Hadoop 集群搭建和维护文档
一、前言 —— 基础环境准备
| 节点名称 | IP | NN | DN | JNN | ZKFC | ZK | RM | NM | Master | Worker |
|---|---|---|---|---|---|---|---|---|---|---|
| master1 | 192.168.8.106 | * | * | * | * | * | * | |||
| master2 | 192.168.8.236 | * | * | * | * | * | * | |||
| worker1 | 192.168.8.107 | * | * | * | * | * | ||||
| worker2 | 192.168.8.108 | * | * | * | ||||||
| worker3 | 192.168.8.109 | * | * | * | ||||||
| worker4 | 192.168.8.110 | * | * | * | ||||||
| worker5 | 192.168.8.111 | * | * | * | ||||||
| worker6 | 192.168.8.112 | * | * | * | ||||||
| worker7 | 192.168.8.113 | * | * | * |
集群规划情况如上图所示:
角色进程介绍:
1、
NN(NameNode):hadoop集群中元数据管理的中心,对元数据信息,资源存储信息等等内容进行管理(角色进程属于hadoop)2、
DN(DataNode):负责hadoop集群数据存储的角色进程(角色进程属于hadoop)3、
JNN(journalNode):在高可用中会使用到的角色进程,主要作用就是用来解决NameNode数据同步问题,因为两个NameNode之间是存在数据延迟的,当一个节点挂了之后,数据就会造成丢失,所以引入JournalNode集群进行管理(角色进程属于hadoop)4、
KFC(DFSZKFailoverController):hadoop中用来进行监控两个NameNode是否健康,同事监视Zookeep集群中的锁情况,当一个NameNode挂了之后,他会将另一个NameNode从standrBy置成active状态(角色进程属于hadoop)5、
ZK(QuorumPeerMain):该进程是ZOOKEEP进程(角色进程属于ZOOKEEP)6、
RM(ResourceManager):该进程主要负责的是集群间的资源管理和资源调度(角色进程属于yarn)7、
NM(NodeManager):对计算资源进行汇报和申请,主要为计算服务提供资源,所以该角色必须在DataNode所在的节点 (角色进程属于yarn)8、
Master:该进程是Spark中的进程,主要是对计算任务进行管理,负责资源相关内容,负责监控spark集群中的健康 (角色进程属于spark)9、
worker:该进程主要负责spark计算任务(角色进程属于spark)
系统环境 :centos7
所需安装包:
1、
hadoop-2.7.7.tar.gz
2、jdk-8u191-linux-x64.tar.gz
如上图的集群规划先将Hadoop相关的基础环境先进行搭建,在搭建之前需要首先完成的工作:
- 创建
hadoop用户和用户组 - 配置
jdk环境变量 - 配置
hadoop环境变量 - 修改
hadoop相关配置文件 - 进行修改相关
免密登录
$ useradd hadoop
$ passwd hadoop
$ su hadoop
$ tar -zxvf hadoop-2.7.7.tar.gz
$ tar -zxvf jdk-8u191-linux-x64.tar.gz
上面所有节点都需要创建hadoop用户和用户组、配置jdk环境变量
/etc/profile设置环境变量
$ vim /etc/profile
#设置环境变量
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
$ source /etc/profile
设置完成之后进行验证,是否设置成功
关闭所有节点防火墙并设置自启动关闭
$ systemctl stop firewalld.service
$ systemctl disable firewalld.service
修改主机名和IP映射
/etc/hosts
192.168.8.236 master2
192.168.8.106 master1
192.168.8.107 worker1
192.168.8.108 worker2
192.168.8.109 worker3
192.168.8.110 worker4
192.168.8.111 worker5
192.168.8.112 worker6
192.168.8.113 worker7
/etc/sysconf/network:分别在不同机器上修改不同的主机名,主机名一旦修改后面不需要再改变
hostname master1 #分别在不同机器上进行修改
$ systemctl restart network #重启网卡
在搭建的过程当中为了避免多种框架环境之间的影响造成不好验证的情况,尽量还是按照顺序进行搭建,并且在完成一步之后就需要进行相关验证,尽量避免多环境错误相互影响!
二、Zookeep 集群搭建
在高可用的环境搭建过程中将会使用到Zookeep进行分布式协调,下面对Zookeep集群进行搭建
$ tar -zxvf zookeeper-3.4.13.tar.gz
$ vim /etc/profile
#环境变量配置(master1、master2、worker1)都需要进行配置
export ZOOKEEP_HOME=/home/hadoop/zookeeper-3.4.13
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEP_HOME/bin
$ source /etc/profile
对Zookeep配置文件进行修改
/home/hadoop/zookeeper-3.4.13/conf/zoo.cfg,没有该文件的换,复制./zoo_sample.cfg改下名字
dataDir=/data/zookeep #给zk配置一个目录用来存储元数据,禁止使用/tmp
server.1=master1:2888:3888
server.2=master2:2888:3888
server.3=worker1:2888:3888
完成上面配置之后,需要创建/data/zookeep目录,并且将server.x中的x分别写入到不同节点的
$ mkdir -p /data/zookeep
$ echo '1' > myid
上面配置需要再安装了ZK的不同节点进行写入,根据具体自己的配置目录和序列号进行写入
配置文件介绍:
端口介绍:在
zk中提供服务的端口是2181,2888、3888这两个端口分别是集群间进行通讯的端口和当集群中leader节点挂了的时候进行通讯的端口
server.[数字]配置介绍:在zk leader节点挂了时候将进行选举,数字是权重值,权重越大的被选为leader的可能性越大,但是在选举过程中还会参考另外一个权重值,另一个权重值主要记录的是数据的多少,数据越多的节点选为leader的几率越大
将``zk的包scp`到其他节点
$ scp ./zookeeper-3.4.13 master2:`pwd`
$ scp ./zookeeper-3.4.13 worker1:`pwd`
配置完成之后进行启动并验证
$ zkServer.sh start #启动zk
$ zkServer.sh stop #关闭zk
$ zkServer.sh status #查看状态
$ zkCli.sh #进入zk终端
启动完成之后将看到QuorumPeerMain进程,同时进入终端之后会看到zookeep目录树,同时三个节点分别查看状态会发现,有一个leader和两个fllower
$ jps #查看java进程,查看QuorumPeerMain是否存在
$ zkCli.sh #进入zk终端
$ ls / #查看zk中的目录树,会发现zookeeper目录




如上图中所示,说明安装成功
注意:zk在安装完成之后,需要启动zk集群过半的数量之后才能向外提供服务,目前集群规模只允许一台节点挂掉
三、Hadoop 集群搭建
1、免密登录配置
在进行hadoop配置之前需要进行集群间的免密登录配置
主要是对master1和master2进行相关配置
#在master1和master2节点记性免密登录配置
$ ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa #生成秘钥
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #cp公钥到验证文件中
$ chmod 0600 ~/.ssh/authorized_keys
上面是对master1和master2进行了自身免密配置
上面完成之后会在~目录生成.ssh/的隐藏文件夹,需要分别将master1和master2的公钥发送到其他节点,同时master1和master2互相之间也需要进行免密配置
第一次在没有生成秘钥的情况下是不会产生~/.ssh/目录的,使用自己登陆自己可以创建,也可以自己创建
$ ssh localhost #该操作会创建~/.ssh/目录
如上在每个节点都执行之后,就可以将master1和master2中的公钥文件id_rsa.pub文件拷贝到其他节点写入authorized_keys文件中
列如worker1节点:
$ scp ./id_rsa.pub worker1:`pwd` #master1上执行
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys #worker1执行
$ chmod 0600 ~/.ssh/authorized_keys #worker1执行
依次对其他节点进行免密配置,配置完成之后需要重新打开终端,然后可以在master1和master2登录其他节点,此时不需要密码就能登录,这里一定需要验证,因为没有免密登录的情况hadoop之间的脚本管理将起不到作用,必须保证免密是配置正确的
2、hadoop相关配置
下面现在Maser节点配置hadoop相关环境
/home/hadoop/hadoop-2.7.7/etc/hadoop/core.sitt.xml 文件配置
<!--修改hadoop tmp 目录,禁止使用/tmp目录,这里使用的是挂在硬盘的目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/data/hadoop/tmp</value>
</property>
<!--配置集群名称(根据后面hdfs.site.xml中的配置进行修改的-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--设置journalNode元数据保存路径,这里保存的是曾经单节点NameNode中的edit.log元数据信息-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/journalnode</value>
</property>
<!-- 配置集群使用的zookeep集群节点名称和端口号 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>master1:2181,master2:2181,worker1:2181</value>
</property>
/home/hadoop/hadoop-2.7.7/etc/hadoop/hdfs.site.xml文件配置
<!--设置副本数,一般最低三个副本-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!--设置集群名称-->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!--设置主节点别名-->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!--主节点别名和IP(主机名)端口映射-->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>master1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>master2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>master1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>master2:50070</value>
</property>
<!--JNN 集群配置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master1:8485;master2:8485;worker1:8485/mycluster</value>
</property>
<!-- 这里直接抄过去 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!--配置ssh验证-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!--配置 rsa 秘钥文件-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!--是否开启 HA 模式-->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
/home/hadoop/hadoop-2.7.7/etc/hadoop/slaves文件配置(该文件配置的是DataNode所在节点的主机名或者IP
worker1
worker2
worker3
worker4
worker5
worker6
worker7
/home/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh文件配置
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
在该文件中找到JAVA_HOME环境变量并进行修改成自己的JDK路径
如上配置完成之后将整个包发送到各个节点
$ scp -r ./hadoop-2.7.7/ worker1:`pwd` #列如worker1
完成包拷贝之后,可以进行启动看HA - Hadoop是否成功
3、hadoop和ZK整合和初始化
在对HDFS进行格式化之前一定要先将journalNode集群启动因为元数据将会保存在这个集群中,
journalNode根据集群规划分别实在master1、master2、worker1
$ hadoop-daemon.sh start journalnode #master1、master2、worker1节点上执行(启动JNN)
NameNode格式化
在master1或者master2上对NameNode进行格式化
$ hadoop namenode -format #格式化
一个节点进行了格式化,另外一个节点只需要进行元数据同步,不需要再进行一次格式化,如果有多个NameNode也是一样的
$ hdfs namenode -h #查看帮助命令
$ hdfs namenode -bootstrapstandby #进行数据同步
格式化完成之后分别在master节点启动NameNode
$ hadoop-daemon.sh start namenode
格式化完成之后需要进行ZKFC的格式化,ZKFC格式化主要是在zookeep集群中生成一个目录树
$ yum -y install psmisc #在格式化中需要依赖的包,有些老系统没有这个包安装一下
$ hdfs zkfc -formatZK
如上格式化完成之后会在ZK中生成一个hadoop-ha目录树
$ zkCli.sh #进入终端
$ ls / #终端输入

只要在这一步出现了hadoop-ha说明配置成功
启动HDFS,随便在一个master节点上执行
$ start-dfs.sh #启动
$ jps #在每一个节点上检查进程是否完整
注意:这里在启动或者格式化的过程中,可能会出现有的文件权限不足的情况,因为我们是挂在的磁盘,可能其他用户不能读写操作,所以可以根据自己的需求适当修改文件读写权限
在检查进程的时候,可以参考集群规划表中的进程数量,到这一步,除了spark的两个角色进程和yarn的两个角色进程以外,其他的进程是否按照预期出现,如果没有说明搭建过程中是存在问题的,若果进程都没有问题,那么可以访问http://master1:50070和http//master2:50070,看是否能被访问
4、验证hadoop高可用是否生效
下面是对hadoop-HA进行验证,通过访问上面的两个地址,将会看到如下两个页面:
master1
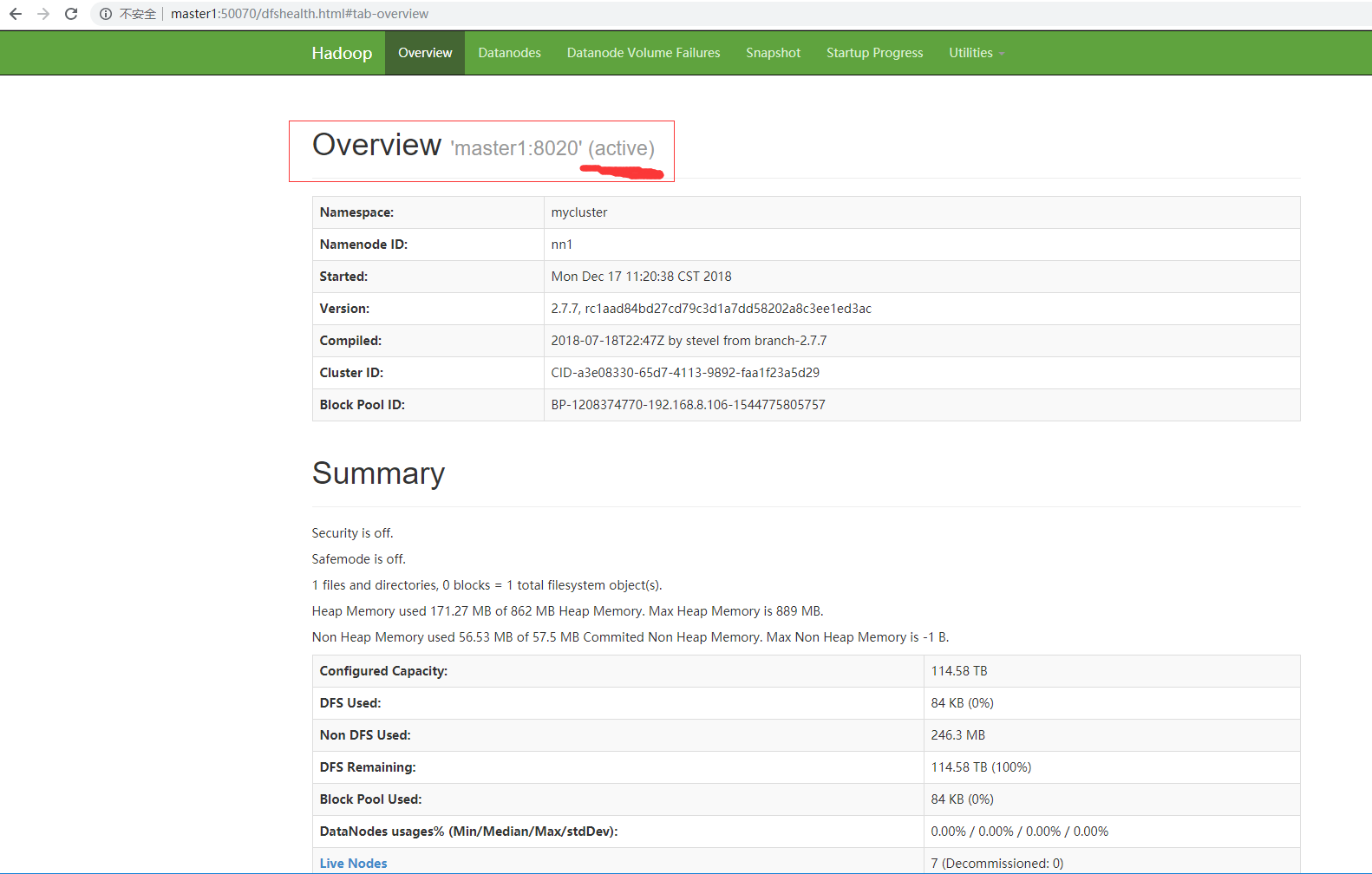
master2

这是正常的,那么需要进行验证的是高可用的可用性,也就是说他们中其中一台挂了,服务都能继续,可以通过kill进程来达到效果,这里说下影响到集群可用性的进程
1、
NameNode:进程结束服务就消失2、
ZKFC:该进程结束,对应的NameNode无法和journalNode建立关系,无法做数据同步,服务也将结束3、
journalNode:journalNode挂了,整个集群歇菜,所以需要做高可用,这里journalNode也是高可用的最多允许一台挂4、
zk:zk一旦挂了,那么会影响到journalNode集群和KFC,所以他挂了,其他的也玩完,所以他也做了集群,避免单点故障,同样的最多允许一台挂,当然这些集群都可以扩充,只是现在没必要
所以验证的方式就是,上面的这些进程,随便找一个master,一个一个kill看他是否能自动从standby切换到active能切换,说明配置就没有问题,是生效的!
四、yarn高可用集群搭建
1、yarn集群搭建
上面的步骤确保正确的情况下,下面进行配置yarn
/home/hadoop/hadoop-2.7.7/etc/hadoop/yarn.site.xml文件配置
<!--mapreduce shuffle配置-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--开启HA模式-->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!--设置yarn集群名称-->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<!--设置yarn集群中resourcemanager别名,节点数量-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!--对yarn集群中 resourcemanager 别名和集群名称进行相关映射-->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>master1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>master2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>master1:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>master2:8088</value>
</property>
<!--设置zk集群地址和端口号-->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>master1:2181,master2:2181,worker1:2181</value>
</property>
<!--配置每个节点每个任务调度和使用最大能分配到的内存和CPU核心数-->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>92160</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>32</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>92160</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>32</value>
</property>
/home/hadoop/hadoop-2.7.7/etc/hadoop/mapred.site.xml文件配置
<!--mapreduce在yarn集群中进行调度配置-->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
如上配置完成之后yarn的基本配置基本上就完了,将这两个文件发送到其他节点
$ scp -r ./mapred.site.xml yarn.site.xml worker1:`pwd` #如worker1
完成集群间的上述文件替换之后启动yarn集群
$ ./start-yarn.sh #启动yarn集群
$ ./stop-yarn.sh #关闭yarn集群
注意: 上述的命令只能关闭和开启NodeManager角色进程,同时这里启动的时候是根据slaves文件中的配置进行启动的 NodeManager,需要手动去到ResourceManager所在节点去启动
$ ./hadoop-daemon.sh start resourcemanager #启动ResourceManager
$ ./hadoop-daemon.sh stop resourcemanager #关闭ResourceManager
2、yarn集群高可用测试和验证
yarn服务地址:http://master1:8088 OR http://master2:8088; http://worker1:8048(该地址是访问node节点的)
如上访问两个地址,
master1
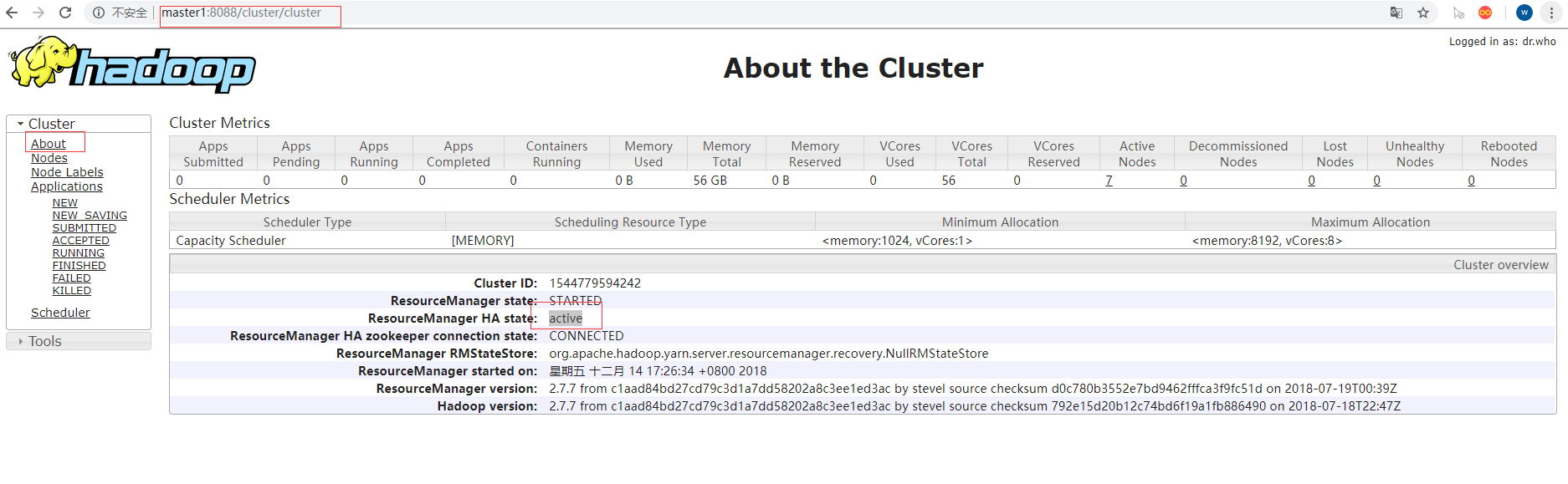
master2
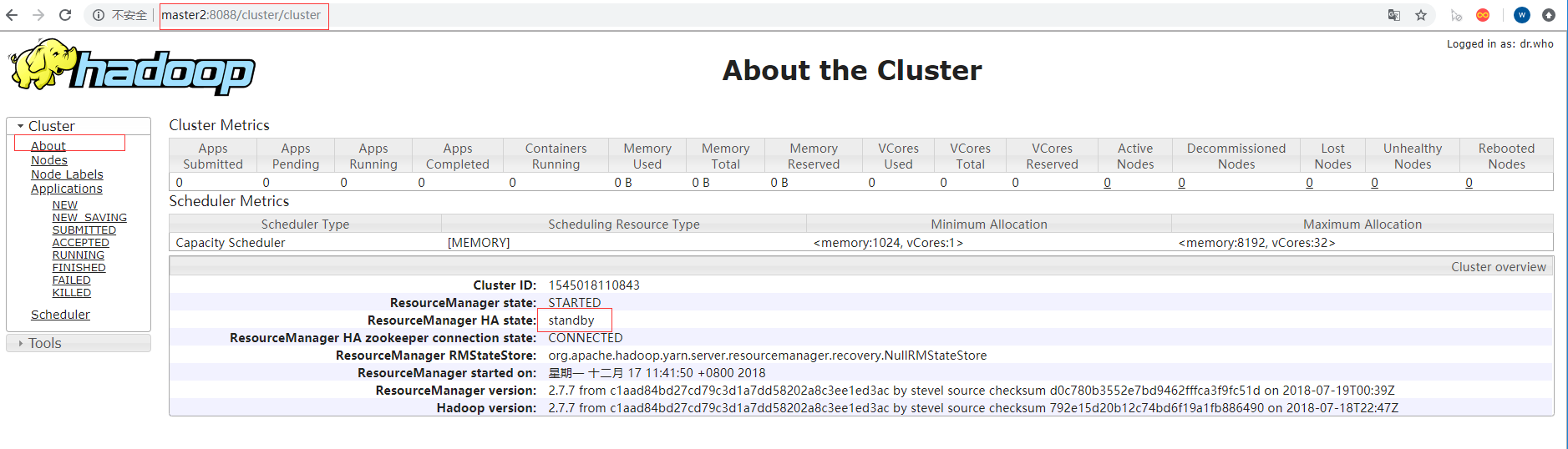
如上出现了两个访问页面,master1是active,master2是standby状态,在访问的时候,当访问standby状态的节点的时候,他会自动重定向到active节点,跳转完成之后再修改主机名或ip就能进行访问!
同时现在还需要查看zk中的状态,进入终端
$ zkCli.sh #进入终端
$ ls / #查看目录树
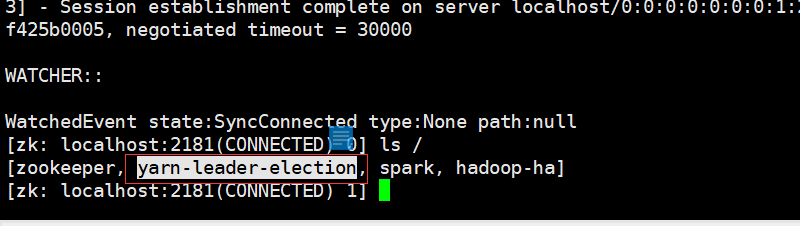
这个时候回多出一个目录树yarn-leader-election说明配置也没有问题,在zk中也进行了相关注册,下面就可以进行测试集群的可用性了,在yarn集群中,ResourceManager角色进程是比较关键的角色,他挂了就意味着yarn集群无法提供服务,所以,只需要模拟kill Resoucemanager的状态,然后看master1和master2状态是否进行了相关切换,如果能够切换成功说明配置是没有问题的
安装到这里需要查看各个节点的角色进程启动情况,是否和上面的集群架构表中的一样,如果正常说明搭建正常
这里说一下,单独把yarn提出来,因为HDFS可以独立于他进行运行,可以看成不同组件,虽然他在hadoop包中
五、Spark 高可用集群搭建
spark安装包:spark-2.4.0-bin-hadoop2.7.tgz
$ tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
$ mv spark-2.4.0-bin-hadoop2.7 spark-2.4
/home/hadoop/spark-2.4.0/conf/slaves文件配置
worker1
worker2
worker3
worker4
worker5
worker6
worker7
/home/hadoop/spark-2.4.0/conf/spark-env.sh文件配置
export JAVA_HOME=/home/hadoop/jdk1.8.0_191
export HADOOP_CONF_DIR=/home/hadoop/hadoop-2.7.7/etc/hadoop
export HADOOP_HOME=/home/hadoop/hadoop-2.7.7
export SPARK_MASTER_PORT=7077
export SPARK_MASTER_HOST=master1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master1:2181,master2:2181,worker1:2181 -Dspark.deploy.zookeeper.dir=/spark"
在上述文件中进行设置相关的环境变量配置,最基础的配置就是上述的这些内容:
SPARK_MASTER_HOST:改配置只需要在MASTER角色进程节点进行配置,同时在配置的时候要根据所在节点的真实地址进行设置,其他节点可以进行配置
SPARK_DAEMON_JAVA_OPTS:改配置中的参数介绍-Dspark.deploy.recoveryMode=ZOOKEEPER,该配置中有三个值,分别是ZOOKEEP(作用,使用ZK作为服务发现)、NONE(作用,不做任何操作)、FILESYSTEM(作用,在不做高可用的情况下,配置了之后,在计算过程中宕机,再次启动时他能尽力去根据记录元数据信息恢复);-Dspark.deploy.zookeeper.url=master1:2181,master2:2181,worker1:2181该配置主要是设置ZK提供服务的节点和端口;-Dspark.deploy.zookeeper.dir=/spark改配置是在进行服务发现的时候在ZK中生成spark的一个文件木树,用于保存高可用的一些元数据信息
上述内容设置完成之后,就可以将配置的文件发送到各个节点,同时针对一些需要进行修改的内容,分别在不同节点进行修改,修改完成之后进行启动,验证是否配置正确,相关启动命令都在/home/hadoop/spark-2.4.0/sbin目录中,这里不对spark进行环境变量的设置,因为他的启动命令和HDFS的启动命令部分重叠,避免发生冲突,当然也可以去修改启动命令文件名
$ ./start-master.sh #分别在master1和master2启动Master进程
$ ./start-slaves.sh #在一个Master节点进行启动所有slaves中配置的worker进程
$ ./stop-slaves.sh #停止worker进程
$ ./stop-master.sh #停止master进程
上述操作完成之后,启动完成之后,就可以查看各个节点角色进程是否和集群规划中的相同了,相同之后可以访问http://master1:8080、http://master2:8080两个地址
master1
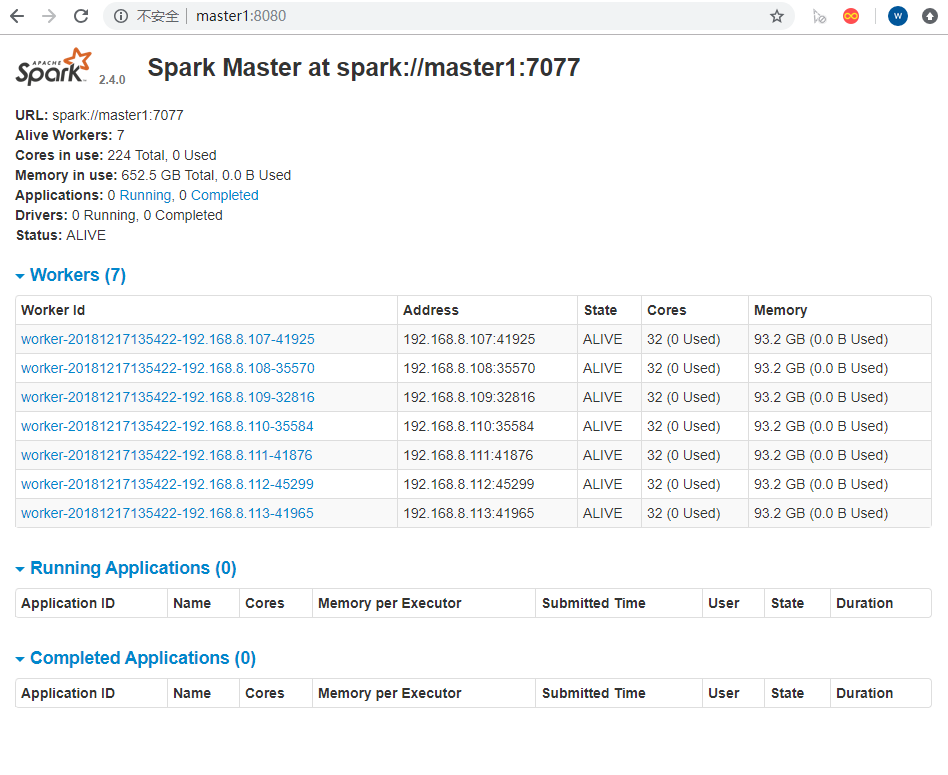
master2
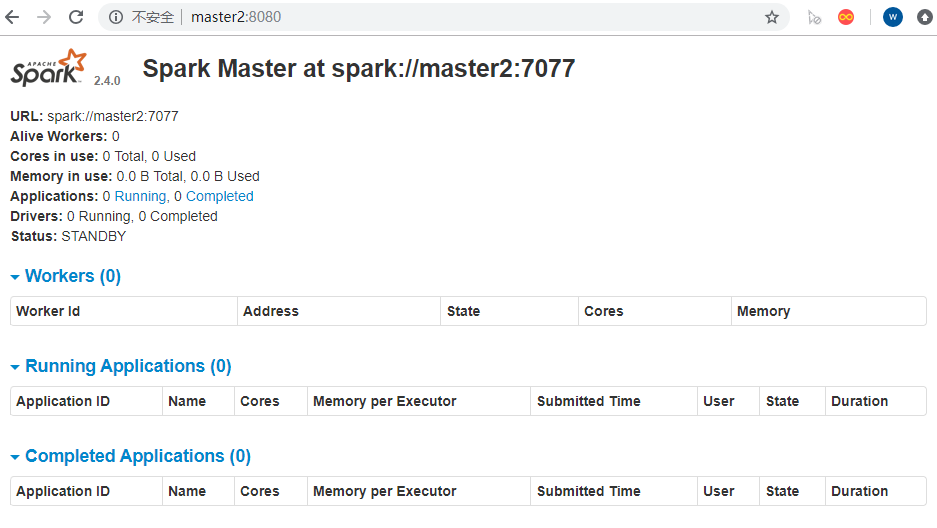
可以从上图中看出来,active、standby两个状态,对应的也可以kill master进程,看是否会进行自动切换状态
注意:在进行切换的时候,会有一段时间延迟,是因为集群间有心跳检测,一般在10秒钟,10秒钟进行一次检测,这个时间不同集群都是可以进行调整的!所以只有检测到集群节点,或者进程不健康的时候才会进行切换
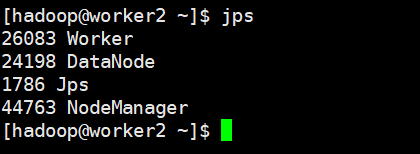
到这里可以看下各个节点的进程:
master1
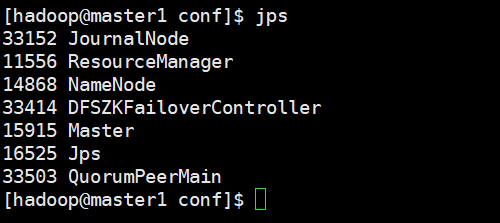
master2
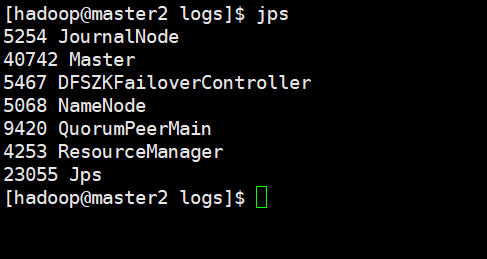
worker1
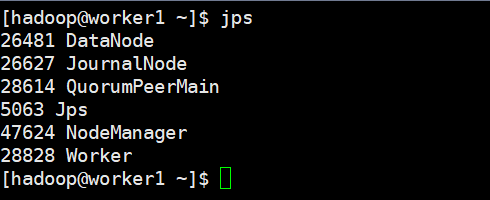
worker2(其他节点和这个节点进程相同)
上述的安装过程基本上是安装完成,下面来跑个测试例子,查看是否能够正常的进行工作。
提交到yarn集群
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 3 \
--queue thequeue \ #这个参数不需要,这里我们没有设置队列相关的内容,所以会报错,队列是关闭的
examples/jars/spark-examples*.jar \
1
提交到master集群
$ ./bin/spark-submit --class org.apache.spark.examples.SparkPi \
--master spark://master1:7077,master2:7077 \
--deploy-mode cluster \
--driver-memory 2g \
--executor-memory 2g \
--executor-cores 3 \
--name pi \
examples/jars/spark-examples*.jar \
1
这两种提交方式,一种是在yarn集群,可以通过yarn提供的webUI进行查看任务进度,一种是通过是Spark,可以通过sparkUI进行查看任务进度!
上面的例子是spark提供的测试例子,这个例子能跑同说明集群运行基本正常
六、PID WORKER_DIR LOG 内容配置
在集群开始正式工作之后,PID、WORKER_DIR、LOG_DIR可能会因为这些内容影响到集群的运行,默认集群中所有的PID都是在/tmp目录中的,这个目录系统会根据心情进行删除数据,这个时候可能会造成集群无法关闭等等问题,日志,工作日志这些会产生非常大的数据量,所以将其配置到挂在磁盘上
1、hadoop相关配置文件修改
/home/hadoop/hadoop-2.7.7/etc/hadoop/hadoop-env.sh文件配置
export HADOOP_PID_DIR=/data/hadoop/pid
export HADOOP_LOG_DIR=/data/hadoop/logs
2、yarn相关配置文件修改
/home/hadoop/hadoop-2.7.7/etc/hadoop/yarn-env.sh文件配置
export YARN_PID_DIR=/data/hadoop/pid
3、spark相关配置文件修改
/home/hadoop/spark-2.4.0/conf/spark-env.sh文件配置
export SPARK_PID_DIR=/data/spark/pid
export SPARK_LOG_DIR=/data/spark/log
export SPARK_WORKER_DIR=/data/spark/application
配置完成重启,查看是否正常安装指定路径创建

 浙公网安备 33010602011771号
浙公网安备 33010602011771号