NumPy-快速处理数据--ndarray对象--多维数组的存取、结构体数组存取、内存对齐、Numpy内存结构
本文摘自《用Python做科学计算》,版权归原作者所有。
上一篇讲到:NumPy-快速处理数据--ndarray对象--数组的创建和存取
接下来接着介绍多维数组的存取、结构体数组存取、内存对齐、Numpy内存结构
一、多维数组的存取
多维数组的存取和一维数组类似,因为多维数组有多个轴,因此它的下标需要用多个值来表示,NumPy采用组元(tuple)作为数组的下标。如二维数组需要(x, y)的元组标记一个数组元素;三维数组需要(x, y, z)的元组标记一个元素。
如下图所示,a为一个6x6的二维数组,图中用颜色区分了各个下标以及其对应的选择区域。
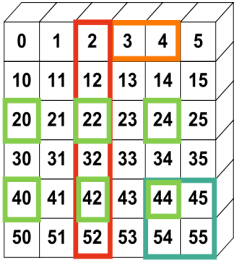
1 >>> a 2 array([[ 0, 1, 2, 3, 4, 5], 3 [10, 11, 12, 13, 14, 15], 4 [20, 21, 22, 23, 24, 25], 5 [30, 31, 32, 33, 34, 35], 6 [40, 41, 42, 43, 44, 45], 7 [50, 51, 52, 53, 54, 55]]) 8 >>> a[0, 3:5]#黄色部分 9 array([3, 4]) 10 >>> a[4:, 4:]#蓝色部分 11 array([[44, 45], 12 [54, 55]]) 13 >>> a[:, 2]#棕色部分 14 array([ 2, 12, 22, 32, 42, 52]) 15 >>> a[2::2, ::2]#青色部分 16 array([[20, 22, 24], 17 [40, 42, 44]])
如何创建这个6×6的二维数组?
数组a实际上是一个加法表,纵轴的值为0, 10, 20, 30, 40, 50;横轴的值为0, 1, 2, 3, 4, 5。纵轴的每个元素都和横轴的每个元素求和,就得到图中所示的数组a。你可以用下面的语句创建它:
1 np.arange(0, 60, 10).reshape(-1, 1) + np.arange(0, 6)
多维数组同样也可以使用整数序列和布尔数组进行存取。
1 >>> a[(0, 1, 2, 3, 4), (1, 2, 3, 4, 5)]#取出坐标为(0, 1), (1, 2), (2, 3), (3, 4), (4, 5)的元素 2 array([ 1, 12, 23, 34, 45]) 3 >>> a[3:, [0, 2, 5]]#取出第3, 4, 5行,第0, 2, 5列的元素 4 array([[30, 32, 35], 5 [40, 42, 45], 6 [50, 52, 55]]) 7 >>> mask = np.array([1, 0, 1, 0, 0, 1], dtype=np.bool)#先制造出一个布尔数组 8 >>> mask 9 array([ True, False, True, False, False, True], dtype=bool) 10 >>> a[mask, 2] #取出第二列下标为True的元素 11 array([ 2, 22, 52])
二、结构体数组
类似C语言中的结构体数组,在NumPy中也很容易对这种结构数组进行操作。只要NumPy中的结构定义和C语言中的定义相同,NumPy就可以很方便地读取C语言的结构数组的二进制数据,转换为NumPy的结构数组。
1 >>> personType = np.dtype({'names':['name', 'age', 'weight'],\ 2 'formats':['S32', 'i', 'f']})#创建personType数据类型 3 #字典有两个关键字:names,formats。每个关键字对应的值都是一个列表。 4 #names定义结构中的每个字段名,而formats则定义每个字段的类型: 5 # S32 : 32个字节的字符串类型 6 # i :32bit的整数类型,相当于np.int32 7 # f :32bit的单精度浮点数类型,相当于np.float32 8 >>> personType 9 dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')]) 10 #描述结构类型的方法: 一个包含多个组元的列表,其中形如 (字段名, 类型描述) 11 #的组元描述了结构中的每个字段。类型描述前面的 '|', '<' 等字符用来描述字段 12 #值的字节顺序: 13 # | :忽视字节顺序 14 # < : 低位字节在前 15 # > : 高位字节在前 16 >>> a = np.array([('zhang', 32, 75.5), ('wang', 24, 65.2)], dtype=personType ) 17 >>> a[0] #读取结构体数组的第0个结构元素 18 ('zhang', 32, 75.5) 19 >>> a[1] #读取结构体数组的第1个结构元素 20 ('wang', 24, 65.19999694824219) 21 >>> a[0].dtype 22 dtype([('name', 'S32'), ('age', '<i4'), ('weight', '<f4')]) 23 >>> c = a[1] #c和a[1]共享同一块内存 24 >>> c['name'] = 'li'#修改c的字段 25 >>> a[1]['name']#则a[1]相应的字段也被修改 26 'li' 27 >>> a[0]['name']#读取a[0]字段的name成员 28 'zhang' 29 >>> b = a[:]['age']#或者 a['age'] 30 >>> b 31 array([32, 24]) 32 >>> b[0] = 40 #通过b[0]修改a[0]['age'] 33 >>> a[0]['age'] 34 40 35 >>> a.tofile('d:\\test.bin') 36 #调用a.tostring或者a.tofile方法,可以直接输出数组a的二进制形式
利用下面的C语言程序可以将test.bin文件中的数据读取出来。
三、内存对齐
C语言的结构体为了内存寻址方便,会自动的添加一些填充用的字节,这叫做内存对齐。内存对齐与操作系统以及编译器有关。例如如果把下面的name[32]改为name[30]的话,由于内存对齐问题,在name和age中间会填补两个字节,最终的结构体大小不会改变。因此如果numpy中的所配置的内存大小不符合C语言的对齐规范的话,将会出现数据错位。为了解决这个问题,在创建dtype对象时,可以传递参数align=True,这样numpy的结构数组的内存对齐和C语言的结构体就一致了。
1 #include <stdio.h> 2 3 struct person 4 { 5 char name[32]; 6 int age; 7 float weight; 8 };//创建结构体数据类型 9 10 struct person p[2];//定义长度为2的一维结构体数组 11 12 int main (void) 13 { 14 FILE *fp; 15 int i; 16 fp=fopen("d:\\test.bin","rb");//以二进制只读方式打开文件 17 fread(p, sizeof(struct person), 2, fp);//读取的内容放在结构体数组p[2]中 18 fclose(fp); 19 for(i=0;i<2;i++) 20 printf("%s %d %f\n", p[i].name, p[i].age, p[i].weight); 21 getchar(); 22 return 0; 23 } 24 /* 25 在VC++6.0输出结果是: 26 ---------------------------- 27 zhang 40 75.500000 28 li 24 65.199997 29 30 Press any key to continue 31 ---------------------------- 32 */
结构类型中可以包括其它的结构类型,下面的语句创建一个有一个字段f1的结构,f1的值是另外一个结构,它有字段f2,其类型为16bit整数。
1 >>> np.dtype([('f1', [('f2', np.int16)])])#结构体套结构体 2 dtype([('f1', [('f2', '<i2')])]) 3 #用dtype([ ])来定义结构体,[('f2', np.int16)]是一个结构体 4 #('f1', [('f2', np.int16)])是一个元组 5 #最外层用dtype([ ])再定义一层结构体
当某个字段类型为数组时,用组元的第三个参数表示,下面描述的f1字段是一个shape为(2,3)的双精度浮点数组:
1 >>> np.dtype([('f0', 'i4'), ('f1', 'f8', (2, 3))]) 2 dtype([('f0', '<i4'), ('f1', '<f8', (2, 3))])
用下面的字典参数也可以定义结构类型,字典的关键字为结构中字段名,值为字段的类型描述,但是由于字典的关键字是没有顺序的,因此字段的顺序需要在类型描述中给出,类型描述是一个组元,它的第二个值给出字段的字节为单位的偏移量,例如age字段的偏移量为25个字节:
1 >>> np.dtype({'surname':('S25',0),'age':(np.uint8,25)}) 2 dtype([('surname', 'S25'), ('age', 'u1')])
四、Numpy内存结构
下面让我们来看看ndarray数组对象是如何在内存中储存的。
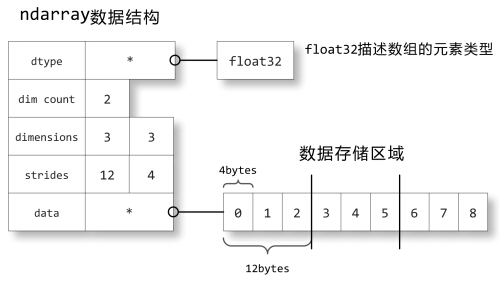
dtype对象则知道如何将元素的二进制数据转换为可用的值。如上图每32位表示一个有用数据
dim count表示数组维数,上图为2维数组
dimmension 3×3给出数组的shape
strides中保存的是当每个轴的下标增加1时,数据存储区中的指针所增加的字节数。例如图中的strides为12,4,即第0轴的下标增加1时,数据的地址增加12个字节:即a[1,0]的地址比a[0,0]的地址要高12个字节,正好是3个单精度浮点数的总字节数;第1轴下标增加1时,数据的地址增加4个字节,正好是单精度浮点数的字节数。
1 >>> a = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32) 2 >>> a 3 array([[ 0., 1., 2.], 4 [ 3., 4., 5.], 5 [ 6., 7., 8.]], dtype=float32)
如果strides中的数值正好和对应轴所占据的字节数相同的话,那么数据在内存中是连续存储的。然而数据并不一定都是连续储存的,前面介绍过通过下标范围得到新的数组是原始数组的视图,即它和原始视图共享数据存储区域:
1 >>> b = a[::2,::2] 2 >>> b 3 array([[ 0., 2.], 4 [ 6., 8.]], dtype=float32) 5 >>> b.strides 6 (24, 8)
由于数组b和数组a共享数据存储区,而b中的第0轴和第1轴都是数组a中隔一个元素取一个,因此数组b的strides变成了24,8,正好都是数组a的两倍。 对照前面的图很容易看出数据0和2的地址相差8个字节,而0和6的地址相差24个字节。
元素在数据存储区中的排列格式有两种:C语言格式和Fortan语言格式。在C语言中,多维数组的第0轴是最上位的,即第0轴的下标增加1时,元素的地址增加的字节数最多;而Fortan语言的多维数组的第0轴是最下位的,即第0轴的下标增加1时,地址只增加一个元素的字节数。在NumPy中,元素在内存中的排列缺省是以C语言格式存储的,如果你希望改为Fortan格式的话,只需要给数组传递order="F"参数:
1 >>> c = np.array([[0,1,2],[3,4,5],[6,7,8]], dtype=np.float32, order="F") 2 >>> c.strides 3 (4, 12)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号