随笔分类 - NLP初学
摘要:写在前面 该系列主要事对指针网络在NER以及关系抽取系列取得的成果进行展示,并根据大佬们的笔记总结其中的优劣以及理论分析。 GlobalPointer 在之前的工作中,我们NER采用传统的LSTM+CRF,在各个字段指标也取得不错的效果,简单字段类似学历这种f1值均在95以上,复杂一点的比如
阅读全文
摘要:問題描述 ValueError: Unknown loss function: bes_loss 問題場景 訓練 margin = 0.6 theta = lambda t : (K.sign(t) + 1.) / 2 def bes_loss(y_true, y_pred): return - (
阅读全文
摘要: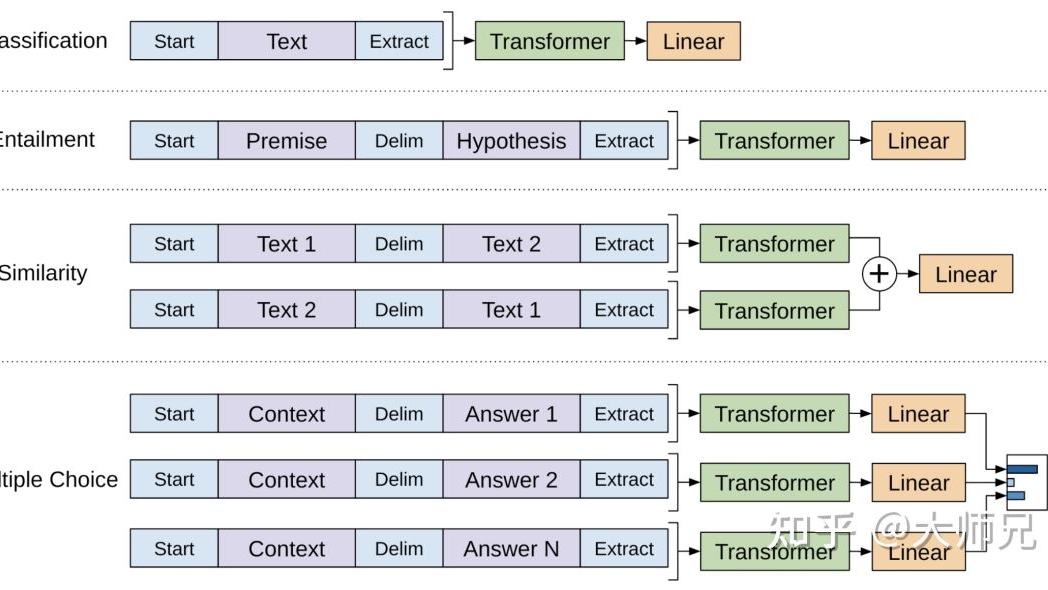 简介 GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法
阅读全文
简介 GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法
阅读全文
简介 GPT(Generative Pre-trained Transformer)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在生成式任务中取得非常好的效果,对于一个新的任务,GTP只需要很少的数据便可以理解任务的需求并达到或接近state-of-the-art的方法
阅读全文
摘要:交叉熵损失函数 - Cross entropy loss function 标准形式 \[ \color{blue}{C=-\frac{1}{n}\sum_x{[ylna+(1-y)ln(1-a)]} (1)} \] 其中$\color{blue}{x}\(表示样本,\)\color{blue}
阅读全文
摘要:关于seq2seq attention 讲解最好的一篇(因为我都看懂了) https://towardsdatascience.com/attn-illustrated-attention-5ec4ad276ee3
阅读全文
摘要:NER 标准 LSTM+CRF 问题 标准成本昂贵 泛化迁移能力不足 可解释性不强 计算资源 JD和CV描述形式不一样 严谨性,简历内容要识别出能力词以及深层挖掘能力词(看起来并不是能力词,但是代表实际的某项能力),所以的深度挖掘词意 不依赖NER,根据词典或者特定语句形式(规则)提出实体词,最后进
阅读全文
摘要:seq2seq " " 每个词在编码器端,经过双向LSTM,在解码端编码层的隐藏状态和解码器的隐藏状态,做一个加法attention: $$ e_i^t = v^Ttanh(W_hh_i+W_ss_t+b_{attn}) $$ $$ a^t = softmax(e^t) $$ 其中: + $h_i$
阅读全文
摘要:Word2Vec 写在前面:最近在学习word2vec,所以记录一下这方面的东西,主要包括skip gram,cbow以及公式推导及实现 提出 word2vec是Google2013年开源推出的工具包,它简单高效,迅速吸引了大量学者投身其中。对于其中的细节内容却不甚了解。据此,本文也就呼之欲出,就是
阅读全文
摘要:写在前面:此篇纯属自我记录,参考意义不大。 数据类型 数值型 标量Scalar:1.0,2.3等,shape为0->[] a = 1.2 向量Vector:[1.0],[2.3,5.4]等,shape为1->[n] a = tf.constant([2.3,5.4]) 矩阵Matrix:[[1.0,
阅读全文
摘要:写在前面:在初学nlp时的第一个任务——NER,尝试了几种方法,cnn+crf、lstm+crf、bert+lstm+crf,毫无疑问,最后结果时Bert下效果最好。 1、关于NER: NER即命名实体识别是信息提取的一个子任务,但究其本质就是序列标注任务。 eg: sentence:壹 叁 去 参
阅读全文
摘要:jieba中文分词¶ 中文与拉丁语言不同,不是以空格分开每个有意义的词,在我们处理自然语言处理的时候,大部分情况下,词汇是对句子和文章的理解基础。因此需要一个工具去把完整的中文分解成词。 jieba是一个分词起家的中文工具。 基本分词函数与用法¶ 安装:pip install jieba(全自动安装
阅读全文
摘要:Python 正则表达式¶ In [1]: import re pattern = re.compile(r'hello.*\!') print(pattern) match = pattern.match('hello,World! how are you?') if match: print(m
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号