竞赛学习活动 —— 文本匹配
文本匹配
重点内容
- 计算文本间的统计距离
- 训练词向量&无监督句子编码
- BERT模型搭建和训练
文本匹配应用场景
文本匹配是NLP中一个重要的基础问题,应用场景包括:
- 信息检索:根据query检索相似文本;
- 新闻推荐:相似新闻推荐;
- 智能客服:根据用户提出的问题检索相似的问题和答案。
数据集
LCQMC数据集侧重于意图匹配,比释义语料库更通用。LCQMC包含260068个带有人工标注的问题对。数据集划分如下:
- train_set: 238766
- dev_set: 8802
- test_set: 12500
评估方式
- Accuracy:\(acc = \frac{预测正确的样本数}{总样本数}\)
- 文本相似度与标签的皮尔逊系数(TODO)(皮尔逊系数是衡量两组数据相关性的工具,计算文本预测结果序列与文本标签序列的皮尔逊相关系数?)
学习打卡
环境依赖
导入依赖包
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
import jieba
数据集读取
# 加载数据集
def load_dataset():
"""
加载LCQMC文本匹配数据集
"""
train_set = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.train.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
valid_set = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.valid.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
test_set = pd.read_csv('https://mirror.coggle.club/dataset/LCQMC.test.data.zip',
sep='\t', names=['query1', 'query2', 'label'])
return train_set, valid_set, test_set
train_set, valid_set, test_set = load_dataset()
train_set.head()
| query1 | query2 | label | |
|---|---|---|---|
| 0 | 喜欢打篮球的男生喜欢什么样的女生 | 爱打篮球的男生喜欢什么样的女生 | 1 |
| 1 | 我手机丢了,我想换个手机 | 我想买个新手机,求推荐 | 1 |
| 2 | 大家觉得她好看吗 | 大家觉得跑男好看吗? | 0 |
| 3 | 求秋色之空漫画全集 | 求秋色之空全集漫画 | 1 |
| 4 | 晚上睡觉带着耳机听音乐有什么害处吗? | 孕妇可以戴耳机听音乐吗? | 0 |
print(f'train_size:{train_set.shape[0]}, valid_size:{valid_set.shape[0]}, test_size:{test_set.shape[0]}')
train_size:238766, valid_size:8802, test_size:12500
文本数据分析
- 比较相似文本对平均文本长度与不相似文本对的平均文本长度
- 统计所有文本中字符和单词(jieba分词)的个数
dataset = pd.concat([train_set, valid_set, test_set])
# 文本数据分析
def data_analysis(dataset):
"""
统计dataset中所有样本的字符和词,比较不同标签样本的平均文本长度
返回query1和query2分词后的列表,供后续环节使用
"""
word_vocab, char_vocab = set(), set()
len_pos, len_neg = [], []
query1_lst, query2_lst = [], []
for index, query1, query2, label in dataset.itertuples():
len_query = len(query1) + len(query2)
if label:
len_pos.append(len_query)
else:
len_neg.append(len_query)
char_vocab |= (set(query1 + query2))
words1 = jieba.lcut(query1, cut_all = False)
words2 = jieba.lcut(query2, cut_all = False)
word_vocab |= (set(words1) | set(words2))
query1_lst.append(words1)
query2_lst.append(words2)
print(f'相似文本对平均长度:{0.25 * sum(len_pos) / len(len_pos)}')
print(f'不相似文本对平均长度:{0.25 * sum(len_neg) / len(len_neg)}')
print(f'词数:{len(word_vocab)}字数:{len(char_vocab)}')
dataset['query1_seg'] = pd.Series(query1_lst)
dataset['query2_seg'] = pd.Series(query2_lst)
return
data_analysis(dataset)
Building prefix dict from the default dictionary ...
Loading model from cache /tmp/jieba.cache
Loading model cost 0.869 seconds.
Prefix dict has been built successfully.
相似文本对平均长度:5.108003967137094
不相似文本对平均长度:5.9488821926706485
词数:40441字数:5088
结果显示:相似文本对与不相似文本对的平均长度差别不大
文本相似度(统计特征)
对query1和query2计算以下统计特征,并计算与标签的相关度(皮尔逊相关系数):
- 文本长度:abs(len(query1) - len(query2))/(len(query1) + len(query2))
- 单词个数:abs(num(query1) - num(query2))/(num(query1) + num(query2))
- 单词差异:Jaccard距离
- LCS:len(LCS)/(len(query1) + len(query2))
- TFIDF编码相似度:余弦相似度
dataset.head()
| query1 | query2 | label | |
|---|---|---|---|
| 0 | 喜欢打篮球的男生喜欢什么样的女生 | 爱打篮球的男生喜欢什么样的女生 | 1 |
| 1 | 我手机丢了,我想换个手机 | 我想买个新手机,求推荐 | 1 |
| 2 | 大家觉得她好看吗 | 大家觉得跑男好看吗? | 0 |
| 3 | 求秋色之空漫画全集 | 求秋色之空全集漫画 | 1 |
| 4 | 晚上睡觉带着耳机听音乐有什么害处吗? | 孕妇可以戴耳机听音乐吗? | 0 |
# 获取tfidf权重
def get_tv(dataset):
"""
基于语料训练TfidfVectorizer
"""
seg1 = dataset.query1_seg.map(lambda x: ' '.join(x)).to_list()
seg2 = dataset.query2_seg.map(lambda x: ' '.join(x)).to_list()
corpus = seg1 + seg2
tv = TfidfVectorizer(use_idf=True, smooth_idf=True, norm=None)
tv_fit = tv.fit(corpus)
return tv_fit
tv_fit = get_tv(dataset)
# 统计特征分析
def get_cos_similarity(v1: list, v2: list):
num = float(np.dot(v1, v2)) # 向量点乘
denom = np.linalg.norm(v1) * np.linalg.norm(v2) # 求模长的乘积
return 0.5 + 0.5 * (num / denom) if denom != 0 else 0
def cal_LCS(s1, s2):
"""
计算字符串s1与s2的最长公共子序列的长度
"""
res = 0
l1, l2 = len(s1), len(s2)
dp = [[0 for _ in range(l2 + 1)] for _ in range(l1 + 1)]
for i in range(l1):
for j in range(l2):
if s1[i] == s2[j]:
dp[i + 1][j + 1] = dp[i][j] + 1
res += 1
else:
dp[i + 1][j + 1] = max(dp[i + 1][j], dp[i][j + 1])
res = res / (len(s1) + len(s2))
return res
def cal_statistic(dataset):
"""
计算各类统计特征
"""
res = []
for index, query1, query2, label, query1_seg, query2_seg in dataset.itertuples():
# 文本长度
length = abs(len(query1) - len(query2))/(len(query1) + len(query2))
# 单词个数
num = abs(len(query1_seg) - len(query2_seg)) / (len(query1_seg) + len(query2_seg))
# 单词差异:jaccard距离
jaccard = len(set(query1_seg) & set(query2_seg)) / len(set(query1_seg) | set(query2_seg))
# LCS
lcs = cal_LCS(query1, query2)
# tfidf_sim
query1_tfidf, query2_tfidf = tv_fit.transform([' '.join(query1_seg), ' '.join(query2_seg)]).toarray()
tfidf_sim = get_cos_similarity(query1_tfidf, query2_tfidf)
res.append([length, num, jaccard, lcs, tfidf_sim, label])
if index and not index % 50000:
print(f'{index} finished!')
print('all finished!')
stat_df = pd.DataFrame(np.array(res), columns=['文本长度', '单词个数', '单词差异(jaccard)', 'LCS', 'tfidf_sim', 'label'], dtype=float)
return stat_df
stat_df = cal_statistic(dataset)
stat_df.corr()
50000 finished!
100000 finished!
150000 finished!
200000 finished!
all finished!
| 文本长度 | 单词个数 | 单词差异(jaccard) | LCS | tfidf_sim | label | |
|---|---|---|---|---|---|---|
| 文本长度 | 1.000000 | 0.767464 | -0.343058 | -0.312184 | -0.247515 | -0.201464 |
| 单词个数 | 0.767464 | 1.000000 | -0.286983 | -0.198526 | -0.093974 | -0.078558 |
| 单词差异(jaccard) | -0.343058 | -0.286983 | 1.000000 | 0.712443 | 0.659670 | 0.534212 |
| LCS | -0.312184 | -0.198526 | 0.712443 | 1.000000 | 0.608842 | 0.492255 |
| tfidf_sim | -0.247515 | -0.093974 | 0.659670 | 0.608842 | 1.000000 | 0.533298 |
| label | -0.201464 | -0.078558 | 0.534212 | 0.492255 | 0.533298 | 1.000000 |
结果显示:以jaccard相似度衡量的单词差异与标签的相关性最高,即单词差异最具有区分性。
文本相似度(词向量与句子编码)
- 使用jieba分词,然后使用word2vec训练词向量
- 计算单词的TFIDF和BM25权重
- 尝试如下无监督句子编码过程
- Mean-Pooling:句子中所有词的embedding按列取平均
- Max-Pooling:句子中所有词的embedding按列取最大值(即取embedding每个维度的最大值)
- TFIDF-Pooling:句子中所有词的embedding按TFIDF加权平均,对Mean-Pooling的优化
- BM25-Pooling:对TFIDF-Pooling中的TF进行优化,主要是考虑到句子长度对TF的影响
- SIF-Pooling:保持加权平均的本质思想,加权平均后得到句子向量列表,对所有的句子向量求第一主成分,然后用原来的句子向量减去其第一主成分。
# 训练word2vec model
from gensim.models.word2vec import Word2Vec
import os
def get_word2vec_model(dataset):
path_model = "../resource/word2vec.model"
if os.path.exists(path_model):
model = Word2Vec.load(path_model)
else:
corpus = dataset.query1_seg.to_list() + dataset.query2_seg.to_list()
model = Word2Vec(sentences=corpus, vector_size=100, min_count=1)
model.save(path_model)
return model
w2v_model = get_word2vec_model(dataset)
# w2v embedding
corpus = dataset.query1_seg.to_list() + dataset.query2_seg.to_list()
w2v_embedding = list(map(lambda x: w2v_model.wv[x], corpus))
# 计算bm25和tfidf权重
from gensim.corpora import Dictionary
from gensim.models.bm25model import OkapiBM25Model, BM25ABC
import math
class BM25Model(BM25ABC):
def __init__(self, corpus=None, dictionary=None, k1=1.5, b=0.75, epsilon=0.25):
self.k1, self.b, self.epsilon = k1, b, epsilon
super().__init__(corpus, dictionary)
def precompute_idfs(self, dfs, num_docs):
idf_sum = 0
idfs = dict()
negative_idfs = []
for term_id, freq in dfs.items():
idf = math.log(num_docs - freq + 0.5) - math.log(freq + 0.5)
idfs[term_id] = idf
idf_sum += idf
if idf < 0:
negative_idfs.append(term_id)
average_idf = idf_sum / len(idfs)
eps = self.epsilon * average_idf
for term_id in negative_idfs:
idfs[term_id] = eps
return idfs
def get_term_weights(self, num_tokens, term_frequencies, idfs):
term_weights = idfs * (term_frequencies * (self.k1 + 1)
/ (term_frequencies + self.k1 * (1 - self.b + self.b
* num_tokens / self.avgdl)))
return term_weights
def __getitem__(self, bow):
num_tokens = sum(freq for term_id, freq in bow)
term_ids, term_frequencies, idfs = [], [], []
for term_id, term_frequency in bow:
term_ids.append(term_id)
term_frequencies.append(term_frequency)
idfs.append(self.idfs.get(term_id) or 0.0)
term_frequencies, idfs = np.array(term_frequencies), np.array(idfs)
bm25_weights = self.get_term_weights(num_tokens, term_frequencies, idfs)
tfidf_weights = term_frequencies * idfs
vector = [
(term_id, float(bm25_weight), float(tfidf_weight))
for term_id, bm25_weight, tfidf_weight
in zip(term_ids, bm25_weights, tfidf_weights)
]
return vector
def get_weight(corpus):
dictionary = Dictionary(corpus)
bm25_model = BM25Model(dictionary=dictionary)
idf_map = bm25_model.idfs
weight_corpus = list(map(lambda x: bm25_model[dictionary.doc2bow(x)], corpus))
bm25_weight, tfidf_weight = [], []
for weight, doc in zip(weight_corpus, corpus):
id_to_bm25, id_to_tfidf = {}, {}
for id, bm25, tfidf in weight:
id_to_bm25[id] = bm25
id_to_tfidf[id] = tfidf
bm25_vec = list(map(lambda x: id_to_bm25[dictionary.token2id[x]], doc))
tfidf_vec = list(map(lambda x: id_to_tfidf[dictionary.token2id[x]], doc))
bm25_weight.append(bm25_vec)
tfidf_weight.append(tfidf_vec)
return bm25_weight, tfidf_weight
bm25_weight, tfidf_weight = get_weight(corpus)
print(len(bm25_weight), len(tfidf_weight))
520136 520136
# pooling
from sklearn.decomposition import TruncatedSVD
def compute_pc(X,npc=1):
"""
Compute the principal components. DO NOT MAKE THE DATA ZERO MEAN!
:param X: X[i,:] is a data point
:param npc: number of principal components to remove
:return: component_[i,:] is the i-th pc
"""
svd = TruncatedSVD(n_components=npc, n_iter=7, random_state=0)
svd.fit(X)
return svd.components_
def remove_pc(X, npc=1):
"""
Remove the projection on the principal components
:param X: X[i,:] is a data point
:param npc: number of principal components to remove
:return: XX[i, :] is the data point after removing its projection
"""
pc = compute_pc(X, npc)
if npc==1:
XX = X - X.dot(pc.transpose()) * pc
else:
XX = X - X.dot(pc.transpose()).dot(pc)
return XX
mean_pooling = list(map(lambda x: np.array(x).mean(axis=0), w2v_embedding))
max_pooling = list(map(lambda x: np.array(x).max(axis=0), w2v_embedding))
bm25_pooling, tfidf_pooling = [], []
for w2v, bm25, tfidf in zip(w2v_embedding, bm25_weight, tfidf_weight):
bm25_pooling.append((np.array(bm25).reshape(-1,1) * w2v).mean(axis=0))
tfidf_pooling.append((np.array(tfidf).reshape(-1,1) * w2v).mean(axis=0))
sif_bm25_pooling = remove_pc(np.array(bm25_pooling))
sif_tfidf_pooling = remove_pc(np.array(tfidf_pooling))
sif_mean_pooling = remove_pc(np.array(mean_pooling))
# 相似度计算
def cal_similarity(pooling):
half_len = int(len(pooling) / 2)
res = list(map(lambda x: get_cos_similarity(x[0], x[1]), zip(pooling[:half_len], pooling[half_len:])))
return res
mean_sim = cal_similarity(mean_pooling)
max_sim = cal_similarity(max_pooling)
bm25_sim = cal_similarity(bm25_pooling)
tfidf_sim = cal_similarity(tfidf_pooling)
sif_bm25_sim = cal_similarity(sif_bm25_pooling)
sif_tfidf_sim = cal_similarity(sif_tfidf_pooling)
sif_mean_sim = cal_similarity(sif_mean_pooling)
sim_df = pd.DataFrame(np.array([mean_sim, max_sim, bm25_sim, tfidf_sim, sif_bm25_sim, sif_tfidf_sim, sif_mean_sim]).T, columns=['mean_sim', 'max_sim', 'bm25_sim', 'tfidf_sim', 'sif_bm25_sim', 'sif_tfidf_sim', 'sif_mean_sim'], dtype=float)
sim_df['label'] = pd.Series(dataset['label'].tolist())
sim_df.corr()
| mean_sim | max_sim | bm25_sim | tfidf_sim | sif_bm25_sim | sif_tfidf_sim | sif_mean_sim | label | |
|---|---|---|---|---|---|---|---|---|
| mean_sim | 1.000000 | 0.430473 | 0.820236 | 0.820078 | 0.817288 | 0.819759 | 0.975252 | 0.504288 |
| max_sim | 0.430473 | 1.000000 | 0.235300 | 0.233249 | 0.233063 | 0.232914 | 0.396588 | 0.153789 |
| bm25_sim | 0.820236 | 0.235300 | 1.000000 | 0.998204 | 0.999388 | 0.997849 | 0.823554 | 0.623700 |
| tfidf_sim | 0.820078 | 0.233249 | 0.998204 | 1.000000 | 0.997549 | 0.999593 | 0.823530 | 0.618218 |
| sif_bm25_sim | 0.817288 | 0.233063 | 0.999388 | 0.997549 | 1.000000 | 0.997193 | 0.820727 | 0.623515 |
| sif_tfidf_sim | 0.819759 | 0.232914 | 0.997849 | 0.999593 | 0.997193 | 1.000000 | 0.823204 | 0.618578 |
| sif_mean_sim | 0.975252 | 0.396588 | 0.823554 | 0.823530 | 0.820727 | 0.823204 | 1.000000 | 0.506946 |
| label | 0.504288 | 0.153789 | 0.623700 | 0.618218 | 0.623515 | 0.618578 | 0.506946 | 1.000000 |
结果显示:bm25加权平均的效果是最优的,在mean_pooling, bm25_pooling, tfidf_pooling的基础上做SIF的去除第一主成分的优化,效果不是很明显。
文本匹配模型(LSTM孪生网络)
- 定义孪生网络(嵌入层、LSTM层、全连接层)
- 使用文本匹配数据训练孪生网络
- 对测试数据进行预测
# 确定合适的seq_len
from matplotlib import pyplot as plt
from collections import Counter
seqs_len = list(sorted([len(x) for x in (dataset.query1_seg.to_list() + dataset.query2_seg.to_list())]))
len_counter = Counter(seqs_len)
plt.bar(len_counter.keys(), len_counter.values())
<BarContainer object of 33 artists>
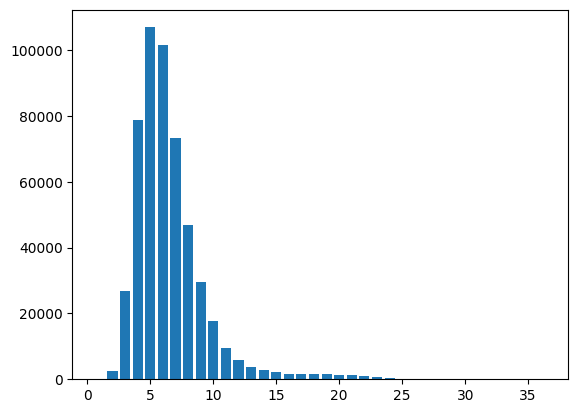
seq_len = 15
# 数据集预处理
def load_pretrained_embedding_matrix(w2v_model):
'''
返回:
1. 加入OOV vector和PAD vector的预训练的embedding矩阵
2. 字典,word2index,用于处理分词后的文本序列
3. padding_idx,PAD vector在embedding矩阵中的index
4. embedding_dim词嵌入维度
'''
embedding_dim = w2v_model.wv.vectors.shape[1]
vec_oov = np.random.rand(embedding_dim)
vec_pad = np.zeros(embedding_dim)
embedding_matrix = np.vstack((w2v_model.wv.vectors, vec_oov, vec_pad))
vocab = w2v_model.wv.key_to_index
oov_idx = len(vocab)
padding_idx = oov_idx + 1
return embedding_matrix, vocab, oov_idx, padding_idx, embedding_dim
def DataProcess(sent):
if len(sent) <= seq_len:
sent = list(map(lambda x: vocab.get(x, oov_idx), sent)) + [padding_idx] * (seq_len - len(sent))
else:
sent = list(map(lambda x: vocab.get(x, oov_idx), sent[:seq_len]))
return np.array(sent)
embedding_matrix, vocab, oov_idx, padding_idx, embedding_dim = load_pretrained_embedding_matrix(w2v_model)
q1 = dataset.query1_seg.map(DataProcess)
q2 = dataset.query2_seg.map(DataProcess)
label = dataset.label
data = pd.concat(([q1, q2, label]), axis=1)
data = data.sample(frac=1, ignore_index=True)
data.head()
| query1_seg | query2_seg | label | |
|---|---|---|---|
| 0 | [22, 1634, 72, 0, 10067, 39658, 39658, 39658, ... | [20, 1634, 10067, 2, 39658, 39658, 39658, 3965... | 1 |
| 1 | [19, 201, 63, 1, 32, 0, 8, 39658, 39658, 39658... | [1, 32, 0, 19, 21352, 7614, 39658, 39658, 3965... | 0 |
| 2 | [44, 6741, 9219, 7, 39658, 39658, 39658, 39658... | [44, 6741, 9219, 103, 39658, 39658, 39658, 396... | 1 |
| 3 | [1175, 35, 4455, 20288, 15181, 54, 39658, 3965... | [35, 5106, 54, 3332, 39658, 39658, 39658, 3965... | 0 |
| 4 | [764, 1139, 3634, 243, 6749, 0, 253, 54, 39658... | [16, 3634, 2368, 54, 4462, 2341, 0, 13, 184, 1... | 0 |
from torch.utils.data import Dataset, DataLoader
import torch
class MyDataset(Dataset):
def __init__(self, data, mode):
if mode == 'train':
self.data = data.iloc[:238766,:].values
if mode == 'valid':
self.data = data.iloc[238766:238766+8802,:].values
if mode == 'test':
self.data = data.iloc[238766+8802:,:].values
def __len__(self):
return self.data.shape[0]
def getdata(self, index):
q1, q2, label = self.data[index]
return torch.tensor(q1), torch.tensor(q2), torch.tensor(label)
def __getitem__(self, index):
if isinstance(index, slice):
start, end, stride = index.indices(len(self))
q1s, q2s, labels = [], [], []
for i in range(start, end):
q1, q2, label = self.getdata(i)
q1s.append(q1)
q2s.append(q2)
labels.append(label)
return q1s, q2s, labels
else:
return self.getdata(index)
train_dataset = MyDataset(data, mode = 'train')
valid_dataset = MyDataset(data, mode = 'valid')
test_dataset = MyDataset(data, mode = 'test')
BATCH_SIZE = 16
train_data_loader = DataLoader(train_dataset, batch_size=4*BATCH_SIZE, shuffle=True, drop_last=True)
valid_data_loader = DataLoader(valid_dataset, batch_size=4*BATCH_SIZE, shuffle=True, drop_last=True)
test_data_loader = DataLoader(test_dataset, batch_size=4*BATCH_SIZE, shuffle=True, drop_last=True)
train_sample = tuple(next(iter(train_data_loader)))
valid_sample = tuple(next(iter(valid_data_loader)))
test_sample = tuple(next(iter(test_data_loader)))
# print(train_sample, valid_sample, test_sample)
# 定义模型
import torch
import torch.nn as nn
class SiameseLSTM(nn.Module):
def __init__(self, pretrained_weight, embedding_dim, hidden_dim, out_dim, padding_idx, batch_size):
super(SiameseLSTM, self).__init__()
self.embedding_dim = embedding_dim
self.hidden_dim = hidden_dim
self.batch_size = batch_size
self.out_dim = out_dim
# self.h0 = torch.randn(1, self.batch_size, self.hidden_dim).cuda()
# self.c0 = torch.randn(1, self.batch_size, self.hidden_dim).cuda()
self.embed = nn.Embedding.from_pretrained(pretrained_weight, padding_idx=padding_idx, freeze=False)
self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_dim, batch_first=True)
self.hidden2tag = nn.Linear(4 * self.hidden_dim, self.out_dim)
def forward(self, q1, q2):
"""
Input:
q1: [batch_size, seq_len]
q2: [batch_size, seq_len]
"""
# [batch_size, seq_len, embedding_dim]
embed1, embed2 = self.embed(q1), self.embed(q2)
# [batch_size, seq_len, hidden_dim]
# output1, (h1, c1) = self.lstm(embed1, (self.h0, self.c0))
# output2, (h2, c2) = self.lstm(embed2, (self.h0, self.c0))
output1, (h1, c1) = self.lstm(embed1)
output2, (h2, c2) = self.lstm(embed2)
# [batch_size, hidden_dim] 沿seq_len方向做max_pooling
output1 = output1.permute(1, 0, 2)[-1]
output2 = output2.permute(1, 0, 2)[-1]
# [batch_size, 4*hidden_dim]
sim = torch.cat([output1, output1 * output2, torch.abs(output1 - output2), output2], dim=-1)
# [batch_size, 2]
output = self.hidden2tag(sim)
return output
torch.cuda.is_available()
True
torch.cuda.device_count()
4
!nvidia-smi
Tue Jan 24 11:01:36 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 470.161.03 Driver Version: 470.161.03 CUDA Version: 11.4 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=++==============|
| 0 Tesla P40 Off | 00000000:03:00.0 Off | 0 |
| N/A 34C P0 51W / 250W | 865MiB / 22919MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 Tesla P40 Off | 00000000:04:00.0 Off | 0 |
| N/A 35C P0 51W / 250W | 611MiB / 22919MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 2 Tesla P40 Off | 00000000:84:00.0 Off | 0 |
| N/A 33C P0 50W / 250W | 611MiB / 22919MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 3 Tesla P40 Off | 00000000:85:00.0 Off | 0 |
| N/A 33C P0 50W / 250W | 611MiB / 22919MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 10876 C ...3/envs/jupyter/bin/python 863MiB |
| 1 N/A N/A 10876 C ...3/envs/jupyter/bin/python 609MiB |
| 2 N/A N/A 10876 C ...3/envs/jupyter/bin/python 609MiB |
| 3 N/A N/A 10876 C ...3/envs/jupyter/bin/python 609MiB |
+-----------------------------------------------------------------------------+
model = SiameseLSTM(
pretrained_weight = torch.FloatTensor(embedding_matrix),
embedding_dim = embedding_dim,
hidden_dim = 16,
out_dim = 2,
padding_idx=padding_idx,
batch_size = BATCH_SIZE
)
model = nn.DataParallel(model).cuda()
print(model)
DataParallel(
(module): SiameseLSTM(
(embed): Embedding(39659, 100, padding_idx=39658)
(lstm): LSTM(100, 16, batch_first=True)
(hidden2tag): Linear(in_features=64, out_features=2, bias=True)
)
)
# 准确率计算
def accuracy(pred, label):
return (pred.argmax(dim=1) == label).float().mean().item()
# 训练模型
import torch.optim as optim
EPOCH = 10
LEARNING_RATE = 0.001
def process(data_loader, mode, optimizer=None):
step, total_loss, total_acc = 0, 0, 0
for q1, q2, tags in data_loader:
pred = model(q1.cuda(), q2.cuda())
loss = nn.CrossEntropyLoss()(pred, tags.cuda())
total_loss += loss.item()
total_acc += accuracy(pred, tags.cuda())
if mode == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
step += 1
print(f'{mode}_loss:{total_loss / step}, {mode}_acc:{total_acc / step}')
seed = 1
torch.manual_seed(seed)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
for i in range(EPOCH):
print(f'-------------------------第{i+1}轮训练开始---------------------')
# 训练
process(train_data_loader, mode='train', optimizer=optimizer)
# 计算验证集损失
with torch.no_grad():
process(valid_data_loader, mode='valid')
-------------------------第1轮训练开始---------------------
train_loss:0.535547758698783, train_acc:0.7363815348525469
valid_loss:0.4924165106167758, valid_acc:0.7692746350364964
-------------------------第2轮训练开始---------------------
train_loss:0.41942384708423075, train_acc:0.8191353887399464
valid_loss:0.4552816731216264, valid_acc:0.7974452554744526
-------------------------第3轮训练开始---------------------
train_loss:0.36078374552023634, train_acc:0.8509509048257373
valid_loss:0.4463498212777785, valid_acc:0.8078239051094891
-------------------------第4轮训练开始---------------------
train_loss:0.3236872991791679, train_acc:0.8693951072386059
valid_loss:0.45117809269985143, valid_acc:0.8153512773722628
-------------------------第5轮训练开始---------------------
train_loss:0.29681315174171496, train_acc:0.8821003686327078
valid_loss:0.4543193623314809, valid_acc:0.8125
-------------------------第6轮训练开始---------------------
train_loss:0.27694827924425097, train_acc:0.8920911528150134
valid_loss:0.4587254343676741, valid_acc:0.8171760948905109
-------------------------第7轮训练开始---------------------
train_loss:0.26128301543580623, train_acc:0.8985673592493297
valid_loss:0.46427330396471234, valid_acc:0.8163777372262774
-------------------------第8轮训练开始---------------------
train_loss:0.24749427433387844, train_acc:0.9042937332439678
valid_loss:0.47178024216725006, valid_acc:0.8185447080291971
-------------------------第9轮训练开始---------------------
train_loss:0.2365480364946993, train_acc:0.9088011058981234
valid_loss:0.48314058378230046, valid_acc:0.8126140510948905
-------------------------第10轮训练开始---------------------
train_loss:0.22686020918689848, train_acc:0.9128141756032172
valid_loss:0.5018375272298381, valid_acc:0.8170620437956204
# 模型测试
process(test_data_loader, mode='test')
test_loss:0.4900959795866257, test_acc:0.8205929487179487
PATH = 'LSTM_model.pt'
torch.save(model.state_dict(), PATH)
选用的模型很简单,第四个epoch基本拟合完毕,测试集准确率0.82
优化方向:提升模型复杂度(BiLSTM),学习率衰减,dropout,梯度剪裁
文本匹配模型(BERT模型)
- 使用BERT对文本进行编码,计算句子对相似度
- 定义BERT网络,使用数据完成BERT-NSP训练,对测试数据进行预测
- 使用BERT模型完成Sentence-BERT,训练并进行预测。
# 使用BERT编码句子
from transformers import BertConfig, BertModel, BertTokenizer
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Load model from HuggingFace Hub
tokenizer = BertTokenizer.from_pretrained("bert-base-chinese")
model = BertModel.from_pretrained("bert-base-chinese")
Some weights of the model checkpoint at bert-base-chinese were not used when initializing BertModel: ['cls.predictions.decoder.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.dense.weight', 'cls.predictions.bias', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias', 'cls.predictions.transform.dense.bias']
- This IS expected if you are initializing BertModel from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertModel from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
dataset.head()
| query1 | query2 | label | |
|---|---|---|---|
| 0 | 喜欢打篮球的男生喜欢什么样的女生 | 爱打篮球的男生喜欢什么样的女生 | 1 |
| 1 | 我手机丢了,我想换个手机 | 我想买个新手机,求推荐 | 1 |
| 2 | 大家觉得她好看吗 | 大家觉得跑男好看吗? | 0 |
| 3 | 求秋色之空漫画全集 | 求秋色之空全集漫画 | 1 |
| 4 | 晚上睡觉带着耳机听音乐有什么害处吗? | 孕妇可以戴耳机听音乐吗? | 0 |
# Tokenize sentences
def bert_encode(sentences):
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt', max_length=32)
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling
embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
# print(f'embedding:{pair_embeddings}')
# Normalize embeddings
encode = F.normalize(embeddings, p=2, dim=1)
return encode
query1 = dataset.query1.to_list()
query2 = dataset.query2.to_list()
num_query = len(query1)
index, batch_size = 0, 128
sim_bert = []
while index + batch_size < num_query:
encode1 = bert_encode(query1[index:index + batch_size])
encode2 = bert_encode(query2[index:index + batch_size])
sim_bert += list(map(lambda x: torch.dot(x[0], x[1]), zip(encode1, encode2)))
index += batch_size
encode1 = bert_encode(query1[index:])
encode2 = bert_encode(query2[index:])
sim_bert += list(map(lambda x: torch.dot(x[0], x[1]), zip(encode1, encode2)))
print(len(sim_bert))
260068
df = pd.DataFrame(np.array([sim_bert, dataset.label.values]).T, columns=['bert_sims', 'label'])
df.corr()
| bert_sims | label | |
|---|---|---|
| bert_sims | 1.000000 | 0.557954 |
| label | 0.557954 | 1.000000 |
# bert-nsp 训练
import transformers
import torch
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader, TensorDataset
transformers.logging.set_verbosity_error()
# 划分为训练集和验证集
# stratify 按照标签进行采样,训练集和验证部分同分布
q1_train, q1_val, q2_train, q2_val, train_label, test_label = train_test_split(
dataset['query1'],
dataset['query2'],
dataset['label'],
test_size=0.2,
stratify=dataset['label'])
from transformers import BertTokenizer
# 分词器,词典
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
train_encoding = tokenizer(list(q1_train), list(q2_train),
truncation=True, padding=True, max_length=32)
test_encoding = tokenizer(list(q1_val), list(q2_val),
truncation=True, padding=True, max_length=32)
# 数据集读取
class MyDataset(Dataset):
def __init__(self, encodings, labels):
self.encodings = encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item = {key: torch.tensor(val[idx]) for key, val in self.encodings.items()}
item['labels'] = torch.tensor(int(self.labels[idx]))
return item
def __len__(self):
return len(self.labels)
train_dataset = MyDataset(train_encoding, list(train_label))
test_dataset = MyDataset(test_encoding, list(test_label))
for k, v in train_encoding.items():
for ids in v:
print(tokenizer.decode(ids))
break
break
[CLS] 辽 宁 卫 生 职 业 技 术 学 院 的 住 宿 条 件 [SEP] 辽 宁 卫 生 职 业 技 术 学 院 医 疗 美 容 [SEP]
from transformers import BertForNextSentencePrediction, get_linear_schedule_with_warmup
import torch
model = BertForNextSentencePrediction.from_pretrained('bert-base-chinese')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 单个读取到批量读取
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=True)
# 优化方法
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
total_steps = len(train_loader) * 1
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0, # Default value in run_glue.py
num_training_steps = total_steps)
# 模型训练
def process(data_loader, mode, optimizer=None, scheduler=None):
step, total_loss, total_acc = 0, 0, 0
for batch in train_loader:
# 正向传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
total_loss += loss.item()
pred = logits.detach().cpu()
label_ids = labels.to('cpu')
total_acc += accuracy(pred, label_ids)
if mode == 'train':
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
step += 1
if mode == 'train' and step % 2000 == 0:
print(f'iter_num: {step}, {mode}_loss: {total_loss / step}, progress:{step/total_steps*100}%')
print(f'{mode}_total_loss:{total_loss / step}, {mode}_acc:{total_acc / step}')
for i in range(5):
print(f'-------------------------第{i+1}轮训练开始---------------------')
# 训练
model.train()
process(train_loader, mode='train', optimizer=optimizer, scheduler=scheduler)
# 计算验证集损失
model.eval()
with torch.no_grad():
process(test_loader, mode='valid')
-------------------------第1轮训练开始---------------------
iter_num: 2000, train_loss: 0.2818656249437481, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.25996779286302624, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.246443612488918, progress:92.27929867733006%
train_total_loss:0.24448637775899182, train_acc:0.8984403400394008
valid_total_loss:0.17493474610913023, valid_acc:0.9312881875481835
-------------------------第2轮训练开始---------------------
iter_num: 2000, train_loss: 0.18335341547057032, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.1840216007931158, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.18221153588220476, progress:92.27929867733006%
train_total_loss:0.18244350250490682, train_acc:0.9271094034045192
valid_total_loss:0.17494391908760862, valid_acc:0.9312838182673752
-------------------------第3轮训练开始---------------------
iter_num: 2000, train_loss: 0.18436180991400034, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.1840214733267203, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.18291711654793472, progress:92.27929867733006%
train_total_loss:0.18276111815716028, train_acc:0.9271478531123014
valid_total_loss:0.1749338287400653, valid_acc:0.9312903721931713
-------------------------第4轮训练开始---------------------
iter_num: 2000, train_loss: 0.18274084678804503, progress:30.759766225776687%
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[9], line 46
44 # 训练
45 model.train()
---> 46 process(train_loader, mode='train', optimizer=optimizer, scheduler=scheduler)
48 # 计算验证集损失
49 model.eval()
Cell In[9], line 12, in process(data_loader, mode, optimizer, scheduler)
10 attention_mask = batch['attention_mask'].to(device)
11 labels = batch['labels'].to(device)
---> 12 outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
14 loss = outputs[0]
15 logits = outputs[1]
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:1480, in BertForNextSentencePrediction.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, labels, output_attentions, output_hidden_states, return_dict, **kwargs)
1476 labels = kwargs.pop("next_sentence_label")
1478 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
-> 1480 outputs = self.bert(
1481 input_ids,
1482 attention_mask=attention_mask,
1483 token_type_ids=token_type_ids,
1484 position_ids=position_ids,
1485 head_mask=head_mask,
1486 inputs_embeds=inputs_embeds,
1487 output_attentions=output_attentions,
1488 output_hidden_states=output_hidden_states,
1489 return_dict=return_dict,
1490 )
1492 pooled_output = outputs[1]
1494 seq_relationship_scores = self.cls(pooled_output)
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:1021, in BertModel.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
1012 head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
1014 embedding_output = self.embeddings(
1015 input_ids=input_ids,
1016 position_ids=position_ids,
(...)
1019 past_key_values_length=past_key_values_length,
1020 )
-> 1021 encoder_outputs = self.encoder(
1022 embedding_output,
1023 attention_mask=extended_attention_mask,
1024 head_mask=head_mask,
1025 encoder_hidden_states=encoder_hidden_states,
1026 encoder_attention_mask=encoder_extended_attention_mask,
1027 past_key_values=past_key_values,
1028 use_cache=use_cache,
1029 output_attentions=output_attentions,
1030 output_hidden_states=output_hidden_states,
1031 return_dict=return_dict,
1032 )
1033 sequence_output = encoder_outputs[0]
1034 pooled_output = self.pooler(sequence_output) if self.pooler is not None else None
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:610, in BertEncoder.forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
601 layer_outputs = torch.utils.checkpoint.checkpoint(
602 create_custom_forward(layer_module),
603 hidden_states,
(...)
607 encoder_attention_mask,
608 )
609 else:
--> 610 layer_outputs = layer_module(
611 hidden_states,
612 attention_mask,
613 layer_head_mask,
614 encoder_hidden_states,
615 encoder_attention_mask,
616 past_key_value,
617 output_attentions,
618 )
620 hidden_states = layer_outputs[0]
621 if use_cache:
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:496, in BertLayer.forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
484 def forward(
485 self,
486 hidden_states: torch.Tensor,
(...)
493 ) -> Tuple[torch.Tensor]:
494 # decoder uni-directional self-attention cached key/values tuple is at positions 1,2
495 self_attn_past_key_value = past_key_value[:2] if past_key_value is not None else None
--> 496 self_attention_outputs = self.attention(
497 hidden_states,
498 attention_mask,
499 head_mask,
500 output_attentions=output_attentions,
501 past_key_value=self_attn_past_key_value,
502 )
503 attention_output = self_attention_outputs[0]
505 # if decoder, the last output is tuple of self-attn cache
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:435, in BertAttention.forward(self, hidden_states, attention_mask, head_mask, encoder_hidden_states, encoder_attention_mask, past_key_value, output_attentions)
416 def forward(
417 self,
418 hidden_states: torch.Tensor,
(...)
424 output_attentions: Optional[bool] = False,
425 ) -> Tuple[torch.Tensor]:
426 self_outputs = self.self(
427 hidden_states,
428 attention_mask,
(...)
433 output_attentions,
434 )
--> 435 attention_output = self.output(self_outputs[0], hidden_states)
436 outputs = (attention_output,) + self_outputs[1:] # add attentions if we output them
437 return outputs
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/transformers/models/bert/modeling_bert.py:386, in BertSelfOutput.forward(self, hidden_states, input_tensor)
384 def forward(self, hidden_states: torch.Tensor, input_tensor: torch.Tensor) -> torch.Tensor:
385 hidden_states = self.dense(hidden_states)
--> 386 hidden_states = self.dropout(hidden_states)
387 hidden_states = self.LayerNorm(hidden_states + input_tensor)
388 return hidden_states
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/dropout.py:58, in Dropout.forward(self, input)
57 def forward(self, input: Tensor) -> Tensor:
---> 58 return F.dropout(input, self.p, self.training, self.inplace)
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/functional.py:1252, in dropout(input, p, training, inplace)
1250 if p < 0.0 or p > 1.0:
1251 raise ValueError("dropout probability has to be between 0 and 1, " "but got {}".format(p))
-> 1252 return VF.dropout(input, p, training) if inplace else _VF.dropout(input, p, training)
KeyboardInterrupt:
# 加入对抗训练
class FGM():
def __init__(self, model):
self.model = model
self.backup = {}
def attack(self, epsilon=0.001):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and 'embeddings.word_embeddings' in name:
# 保存原始参数
self.backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0:
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self):
# emb_name这个参数要换成你模型中embedding的参数名
for name, param in self.model.named_parameters():
if param.requires_grad and 'embeddings.word_embeddings' in name:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
def process(data_loader, mode, optimizer=None, scheduler=None):
step, total_loss, total_acc = 0, 0, 0
for batch in train_loader:
# 正向传播
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs[0]
logits = outputs[1]
total_loss += loss.item()
pred = logits.detach().cpu()
label_ids = labels.to('cpu')
total_acc += accuracy(pred, label_ids)
if mode == 'train':
fgm = FGM(model)
optimizer.zero_grad()
loss.backward()
fgm.attack() # 在embedding上添加对抗扰动
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
outputs[0].backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
step += 1
if mode == 'train' and step % 2000 == 0:
print(f'iter_num: {step}, {mode}_loss: {loss.item()}, progress:{step/total_steps*100}%')
print(f'{mode}_average_loss:{total_loss / step}, {mode}_acc:{total_acc / step}')
for i in range(3):
print(f'-------------------------第{i+1}轮训练开始---------------------')
# 训练
model.train()
process(train_loader, mode='train', optimizer=optimizer, scheduler=scheduler)
# 计算验证集损失
model.eval()
with torch.no_grad():
process(test_loader, mode='valid')
-------------------------第1轮训练开始---------------------
iter_num: 2000, train_loss: 0.10326074808835983, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.21262915432453156, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.21447157859802246, progress:92.27929867733006%
train_average_loss:0.24003259284792497, train_acc:0.9002618949455835
valid_average_loss:0.16738152858047475, valid_acc:0.9339346634593607
-------------------------第2轮训练开始---------------------
iter_num: 2000, train_loss: 0.19769251346588135, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.4742729067802429, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.18049080669879913, progress:92.27929867733006%
train_average_loss:0.17529396013528914, train_acc:0.9301901862405697
valid_average_loss:0.1673766056904171, valid_acc:0.9339390327493362
-------------------------第3轮训练开始---------------------
iter_num: 2000, train_loss: 0.23520785570144653, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.11421637237071991, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.1428006887435913, progress:92.27929867733006%
train_average_loss:0.1755074827219364, train_acc:0.9306874108640864
valid_average_loss:0.1673783917777568, valid_acc:0.9339412173851568
# 构造SBERT模型
# SBERT把句子通过预训练BERT进行编码获得并按照一定的策略(如平均池化,或者取CLS)获得句向量
#然后送入后续网络进行分类。其实就是用BERT替换LSTM及其之前的部分作为encoder
import torch.nn as nn
from transformers import BertModel, BertTokenizer
import torch
import torch.nn.functional as F
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
class SentenceBert(nn.Module):
def __init__(self, model_name = 'bert-base-chinese', out_dim=2, vocab_size=768):
super(SentenceBert, self).__init__()
self.out_dim = out_dim
self.vocab_size = vocab_size
self.encoder = BertModel.from_pretrained(model_name)
self.hidden2tag = nn.Linear(4 * self.vocab_size, self.out_dim)
def forward(self, encoded_input1, encoded_input2):
# Compute token embeddings
with torch.no_grad():
model_output1 = self.encoder(**encoded_input1)
model_output2 = self.encoder(**encoded_input2)
# Perform pooling
pool_embed1 = mean_pooling(model_output1, encoded_input1['attention_mask'])
pool_embed2 = mean_pooling(model_output2, encoded_input2['attention_mask'])
# Normalize embeddings
embed1 = F.normalize(pool_embed1, p=2, dim=1)
embed2 = F.normalize(pool_embed2, p=2, dim=1)
sim = torch.cat([embed1, embed1 * embed2, torch.abs(embed1 - embed2), embed2], dim=-1)
# [batch_size, 2]
output = self.hidden2tag(sim)
return output
import transformers
from sklearn.model_selection import train_test_split
from torch.utils.data import Dataset, DataLoader, TensorDataset
transformers.logging.set_verbosity_error()
# 划分为训练集和验证集
# stratify 按照标签进行采样,训练集和验证部分同分布
q1_train, q1_val, q2_train, q2_val, train_label, test_label = train_test_split(
dataset['query1'],
dataset['query2'],
dataset['label'],
test_size=0.2,
stratify=dataset['label'])
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
q1_train_encoding = tokenizer(list(q1_train), truncation=True, padding=True, max_length=32)
q2_train_encoding = tokenizer(list(q2_train), truncation=True, padding=True, max_length=32)
q1_test_encoding = tokenizer(list(q1_val), truncation=True, padding=True, max_length=32)
q2_test_encoding = tokenizer(list(q2_val), truncation=True, padding=True, max_length=32)
# 数据集读取
class MyDataset(Dataset):
def __init__(self, q1_encodings, q2_encodings, labels):
self.q1_encodings = q1_encodings
self.q2_encodings = q2_encodings
self.labels = labels
# 读取单个样本
def __getitem__(self, idx):
item1 = {key: torch.tensor(val[idx]) for key, val in self.q1_encodings.items()}
item2 = {key: torch.tensor(val[idx]) for key, val in self.q2_encodings.items()}
label = torch.tensor(self.labels[idx])
return item1, item2, label
def __len__(self):
return len(self.labels)
train_dataset = MyDataset(q1_train_encoding, q2_train_encoding, list(train_label))
test_dataset = MyDataset(q1_test_encoding, q2_test_encoding, list(test_label))
train_dataset[:2]
({'input_ids': tensor([[ 101, 784, 720, 4277, 2094, 4638, 1922, 7345, 7262, 1962, 8043, 102,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 4263, 677, 1166, 782, 4638, 5439, 2038, 2582, 720, 1215, 102,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])},
{'input_ids': tensor([[ 101, 784, 720, 4277, 2094, 4638, 7676, 3717, 8024, 1914, 2208, 7178,
8043, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 4263, 677, 1166, 782, 4638, 5439, 2038, 2582, 720, 1215, 8043,
102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])},
tensor([0, 1]))
model = SentenceBert()
model = nn.DataParallel(model).cuda()
train_loader = DataLoader(train_dataset, batch_size=4 * 8, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=4 * 8, shuffle=True)
# 训练模型
from transformers import get_linear_schedule_with_warmup
import torch.optim as optim
def process(data_loader, mode, optimizer=None, scheduler=None):
step, total_loss, total_acc = 0, 0, 0
for q1, q2, tags in data_loader:
for k, v in q1.items():
q1[k] = v.cuda()
for k, v in q2.items():
q2[k] = v.cuda()
pred = model(q1, q2)
loss = nn.CrossEntropyLoss()(pred, tags.cuda())
total_loss += loss.item()
total_acc += accuracy(pred, tags.cuda())
if mode == 'train':
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
scheduler.step()
step += 1
if mode == 'train' and step % 2000 == 0:
print(f'iter_num: {step}, {mode}_loss: {loss.item()}, progress:{step/total_steps*100}%')
print(f'{mode}_average_loss:{total_loss / step}, {mode}_acc:{total_acc / step}')
EPOCH = 5
LEARNING_RATE = 2e-4
total_steps = len(train_loader) * 1
optimizer = optim.AdamW(model.parameters(), lr=LEARNING_RATE)
scheduler = get_linear_schedule_with_warmup(optimizer,
num_warmup_steps = 0, # Default value in run_glue.py
num_training_steps = total_steps)
for i in range(EPOCH):
print(f'-------------------------第{i+1}轮训练开始---------------------')
# 训练
model.train()
process(train_loader, mode='train', optimizer=optimizer, scheduler=scheduler)
# 计算验证集损失
model.eval()
with torch.no_grad():
process(test_loader, mode='valid')
-------------------------第1轮训练开始---------------------
iter_num: 2000, train_loss: 0.6034929752349854, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.460986852645874, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.4471384882926941, progress:92.27929867733006%
train_average_loss:0.5418581028088758, train_acc:0.7537261262302287
valid_average_loss:0.48876352958280367, valid_acc:0.7563944166436847
-------------------------第2轮训练开始---------------------
iter_num: 2000, train_loss: 0.557519793510437, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.5344920754432678, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.5915530920028687, progress:92.27929867733006%
train_average_loss:0.5003710666305283, train_acc:0.7816580912216888
valid_average_loss:0.4888062159476978, valid_acc:0.7563202864276234
-------------------------第3轮训练开始---------------------
iter_num: 2000, train_loss: 0.5355170369148254, progress:30.759766225776687%
iter_num: 4000, train_loss: 0.5583447217941284, progress:61.519532451553374%
iter_num: 6000, train_loss: 0.5360739231109619, progress:92.27929867733006%
train_average_loss:0.5007460270660249, train_acc:0.7811530018743827
valid_average_loss:0.48879986114314267, valid_acc:0.7563697065961024
-------------------------第4轮训练开始---------------------
iter_num: 2000, train_loss: 0.5362592935562134, progress:30.759766225776687%
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[42], line 54
52 # 训练
53 model.train()
---> 54 process(train_loader, mode='train', optimizer=optimizer, scheduler=scheduler)
56 # 计算验证集损失
57 model.eval()
Cell In[42], line 16, in process(data_loader, mode, optimizer, scheduler)
14 for k, v in q2.items():
15 q2[k] = v.cuda()
---> 16 pred = model(q1, q2)
17 loss = nn.CrossEntropyLoss()(pred, tags.cuda())
19 total_loss += loss.item()
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1130, in Module._call_impl(self, input, **kwargs)
1126 # If we don't have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1130 return forward_call(input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = [], []
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/parallel/data_parallel.py:167, in DataParallel.forward(self, inputs, **kwargs)
165 if len(self.device_ids) == 1:
166 return self.module(inputs[0], **kwargs[0])
--> 167 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
168 outputs = self.parallel_apply(replicas, inputs, kwargs)
169 return self.gather(outputs, self.output_device)
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/parallel/data_parallel.py:172, in DataParallel.replicate(self, module, device_ids)
171 def replicate(self, module, device_ids):
--> 172 return replicate(module, device_ids, not torch.is_grad_enabled())
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/parallel/replicate.py:115, in replicate(network, devices, detach)
113 module_indices[module] = i
114 for j in range(num_replicas):
--> 115 replica = module._replicate_for_data_parallel()
116 # This is a temporary fix for DDP. DDP needs to access the
117 # replicated model parameters. It used to do so through
118 # mode.parameters(). The fix added in #33907 for DP stops the
119 # parameters() API from exposing the replicated parameters.
120 # Hence, we add a _former_parameters dict here to support DDP.
121 replica._former_parameters = OrderedDict()
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1971, in Module._replicate_for_data_parallel(self)
1968 # replicas do not have parameters themselves, the replicas reference the original
1969 # module.
1970 replica._parameters = OrderedDict()
-> 1971 replica._buffers = replica._buffers.copy()
1972 replica._modules = replica._modules.copy()
1973 replica._is_replica = True # type: ignore[assignment]
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/modules/module.py:1220, in Module.setattr(self, name, value)
1217 d.discard(name)
1219 params = self.dict.get('_parameters')
-> 1220 if isinstance(value, Parameter):
1221 if params is None:
1222 raise AttributeError(
1223 "cannot assign parameters before Module.init() call")
File /opt/anaconda3/envs/jupyter/lib/python3.10/site-packages/torch/nn/parameter.py:10, in _ParameterMeta.instancecheck(self, instance)
9 def instancecheck(self, instance):
---> 10 return super().instancecheck(instance) or (
11 isinstance(instance, torch.Tensor) and getattr(instance, '_is_param', False))
KeyboardInterrupt:
结果显示SBERT效果还不如LSTM,远不如BERT,暂时不知道哪里出现的问题,要去看Sentence-Bert源码
# SimCSE 数据集构造
import transformers
from transformers import BertModel, BertTokenizer, BertConfig
from torch.utils.data import Dataset, DataLoader
transformers.logging.set_verbosity_error()
class TrainDataset(Dataset):
"""
训练数据集, 重写__getitem__和__len__方法
"""
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def text_2_id(self, text: str):
# 添加自身两次, 经过bert编码之后, 互为正样本
return tokenizer([text, text], max_length=32, truncation=True, padding='max_length', return_tensors='pt')
def __getitem__(self, index: int):
return self.text_2_id(self.data[index])
class TestDataset(Dataset):
"""
测试数据集, 重写__getitem__和__len__方法
"""
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def text_2_id(self, text: str):
return tokenizer(text, max_length=32, truncation=True, padding='max_length', return_tensors='pt')
def __getitem__(self, index: int):
da = self.data[index]
return self.text_2_id([da[0]]), self.text_2_id([da[1]]), int(da[2])
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
train_data = TrainDataset(train_set.query1.to_list()[:100000] + train_set.query2.to_list()[:100000])
val_data = TestDataset(list(zip(valid_set.query1.to_list(), valid_set.query2.to_list(), valid_set.label.to_list()))[:5000])
test_data = TestDataset(list(zip(test_set.query1.to_list(), test_set.query2.to_list(), test_set.label.to_list()))[:5000])
# 构造SimCSE unsper模型
import torch
import torch.nn as nn
from loguru import logger
class SimcseModel(nn.Module):
"""Simcse无监督模型定义"""
def __init__(self, pretrained_model='bert-base-chinese', pooling='last-avg', DROPOUT=0.3):
super(SimcseModel, self).__init__()
config = BertConfig.from_pretrained(pretrained_model)
config.attention_probs_dropout_prob = DROPOUT # 修改config的dropout系数
config.hidden_dropout_prob = DROPOUT
self.bert = BertModel.from_pretrained(pretrained_model, config=config)
self.pooling = pooling
def forward(self, input_ids, attention_mask, token_type_ids):
out = self.bert(input_ids, attention_mask, token_type_ids, output_hidden_states=True)
if self.pooling == 'cls':
return out.last_hidden_state[:, 0] # [batch, 768]
if self.pooling == 'pooler':
return out.pooler_output # [batch, 768]
if self.pooling == 'last-avg':
last = out.last_hidden_state.transpose(1, 2) # [batch, 768, seqlen]
return torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
if self.pooling == 'first-last-avg':
first = out.hidden_states[1].transpose(1, 2) # [batch, 768, seqlen]
last = out.hidden_states[-1].transpose(1, 2) # [batch, 768, seqlen]
first_avg = torch.avg_pool1d(first, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
last_avg = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
avg = torch.cat((first_avg.unsqueeze(1), last_avg.unsqueeze(1)), dim=1) # [batch, 2, 768]
return torch.avg_pool1d(avg.transpose(1, 2), kernel_size=2).squeeze(-1) # [batch, 768]
def simcse_unsup_loss(y_pred: 'tensor') -> 'tensor':
"""无监督的损失函数
y_pred (tensor): bert的输出, [batch_size * 2, 768]
"""
# 得到y_pred对应的label, [1, 0, 3, 2, ..., batch_size-1, batch_size-2]
y_true = torch.arange(y_pred.shape[0]).cuda()
y_true = (y_true - y_true % 2 * 2) + 1
# batch内两两计算相似度, 得到相似度矩阵(对角矩阵)
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
# 将相似度矩阵对角线置为很小的值, 消除自身的影响
sim = sim - torch.eye(y_pred.shape[0]).cuda() * 1e12
# 相似度矩阵除以温度系数
sim = sim / 0.05
# 计算相似度矩阵与y_true的交叉熵损失
loss = F.cross_entropy(sim, y_true)
return loss
def eval(model, dataloader) -> float:
"""模型评估函数
批量预测, batch结果拼接, 一次性求spearman相关度
"""
model.eval()
sim_tensor = torch.tensor([], device=DEVICE)
label_array = np.array([])
with torch.no_grad():
for source, target, label in dataloader:
# source [batch, 1, seq_len] -> [batch, seq_len]
source_input_ids = source.get('input_ids').squeeze(1).to(DEVICE)
source_attention_mask = source.get('attention_mask').squeeze(1).to(DEVICE)
source_token_type_ids = source.get('token_type_ids').squeeze(1).to(DEVICE)
source_pred = model(source_input_ids, source_attention_mask, source_token_type_ids)
# target [batch, 1, seq_len] -> [batch, seq_len]
target_input_ids = target.get('input_ids').squeeze(1).to(DEVICE)
target_attention_mask = target.get('attention_mask').squeeze(1).to(DEVICE)
target_token_type_ids = target.get('token_type_ids').squeeze(1).to(DEVICE)
target_pred = model(target_input_ids, target_attention_mask, target_token_type_ids)
# concat
sim = F.cosine_similarity(source_pred, target_pred, dim=-1)
sim_tensor = torch.cat((sim_tensor, sim), dim=0)
label_array = np.append(label_array, np.array(label))
# corrcoef
return spearmanr(label_array, sim_tensor.cpu().numpy()).correlation
def train(model, train_dl, dev_dl, optimizer) -> None:
"""模型训练函数"""
model.train()
global best
for batch_idx, source in enumerate(train_dl):
# 维度转换 [batch, 2, seq_len] -> [batch * 2, sql_len]
real_batch_num = source.get('input_ids').shape[0]
input_ids = source.get('input_ids').view(real_batch_num * 2, -1).to(DEVICE)
attention_mask = source.get('attention_mask').view(real_batch_num * 2, -1).to(DEVICE)
token_type_ids = source.get('token_type_ids').view(real_batch_num * 2, -1).to(DEVICE)
out = model(input_ids, attention_mask, token_type_ids)
loss = simcse_unsup_loss(out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch_idx and batch_idx % 1000 == 0:
print(f'idx:{batch_idx}, loss: {loss.item():.4f}, progress:{100*batch_idx/len(train_dl):.4f}%')
corrcoef = eval(model, dev_dl)
model.train()
if best < corrcoef:
best = corrcoef
torch.save(model.state_dict(), SAVE_PATH)
print(f"higher corrcoef: {best:.4f} in batch: {batch_idx}, save model")
import torch.nn.functional as F
DEVICE = 'cuda'
POOLING = 'cls'
model_name = 'bert-base-chinese'
BATCH_SIZE = 64
LR = 2e-6
train_dataloader = DataLoader(train_data, batch_size=BATCH_SIZE)
dev_dataloader = DataLoader(val_data, batch_size=BATCH_SIZE)
test_dataloader = DataLoader(test_data, batch_size=BATCH_SIZE)
from scipy.stats import spearmanr
# load model
model = SimcseModel(pretrained_model=model_name, pooling=POOLING)
model = nn.DataParallel(model).cuda()
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
# train
EPOCHS = 5
SAVE_PATH = 'best_model.pt'
best = 0
for epoch in range(EPOCHS):
print(f'------------------------ epoch: {epoch + 1}------------------------')
train(model, train_dataloader, dev_dataloader, optimizer)
print(f'train is finished, best model is saved at {SAVE_PATH}')
# eval
model.load_state_dict(torch.load(SAVE_PATH))
dev_corrcoef = eval(model, dev_dataloader)
test_corrcoef = eval(model, test_dataloader)
print(f'dev_corrcoef: {dev_corrcoef:.4f}')
print(f'test_corrcoef: {test_corrcoef:.4f}')
------------------------ epoch: 1------------------------
idx:1000, loss: 0.1693, progress:32.0000%
higher corrcoef: 0.6005 in batch: 1000, save model
idx:2000, loss: 0.0759, progress:64.0000%
idx:3000, loss: 0.0367, progress:96.0000%
train is finished, best model is saved at best_model.pt
------------------------ epoch: 2------------------------
idx:1000, loss: 0.0159, progress:32.0000%
idx:2000, loss: 0.0193, progress:64.0000%
idx:3000, loss: 0.0090, progress:96.0000%
train is finished, best model is saved at best_model.pt
------------------------ epoch: 3------------------------
idx:1000, loss: 0.0097, progress:32.0000%
idx:2000, loss: 0.0059, progress:64.0000%
idx:3000, loss: 0.0052, progress:96.0000%
train is finished, best model is saved at best_model.pt
------------------------ epoch: 4------------------------
idx:1000, loss: 0.0040, progress:32.0000%
idx:2000, loss: 0.0058, progress:64.0000%
idx:3000, loss: 0.0034, progress:96.0000%
train is finished, best model is saved at best_model.pt
------------------------ epoch: 5------------------------
idx:1000, loss: 0.0030, progress:32.0000%
idx:2000, loss: 0.0028, progress:64.0000%
idx:3000, loss: 0.0028, progress:96.0000%
train is finished, best model is saved at best_model.pt
dev_corrcoef: 0.6005
test_corrcoef: 0.6579
import random
import time
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from scipy.stats import spearmanr
from torch.utils.data import DataLoader, Dataset
from transformers import BertConfig, BertModel, BertTokenizer
# 基本参数
EPOCHS = 2
BATCH_SIZE = 32
LR = 1e-6
MAXLEN = 32
POOLING = 'cls' # choose in ['cls', 'pooler', 'last-avg', 'first-last-avg']
DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 预训练模型
model_name = 'bert-base-chinese'
# 微调后参数存放位置
SAVE_PATH = 'simcse_sup.pt'
def load_train_data(data) -> list:
"""
"""
q1 = data.query1.to_list()
q2 = data.query2.to_list()
train_data = []
for i in range(len(q1) - 1):
train_data.append([q1[i], q2[i], q1[i+1]])
return train_data
class TrainDataset(Dataset):
"""训练数据集, 重写__getitem__和__len__方法
"""
def __init__(self, data: list):
self.data = data
def __len__(self):
return len(self.data)
def text_2_id(self, text: str):
return tokenizer([text[0], text[1], text[2]], max_length=MAXLEN,
truncation=True, padding='max_length', return_tensors='pt')
def __getitem__(self, index: int):
return self.text_2_id(self.data[index])
class TestDataset(Dataset):
"""测试数据集, 重写__getitem__和__len__方法
"""
def __init__(self, data: list):
self.data = data
def __len__(self):
return len(self.data)
def text_2_id(self, text: str):
return tokenizer(text, max_length=MAXLEN, truncation=True,
padding='max_length', return_tensors='pt')
def __getitem__(self, index):
line = self.data[index]
return self.text_2_id([line[0]]), self.text_2_id([line[1]]), int(line[2])
train_data = TrainDataset(load_train_data(train_set[train_set['label'] == 1]))
val_data = TestDataset(list(zip(valid_set.query1.to_list(), valid_set.query2.to_list(), valid_set.label.to_list()))[:5000])
test_data = TestDataset(list(zip(test_set.query1.to_list(), test_set.query2.to_list(), test_set.label.to_list()))[:5000])
print(train_data[0])
{'input_ids': tensor([[ 101, 1599, 3614, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614, 784,
720, 3416, 4638, 1957, 4495, 102, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 4263, 2802, 5074, 4413, 4638, 4511, 4495, 1599, 3614, 784, 720,
3416, 4638, 1957, 4495, 102, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[ 101, 2769, 2797, 3322, 696, 749, 8024, 2769, 2682, 2940, 702, 2797,
3322, 102, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]), 'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0]])}
# -*- encoding: utf-8 -*-
class SimcseModel(nn.Module):
"""Simcse有监督模型定义"""
def __init__(self, pretrained_model: str, pooling: str):
super(SimcseModel, self).__init__()
# config = BertConfig.from_pretrained(pretrained_model) # 有监督不需要修改dropout
self.bert = BertModel.from_pretrained(pretrained_model)
self.pooling = pooling
def forward(self, input_ids, attention_mask, token_type_ids):
# out = self.bert(input_ids, attention_mask, token_type_ids)
out = self.bert(input_ids, attention_mask, token_type_ids, output_hidden_states=True)
if self.pooling == 'cls':
return out.last_hidden_state[:, 0] # [batch, 768]
if self.pooling == 'pooler':
return out.pooler_output # [batch, 768]
if self.pooling == 'last-avg':
last = out.last_hidden_state.transpose(1, 2) # [batch, 768, seqlen]
return torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
if self.pooling == 'first-last-avg':
first = out.hidden_states[1].transpose(1, 2) # [batch, 768, seqlen]
last = out.hidden_states[-1].transpose(1, 2) # [batch, 768, seqlen]
first_avg = torch.avg_pool1d(first, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
last_avg = torch.avg_pool1d(last, kernel_size=last.shape[-1]).squeeze(-1) # [batch, 768]
avg = torch.cat((first_avg.unsqueeze(1), last_avg.unsqueeze(1)), dim=1) # [batch, 2, 768]
return torch.avg_pool1d(avg.transpose(1, 2), kernel_size=2).squeeze(-1) # [batch, 768]
def simcse_sup_loss(y_pred: 'tensor') -> 'tensor':
"""有监督的损失函数
y_pred (tensor): bert的输出, [batch_size * 3, 768]
"""
# 得到y_pred对应的label, 每第三句没有label, 跳过, label= [1, 0, 4, 3, ...]
y_true = torch.arange(y_pred.shape[0], device=DEVICE)
use_row = torch.where((y_true + 1) % 3 != 0)[0]
y_true = (use_row - use_row % 3 * 2) + 1
# batch内两两计算相似度, 得到相似度矩阵(对角矩阵)
sim = F.cosine_similarity(y_pred.unsqueeze(1), y_pred.unsqueeze(0), dim=-1)
# 将相似度矩阵对角线置为很小的值, 消除自身的影响
sim = sim - torch.eye(y_pred.shape[0], device=DEVICE) * 1e12
# 选取有效的行
sim = torch.index_select(sim, 0, use_row)
# 相似度矩阵除以温度系数
sim = sim / 0.05
# 计算相似度矩阵与y_true的交叉熵损失
loss = F.cross_entropy(sim, y_true)
return loss
def eval(model, dataloader) -> float:
"""模型评估函数
批量预测, 计算cos_sim, 转成numpy数组拼接起来, 一次性求spearman相关度
"""
model.eval()
sim_tensor = torch.tensor([], device=DEVICE)
label_array = np.array([])
with torch.no_grad():
for source, target, label in dataloader:
# source [batch, 1, seq_len] -> [batch, seq_len]
source_input_ids = source['input_ids'].squeeze(1).to(DEVICE)
source_attention_mask = source['attention_mask'].squeeze(1).to(DEVICE)
source_token_type_ids = source['token_type_ids'].squeeze(1).to(DEVICE)
source_pred = model(source_input_ids, source_attention_mask, source_token_type_ids)
# target [batch, 1, seq_len] -> [batch, seq_len]
target_input_ids = target['input_ids'].squeeze(1).to(DEVICE)
target_attention_mask = target['attention_mask'].squeeze(1).to(DEVICE)
target_token_type_ids = target['token_type_ids'].squeeze(1).to(DEVICE)
target_pred = model(target_input_ids, target_attention_mask, target_token_type_ids)
# concat
sim = F.cosine_similarity(source_pred, target_pred, dim=-1)
sim_tensor = torch.cat((sim_tensor, sim), dim=0)
label_array = np.append(label_array, np.array(label))
# corrcoef
return spearmanr(label_array, sim_tensor.cpu().numpy()).correlation
def train(model, train_dl, dev_dl, optimizer) -> None:
"""模型训练函数
"""
model.train()
global best
early_stop_batch = 0
for batch_idx, source in enumerate(train_dl, start=1):
# 维度转换 [batch, 3, seq_len] -> [batch * 3, sql_len]
real_batch_num = source.get('input_ids').shape[0]
input_ids = source.get('input_ids').view(real_batch_num * 3, -1).to(DEVICE)
attention_mask = source.get('attention_mask').view(real_batch_num * 3, -1).to(DEVICE)
token_type_ids = source.get('token_type_ids').view(real_batch_num * 3, -1).to(DEVICE)
# 训练
out = model(input_ids, attention_mask, token_type_ids)
loss = simcse_sup_loss(out)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 评估
if batch_idx % 100 == 0:
print(f'batch_idx:{batch_idx}, loss: {loss.item():.4f}, progress:{100*batch_idx/len(train_dl):.4f}%')
corrcoef = eval(model, dev_dl)
model.train()
if best < corrcoef:
early_stop_batch = 0
best = corrcoef
torch.save(model.state_dict(), SAVE_PATH)
print(f"higher corrcoef: {best:.4f} in batch: {batch_idx}, save model")
continue
early_stop_batch += 1
if early_stop_batch == 5:
print(f"corrcoef doesn't improve for {early_stop_batch} batch, early stop!")
print(f"train use sample number: {(batch_idx - 10) * BATCH_SIZE}")
return
tokenizer = BertTokenizer.from_pretrained(model_name)
# load data
train_dataloader = DataLoader(train_data, batch_size=BATCH_SIZE)
dev_dataloader = DataLoader(val_data, batch_size=BATCH_SIZE)
test_dataloader = DataLoader(test_data, batch_size=BATCH_SIZE)
# load model
model = SimcseModel(pretrained_model=model_name, pooling=POOLING)
model.to(DEVICE)
optimizer = torch.optim.AdamW(model.parameters(), lr=LR)
# train
best = 0
for epoch in range(EPOCHS):
print(f'----------------------epoch: {epoch + 1}-----------------------')
train(model, train_dataloader, dev_dataloader, optimizer)
print(f'train is finished, best model is saved at {SAVE_PATH}')
# eval
model.load_state_dict(torch.load(SAVE_PATH))
dev_corrcoef = eval(model, dev_dataloader)
test_corrcoef = eval(model, test_dataloader)
print(f'dev_corrcoef: {dev_corrcoef:.4f}')
print(f'test_corrcoef: {test_corrcoef:.4f}')
----------------------epoch: 1-----------------------
batch_idx:100, loss: 1.1291, progress:2.3089%
higher corrcoef: 0.4878 in batch: 100, save model
batch_idx:200, loss: 0.9710, progress:4.6179%
higher corrcoef: 0.5499 in batch: 200, save model
batch_idx:300, loss: 0.9440, progress:6.9268%
higher corrcoef: 0.5832 in batch: 300, save model
batch_idx:400, loss: 0.9957, progress:9.2357%
higher corrcoef: 0.6009 in batch: 400, save model
batch_idx:500, loss: 0.8824, progress:11.5447%
higher corrcoef: 0.6119 in batch: 500, save model
batch_idx:600, loss: 0.9363, progress:13.8536%
higher corrcoef: 0.6195 in batch: 600, save model
batch_idx:700, loss: 0.8632, progress:16.1625%
higher corrcoef: 0.6234 in batch: 700, save model
batch_idx:800, loss: 0.8339, progress:18.4715%
higher corrcoef: 0.6258 in batch: 800, save model
batch_idx:900, loss: 0.8889, progress:20.7804%
higher corrcoef: 0.6271 in batch: 900, save model
batch_idx:1000, loss: 0.8728, progress:23.0894%
higher corrcoef: 0.6275 in batch: 1000, save model
batch_idx:1100, loss: 0.8358, progress:25.3983%
batch_idx:1200, loss: 0.8673, progress:27.7072%
batch_idx:1300, loss: 0.8888, progress:30.0162%
batch_idx:1400, loss: 0.8947, progress:32.3251%
batch_idx:1500, loss: 0.7396, progress:34.6340%
corrcoef doesn't improve for 5 batch, early stop!
train use sample number: 47680
----------------------epoch: 2-----------------------
batch_idx:100, loss: 0.7435, progress:2.3089%
batch_idx:200, loss: 0.7990, progress:4.6179%
batch_idx:300, loss: 0.8162, progress:6.9268%
batch_idx:400, loss: 0.7929, progress:9.2357%
batch_idx:500, loss: 0.7649, progress:11.5447%
corrcoef doesn't improve for 5 batch, early stop!
train use sample number: 15680
train is finished, best model is saved at simcse_sup.pt
dev_corrcoef: 0.6275
test_corrcoef: 0.6614

 浙公网安备 33010602011771号
浙公网安备 33010602011771号