Python将HTML格式文件中字段提取到EXCEL表的方法
首先不需要关心HTML格式文件具体是什么内容(电子病历还是其他网页啥的),这篇主要内容是介绍如何用Python批量处理HTML格式文件、TXT格式文件,以及Python字典列表导出到EXCEL的一种解决方法。
我的原始数据是200+条HTML格式的入院记录
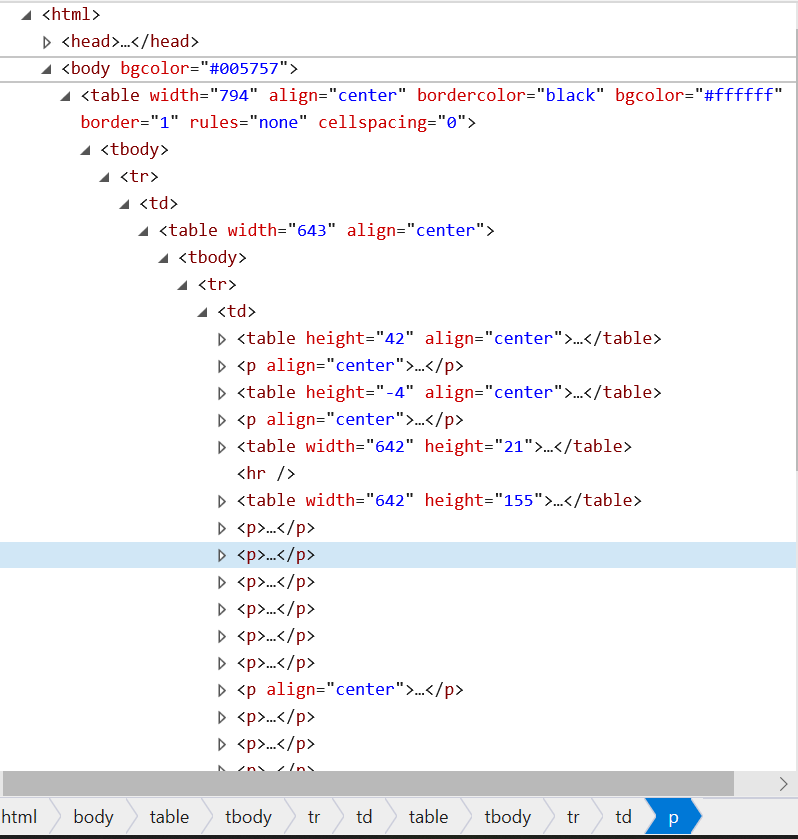
如上图所示,我关心的内容都在这些P标签里面
首先用BeautifulSoup包来处理HTML内容,提取到TXT文件如图所示
from bs4 import BeautifulSoup import re #创建BeautifulSoup对象 bs=BeautifulSoup(open('D:/rxa/1.html'),features='lxml') #获取所有文字内容 #print(soup.get_text()) #获取所有p标签的文字内容,写入TXT文件 for item in bs.find_all("p"): ptxt=re.sub('\s', ' ', item.get_text()) with open('d:/testvs/cutwords/test2.txt', 'a',encoding='utf-8') as f: f.write(ptxt+'\n')
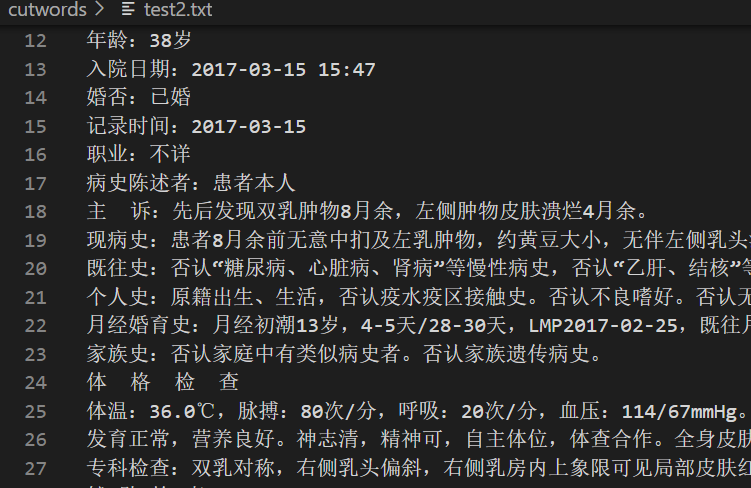
观察发现,这些属性都是由“:”分隔的,可以作为切分的依据。我想到在C#里面,我会定义一个类,比如“病人类”,然后“年龄、入院日期、婚否......”这些都可以作为类的属性传入,然后每次实例化一个病人对象就把这些保存下来,通过“.”访问,Python里面不用这么麻烦,因为Python自己就有字典这样一个高级的数据结构,这种键值对的形式不恰好适合存放这种数据么。于是我想到将这些先存入字典以冒号切分,前面作为“key”,后面作为“value”。
#重要字段存入字典 dic={} k=[] f=False for item in bs.find_all("p"): ptxt=re.sub('\s', ' ', item.get_text()) if f: dic['体格检查']=ptxt k.append('体格检查') f=False if re.search(':',ptxt): v=ptxt.split(':') dic[v[0]] = v[1] k.append(v[0]) if re.search(':',ptxt): if re.search('体温',ptxt): s=ptxt.split(',') v=s[0].split(':') dic[v[0]] = v[1] k.append(v[0]) v=s[1].split(':') dic[v[0]] = v[1] k.append(v[0]) v=s[2].split(':') dic[v[0]] = v[1] k.append(v[0]) v=s[3].split(':') dic[v[0]] = v[1] k.append(v[0]) f=True else: v=ptxt.split(':') dic[v[0]] = v[1] k.append(v[0])
为什么写得这么麻烦,还有这么多判断分支,因为我这个数据不太规范,既有中文冒号,又有英文冒号,而且正则表达式re.search是不是只能匹配第一个来着,体温那一行就不好处理,还有其他的一些问题,要结合自己数据情况分析。至于这里有个变量f,我要解释一下,在for循环遍历时,我不知道怎么取当前item的下一个item,没有指针,没有next(怪我自己学艺不精)迭代器???反正不会写,于是我想到了以前学C语言,有一个flag标志位,来调整程序跳转啥的,还自以为是臭不要脸觉得自己有点点机智哈哈。
以上都是单个文件的处理,下面介绍文件夹文件批量处理
我觉得计算机批量处理才是它被发明的义意啊,对于这种重复的工作,比人工做得又快又好,还不会烦躁乱发脾气
import os.path import re def eachFile(filepath): pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List temp=1 for s in pathDir: newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面 if os.path.isfile(newDir) : #如果是文件 if os.path.splitext(newDir)[1]==".html": #判断是否是html bs=BeautifulSoup(open(newDir),features='lxml') #获取所有p标签的文字内容 for item in bs.find_all("p"): ptxt=re.sub('\s', ' ', item.get_text()) savepath = os.path.join("D:\\t",str(temp)) with open(savepath+'.txt', 'a',encoding='utf-8') as f: f.write(ptxt+'\n') temp+=1 else: eachFile(filepath) #如果不是文件,递归这个文件夹的路径 rootdir = 'D:\\rxadata' eachFile(rootdir) print('提取完成')
也就是会多一层循环,这里一定要注意路径问题,我开始就是犯了点错,9000+条TXT文件都铺到了D盘,差点当场去世。。。
提取的字典,存入一个列表,然后借助xlwt包来导入到excel里面,下面是完整代码(能用,但是写得灰常烂我自己知道)
import re import os.path import xlwt import pandas as pd def eachFile(filepath): Info=[] pathDir = os.listdir(filepath) #获取当前路径下的文件名,返回List for s in pathDir: newDir=os.path.join(filepath,s) #将文件命加入到当前文件路径后面 if os.path.isfile(newDir) : if os.path.splitext(newDir)[1]==".txt": dic={} k=[] f=open(newDir,'r',encoding='utf-8') for s in f.readlines(): s=s.strip() if re.search(':',s): v=s.split(':') if v[0]!='体温': dic[v[0]] = v[1] k.append(v[0]) else: dic['TPRBP']=s elif re.search(':',s): v=s.split(':') dic[v[0]] = v[1] k.append(v[0]) elif re.search('T',s): dic['TPRBP']=s f.close() if dic.get('出院诊断')==None: dic['出院诊断']='' if dic.get('确诊日期')==None: dic['确诊日期']='' if dic.get('辅 助 检 查')==None: dic['辅 助 检 查']='' Info.append(dic) else: break return Info def export_excel(export): #将字典列表转换为DataFrame pf = pd.DataFrame(list(export)) #指定生成的Excel表格名称 file_path = pd.ExcelWriter('D:\\info.xlsx') #替换空单元格 pf.fillna(' ',inplace = True) #输出 pf.to_excel(file_path,encoding = 'utf-8',index = False) #保存表格 file_path.save() rootdir = 'D:\\t' IF=eachFile(rootdir) export_excel(IF) print('完成')

提取完成了,我还发现在我这两百多份乳腺癌病历里竟然有一位男患者。。。可惜没有他的首次住院病历,我还挺好奇男患者“月经婚育史”要怎么描述的。(PS:电子病历是敏感的隐私数据,放截图恐怕不妥,不过这里都故意隐藏了病人个人信息及医院信息,只是分享知识用的,应该不违法吧)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号