
NFA解决正则匹配
2021-11-10周三下午面试,遇到一道题挺有意思,哪家不能说 反正是个外企。
给你一个字符串 str 和一个字符规则 reg,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
"."表示匹配任意单个字符
"*"表示匹配零个或多个前面的那一个元素
当时我表示这应该用不确定自动机来做,但是我短时间写不出来。
就给他们画了一个状态图
类似这种
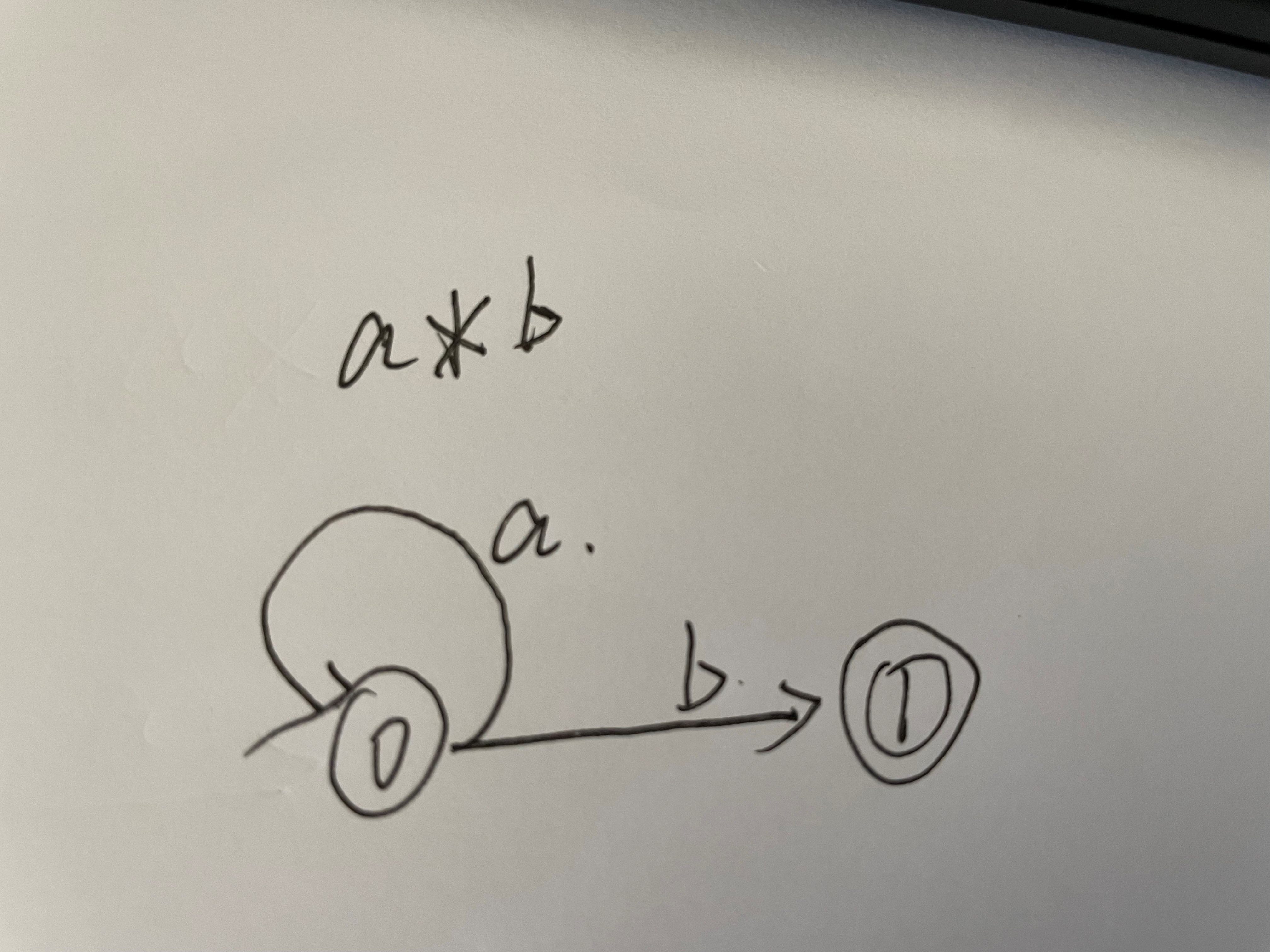
这种图比较好理解但是 程序实现比较麻烦,然后我就去翻了一下编译原理。
应该添加epsilon 程序才容易 实现
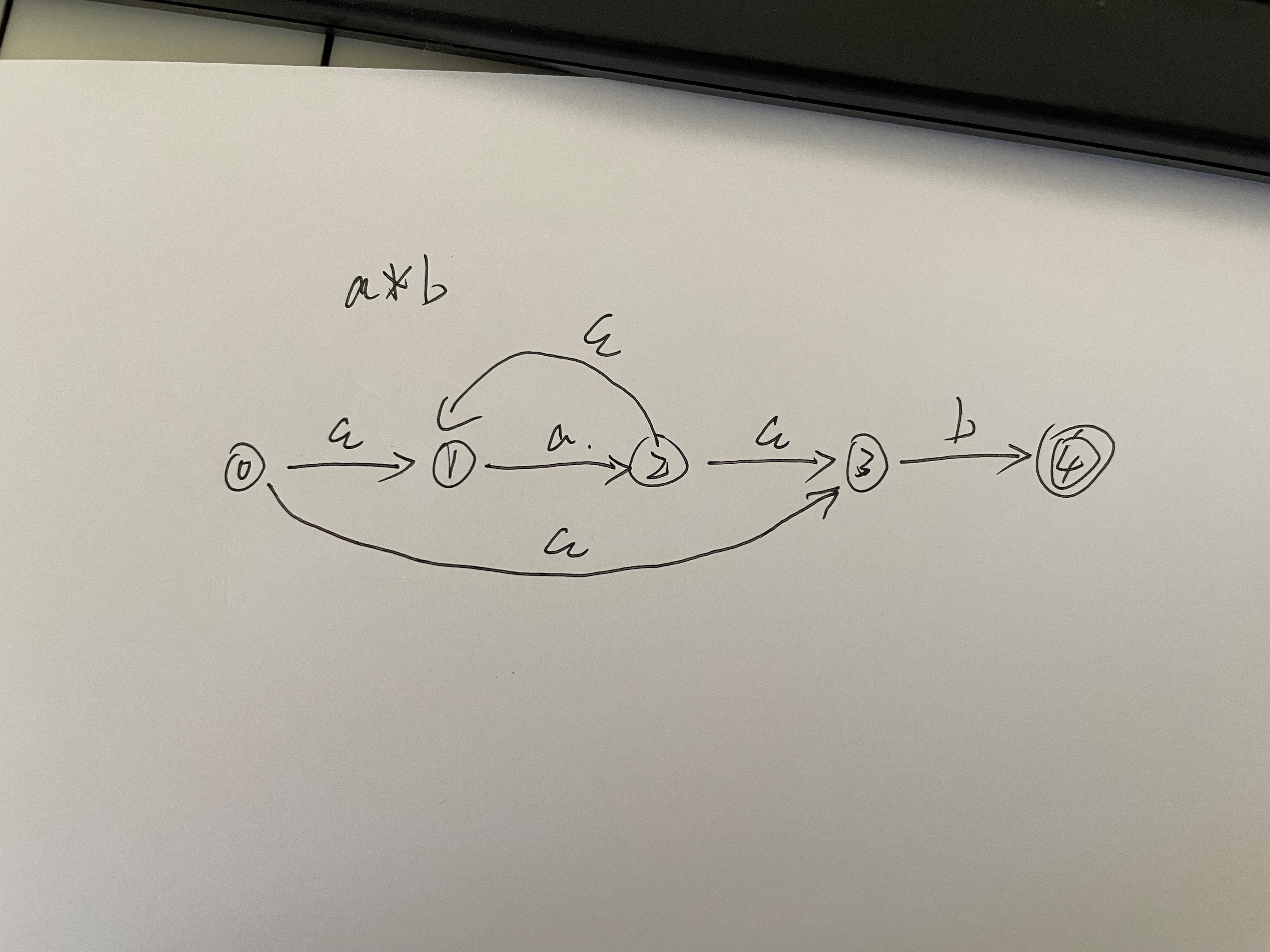
好那么说一下怎么构造NFA
先定义节点
public class Node { public bool IsEnd { get; set; } public Dictionary<char, List<Node>> Transform { get; set; } public Node() { Transform = new Dictionary<char, List<Node>>(); } }
public class NFA { private char epsilon = (char)1; private char dot = '.'; }
Transform 表示图上面的箭头连接到的节点,对应的key表示字母
构造最难的地方在于类似a*的构造,可以参考上面的图片
public Node CreateNFA(string reg) { Node n = new Node(); Node current = n; int index = 0; while (index < reg.Length) { Node next = new Node(); //类似a*实现 if (index + 1 < reg.Length && reg[index + 1] == '*') { Node n1 = new Node(); Node n2 = new Node(); //对应上图0节点到1节点,0节点到3节点 current.Transform.Add(epsilon, new List<Node>() { n1, next }); //对应上图1节点到2节点 n1.Transform.Add(reg[index], new List<Node>() { n2 }); //2节点到3节点,对应上图2节点到1节点 n2.Transform.Add(epsilon, new List<Node>() { next, n1 }); index += 2; } else { current.Transform.Add(reg[index], new List<Node>() { next }); index++; } current = next; } current.IsEnd = true; return n; }
接下来是验证的部分,简单说就是从左往右扫字符串,然后根据NFA状态机来匹配,主要特殊处理一下"."和epsilon
public bool isMatch(string str, int currentIndex, Node n) { //终结判断 if (currentIndex == str.Length) { return IsEnd(n); } //单个字符匹配 if (n.Transform.ContainsKey(str[currentIndex])) { foreach (var item in n.Transform[str[currentIndex]]) { if (isMatch(str, currentIndex + 1, item)) { return true; } } } //匹配 . if (n.Transform.ContainsKey(dot)) { foreach (var item in n.Transform[dot]) { if (isMatch(str, currentIndex + 1, item)) { return true; } } } //处理epsilon跳转,不消耗字符 if (n.Transform.ContainsKey(epsilon)) { foreach (var item in n.Transform[epsilon]) { if (isMatch(str, currentIndex, item)) { return true; } } } return false; } /// <summary> /// 分两种 已经到末尾了和通过epsilon到末尾 /// </summary> /// <returns></returns> private bool IsEnd(Node n) { if (n.IsEnd) { return true; }else { if (n.Transform.ContainsKey(epsilon)) { foreach (var item in n.Transform[epsilon]) { return IsEnd(item); } } } return false; }
后面简单加了个单元测试
[Test] public void Test1() { NFA nfa = new NFA(); var nfaNode=nfa.CreateNFA("ab*c"); var result=nfa.isMatch("abbbbbc", 0, nfaNode); Assert.AreEqual(true,result); } [Test] public void Test2() { NFA nfa = new NFA(); var nfaNode = nfa.CreateNFA("ab*c."); var result = nfa.isMatch("abbbbbce", 0, nfaNode); Assert.AreEqual(true, result); } [Test] public void Test3() { NFA nfa = new NFA(); var nfaNode = nfa.CreateNFA("ab*c"); var result = nfa.isMatch("ac", 0, nfaNode); Assert.AreEqual(true, result); } [Test] public void Test4() { NFA nfa = new NFA(); var nfaNode = nfa.CreateNFA("ab*c"); var result = nfa.isMatch("ad", 0, nfaNode); Assert.AreEqual(false, result); }
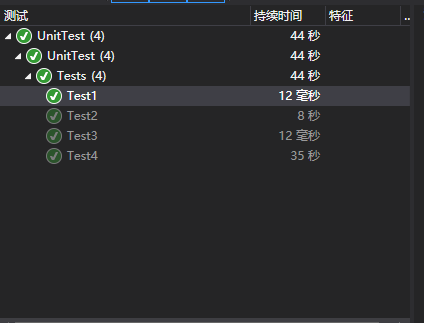
下面把完整的代码 附上来


public class NFA { private char epsilon = (char)1; private char dot = '.'; public Node CreateNFA(string reg) { Node n = new Node(); Node current = n; int index = 0; while (index < reg.Length) { Node next = new Node(); //类似a*实现 if (index + 1 < reg.Length && reg[index + 1] == '*') { Node n1 = new Node(); Node n2 = new Node(); //对应上图0节点到1节点,0节点到3节点 current.Transform.Add(epsilon, new List<Node>() { n1, next }); //对应上图1节点到2节点 n1.Transform.Add(reg[index], new List<Node>() { n2 }); //2节点到3节点,对应上图2节点到1节点 n2.Transform.Add(epsilon, new List<Node>() { next, n1 }); index += 2; } else { current.Transform.Add(reg[index], new List<Node>() { next }); index++; } current = next; } current.IsEnd = true; return n; } public bool isMatch(string str, int currentIndex, Node n) { //终结判断 if (currentIndex == str.Length) { return IsEnd(n); } //单个字符匹配 if (n.Transform.ContainsKey(str[currentIndex])) { foreach (var item in n.Transform[str[currentIndex]]) { if (isMatch(str, currentIndex + 1, item)) { return true; } } } //匹配 . if (n.Transform.ContainsKey(dot)) { foreach (var item in n.Transform[dot]) { if (isMatch(str, currentIndex + 1, item)) { return true; } } } //处理epsilon跳转,不消耗字符 if (n.Transform.ContainsKey(epsilon)) { foreach (var item in n.Transform[epsilon]) { if (isMatch(str, currentIndex, item)) { return true; } } } return false; } /// <summary> /// 分两种 已经到末尾了和通过epsilon到末尾 /// </summary> /// <returns></returns> private bool IsEnd(Node n) { if (n.IsEnd) { return true; }else { if (n.Transform.ContainsKey(epsilon)) { foreach (var item in n.Transform[epsilon]) { return IsEnd(item); } } } return false; } } public class Node { public bool IsEnd { get; set; } public Dictionary<char, List<Node>> Transform { get; set; } public Node() { Transform = new Dictionary<char, List<Node>>(); } }
总结一下,NFA其实效率不高,如果要优化的话,可以用MYT算法转化成DFA,最小DFA怎么求,emm留给后面吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号