Hive环境搭建和SparkSql整合
一、搭建准备环境
在搭建Hive和SparkSql进行整合之前,首先需要搭建完成HDFS和Spark相关环境
这里使用Hive和Spark进行整合的目的主要是:
1、使用
Hive对SparkSql中产生的表或者库的元数据进行管理(因为SparkSql没有提供相关的功能,官方提供的是和Hive的整合方案,官方之所以不在独立去开发一个元数据管理模块是为了防止重复造轮子),所以直接复用了Hive的元数据管理这一套内容2、单独使用
Hive的话速度太慢,所以在前期就打算切换到Spark作为计算引擎,然后使用了Spark的thriftserver向外提供JDBC相关的服务
环境准备:
hadoop版本:Hadoop-2.7.7
spark版本:Spark-2.4.0
相关安装包准备:
Mysql:mysql57-community-release-el7-11.noarch.rpm
Hive:apach-hive-1.2.2.tar.gz
Mysql驱动:mysql-connector-java-5.1.47-bin.jar
如上内容是安装Hive所需要的环境
这里说一下Hive官方所推荐的Hive On Spark安装方法,官方说需要编译一个不包含Hive依赖的纯净版本的Spark版本,但是使用这种方式编译出来的内容和Spark官方编译出来的包,缺少了一些依赖,主要是在组件上,比如K8s\docker\parquert等等所以不用这种方式;并且Hive官方的支持也很慢,从官方看,没有经过测试的版本和Spark2.4进行整合的稳定版本;Spark官方目前还是集成的Hive1.2.1版本的Hive,所以这里选择跟着Spark官方走

我们后面还是主要使用的是SparkSql作为主要的使用手段,只是借助了Hive作为元数据管理的角色,至于他的那些新特性,到后面Spark进行升级的时候再进行考虑
二、Mysql搭建
这里暂时就单节点进行部署,到后面可能会考虑主-主备份的方式保证元数据安全,现在数据很少就不进行考虑了!如果后面再进行搭建,直接加一个节点部署就完了
首先我目前的服务器上是没有安装mysql的,如果安装了mysql的需要自己注意,我先检查Mysql是否有其他版本内容,若果有卸载,其他环境的话需要注意,不要印象其他业务,这里Mysql可以部署在任何一台能访问的机器上
查看是否有多余的包
$ rpm -qa |grep -i mysql
删除不需要或者多余的包
$ yum remove mysql-community mysql-community-server mysql-community-libs mysql-community-common
删除Mysql安装生成的路径
$ whereis mysql

根据情况删除出现的路径
安装msyql
$ wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
$ yum -y install mysql57-community-release-el7-10.noarch.rpm
$ yum -y install mysql-community-server
$ systemctl start mysqld.service
$ systemctl status mysqld.service #查看是否启动
$ cat /var/log/mysqld.log | grep password #记住默认密码,等会还要进行修改
$ mysql -uroot -p #此时登录进去,需要重设密码
mysql > set global validate_password_policy='LOW'; #密码校验不区分大小写
mysql > set global validate_password_length=6; #校验时密码长度
mysql > ALTER USER USER() IDENTIFIED BY '123456'; #在Mysql新 5.7.6 版本设置密码使用
mysql > ALTER USER 'hive'@'%' IDENTIFIED BY '123456'; #设置密码,这里我还把root设置(当前设置老版本使用,新版本报错)
mysql > GRANT ALL ON *.* TO 'hive'@'%' IDENTIFIED BY '123456'; #赋权限
mysql > SELECT Host,User FROM user; #删除掉一些多余的用户和权限,防止权限影响

主要登录的是hive中所要使用的用户,查看在当前机器和在其他机器上是否都能进行登录和进行相关操作,如果一切正常,那么久可以进行Hive相关内容搭建,如上内容可以在root用户或者hadoop用户都行
三、Hive环境搭建
这里Hive只是作为元数据管理角色使用,或者在某些情况下也可以使用Hive进行操作,比如,HIve delete AND update(sparkSql中不能进行删除相关操作,但是Hive中也是需要进行配置才能开启的,因为HDFS中的数据是不能进行修改的,所以基本上不推荐使用,这里也就不进行开启,后面需要再开启)
下面搭建需要再hadoop用户进行搭建
$ tar -zxvf apache-hive-1.2.2-bin.tar.gz
$ mv apache-hive-1.2.2-bin hive-1.2.2
配置Hive环境变量
/etc/profile
export HIVE_HOME=/home/hadoop/hive-1.2.2
export PATH=$PATH:$HIVE_HOME/bin
$ source /etc/profile
~/hive-1.2.2/conf/hive.site.xml配置(在进行下面配置的时候,里面配置非常多,我将其删除了,然后只留下如下配置,相当于只是覆盖了下面内容)
$ cp ~/hive-1.2.2/conf/hive.default.template ~/hive-1.2.2/conf/hive.site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master1:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
<description>password to use against metastore database</description>
</property>
</configuration>
如上根据自己的Mysql地址进行配置相关地址、用户名、密码等信息
配置完成之后需要将改配置文件复制到spark/conf目录下,然后需要将mysql驱动分别复制到hive/lib和spark/jars目录下
上面内容设置完成之后需要进行
初始化元数据
$ schematool -dbType mysql -initSchema
数据初始换成之后会在Mysql中创建hive的库,并且在Hdfs中创建/tmp/hive和/user/hive/warehouse
这两个路径都是可以在hive.site.xml中进行设置的,配置完成之后进入hive终端
$ ./hive #在使用过程中需要开启yarn hdfs
hive > show databases;
hive > use default;
hive > show tables;
hive > create table spark_on_hive(id int,username String);
hive > insert into spark_on_hive values(1,'zhangsan');
hive > select * from spark_on_hive;
执行如上命令进行相关测试,看Hive是否能够进行正常工作
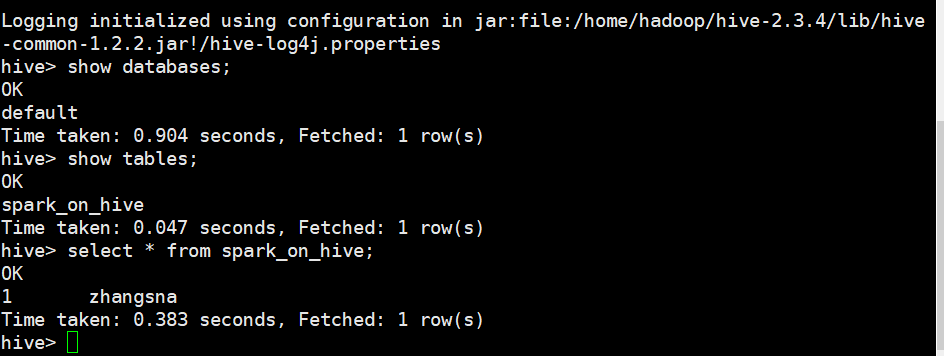
出现如上内容说明配置正确,下面和sparkSql进行相关整合
四、Hive和SparkSql进行整合
上面内容中已近将Mysql驱动和hive.site.xml拷贝到了Spark中,这个时候需要将Spark集群进行重启,重启完成之后,需要启动Spark的thriftserver服务
启动这个服务主要是通过这个服务进行监听JDBC的相关操作,默认端口为10000
$ ./spark-2.4.0/sbin/start-thriftserver.sh
启动完成之后可以通过Spark中自带的beeline服务来进行JDBC连接,连接到SparkSql
$ ./spark-2.4.0/bin/beeline
beeline > !connect jdbc:hive2://master1:10000/default
Enty Username : hadoop
Enty password : (空)
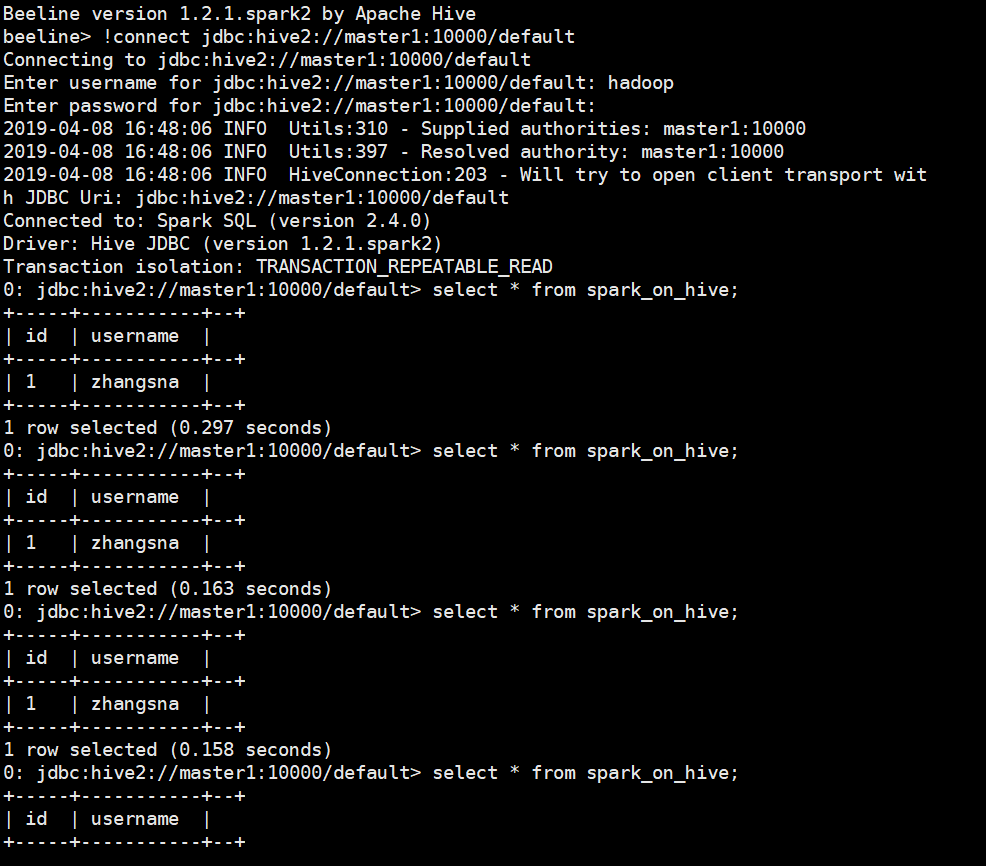
如上内容说明配置成功,在这里面能够查询出刚才通过hive终端创建的表和数据,同样的可以进行相关查询创建操作
beelin可以使用hive中的也可以使用spark中带的,都可以;
经过上面的测试说明jdbc也是能够进行访问SparkSql中的数据的,并且根据日志看出来所有的查询或者是创建操作走的都是Spark而不是MapReduce
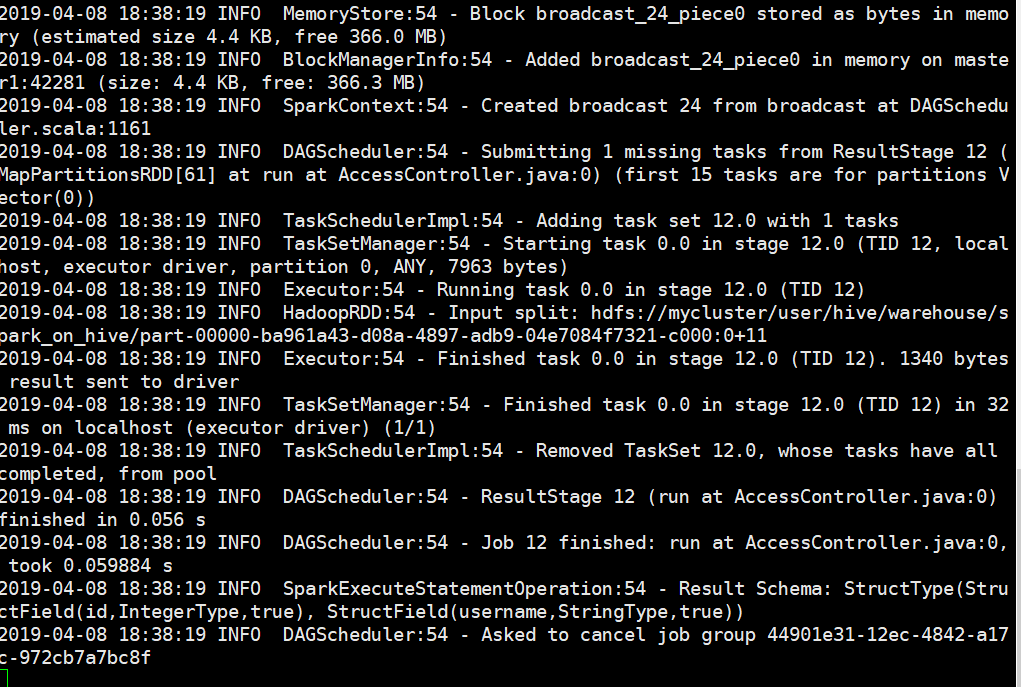
如上内容可以看出走的是Spark
五、代码验证
通过使用代码进行验证是否能够使用JDBC的方式来获取查询创建SparkSql中的数据和内容
创建一个Maven项目
pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.isoon.sparksql</groupId>
<artifactId>sparkjdbc</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<hive.version>1.2.1</hive.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>${hive.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>${hive.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
package com.demo;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
/**
* created by mojita on 2019/4/8
*/
public class SparkSqlDemo {
//使用jdbc进行对sparksql相关操作
public static void main(String[] args) {
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
//这里需要进行配置相关验证内容
Connection connection = DriverManager.getConnection("jdbc:hive2://192.168.8.236:10000/default","hadoop","");
ResultSet rs = connection.createStatement().executeQuery("select * from spark_on_hive");
while (rs.next()) {
System.out.printf("%d / %s\r\n", rs.getInt(1), rs.getString(2));
}
rs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
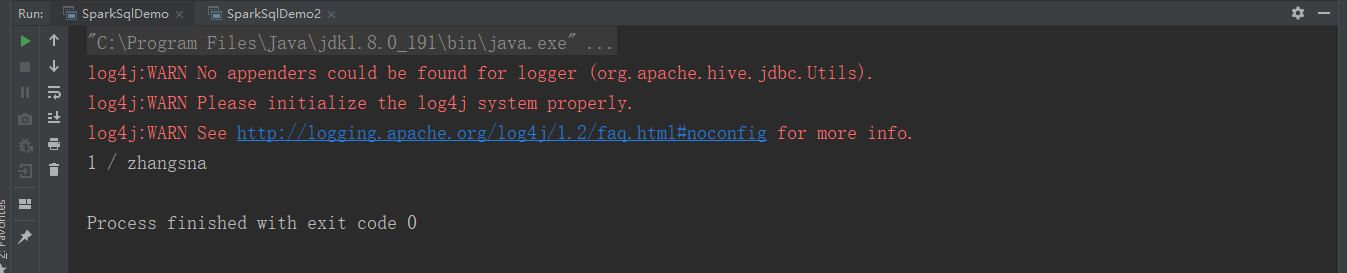
如上内容说明也是能够访问成功的
六、集群搭建总览和动态资源配置
上面内容部署完成之后,只有Master节点能够提供访问,下面再进行其他节点部署,使其也能够提供正常访问
1、将
Spark/conf目录下的hive-site.xml文件拷贝到需要提供访问的节点2、拷贝
mysql驱动到指定节点的spark/jars文件夹中3、需要开启
spark/sbin/start-thriftserver.sh服务
这里也只是多开启了一个客户端支持访问,并不是高可用的,Mysql同样也不是高可用的
整个部署的结构如下:
| 节点 | hive与spark整合 | hive | mySql | thriftServer服务 |
|---|---|---|---|---|
| 192.168.8.106 | * | * | * | * |
| 192.168.8.236 | * | * |
在启动thriftserver服务的时候可以设置JDBC提交Sql执行资源情况
sh $SPARK_HOME/sbin/start-thriftserver.sh \
--hiveconf hive.server2.thrift.port=10000 \
--master MASTER_URL \ //master的URL,如spark://host:port, mesos://host:port, yarn, 或local
--queue queue_name \ //如果使用yarn模式,设置队列名字
--num-executors NUM \ //executor的数目
--conf spark.driver.memory=40g \ //driver内存的大小
--driver-cores NUM \ //driver CPU数目,cluster模式才有这个参数
--executor-memory 6g \ //executor内存大小,如果开启动态分配,这个就不需要了
--conf spark.yarn.executor.memoryOverhead=2048 \ //overhead大小
如上内容为实例,想要获取更多关于./start-thriftserver.sh服务的参数可以使用如下命令./start-thriftserver.sh --help查看
使用上面内容进行提交的任务,一直会占用资源,下面进行提交和配置动态的资源分配,在任务执行完成之后根据策略回收Spark集群计算资源
设置任务动态资源提交,需要对spark配置文件进行修改spark/conf/spark-default.xml
配置Spark/conf/spark-default.xml
spark.shuffle.service.enabled true #默认值为false
spark.sql.warehouse.dir hdfs://mycluster/user/hive/warehouse
设置完成之后再每次提交任务的时候加入如下两个参数,这两个参数也可以在代码中直接指定
--conf spark.dynamicAllocation.enabled=true
--conf spark.shuffle.service.enabled=true
下面是一些策略配置(下面这些都是默认值)
spark/conf/spark-default.xml
spark.dynamicAllocation.executorIdleTimeout 60s #60秒没有任务请求删除executors
spark.dynamicAllocation.cachedExecutorIdleTimeout infinity #如果启用了动态分配并且具有高速缓存数据块的执行程序已空闲超过此持续时间,则将删除executors
spark.dynamicAllocation.initialExecutors spark.dynamicAllocation.minExecutors #启用动态分配时要运行的初始执行程序数 如果设置了`--num-executors`(或`spark.executor.instances`)并且大于此值,它将用作执行程序的初始数。
spark.dynamicAllocation.maxExecutors infinity #启用动态分配时执行程序数的上限。
spark.dynamicAllocation.minExecutors 0 #启用动态分配时执行程序数的下限。
spark.dynamicAllocation.executorAllocationRatio 1
spark.dynamicAllocation.schedulerBacklogTimeout 1s #如果启用了动态分配,并且已有挂起的任务积压超过此持续时间,则将请求新的executor。
spark.dynamicAllocation.sustainedSchedulerBacklogTimeout schedulerBacklogTimeout #与之相同spark.dynamicAllocation.schedulerBacklogTimeout,但仅用于后续执行程序请求。
#因为使用spark作为执行引擎,让sparksql知道仓库位置,配置默认仓库位置,如果代码中使用到别的仓库可以手动指定
spark.sql.warehouse.dir hdfs://mycluster/user/hive/warehouse
如上内容根据自己需求进行配置,目前使用的都是默认的参数,没有进行更多的修改
下面是启动thriftserver服务其实这个服务也是提交了一个application所以和执行spark-submit application是一样的
./start-thriftserver.sh \
--conf spark.dynamicAllocation.enabled=true \
--conf spark.shuffle.service.enabled=true \
--conf spark.driver.maxResultSize=10g \
--master spark://master1:7077 \
--driver-memory 10g \
--driver-cores 3 \
--executor-memory 6g \
--executor-cores 3 \
--total-executor-cores 220
下面只是一个示例,在连接的时候最好还是指定仓库地址
$ ./bin/beeline --hiveconf hive.server2.thrift.port=1000 --hiveconf "hive.metastore.warehouse.dir=hdfs://master1:9000/user/hive/warehouse"

 浙公网安备 33010602011771号
浙公网安备 33010602011771号