Flink
- Flink是一个有状态的流式计算,意味着可以存放中间计算结果
一.Flink部署
放表格
二.一些重要概念
- 并行度:一个算子的子任务就是并行度,比如一个map有2个subTask,并行度就是2,每一个subTask占用一个slot槽。整个流程序的并行度是算子中最大的并行度
- 算子链:为了资源的充分利用,前后相连接的算子可以合并在一起,形成一个算子链,放在一个task中执行。所以我们看到好多dataflow图,一个框里有多个算子。
- 前提条件:算子之前有2种关系:一对一,比如source到map;重分区:一对多的关系,比如keyBy和window,并行度为2,会根据key的值,有数据流会发送改变。
- 形成条件:并行度一样&&一对一关系的算子会形成一个算子链、
- 图:
- StreamGraph(逻辑流图):主要是根据DataStream在客户端生成的图
- JobGraph(作业图):对逻辑流图进行优化,主要是合并算子链
- ExecutionGraph(执行图):jobManager执行,主要是作业图并行化版本,按照并行度进行拆分
- Physical Graph(物理图):TaskManager执行,主要确认数据存放位置和收发方式,然后就可以对过来的数据进行处理计算
- 子任务,任务槽,并行度
- 子任务(subTask):就是一个并行度任务,每个子任务都需要一个线程
- 任务槽(task Slots):每一个taskManager就是一个jvm进程,那么将进程划分成多个线程,每一个线程就是一个slots槽
- 共享任务槽:如果slots槽不够,多个subTask可以公用一个slots槽。主要是为了将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的slots,而不是有的slot任务轻,有的重。如图:
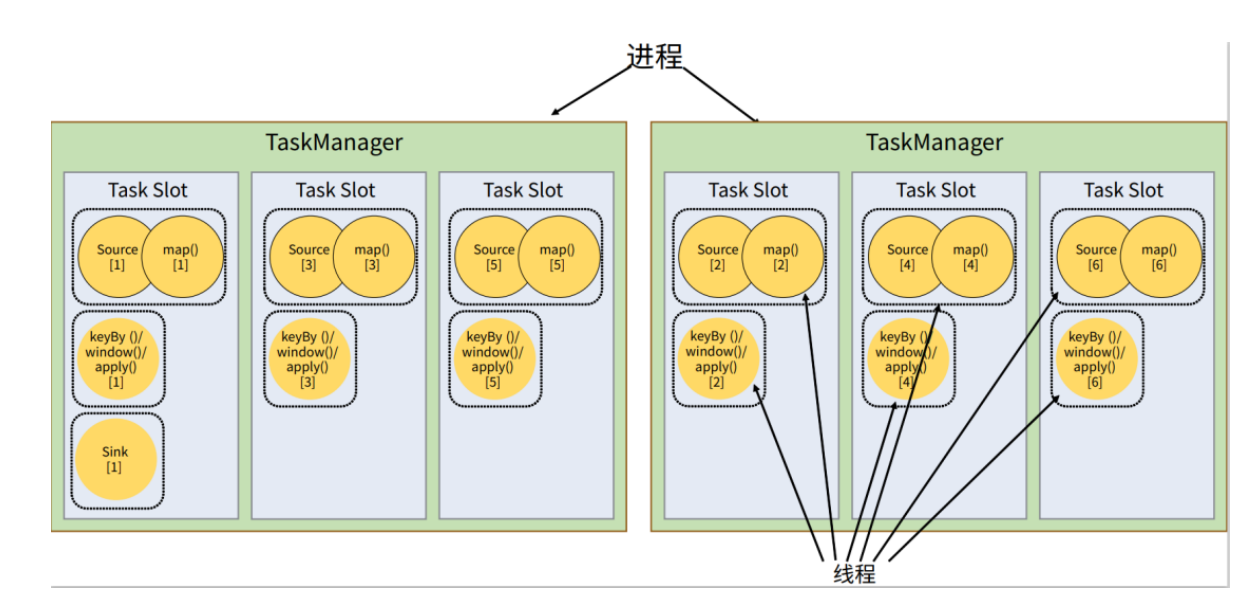
- 共享任务槽:如果slots槽不够,多个subTask可以公用一个slots槽。主要是为了将资源密集型和非密集型的任务同时放到一个slot中,它们就可以自行分配对资源占用的比例,从而保证最重的活平均分配给所有的slots,而不是有的slot任务轻,有的重。如图:
- 并行度:我们程序设置的并行度受限于solt的数量,比如solt为5,并行度为6,实际并行度还是5
三.DataStream
获取运行环境:
// 获取执行环境 StreamExecutionEnvironment.getExecutionEnvironment(); // 设置执行模式 execution.runtime-mode=STREAMING(流处理,默认)/BATCH(批处理)/AUTOMATIC(自动选择)
源/输出算子:
env.addSource(); env.addSink(); // 自定义Source 1.实现SourceFunction接口,重新run() 2.新架构的Source:吃透 Flink 架构:一个新版 Connector 的实现 - 知乎 (zhihu.com)
转换算子:
基本转化算子:
- map:一一映射,将数据进行转换,形成新的数据
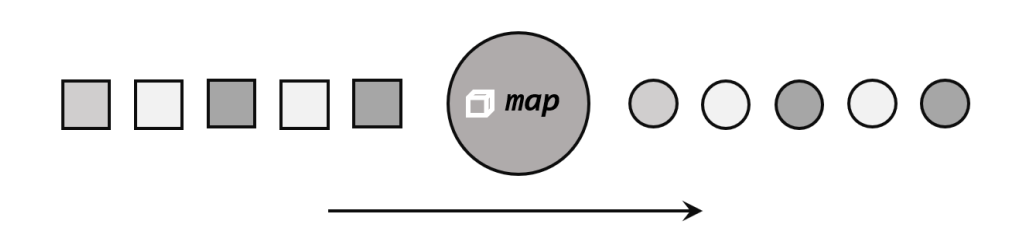
- flatMap:扁平化映射,一对多,可以过滤。结合了map和filter的特性。比如将wordCount程序的输入数据,进行转化:

- filter:数据过滤
聚合算子:Flink做聚合计算,就是把计算中间结果保存起来。要做聚合,需要先进行分区(keyBy),分区后执行sum等聚合运算,flink就会存储中间计算结果,一直累加
- keyBy:按照某个key进行分区,分区后中间计算结果会被保存
- 简单聚合:使用sum(),max(),min()等内置方法

- 规约聚合:使用reduce()方法自定义统计方法。主要可以实现ReduceFunction接口进行自定义
自定义函数:如上的算子map,filter,reduce等,需要写具体逻辑,就要实现RichMapFunction、RichFilterFunction、 RichReduceFunction等接口,这些都是叫自定义函数
物理分区:keyBy是逻辑分区,实际真正每个key分到哪个slot是不知道的,就可能造成某一个分区key的数量很多,就会造成某一个slot的压力很大。所以flink提供一些方法供我们做底层逻辑分区
- 随机分区:shuffle()
- 轮询分区:rebalance()
- 重缩放分区:rescale(),就是分组进行轮询分区,只在自己的组进行轮询
- 广播分区:broadcast(),让每一个slot都重复的接收算子
- 全局分区:global(),很极端,让所有的算子都分配到一个slot上
- 自定义分区:Custom(),按照自己的要求进行分区
四.时间和窗口
- 时间:时间是存在差异的,一条数据有事件时间(产生时间),也有处理时间(就是在flink处理的时间)。比如处理8-9点数据,是处理8-9点产生的数据呢?还是处理8-9到达flink的数据呢?
- 显然一般都是处理事件时间,就是按照数据产生的时间。
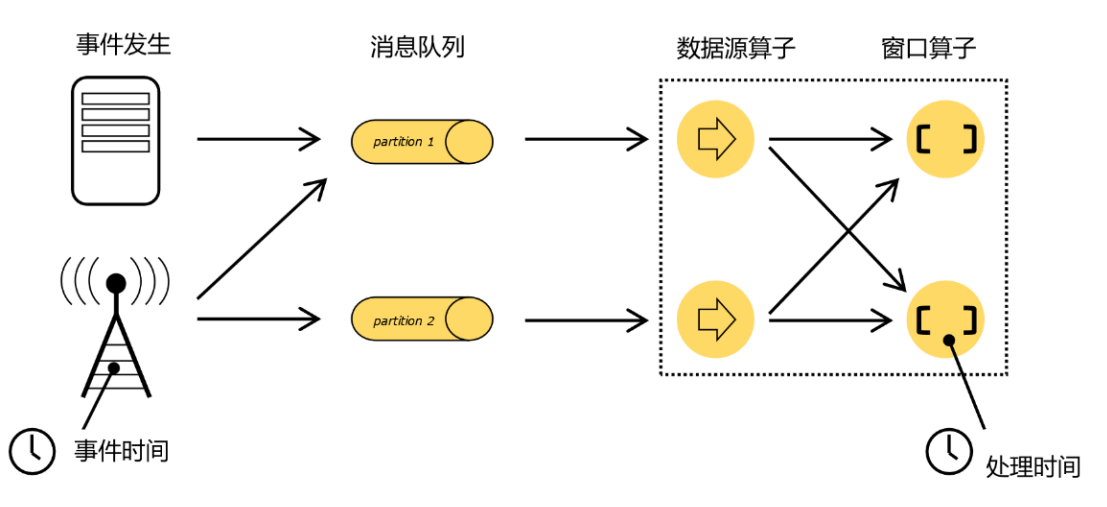
- 有问题,事件时间其实就是一个数据的一个标识,比如像日志数据那样,那么窗口在处理数据要看这个标识。如果数据一直没有到来,下游算子是没办法知道时间的,所以就需要定义一个公共的"逻辑时间"
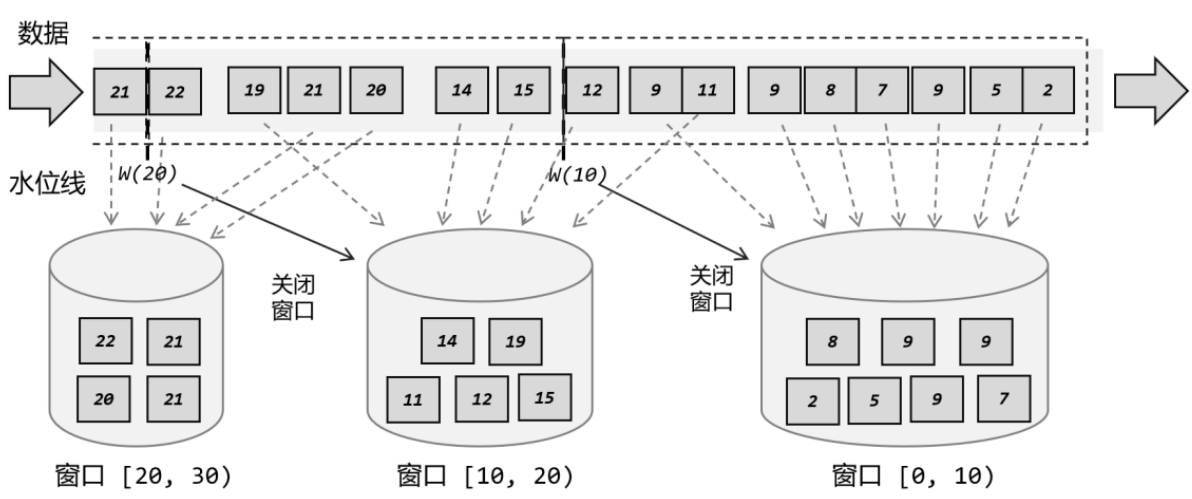
- 水位线:在 Flink 中,这种用来衡量事件时间进展的标记,就被称作“水位线”(Watermark)
- 分类:
- 每个数据更新一下水位线
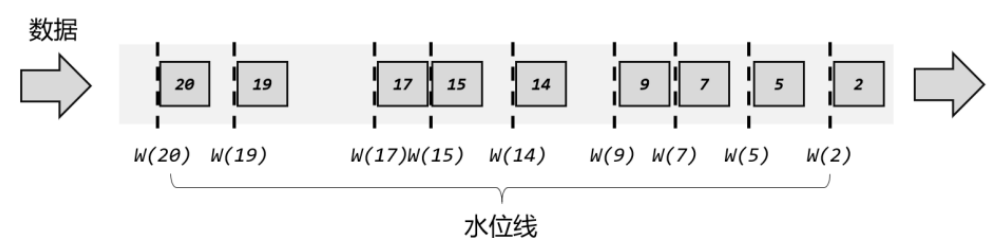
- 周期性更新水位线:因为数据量太大,时间戳可能重复,水位线会被重复更新,所以一般采用周期性更新

- 每个数据更新一下水位线
- 乱序问题:理想情况下,数据是按序来的,但是不排除有乱序的情况,水位线怎么处理
- 水位线一定是递增的,只有发现新来的数据比水位线时间戳大,才更新水位线,小的话不更新

-
对于晚来的数据,可以根据经验设置水位线延迟,比如一般乱序3s左右,设置水位线慢3s,窗口就可以慢3s。其他没等到的数据就会丢失
- 水位线一定是递增的,只有发现新来的数据比水位线时间戳大,才更新水位线,小的话不更新
- Watermark = 当前最大事件时间 - 乱序时间 - 1ms
- 水位线的传递:是依靠数据进行传递,但是数据如果分区多个子任务,有的水位线快有的水位线慢,下游数据要根据"之前数据都到齐"原则,取最慢的水位线
- 分类:
- 窗口:流处理是无界的,但是我们一般会统计一个"范围"之内的数据,这时候就需要将无界流变为无数个有界流(数据块)进行处理,这些数据块就是窗口。
- 和聚合函数不同的是,聚合函数会来一条数据,更新输出一条结果,而窗口是一批数据输出一个结果
- 窗口是动态创建的,同时可以有多个窗口存在,如图:
- 分类:
- 按照驱动类型:时间窗口(按照水位线);计数窗口(人满发车)
- 按照分配规则:
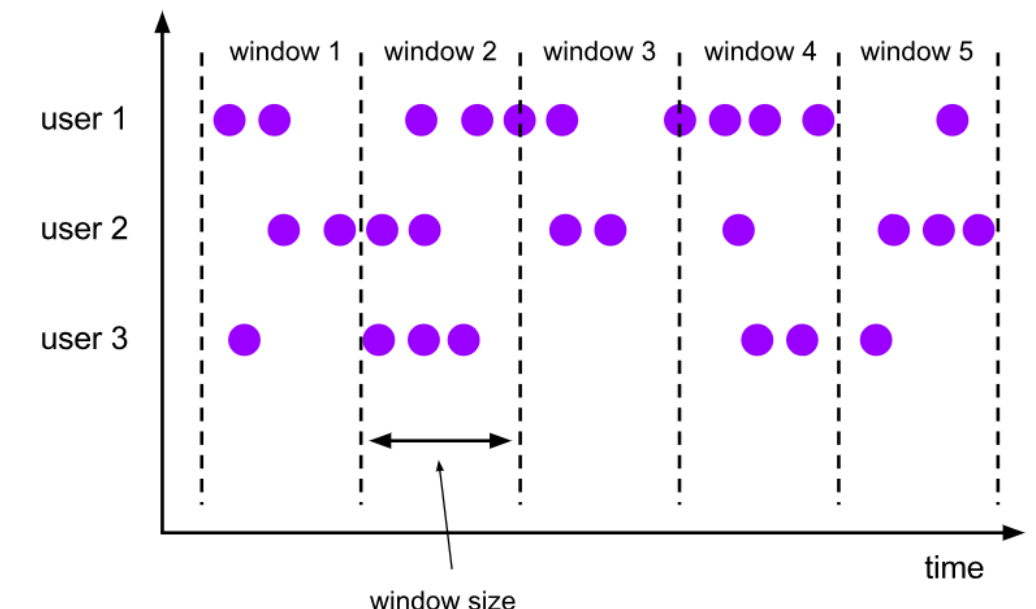
- 滚动窗口:类似窗口不停向后翻滚,首尾相连,没有重复部分。比如计算8-9的数据
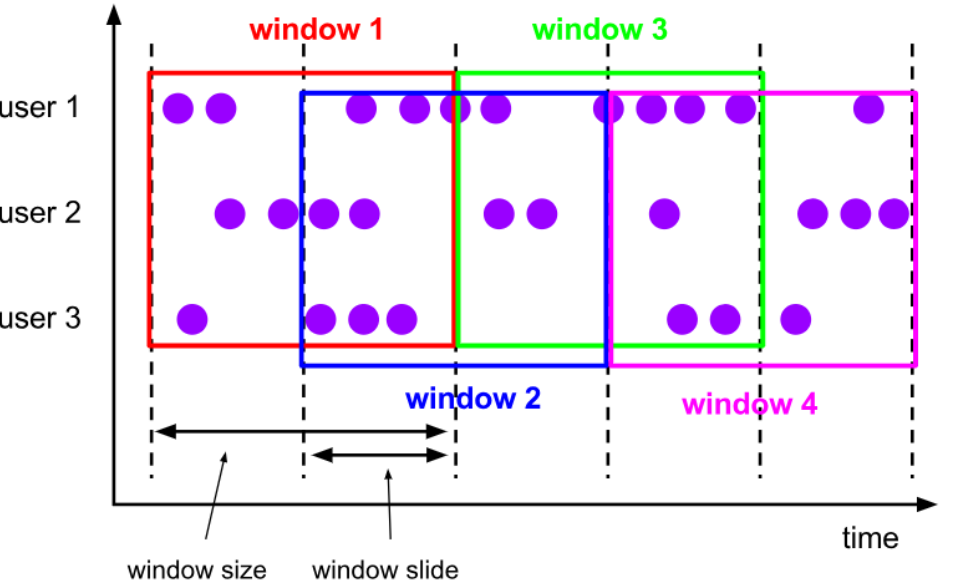
- 滑动窗口: 类似窗口不停向后滑动,每次滑动一步,但是窗口大小不变,有重复部分。比如统计24小时内数据
- 会话窗口:类似打电话,有数据到就开启会话(开启窗口),没有数据就关闭会话(关闭窗口)。比如做一些报警处理,有问题才弄个窗口计算指标数据
-
全局窗口:全局窗口没有关闭窗口一说,需要你自定义触发器,进行关闭窗口和开启窗口
- 滚动窗口:类似窗口不停向后翻滚,首尾相连,没有重复部分。比如计算8-9的数据
- 组成部分:
- 窗口分配器:就是决定使用什么类型窗口
- 窗口函数: 就是窗口做什么计算
五.合流和分流
分流:
- process Function 的测出流(side output)
合流:
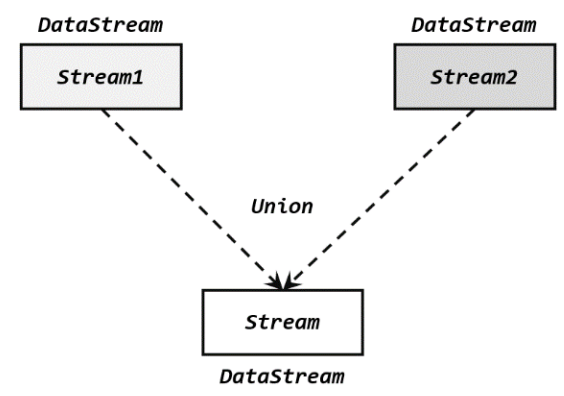
- Union:可以合并多条流,数据类型是一致的。
- Connect:只能合并2条流,数据类型可以不一直,主要是合成一个流后做map操作区分数据类型。
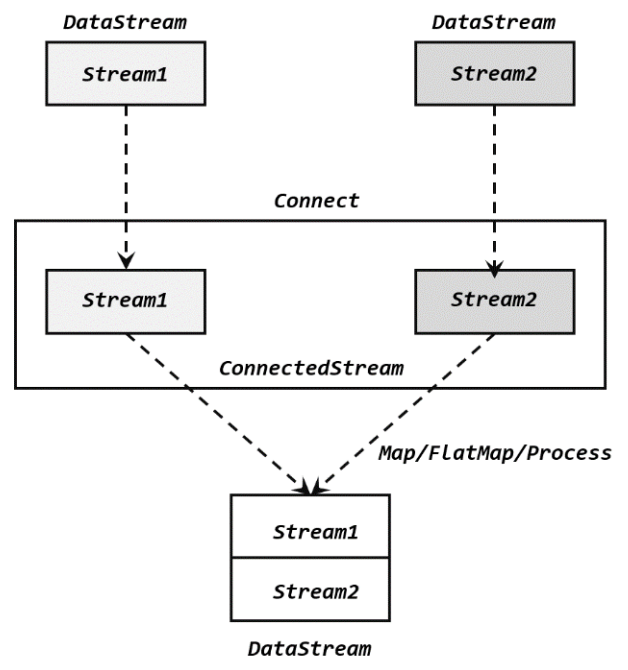 :
: - join:基于时间的合流,参考资料 Flink详述双流 Join 3 种解决方案 + 2 种优化方案_flink双流join数据延迟-CSDN博客
- window join:先进行join,再进行窗口统计

- window coGroup:相当于window join只能内连接,coGroup可以内连接外连接
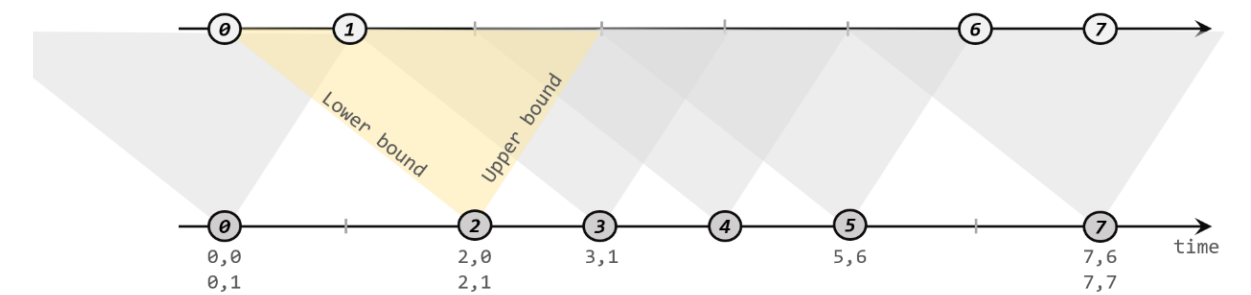
- internel join:间隔join,根据一个元素,取它上限和下限的范围,在另一个流中找这个范围内匹配的数据。
 ::
::
- window join:先进行join,再进行窗口统计
六.状态和容错机制
状态:
- 在流处理中,数据是连续不断到来和处理的。每个任务进行计算处理时,可以基于当前数据直接转换得到输出结果;也可以依赖一些其他数据。这些由一个任务维护,并且用来计算输出结果的所有数据,就叫作这个任务的状态。状态有各种各样结构的数据类型,有的算子有状态有的算子没有状态。有状态:source,sink,sum等 无状态:map。
- 状态持久化(使用检查点):所有任务的状态在某个时间点的一个快照,一般将这个快照保存在分布式文件系统,如果出现故障进行恢复
- 状态后端:因为状态是分布式的,所以状态的存储,访问,维护都需要一个可拔插的组件决定,这个组件就叫做"状态后端"
- 主要做2件事:1.本地的状态管理(tm的内存/rocksDB); 2.将检查点写入到远程的持久化存储(hdfs)
容错机制:
- checkpoint:Flink周期性保存。在所有算子(任务)都恰好处理完一个相同的数据的时候,将它们的状态保存下来。(每个算子保存的的状态要一致,不能有的快有的慢)
- 恢复:当发生故障重启时,一般时找到最近一次成功保存的检查点来恢复状态
- 检查点算法:在保存状态的时候,还是会有新的数据进来,难道让其他算子都暂停,然后保存数据吗?为了解决这个问题,引入了检查点分界线(Barrier)
- Barrier:就相当于一个标识,其实就是jobmanager向taskmanager定时发送一个barrier(分界线),barrier中携带检查点id,随着数据向下游算子流去,source->map->sink。当barrier到达最后一个算子sink时,前面经过的算子都保存了状态,所有状态一致,开始保存状态。
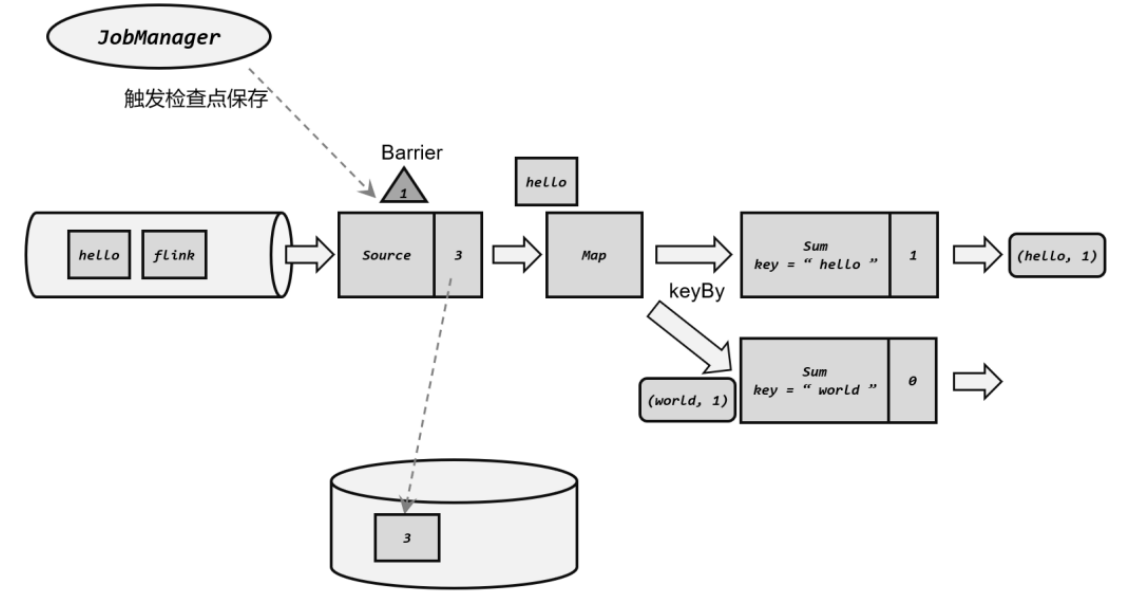
- 分布式Barrier:如果多个任务都在进行Barrier,有的快有的慢,怎么处理?那就在下游设置分界线对齐操作,需要等到所有并行分区 的 barrier 都到齐,才可以开始状态的保存。
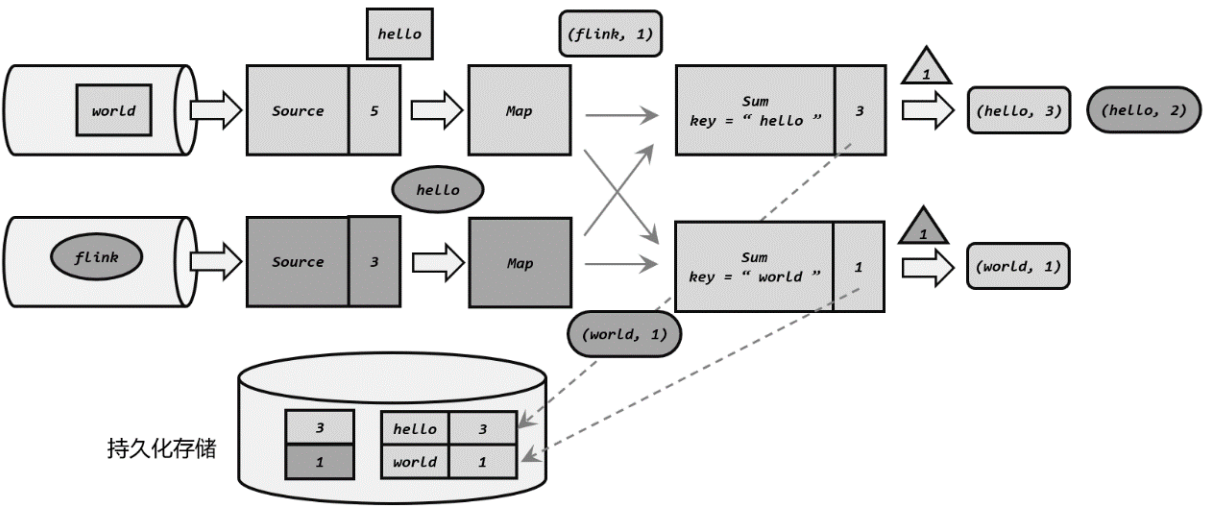
- Barrier:就相当于一个标识,其实就是jobmanager向taskmanager定时发送一个barrier(分界线),barrier中携带检查点id,随着数据向下游算子流去,source->map->sink。当barrier到达最后一个算子sink时,前面经过的算子都保存了状态,所有状态一致,开始保存状态。
- savepoint:就是我们手动触发一个状态的保存,再次启动时,指定这个状态。
- 触发保存点的方法:
- 单独保存:bin/flink savepoint :jobId [:targetDirectory]
- 停止时保存(推荐):bin/flink stop --savepointPath [:targetDirectory] :jobId
- 从保存点重启:bin/flink run -s :savepointPath [:runArgs]
- 触发保存点的方法:
状态一致性:
- 最多一次(at-most-once):发生故障,直接重启。之前的运行的状态不管
- 至少一次(at-least-once):保证之前状态不丢,再次重启延续之前状态,但是有可能有重复数据、
- 精确一次(exactly-once):数据不丢不重复
要想实现精确一次,就要求输入源支持数据重放,Flink支持数据状态保存恢复,输出源支持事务/幂等写入
经典例:Kafka作为输入端和输出端,Flink作为中间处理。如何保证精确一次:
- 输入端Kafka:支持状态重放,Flink Kafka connect保存Kafak消费点位,故障可以重新读取数据
- Flink:支持状态保存和恢复
- 输出端Kafka:保证事务(支持二阶段提交),Flink开启状态保存出现一个barrier,barrier到达sink算子开启一个事务。接下来所有barrier后的数据都会进入预提交阶段,当jobManager通知保存checkpoint的时候,才进入正式提交阶段。这样其实保证了kafka和flink同存一致的状态,恢复的时候肯定就不会有重复数据。
七.Flink SQL
CataLog:
- 提供元数据信息,例如库表信息等。是数据库之上的一层概念,相当于一个连接(目录)
- 类型:
- 基于内存:每一个任务运行都会建立一个defaule_catalog,这个是基于内存的,任务运行完就消亡
- jdbcCataLog:支持连接关系型数据库:MySQL和Postgres。不支持自己create表,只支持MySQL现有的表
- HiveCatalog:连接hive的metastore。俩个作用:1.作为Flink元数据持久化存储(只要是在这个catalog创建任何类型的表,都可以存储到这里) 2.作为读写hive数据的接口。

- 注意:
- create catalog这个语句是每次运行作业都需要定义,而真正create table,在hiveCatalog中是持久化保存,再次运行也会存在。
- 使用catalog中的表是三段式:catalog名.库名.表名
- 使用jdbc或者hiveCataLog只需要将jdbc-connect或者hive-connect的jar包放入flink 的lib目录下
自定义函数:一般继承xxFunction,重写eval()
- 标量函数(Scalar Functions):一对一,

-
表函数(Table Functions) :一对多
- 聚合函数(Aggregate Functions):多对一
- 表聚合函数(Table Aggregate Functions):多对多
八.提交流程

- 客户端底层就是YarnClusterDescriptor,部署perjob模式在客户端执行main,session和application不在客户端执行main
- perjob执行main主要是:执行用户main代码,执行execute()生成jobGroup
- ClusterEntryPoint:就是执行AM的入口类,application模式中会读取pipeline.jar,读取用户的代码
- 轻量化的改造是合并Flink1.16的sql-gateway,在启动session的时候启动sql_gateway。这样可以通过rest接口提交作业
- 对于Flink sql 的提交:其实就是sql_gateway通过系列转换,将sql转换成算子,TableEnvironmentImpl.executeSql()最终会生成Transformation(转换算子)->StreamGraph->jobGraph->xxx
- 对于DDL语句(create,show等)都是创建一个catelog,相当于存了一份表。
- 对于DML语句,都是一个作业,真正把输入源、输出源连接在一起执行的(比如insert和select语句)
- 对于Flink sql 的提交:其实就是sql_gateway通过系列转换,将sql转换成算子,TableEnvironmentImpl.executeSql()最终会生成Transformation(转换算子)->StreamGraph->jobGraph->xxx
k8s提交模式:
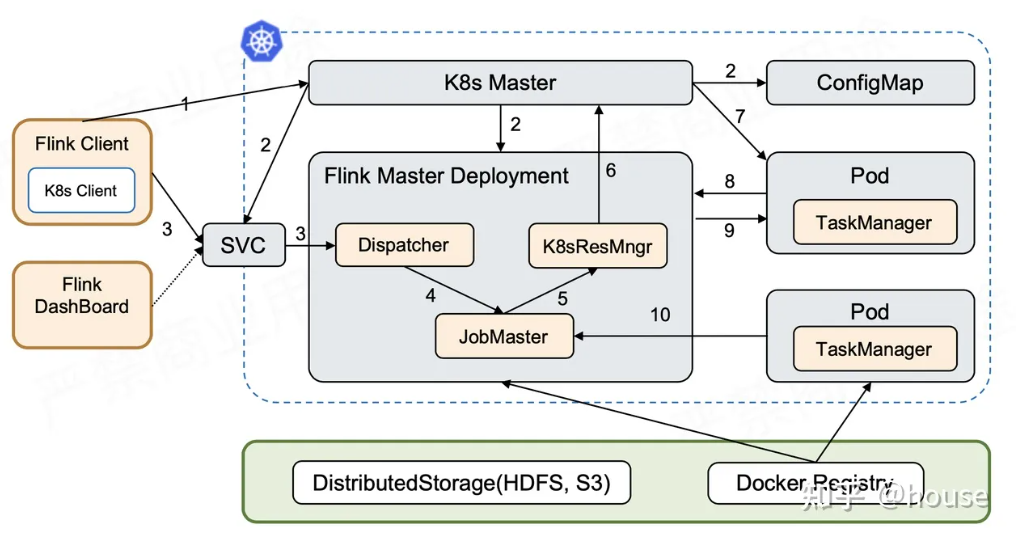
- 第一个阶段:启动 Session Cluster。Flink Client 内置了 K8s Client,告诉 K8s Master 创建 Flink Master Deployment,ConfigMap,SVC。这些k8s对象创建完成后,Master 就拉起来了。这时 Session 已经部署完成,因为是k8s navtive 模式并没有创建维护任何 TaskManager。
- 第二个阶段:当用户提交 Job 时,可以通过 Flink Client 或者 Dashboard 的方式,然后通过 Service 到 Dispatcher,Dispatcher 会产生一个 JobMaster。JobMaster 会向 K8sResourceManager 申请资源。ResourceManager 会发现现在没有任何可用的资源,它就会继续向 K8s 的 Master 去请求资源,请求资源之后将其发送回去,起新的 Taskmanager。Taskmanager 起来之后,再注册回来,此时的 ResourceManager 再向它去申请 slot 提供给 JobMaster,最后由 JobMaster 将相应的 Task 部署到 TaskManager 上。这样整个从 Session 的拉起到用户提交都完成了。
和yarn的主要区别:
- 存储:hdfs和pvc
- 调度:yarn的rm和k8s的master
- 配置文件:本地和ConfigMap
- 部署k8s资源主要通过:pod_template
九.Flink sql gateway
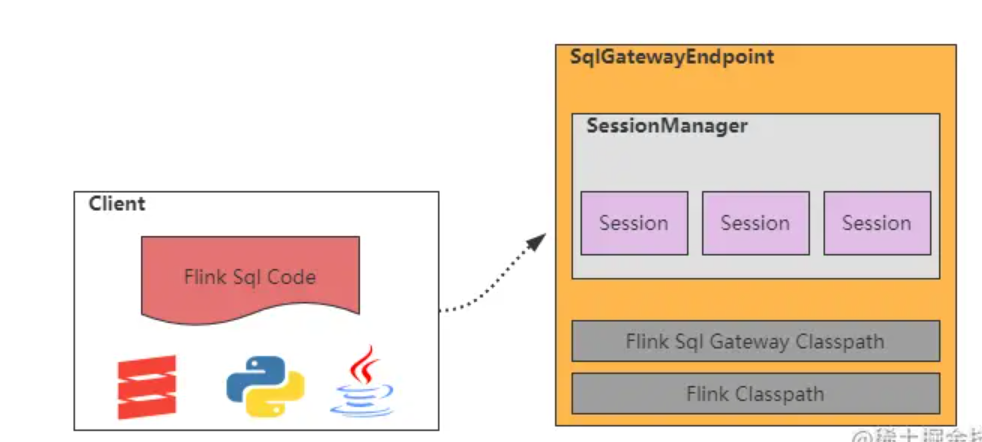
- SqlGatewayEndpoint:基于RestServerEndpoint实现的Netty服务,对外提供Rest Api
- SessionManager :会话管理器,管理session创建与删除;
- Session:一个会话,里面存放着任务所需要的Flink配置和上下文环境信息,负责任务的执行;
- Classpath:Flink Sql Gateway启动时会加载flink安装目录的classpath,所以flink sql gateway 基本上没有除flink以外的相关依赖。
flink sql转变为算子:
TableEnvironmentImpl.executeSql()最终会生成Transformation(转换算子)->StreamGraph->jobGraph
- 对于DDL语句(create,show等)都是创建一个catelog,相当于存了一份表。
- 对于DML语句,都是一个作业,真正把输入源、输出源连接在一起执行的(比如insert和select语句)
十.内存模型

- JVM管理内存,在大数据场景下有很多问题,Flink就用上面模型自主管理内存。
- 比如对象存储密度低(本来boolean需要1byte,为了对其用了8byte);经常GC时间长;OOM影响整个程序等
- Flink将内存划分多个内存段(MemorySegment),每个内存段大约32KB。自动提供对二进制的读写,不用序列化
十一.反压
- 原因:每一个任务(算子),都有一个输入缓存区(RP),输出缓存区(IG)。当缓存区的数据来不及消费时,就会堆积,造成上游缓存区也堆积,最后没有新数据流入
- Credit-based反压机制:就是每次taskManager之间传递数据,每传递一个,都有个响应,告诉当前缓存区还能存多少数据,当缓存区数据满了,就不会再发送新数据
- 分析手段:Flink web ui
- 反压造成后果:
- checkpoint保存失败,比如超过保存时间
- 影响state变大,barrier到达快的,会放入缓存区,等待到达慢的barrier,就会把缓存区所有数据都存,导致state变大
- 解决方案:
- 是否数据倾斜:就是有某个算子,计算压力太大,数据都阻塞到那里。
- 数据量大,没有设置并发度,比如读取kafka的source算子
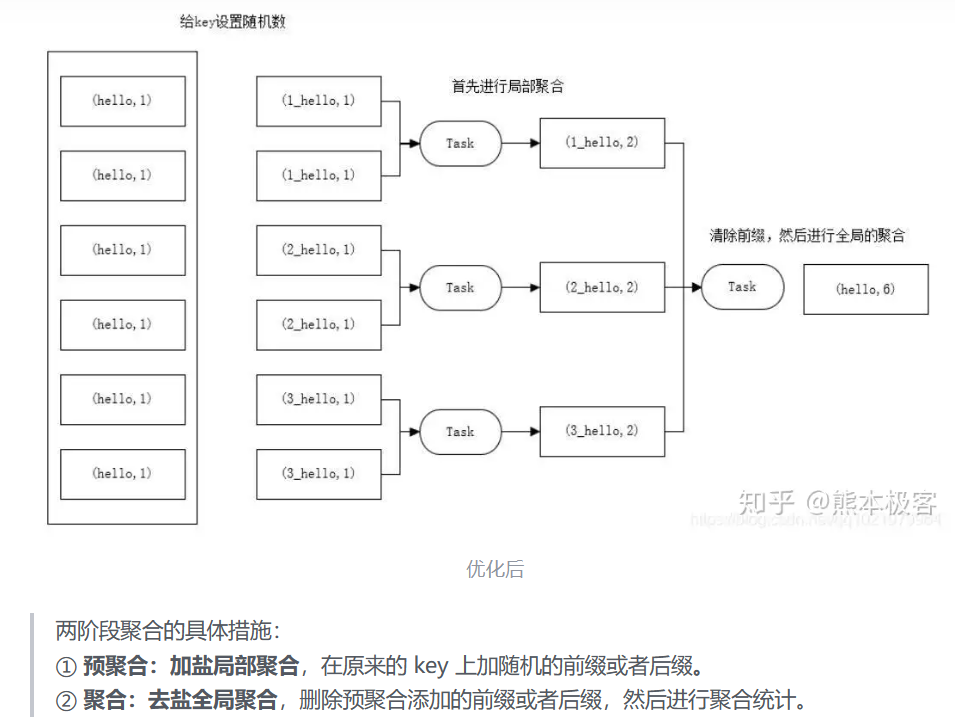
- key分布不均匀,无统计,这样可以在key前缀加上随机数,确保数据不会分布到某一个任务中
- key分布不均匀,需要统计,预聚合+聚合。
- 资源是否满足
- GC是否影响
- 外部数据源读取是不太慢
- 是否数据倾斜:就是有某个算子,计算压力太大,数据都阻塞到那里。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号