积 + S*S 组 Grid 的输出) + 样本设计(样本 Box 的中心分布在各个 Grid)实现的
但这还有一些缺点,比如由于算法实际上没做限制,导致预测的时候某个 Grid 输出的点会跑到其他 Grid(在 v2 版本解决),比如由于没有预定义框,输出位置的大小变化较大,不稳定,不容易收敛(在 v2 版本解决),比如每个 Grid 只能预测一个 Box,每个 Grid 只能预测一个分类(在 v3 版本解决),比如只有一个感受野较大的特征图,导致对小物体效果不好(在 v3 版本解决),等等,后续版本陆续改进
训练中,计算损失函数时,Box 的置信度,也就是输出的 p,是由 $\small P(obj) \times IoU $,既该 box 有物体的概率乘以该 box 和真实 box 间的 IoU ,通常大于 50% 才认为是正确的检测,训练中 NMS 的分数计算是 \(\small P(class | obj) \times P(obj) \times IoU\)
损失函数
\(\large L = \lambda_{coord} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{ij}^{obj} [(x_{i} - \widetilde{x}_{i})^{2} + (y_{i} - \widetilde{y}_{i})^{2}] \ \ +\)
\(\large \lambda_{coord} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{ij}^{obj} [(\sqrt{w}_{i} - \sqrt{\widetilde{w}_{i}})^{2} + (\sqrt{h}_{i} - \sqrt{\widetilde{h}_{i}})^{2}] \ \ +\)
\(\large \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{ij}^{obj} (C_{i} - \widetilde C_{i})^{2} \ \ +\)
\(\large \lambda_{noobj} \sum_{i=0}^{S^{2}} \sum_{j=0}^{B} I_{ij}^{noobj} (C_{i} - \widetilde C_{i})^{2} \ \ +\)
\(\large \sum_{i=0}^{S^{2}} I_{i}^{obj} \sum_{c \in classes} (p_{i}(c) - \widetilde p_{i}(c))^{2}\)
其中
\(\large I_{i}^{obj}\) 表示第 i 个 grid 有没有物体,有就是 1,没有就是 0
\(\large I_{ij}^{obj}\) 表示第 i 个 grid 的第 j 个 box 有没有物体,有就是 1,没有就是 0
\(\large I_{ij}^{noobj}\) 表示第 i 个 grid 的第 j 个 box 有没有物体,有就是 0,没有就是 1
\(\large \lambda_{coord}\) 提高有物体的 box 的坐标权重,比如 = 5,因为有物体的 box 比较少
\(\large \lambda_{noobj}\) 降低没物体的 box 的分类权重,比如 = 0.5,因为没物体的 box 比较多
\(\large C_{i}\) 表示 Box 的置信度 \(\small P(obj) \times IoU\)(不理解为什么不写 \(\small C_{ij}\),但原论文确实这样写)
\(\large p_{i}(c)\) 表示第 i 个 grid 的物体为 c 的概率,既 \(\small P(class | obj)\)
可以看到,有物体的会执行第 1、2、3、5 个式子,没有物体的执行第 4 个式子
优点
- 端到端的网络结构,较为简单
- 检测速度快,每秒可以处理几十帧,甚至可以用于视频
- 背景误检率低,分类还算较为准确
- 通用性强,对于艺术作品中的物体检测同样适用
缺点
- 在大小不同的物体上泛化能力较差,检测小目标效果差(大小物体 IoU 误差对 loss 贡献值接近,但实际小物体的 IoU 误差影响较大,尤其影响小物体的定位,全连接层输出对图像大小泛化能力不足)
- 靠的近的物体或有重合的物体(grid 内有多个物体)检测效果不好(只有两个框一个类)
- 不能做多标签分类(grid 只能一个分类)
- 位置精准性较差 (不如 RCNN,没有专门的 Region Proposal,每个 grid 就 2 个 box,而 RCNN 上千个)
- mAP(mean average precision,所有类别平均精度的平均值)较低,recall (召回率)较低(和分类准确度较高不冲突,recall 低就像图中有 10 个人但只预测了 3 个,准确度高就是这 3 次预测都是对的)
还是有不少改进空间的
YOLOv2
YOLOv2 提出了 Better,Faster,Stronger,对这三个方面做了改进
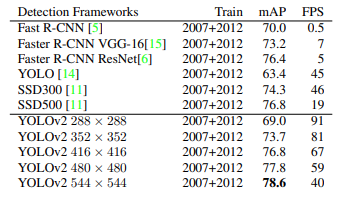
下面是原论文 ( https://arxiv.org/pdf/1612.08242.pdf )列举的 mAP 的比较

YOLOv2 主要做了以下改进
Batch Normalization(归一化)
在每个卷积层后面都加归一化层,不要 Dropout
这样加快了收敛,起到正则化作用,防止过拟合
mAP 提升了 2.4%
High Resolution Classifier(高分辨率分类)
YOLO v1 是在 224 x 224 训练,然后用于 448 x 448 检测
而 YOLO v2 用 224 x 224 训练,然后再用部分 448 x 448 样本数据作 10 个迭代训练,对模型微
(不直接用 448 x 448 是因为现成的样本很多是 224 x 224 的)
mAP 提升了 4.3%
Convolutional With Anchor Boxes(使用 Anchor Box)
YOLO v1 每个 grid 只有两个 Box,而且是靠全连接网络生成的
YOLO v2 则借鉴了 Faster RCNN 的 anchor box 方法,预先给每个 grid 定义一些 anchor box
用卷积网络预测 anchor box 的置信度,以及对 anchor box 的偏移
设计预定义框,使得系统要学习的是实际框相对于多个预定义框的偏移变化
这样输出变化较小,较稳定,更容易收敛
还把全连接层去掉了,最后一个池化层后直接接 softmax,并且最后的 feature map 改成 13 x 13
假设每个 grid 有 9 个 anchor box,那总共就有 13 x 13 x 9 = 1521 个
尽管 mAP 下降了 0.3%,但 recall 从 81% 提高到了 88%
Darknet-19(新网络模型)
设计了新的卷积网络模型,叫 Darknet-19,同样没有全连接层,主要作用是计算更快
Dimension Clusters(通过聚类找合适的 anchor box)
Faster RCNN 的 anchor box 是靠经验设定的
YOLO v2 用 k-means 算法对训练集的实际框做聚类分析,计算距离用
$\small d(box, centroid) = 1 - IoU(box, centroid) $
centroid 是 K-means 选做中心的 box
最终选择了 5 个聚类中心,作为 5 个 anchor box,其模型复杂度和 recall 比较平衡
这样 box 数变成 13 x 13 x 5 = 845
Direct location prediction(直接位置预测)
迭代的早期容易出现模型的不稳定,多数不稳定来自对 box 的 (x, y) 位置的预测
原因是调整 (x,y) 有可能调整到相邻的 box 里面去了,解决方法是对偏移的范围加了限制
这个限制加上聚类找 anchor box,带来约 5% 的 mAP 的提升
Fine-Grained Features (Passthrough 精细粒度特征)
13 x 13 的 feature map 可能太小,导致一些小物体的特征体现不出来
YOLOv2 引入 Passthrough 层
在最后一层之前是 26 x 26 x 512,然后卷积变成 13 x 13 x 1024,这个保持不变
但同时加一个并行的 Passthrough 层
这层把 26 x 26 x 512 在长宽这个维度拆成 4 个 13 x 13 x 512,不做其他计算,只是拆
然后拼成 13 x 13 x (512 x 4) = 13 x 13 x 2048
再和原来的 13 x 13 x 1024 拼成 13 x 13 x 3072
这样就多了更多细粒度的特征信息
这个可以带来 1% 的 mAP 的提升
Multi-Scale Training(多尺度训练)
前面在 448 x 448 做了训练,但还不够
现在选更多图片,每 10 个 batch 就随机挑选新的尺寸
带来约 1.4% 的提升
hi-res detector(高分辨率检测)
使用高分辨率的图片检测,可以提升约 1.8 %
可以看到,在做了很多改进后,mAP 慢慢从 63.4% 提高到了 78.6%
YOLOv2 能够扩展到检测 9000 种不同对象,有时也称为 YOLO 9000
YOLOv3
https://pjreddie.com/media/files/papers/YOLOv3.pdf
网络结构
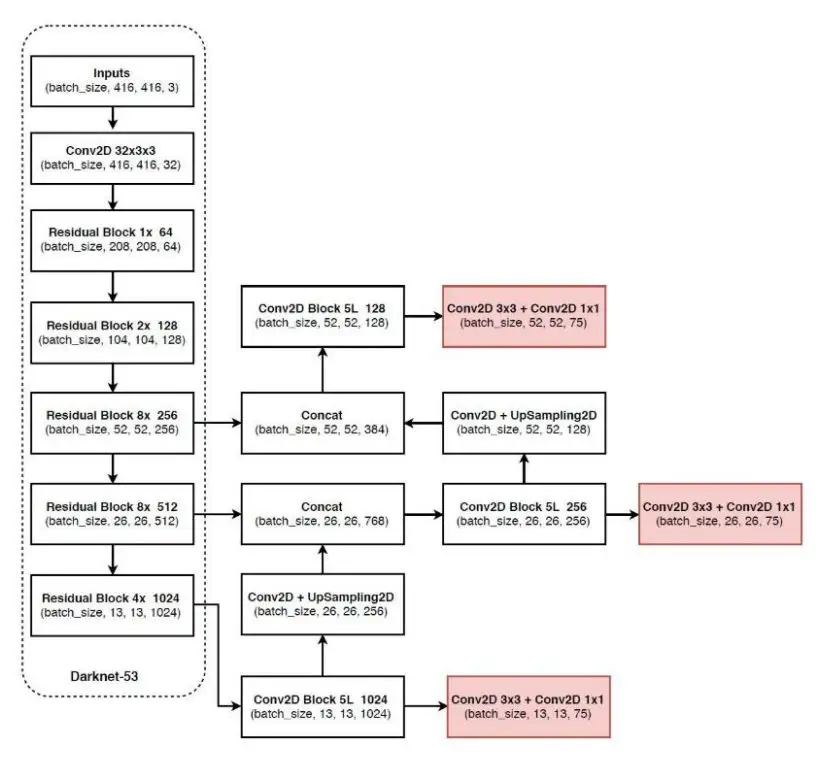
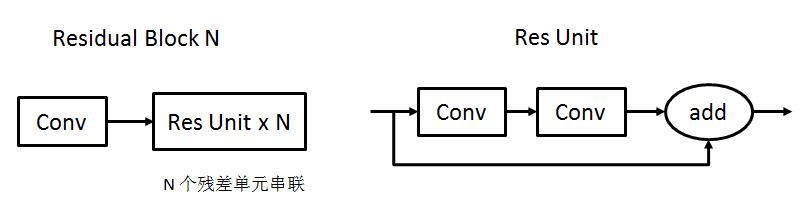
YOLOv3 的改进主要有
新的 Backbone(主干网络)Darknet-53
和 v2 的网络比有几处改变
1. 使用了残差网络,这样能使网络更深,达到了 53 层
2. 去掉了池化层,通过设置步长为 2 进行下采样,使输出的长宽变小
3. 上图中除了最终输出的 conv,其他 conv 后面都接 BN(Batch Normalization)和 LeakyReLU
4. 输出 3 个 feature map,比如 13 x 13、26 x 26、52 x 52,用以提高对不同大小物体的检测能力
Bounding Box 和多尺度预测
v2 的 anchor box 是通过 K-mean 寻找的
v3 则是设计好的,共 9 个 anchor box
(10x13),(16x30),(33x23),(30x61),(62x45),(59x119),(116x90),(156x198),(373x326)
每个 feature map 对应 3 个 anchor box
13 x 13:感受野最大,使用 (116x90),(156x198),(373x326),适合检测较大的对象
26 x 26:感受野中等,使用 (30x61),(62x45),(59x119),适合检测中等的对象
52 x 52:感受野较小,使用 (10x13),(16x30),(33x23),适合检测较小的对象
每个 grid 的输出维度是 255 = 3 x (4 + 1 + 80)
分别是 3 个 box,每个 box 有 4 个位置参数 x,y,w,h,一个置信度参数 p,以及 80 个分类的概率
(这里每个 box 都有自己的分类概率)
(80 个类别是 Coco 数据集,是对象检测、分割、关键点检测、字幕数据集,共 30 多万张图片)
对象分类 softmax 改成 logistic
为了执行多标签分类,比如一个玩具车,既可以标记为玩具,又可以标记为车
损失函数
对置信度损失、类别损失,改成使用二值交叉熵损失函数(Binary CrossEntroy)
训练
需要有不同大小物体的样本,由不同大小的 anchor box 检测
标记实际 box 与 anchor box 的偏移缩放作 Y
YOLOv4
2020 年 4 月发布的 https://arxiv.org/pdf/2004.10934v1.pdf
网络结构
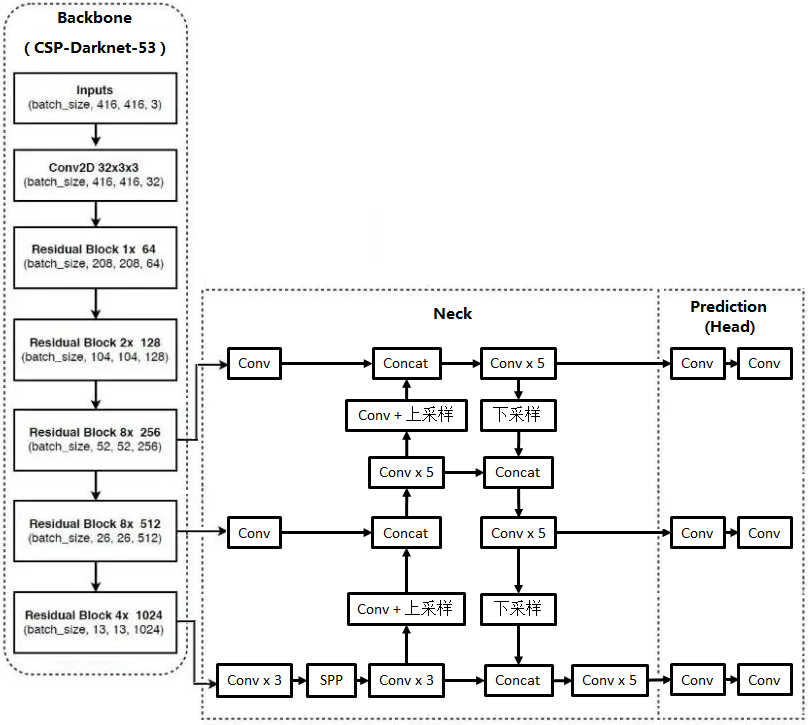
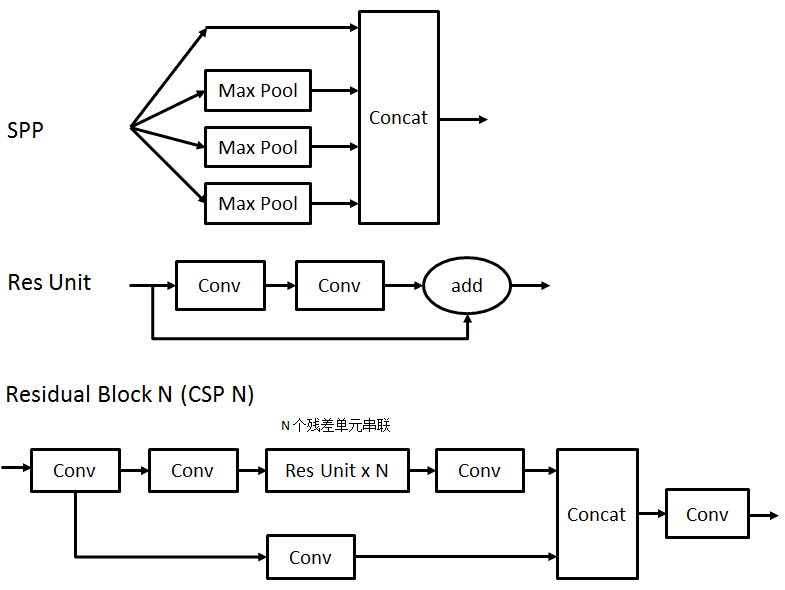
YOLOv4 主要是做优化,这里有两个概念
Bag of Freebies(免费包):
不需要增加模型复杂度和计算量的技巧,如增强样本,加 Dropout,改进损失函数
Bag of Specials(特价包):
增加少量模型复杂度或计算量的技巧,如增加感受野,新的网络模块,改进激活函数
优化 BackBone
主干(BackBone,用于提取特征)依然是 Darknet-53
设计新的残差块 CSP (Cross-Stage-Partial)
CSP 激活函数用 Mish
\(\small f(x) = x * tanh(ln(1 + e^{x}))\)
曲线类似 ReLU,但更光滑、非单调函数
使用 DropBlock
在 BackBone 和输出间加入 Neck 层,用于特征融合
SPP(Spatial Pyramid Pooling,空间金字塔池化):
输入经过 3 个不同大小、步长 1、padding 模式的池化层
比如 5x5,9x9,13x13,再加上原有的相当于 1x1 的输出,目的是获取不同大小的感受野
这样 4 个的输出大小还是一样,比如都是 13x13x512(取决于输入大小),再拼成 13x13x2048
PAN(Path Aggregation Network,路径聚合网络):
和 v3 差不多,就是聚合形成 3 个 feature map 输出
和 v3 的差别是,既用了上采样,又用了下采用
没有使用残差块
Conv 后面都用 BN(Batch Normalization)和激活函数 LeakyReLU
Prediction(Head)预测输出
和 v3 一样,在 3 个大小不同的 feature map 上,分别应用 3 组不同大小的 anchor box
每个 grid 的输出维度是 255 = 3 x (4 + 1 + 80)
分别是 3 个 box,每个 box 有 4 个位置参数 x,y,w,h,一个置信度参数 p,以及 80 个分类的概率
最后的 Conv 没有用 BN 和激活函数
数据增强
Mosaic
将多个张照片做裁剪,缩放,排布,最终拼接成一张图片
SAT(Self-Adversarial-Training,对抗训练)
对图片加噪音,使图片看起来没什么变化,但却能对系统产生干扰,来提高系统训练能力
调整光照
改变亮度,对比度,饱和度
调整图形
缩放,裁剪,翻转,旋转
遮挡图像
随机擦除
随机地将部分区域擦除
Cutout
擦除区域是个大小固定的正方体
Hide and Seek
将图片分成 S x S 个格子,随机擦除其中的若干个格子
Grid Mask
用 S x S 个小格子(不相连、间距固定、比图片小)遮挡图片

CutMix
融合多张图片(下图融合了一张猫的图片和一张狗的图片)

类标签平滑
one hot 不都是用 1,可以用 0.9,0.8 等
CmBN(Cross mini-Batch Normalization,跨微批归一化)
每个 mini-Batch 会做归一化,并且会考虑前面的 mini-Batch 的归一化结果
只针对同一个 batch 的多个 mini batch
原因是小批量的归一化效果不好,通过这种方式变相的对大批量做归一化
损失函数的改进
采用 CIoU-loss,其他部分不变,但把位置的损失改成
\(\large 1 - (IoU - \frac{d^{2}}{c^{2}} - \frac{v^{2}}{(1 - IoU) + v})\)
\(\large v = \frac{4}{\pi^{2}}(arctan(\frac{w}{h}) - arctan(\frac{w^{gt}}{h^{gt}}))^2\)
d 是预测框和真实框的中心点之间的距离
c 是预测框和真实框的最小包围框的对角线长度
目的是把重叠面积、中心点距离,长宽比都考虑进去
非极大抑制算法(NMS)的改进
原来判断重复的条件是
\(\large IoU > e\)
将其改成
\(\large IoU - \frac{d^{2}}{c^{2}} > e\)
d 是两个框的中心点之间的距离
c 是两个框的最小包围框的对角线长度
原因是,IoU 比较大,但是中心点相对也比较大,那有可能是两个物体
YOLOv5
2020 年 6 月由 Ultralytics 公司发布,可以在 iOS 下载例子应用
YOLOv5 做的改进
CSP
v4 的 CSP 只用于 Backbone
v5 设计两种 CSP 用于 Backbone 和 Neck
提供 depth_multiple 和 width_multiple 两个参数,用于灵活调整网络
Backbone
在 Backbone 最前面加入了 Focus 层
由 slice 块和 concat 块组成
如图相当于把 4 个相邻的元素,分别放到不同的 channel,再拼起来
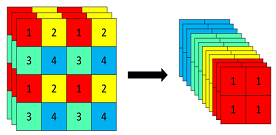
这样 channel 变多了,长宽变小了,相当于做了采用,但没有信息损失,这样能提升计算能力
concat 后面再加 CBL (Conv + Batch Normalization + LeakyReLU) 模块
Neck
改进 PAN
使用 CSP
SPP
v4 的 SPP 结构,是 3 个并行的池化层,分别是 5 x 5,9 x 9,13 x 13
v5 的 SPP 结构,将并行的池化层换成了串行的池化层,由 3 个 5 x 5 池化层串行组成
经过两个 5 x 5 串行的输出和 9 x 9 的输出是一样的
经过三个 5 x 5 串行的输出和 13 x 13 的输出是一样的
最后 3 个池化层输出连同 SPP 的输入数据,组成更大的输出,效果和 v4 一样
这样做的原因是效率更高
Prediction(Head)
结果和 v3,v4 相同
除了当前网格的一个 anchor box,还找两个相邻网格的 anchor box 来预测
Loss
位置损失函数用 GIoU-loss
支持自适应锚框
v3 和 v4 的 anchor box 都是训练前计算好的
v5 将这个功能集成到训练代码中,就是训练开始前,会根据数据,自动计算 anchor box
也可以使用已经计算好的 anchor box
自适应图片缩放
当输入图片大小和网络输入大小不同的时候,自动做缩放和填充短边,估计和 v3, v4 类似但做了优化
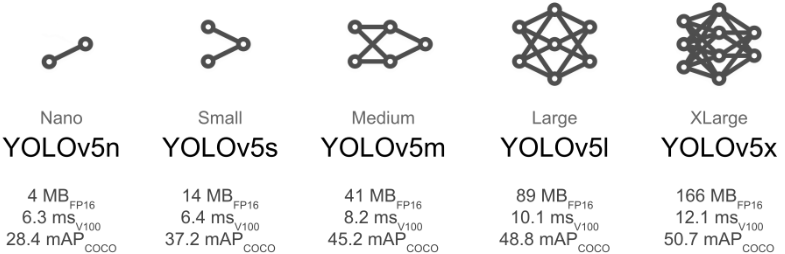
YOLOv5 有多个版本,较小的模型推理速度达到 10ms 以内,而模型尺寸只有十几 M,适合用于移动端等
较大的 YOLOv5 模型也和 YOLOv4 差不多,得有 200 多 M
YOLOv5 应用代码例子
https://github.com/ultralytics/yolov5
YOLOv5 是 Ultralytics 公司开发的
有多个版本
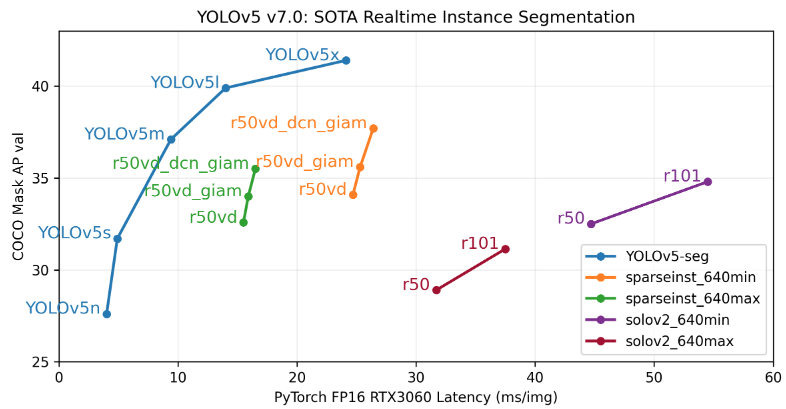
其中的 YOLOv5s 版本只有 14M 大小
Ultralytics 认为他们的模型是最快、最准、最容易训练、部署的,下面是官网原话
Our new YOLOv5 release v7.0 instance segmentation models are the fastest and most accurate in the world, beating all current SOTA benchmarks. We've made them super simple to train, validate and deploy.
很容易在 kaggle,AWS,GCP,Docker 等环境部署
https://www.kaggle.com/code/ultralytics/yolov5/notebook
https://github.com/ultralytics/yolov5/wiki/GCP-Quickstart
https://github.com/ultralytics/yolov5/wiki/AWS-Quickstart
https://hub.docker.com/r/ultralytics/yolov5
下载代码
git clone https://github.com/ultralytics/yolov5
安装
我用的 PyCharm
打开 PyCharm 的 Terminal 窗口,执行
pip3.7.exe install -i https://pypi.mirrors.ustc.edu.cn/simple/ -r requirements.txt
如果有安装不了的比如
opencv-python
psutil
可以在 PyCharm 外安装好
pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ opencv-contrib-python 或 opencv-python
pip install -i https://pypi.mirrors.ustc.edu.cn/simple/ psutil
然后把 cv2 和 psutil 两个目录拷过来,到项目的 venv\Lib\site-packages 下
每个包需要拷两个比如 psutil 和 psutil-5.9.4.dist-info
然后把 requirements.txt 里面的 opencv-python 和 psutil 注释掉,再 install
通过 torch.hub 使用(不需要 clone YOLOv5 代码)
参考 https://github.com/ultralytics/yolov5/issues/36
import torch
# 下载模型
# 实际上不需要本地有 YOLO 的代码
# torch 会自动下载模型,存到当前目录
# Downloading https://github.com/ultralytics/yolov5/releases/download/v7.0/yolov5s.pt to yolov5s.pt...
# 100%|██████████| 14.1M/14.1M [00:03<00:00, 4.42MB/s]
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
# 打印模型结构
print(model)
# 要识别的图片
# 如果网络不好,就改成指定本地的图片
img = 'https://ultralytics.com/images/zidane.jpg'
# 识别
results = model(img)
# 输出识别的结果
# image 1/1: 720x1280 2 persons, 2 ties
# Speed: 16.0ms pre-process, 260.0ms inference, 2.0ms NMS per image at shape (1, 3, 384, 640)
results.print()
# 输出具体信息
"""
[ xmin ymin xmax ymax confidence class name
0 743.290405 48.343658 1141.756592 720.000000 0.879861 0 person
1 441.989624 437.336731 496.585083 710.036194 0.675119 27 tie
2 123.051147 193.238098 714.690735 719.771301 0.666693 0 person
3 978.989807 313.579468 1025.302856 415.526184 0.261517 27 tie]
"""
print(results.pandas().xyxy)
# 打开识别后的图片
# 需要手动关掉图片才会执行下一步
results.show()
# Saved 1 image to runs\detect\exp
# 把识别后的图片保存下来
results.save()
程序运行成功后,到 runs\detect\exp 打开保存的图片

torch.hub.load 返回的 model,类型是 <class 'models.common.AutoShape'>
定义在 yolov5\models\common.py
继承的是 PyTorch 的 Module
import torch.nn as nn
class AutoShape(nn.Module):
AutoShape 定义了一些可以调整的参数
model.conf = 0.25 # NMS confidence threshold
iou = 0.45 # NMS IoU threshold
agnostic = False # NMS class-agnostic
multi_label = False # NMS multiple labels per box
classes = None # (optional list) filter by class, i.e. = [0, 15, 16] for COCO persons, cats and dogs
max_det = 1000 # maximum number of detections per image
amp = False # Automatic Mixed Precision (AMP) inference
而 results = model(img) 调用的应该是 AutoShape 的 forward 函数,从函数定义可以看到可用的参数
@smart_inference_mode()
def forward(self, ims, size=640, augment=False, profile=False):
# Inference from various sources. For size(height=640, width=1280), RGB images example inputs are:
# file: ims = 'data/images/zidane.jpg' # str or PosixPath
# URI: = 'https://ultralytics.com/images/zidane.jpg'
# OpenCV: = cv2.imread('image.jpg')[:,:,::-1] # HWC BGR to RGB x(640,1280,3)
# PIL: = Image.open('image.jpg') or ImageGrab.grab() # HWC x(640,1280,3)
# numpy: = np.zeros((640,1280,3)) # HWC
# torch: = torch.zeros(16,3,320,640) # BCHW (scaled to size=640, 0-1 values)
# multiple: = [Image.open('image1.jpg'), Image.open('image2.jpg'), ...] # list of images
可以设置模型要运行在哪个设备上
model.cpu() # CPU
model.cuda() # GPU
model.to(device) # i.e. device=torch.device(0)
改变输入的 channel(输入层的 weight 会被随机重置,可以重新训练)
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', channels=4)
改变输出总数(输出层的 weigh 会被随机重置,可以重新训练)
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', classes=10)
可以直接获取桌面
# Image
im = ImageGrab.grab() # take a screenshot
# Inference
results = model(im)
如果要自己重新训练模型
# 所有 weight 会被随机重置
model = torch.hub.load('ultralytics/yolov5', 'yolov5s', autoshape=False, pretrained=False)
如果要在代码里自己处理识别后的图片
results = model(im) # inference
results.ims # array of original images (as np array) passed to model for inference
results.render() # updates results.ims with boxes and labels
for im in results.ims:
buffered = BytesIO()
im_base64 = Image.fromarray(im)
im_base64.save(buffered, format="JPEG")
print(base64.b64encode(buffered.getvalue()).decode('utf-8')) # base64 encoded image with results
如果要导入 custom model
model = torch.hub.load('ultralytics/yolov5', 'custom', path='path/to/best.pt') # local model
model = torch.hub.load('path/to/yolov5', 'custom', path='path/to/best.pt', source='local') # local repo
更多内容参考官网
使用 YOLOv5 代码的 detect.py 脚本
cd yolov5
python detect.py --weights yolov5s.pt --source .\data\images\
# detect.py 会自动下载模型,到本地当前目录
# Downloading https://github.com/ultralytics/yolov5/releases/download/v6.2/yolov5s.pt to yolov5s.pt...
# 如果本地已经有这个文件了,那么可以直接指定本地文件,不需要下载
python detect.py --weights .\yolov5s.pt --source .\data\images\
# 本地目录 .\data\images\ 下的图片都会被识别
# 结果保存在 runs\detect\exp
--weights 和 --source 支持多种参数
Usage - sources:
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s_openvino_model # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
可以看到,模型文件除了支持 PyTorch,还支持 TensorFlow,支持 ONNX,等等
除了能处理文件夹下的所有图片,还能指定文件类型,也支持处理单个文件,支持处理视频,支持摄像头
使用 YOLOv5 代码的 train.py 脚本做训练
# --data 定义训练数据的 yaml 文件,包括到哪下载,下载到哪个目录,有哪些分类,等等
# --epochs 迭代次数
# --weights 存储权值的文件,指定为空代表全部权值都从随机数开始
# --cfg 定义模型的文件,如果有定义 --weights,就不需要定义 --cfg
# --batch-size 批大小
# --img 图片大小
python train.py --data coco.yaml --epochs 300 --weights '' --cfg yolov5n.yaml --batch-size 128 --img 640
yolov5s 64
yolov5m 40
yolov5l 24
yolov5x 16
下面是 train.py 开头的注释
Train a YOLOv5 model on a custom dataset.
Models and datasets download automatically from the latest YOLOv5 release.
Usage - Single-GPU training:
$ python train.py --data coco128.yaml --weights yolov5s.pt --img 640 # from pretrained (recommended)
$ python train.py --data coco128.yaml --weights '' --cfg yolov5s.yaml --img 640 # from scratch
Usage - Multi-GPU DDP training:
$ python -m torch.distributed.run --nproc_per_node 4 --master_port 1 train.py --data coco128.yaml \
--weights yolov5s.pt --img 640 --device 0,1,2,3
Models: https://github.com/ultralytics/yolov5/tree/master/models
Datasets: https://github.com/ultralytics/yolov5/tree/master/data
Tutorial: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
训练结果保存在 runs/train/exp
使用自己的数据训练
参考 https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
创建数据集
收集图片
创建 Label(官网推荐使用 Roboflow,或者其他软件如 LabelImg(不确定行不行))
组织文件目录,比如
parent
├── yolov5
└── datasets
└── coco128
└── images
└── train2017
└── labels
└── train2017
创建定义数据集的 yaml 文件,可以参考 yolov5\data\coco128.yaml
选择模型
根据需要选择 YOLOv5n,YOLOv5s,YOLOv5m,YOLOv5l,YOLOv5x 中的一个
训练
# coco128.yaml 换成自己创建的
# 可以使用 --cache ram 或 --cache disk 来提速
# 结果保存到 runs/train/exp
python train.py --img 640 --batch 16 --epochs 3 --data coco128.yaml --weights yolov5s.pt
可视化
使用 Comet,ClearML 等工具

 浙公网安备 33010602011771号
浙公网安备 33010602011771号