爬虫实例--爬取梨视频网站视频
import requests #调用requests模块 import re #调用re 正则表达式 from urllib.request import urlretrieve #调用下载模块 import os #调用系统模块 '''分析网页''' #获取页面源代码 html = requests.get(url) #获取视频ID google按F12 <a href="video_1637261" #拼接完整的URL地址 https://www.pearvideo.com/video_1637261(点击视频) #获取视频源的播放地址 src="https://video.pearvideo.com/mp4/adshort/20191229/cont-1637261-14747122_adpkg-ad_hd.mp4"() #下载视频 #解耦 def download_video(): '''下载梨视频''' #获取页面源代码 url = 'https://www.pearvideo.com/' html = requests.get(url).text #获取视频ID #正则表达式 #.*? 匹配所有 #<a href="video_1637303" class="vervideo-lilink actplay"> regex = r'<a href="(.*?)" class="vervideo-lilink actplay">' video_id = re.findall(regex,html) #print(video_id) #[] 列表 #拼接完整的url地址 video_url = [] starturl = 'https://www.pearvideo.com/' for vid in video_id: newurl = starturl + vid #https://www.pearvideo.com/video_1637261 video_url.append(newurl) #获取视频的播放地址 for playurl in video_url: #获取视频播放页面源代码 html = requests.get(playurl).text #正则表达式 regex = r'ldUrl="",srcUrl="(.*?)",vdoUrl=' play_rul = re.findall(regex,html) #print(play_rul[0]) #通过索引取列表里的元素 #正则表达式获取标题名称 #<h1 class="video-tt">网红乔丽娅发声:我主动退学非清退</h1> regex = r'<h1 class="video-tt">(.*?)</h1>' video_name = re.findall(regex,html) #print(video_name) 可以查看视频标题 print('正在下载:%s'%video_name[0]) #反馈下载进度 path = 'video' #目前没有video文件夹 #调用os系统模块帮助创建video文件夹 #如果video文件夹没有在当前目录下,就会自动创建video文件夹 if path not in os.listdir(): os.mkdir(path) #下载视频 #filepath = path + '/' + '%s.mp4'%video_name[0] 另一种下载方式 urlretrieve(play_rul[0],path+"/%s.mp4"%video_name[0]) download_video()
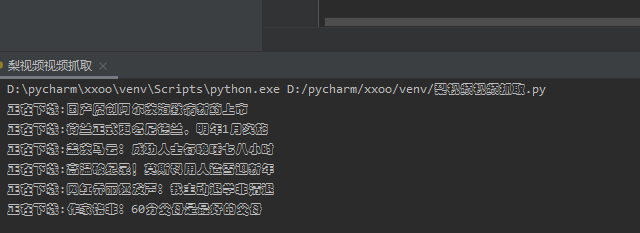
开始下载网站视频,明显下载速度变慢。
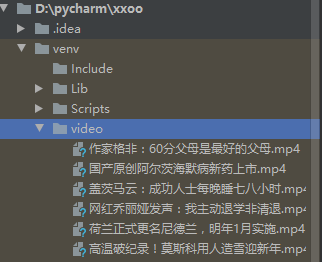
已下载到video文件里。
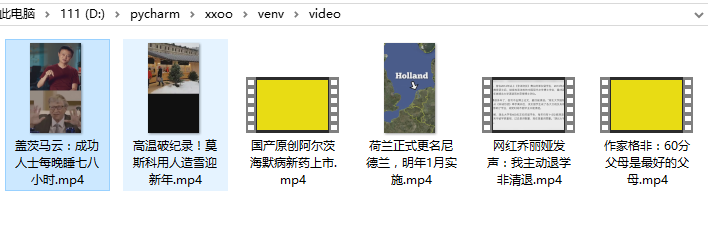
到本地目录查看视频。
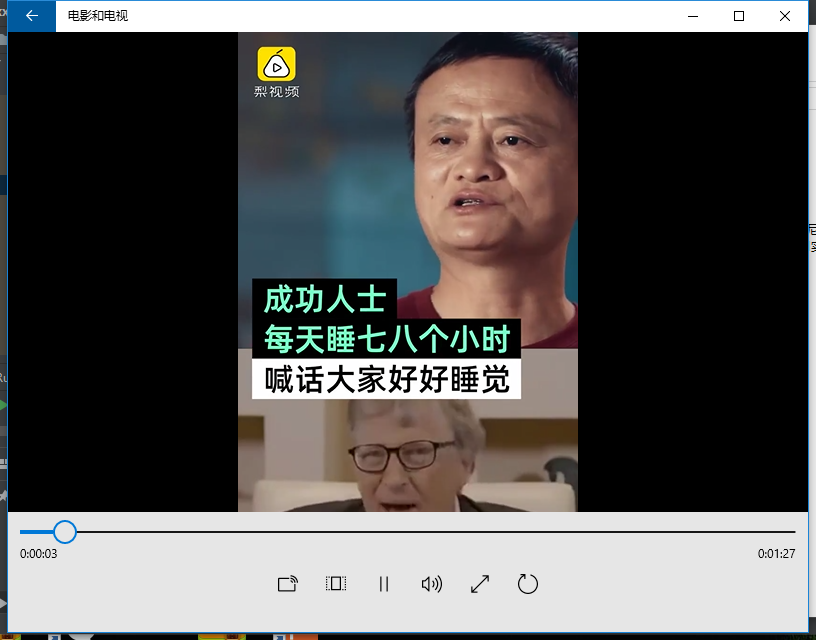
视频正常播放。
无反爬,大家可以去试试。代码是看视频一步一步做的有想看的给我留言哦,我会发给大家的。-
最后在心里默默地说了句:'hello,wolrd'...

 浙公网安备 33010602011771号
浙公网安备 33010602011771号