HDFS
一.概述
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
二.架构
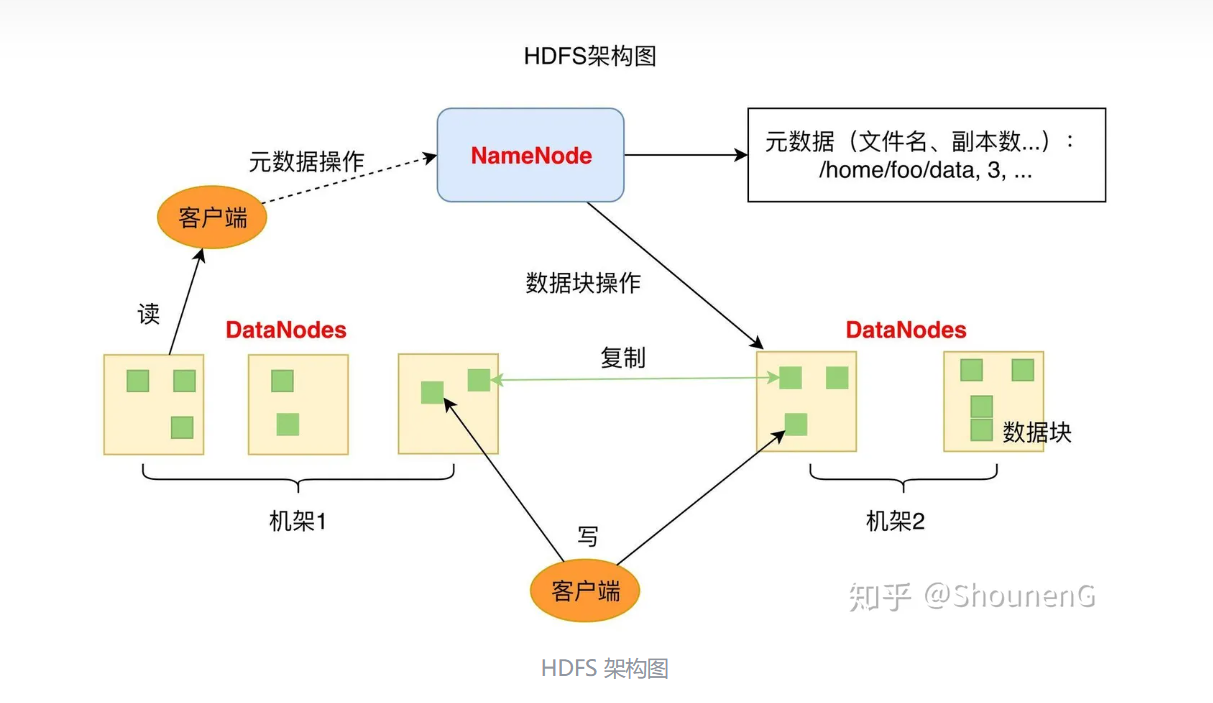
- 客户端:提供一些命令来管理HDFS文件,将文件切分成一个一个Block,然后上传
- NameNode:存储文件元数据,如文件名,文件目录结构,文件属性,每一个文件的块列表和块所在的DataNode等
- DataNode:真正存储文件块数据
- Secondary NameNode(2NN):每隔一段时间对NameNode元数据进行备份
三.Hdfs读写流程
写流程:
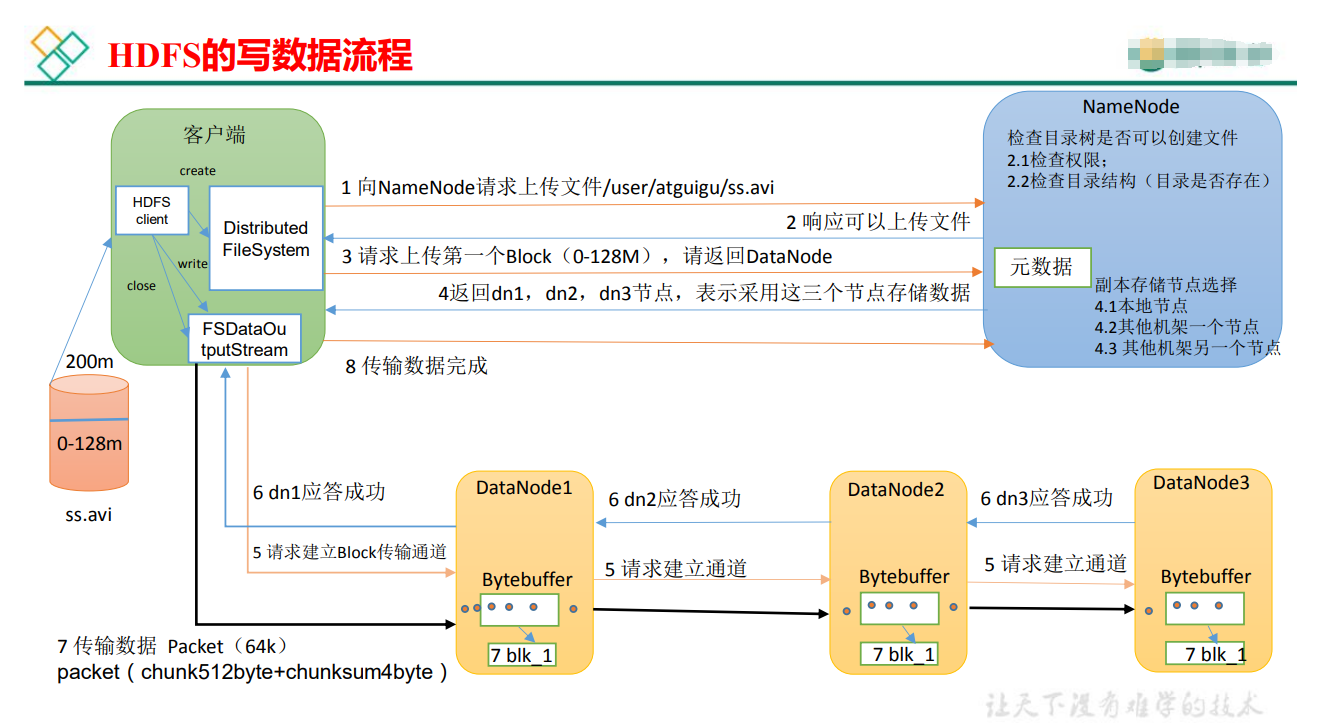
- Packet是基本传输单位,每一个DataNode会存放一个块(因为有副本)
- HDFS 写入流程时候,某台 dataNode 挂掉如何运行?
- 当 DataNode 突然挂掉了,客户端接收不到这个 DataNode 发送的 ack 确认,客户端会通 知 NameNode,NameNode 检查并确认该块的副本与规定的不符,NameNode 会通知闲置的 DataNode 去复制副本,并将挂掉的 DataNode 作下线处理。等挂掉的 DataNode 节点恢复后, 删除该节点中曾经拷贝的不完整副本数据。
读流程:
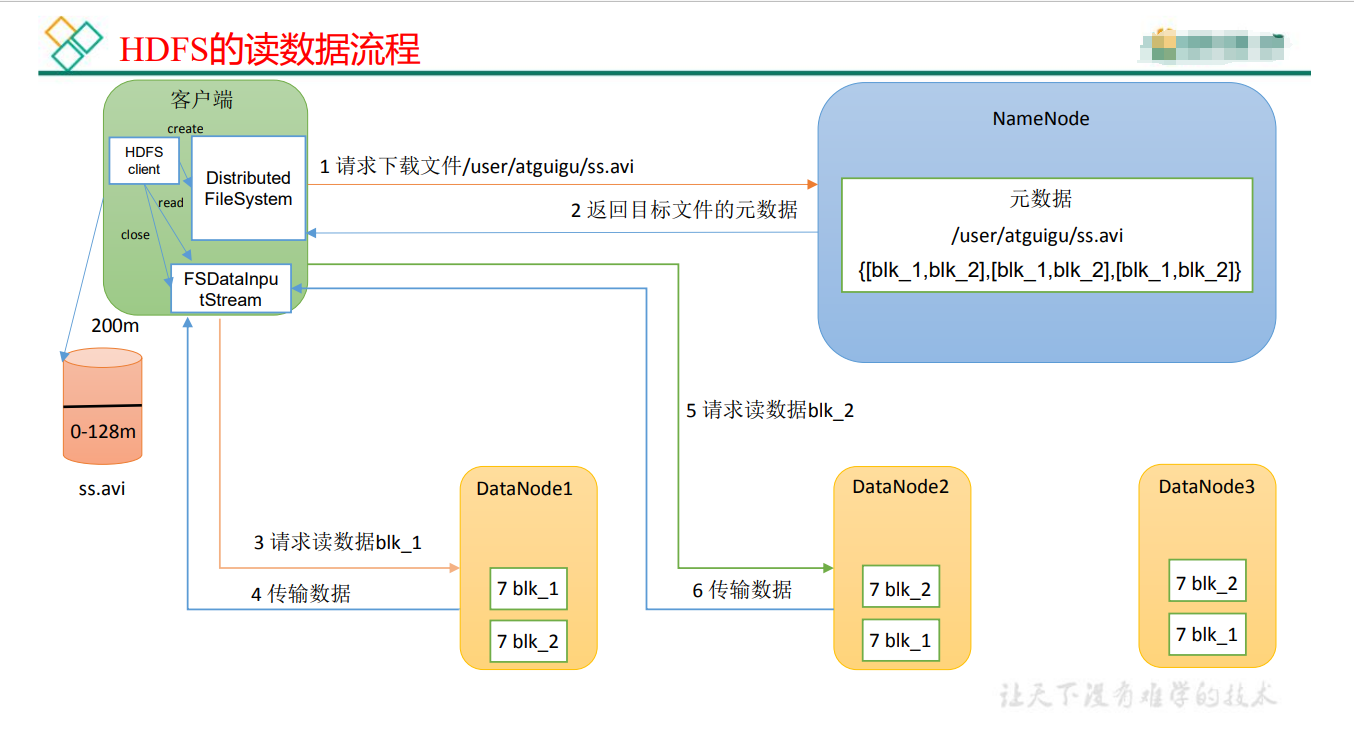
四.其他
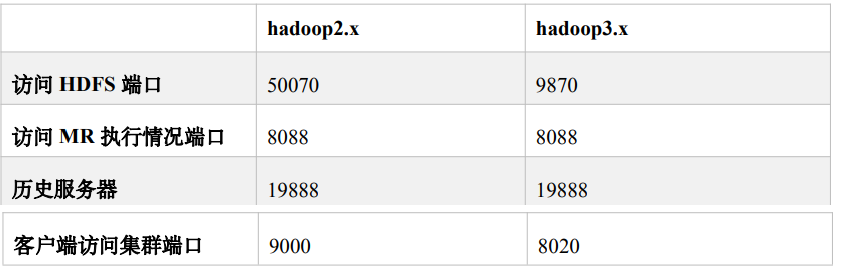
hdfs常用端口号:
块大小:
- 默认大小在Hadoop2.x/3.x版本中是128M,1.x版本中是64M。
- 可以通过:dfs.blocksize 设置
- 为什么块的大小不能设置太小,也不能设置太大?
- 太大:增加传输时间,比如一块为1T,那么传输1T需要的时间很长
- 太小:增加寻址时间,比如一个文件分成100快,要找到100快才能拼成文件
- HDFS块的大小设置主要取决于磁盘传输速率
NN 和 2NN工作机制 待补充
DataNode工作机制 待补充

 浙公网安备 33010602011771号
浙公网安备 33010602011771号