栈和队列
栈与队列:
栈和队列主要用于在计算过程中保存临时数据,这些数据是计算中发现或者产生的,在后面的计算中可能需要使用它们。栈和 队列也是最简单的缓存结构,他们只支持数据项的存储和访问,不支持数据项之间的任何关系,
栈和 队列的使用顺序:
栈:栈是保证元素后进先出关系的结构,简称为LIFO结构。
根据数据生成的顺序 ,较后生成并保存的数据需要先行使用和处理,例如一摞碗,可以把新的碗摞上去,而取一个时,总是取得最后放上去的碗。
队列:队列是保证先进先出关系的结构。简称为FIFO结构。
按先后顺序处理,先生成的数据先处理,例如到银行办理业务,先到者先得到服务,具体等待方式并不重要,常见的如直接排入一个等待队列,或者拿号后等候叫号,每次得到服务的总是此前尚未得到服务的最早来的顾客。
对于一个栈或队列,在任何时候,下一次访问或者删除的元素都默认的唯一确定了,只有新的存入或者删除操作才会改变下一次默认访问的元素,从元素操作的层面看,栈和队列的性质完全是抽象和逻辑的,对于如何实现着这种关系没有任何约束,任何满足要求的技术均可使用。
栈和队列应用环境 :
栈和队列是计算中使用最广泛的缓存结构,其使用环境可以总结如下:
1.计算过程分为一些顺序进行的步骤
2.计算中执行的某些步骤会不断产生一些后面可能需要的中间数据
3.生产的数据中有些不能立即使用,但又需要 在将来使用
4.需要保存的数据的项数不能事先(在编程序的时候)确定
在这种情况下,通常需要用一个栈或者队列作为 缓存结构。
栈的概念与实现:
概念:栈(stack)是一种容器,可存入数据元素、访问元素、删除元素等,存入栈中的元素之间相互没有任何具体关系,只有到来的时间先后顺序,
实现:如图所示,执行插入和删除操作的端被称为栈顶,另一端成为栈底,访问和弹出的都应该是栈顶元素

用线性表的技术实现栈时,操作只在表的一端进行,不涉及另一端,更不涉及表的中间部分,由于着种情况,自然应该选择实现最方便而且保证两个主要操作效率最高的那一端作为栈顶。
1.对于线性表,后端插入和删除时O(1)操作,应该用这一端作为栈顶(采用顺序表实现,如图所示,用表尾作为栈顶)


2.对于链接表,前端插入和删除都是O(1),应该用这端作为栈顶。
在实际中,栈和队列都是用着两种技术实现。
栈的顺序表实现:
class StackUnderflow(ValueError): pass class SStack(): def __init__(self): self._elem = [] def is_empty(self): return self._elem == [] def top(self): if self._elem == []: raise StackUnderflow("in SStack.top()") return self._elem[-1] def push(self, elem): self._elem.append(elem) def pop(self): if self._elem == []: raise StackUnderflow("in SStack.pop()") return self._elem.pop() if __name__ == "__mian__": st1 = SStack() st1.push(2) st1.push(3) while not st1.is_empty(): print(st1.pop())
栈的链接表实现:
class LStack(): def __init__(self): self._top = None def is_empty(self): return self._top is None def top(self): if self._top is None: raise StackUnderflow("in LStack.top()") return self._top.elem def push(self, elem): self._top = LNode(elem, self._top) def pop(self): if self._top is None: raise StackUnderflow("in LStack.pop()") p = self._top self._top = p.next return p.elem
栈的应用:括号匹配问题,背包问题,。。。
队列的概念与实现:
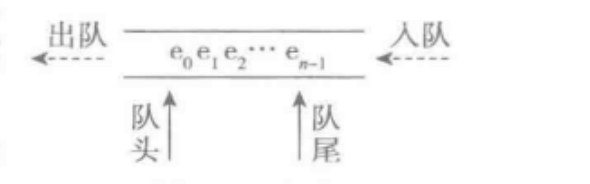
队列(queue),或称为队,也是一种容器,可存入元素,访问元素,删除元素。队列中也没有位置的概念,只支持默认方式的元素存入和取出,其特点就是保证在任何时刻可访问或删除的元素,都是再此之前最早存入队列而至今为删除的那个元素,因此队列时先进先出结构。队列的基本操作也是一个封闭集合,通常包括:创建新队列对象、判断队列是否为空(is_empty)、将一个元素放入队列中(入队,dequeue)、从队列中删除一个元素并返回它(出队,dequeue),查看当前元素(peek)。队列如图所示:
队列的链接表实现:
最简单的单链表只支持首端高效操作,在另一端操作需要O(n)时间,不适合作为队列实现基础。带表尾端指针的单链表,它支持O(1)时间的尾端插入操作,在加上表首端的高效访问和删除,基于单链表实现队列的技术已经很清奇了,如图:
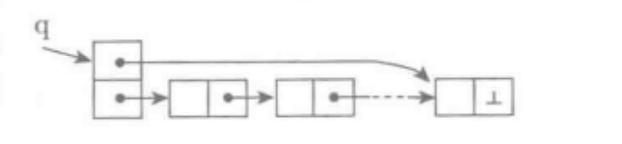
有了尾端指针,尾端加入元素是O(1)时间操作,可以用作队列的入队操作enqueue,首端访问和删除都是O(1)时间操作,分别看作队列的peek和dequeue,可见,单链表的技术和实现可hi直接用于队列,只需要修改几个重要的操作的名字,把append()改为enqueue,pop改为dequeue,将top改为peek,他们都是O(1)时间操作。
队列顺序表的实现:
基于顺序表实现队列的困难:如果入队在表的尾端进行,那么出队操作应该在表的首端进行,为了维护顺序表的完整性,出队操作取出当前首元素后,就需要把表中其余元素全部前移,这样将得到一个O(n)时间操作,python里list对象的pop(0)操作就是这样。反过来实现的情况 与此类似,从尾端弹出元素是O(1)时间操作,但是从首端插入就是O(n)时间操作,两种设计都无法排除O(n)操作,因此都不理想。
解决方案:循环顺序表-->把一定大小的顺序表看作一种环形结构,认为其最后存储位置之后是最前的位置,形成一个环,队列元素保存在这种结构中的一段连续位置里。
队列的list实现:
class QueueUnderflow(ValueError): pass class SQueue(): def __init__(self, init_len): self._len = init_len # 存储区长度 self._elems = [0]*init_len # 元素存储 self._head = 0 # 表头元素下标 self._num = 0 # 元素个数 def is_empty(self): return self._num == 0 def peek(self): if self._num == 0: raise QueueUnderflow("...") return self._elems[self._head] def dequeue(self): if self._num == 0: raise QueueUnderflow("--") e = self._elems[self._head] self._head = (self._head+1) % self._len self._num -= 1 return e def enqueue(self, e): if self._num == self._len: self.__extend() self._elems[(self._head + self._num) % self._len] = e self._num +=1 def __extend(self): old_len = self._len self._len *= 2 new_elems = [0]*self._len for i in range(old_len): new_elems[i] = self._elems[(self._head+i) % old_len] self._elems, self._head = new_elems, 0
队列的应用:文件打印、万维网服务器,如淘宝,抢票等、消息队列、离散时间系统模拟

 浙公网安备 33010602011771号
浙公网安备 33010602011771号