经典网络结构(一)LeNet-5
一、 前言
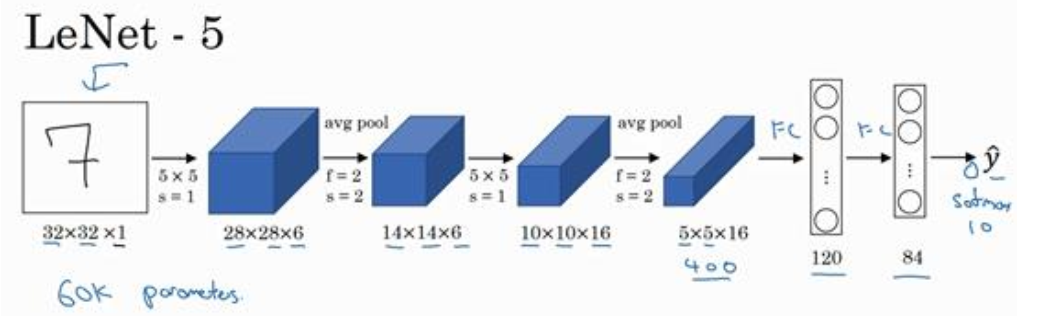
网络有5层(不考虑没有参数的层,所以是LeNet-5),包含3个卷积层,2个池化层,2个全连接层,No padding。
LeNet-5(Gradient-Based Learning Applied to Document Recognition)是1998年提出的专注于银行手写体识别的卷积神经网络。因此,输入是单通道的灰度图像, 图像分辨率不高。 当时人们不使用padding,共包含60k个params。
二、 LeNet-5网络的基本结构
LeNet-5网络规模不大,主要包含卷积层,池化层,全连接层,是深度学习模型的基础。
三、 网络结构详述:
1. Input层
输入的是灰度图像,输入图像的尺寸为32*32*1。
2. C1层 - 卷积层
- 输入尺寸: 32*32*1
- 卷积核大小: 5*5*1
- 卷积核个数:6
- 可训练参数: (5*5+1)*6 = 156
- 输出feature map大小: 28*28*6
3. S2层 - 池化层 用于降采样upsample
- 输入尺寸: 28*28*6;
- pool滤波器大小:2*2;
- 池化方式:4个输入相加,乘以一个可训练权重,再加上一个可训练偏执bias; ----带有参数的池化方式(与现在的池化方式有所不同,近期如果使用LeNet-5,均是使用现在的池化方式进行处理)
- 滤波器个数:6
- 可训练参数:(1+1)*6 = 12 --- 带参数的池化
- 输出feature map大小: 14*14*6
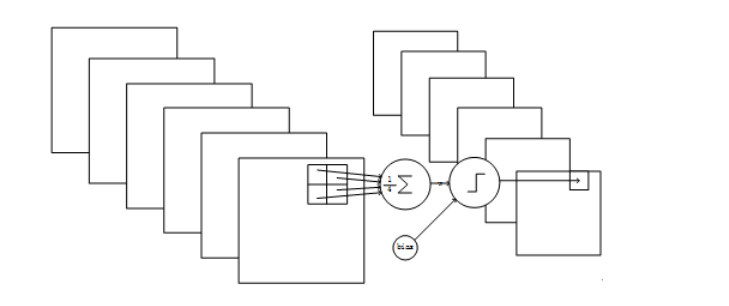
4. C3层 - 卷积层
- 输入尺寸: 14*14*6
- 卷积核大小: 5*5
- 卷积核个数:16
- 它是一种不对称的组合方式。即不是16个 5*5*6 的卷积核 --- 近期使用LeNet-5,此处使用5*5*6的卷积核16个。
-
- 有6个 5*5*3 的卷积核 生成6个feature_map -- 第一个红框
- 有6个 5*5*4 的卷积核 生成6个feature_map -- 第二个红框
- 有3个 5*5*4 的卷积核 生成3个feature_map -- 第三个红框
- 有1个 5*5*6 的卷积核 生成1个feature_map -- 第四个红框
每个卷积核均有一个bias,即有(5x5x3+1)x6 + (5x5x4 + 1) x 3 + (5x5x4 +1)x6 + (5x5x6+1)x1 =1516 个训练参数。 ----10*10*16
- 可训练参数:1516
- 输出feature map 大小:10*10*16

上图解析: 行号是输入feature map的6个通道,列号是输出feature map的16个通道。(也是每个卷积核作用的结果),X表示卷积核分别作用在输入feature map的指定通道上,可以看出,每一组卷积核均会将所有输入通道数量遍历一遍。
5. S4层 - 池化层
- 输入尺寸:10*10*16;
- pool滤波器大小:2*2; pool方式与S2相同
- 滤波器个数:16
- 可训练参数个数: (1+1)*16 = 32
- 输出feature map大小:5*5*16
6. C5层 - 卷积层
- 输入尺寸: 5*5*16
- 卷积核大小:5*5
- 卷积核个数:120
- 可训练参数个数: (5*5+1)*120 = 3120
- 输出尺寸大小: 1*1*120
7. F6层 - 全连接层
-
- 输入神经元个数: 120
- 输出神经元个数: 84
- 可训练参数:84*(120+1) = 10164


8. F7层 - 全连接层 output层
- 神经元个数: 10 (10个数字)
- 可训练参数个数:84*(10+1) = 924
- the output layer is composed of Euclidean Radial Basis Fuction units(RBF).
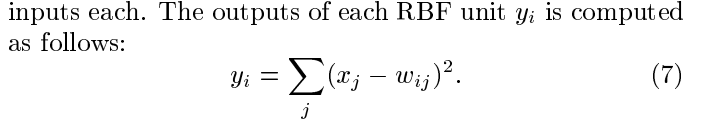
上式w_ij 的值由i的比特图编码确定,i从0到9,j取值从0到7*12-1。RBF输出的值越接近于0,则越接近于i,即越接近于i的ASCII编码图,表示当前网络输入的识别结果是字符i。

该论文原版中,池化后采用的是sigmoid激活函数。
四、 总结
LeNet-5是一种用于手写体识别的非常高效的卷积神经网络。其结构简单,参数量较少。
现在代码的实现与论文描述的不同之处体现为以下四点:
- 卷积方式: 不采用论文中描述的不对称卷积;
- 池化方式:采用无参的池化方式;
- 激活函数:池化后激活函数由sigmoid 变为ReLU
- 输出层会添加softmax激活函数
1 def model(self, is_trained=True): 2 with slim.arg_scope([slim.conv2d, slim.fully_connected], 3 weights_initializer=tf.truncated_normal_initializer(stddev=0.01), 4 weights_regularizer=slim.l2_regularizer(0.005), 5 biases_initializer=tf.constant_initializer(0)): 6 with slim.arg_scope([slim.conv2d], padding="valid"): 7 net = slim.conv2d(self.input_image, 6, kernel_size=[5, 5], stride=1, scope="conv_1") 8 net = slim.max_pool2d(net, [2, 2], 2, scope="pool_2") 9 net = slim.conv2d(net, 16, kernel_size=[5, 5], stride=1, scope="conv_3") 10 net = slim.max_pool2d(net, [2, 2], 2, scope="pool_4") 11 net = slim.conv2d(net, 120, kernel_size=[5, 5], stride=1, scope="conv_5") 12 net = slim.flatten(net, scope='flatten') 13 net = slim.fully_connected(net, 84, activation_fn=tf.nn.relu6, scope="fc_6") 14 net = slim.dropout(net, self.keep_prob, is_training=is_trained, scope='dropout') 15 digits = slim.fully_connected(net, 11, activation_fn=tf.nn.softmax, scope="fc_7") 16 return digits
作者:墨殇浅尘
-------------------------------------------
算法届的小学生,虔诚而不迷茫,做一个懂生活并有趣的人!
如果觉得这篇文章对你有小小的帮助的话,记得在右下角点个 [推荐] 噢! 欢迎共同交流机器学习,机器视觉,深度学习~
欢迎转载,转载请声明出处!
 浙公网安备 33010602011771号
浙公网安备 33010602011771号