随笔!!( UPDATE IN 2022-3-27 )
- vim ctags 自动更新
noremap <F6> <ESC>:!ctags -R *<CR>:set tags=./tags,./TAGS,tags,TAG<CR> - vim cscope 自动更新
noremap <F6> <ESC>:!cscope -Rbq *<CR><CR>:cs add cscope.out - vim 统计当前选择文本字数
1. 选择需要统计的文本
2. 先后按下键盘下的按键 g -> ctrl + g - vimrc 中 *map 的区别:
首先需要注意的是 vim 有三种工作模式: visual, insert, normal; 然后 map 分为两种:map(递归映射),noremap(非递归映射,not recursive map); 解释一下这里映射的概念: 如果存在映射: A -> B and B -> C 如果是递归映射:则在执行 A 的时候最终会执行到 C 代表的命令。 如果是非递归的: 执行 A 时只会执行到 B。 然后是作用域的说明: n normal v visual + option s option(在可是模式下 C^ + G 进入) x 可视 o 操作符等 ! 插入和命令行 i 插入 I 插入,命令行和 Lang-Arg c 命令行 功能域说明: 递归映射 nore 映射 un 取消映射 clear 取消所有 然后就有: nmap, xmap, smap, noremap, nnoremap, nunmap ... 具体参考 :help map - tab
VIM 7.0 开始支持标签页打开方式
:tabnew [cmd] [file_path] // 打开一个标签页 :tabc // 关闭当前标签页 :tabo // 关闭其他标签页 :tabs // 显示所有标签叶打开的文件 :tabp [n] or gT // 切换到前一标签页 :tabn [n] or gn // 切换到后一标签页 :tabfirst // 切换到第一个标签签页 :tablast // 切换到最后一个标签页 :tab split // 在新的标签页中打开当前缓冲区文件 :tabf // 搜索当前目录中的文件并打开,如 :tabf img.* :tabm [n] // 移动到第 n 个标签页处 :set showtabline=[1,2,3] // 0 完全不显示标签栏;1 只有用户新建时才显示;2 总是现实标签栏 :tabdo [cmd] // 执行命令,将作用到标签叶中,比如: :tabdo %s/food/drink/g 将替换多个标签文件中的 food 为 drink - 批量操作
:%s/pattern/replace/gc // % 标定范围,也可以用具体多少行到多少行表示,比如当前替换规则适用于 10 到 20 行,则可以这样写 10,20 // pattern 正则表达式 // replace 需要替换的字符串,可以用 & 表示之前匹配到的目标串 :%g/pattern/d // 删除匹配到的行 :%g!/pattern/d // 删除除匹配行的所有行 :%v/pattern/d // 删除除匹配行的所有行 - 设置状态栏现实文件完整路径
在状态栏中,添加%F以显示完整路径,如set statusline+=%F, 如果你的状态栏还是没有变化,那么你还需要加上set laststatus=2
也可以执行Ctr g查看 - spaceVim 的常用功能
-
:SPUpdate SpaceVim打开 SpaceVim 的插件管理器,更新 SpaceVim -
:h SpaceVim-options查看 spaceVim 的所有配置 -
~/.SpaceVim.d/init.toml用户的 SpaceVim 的配置目录 -
SPC t进入 SpaceVim 的控制面板 -
SPC t t打开标签管理器 -
SPC f t或者F3打开文件树 -
SPC v d打开当前配置 -
F2打开关闭语法树 - 修改
~/.SpaceVim/autoload/SpaceVim.vim文件中g:spacevim_lint_on_save参数为 0, 可禁止 SpaceVim 在编写代码时候弹出语法检查看板
-
- vim 语法
查询 vim 中与 theme 相关的配置以及 vim 配置中的语法可在 vim 中运行
:help syntax.txt - 我的 spaceVim 的配置
..[$] <()> cat ~/.SpaceVim.d/init.toml [options] colorscheme = "gruvbox" colorscheme_bg = "dark" enable_guicolors = false statusline_separator = "nil" statusline_iseparator = "bar" buffer_index_type = 4 windows_index_type = 3 enable_tabline_filetype_icon = false enable_statusline_mode = false statusline_unicode_symbols = false vimcompatible = true default_indent = 4 expand_tab = true autocomplete_method = "deoplete" snippet_engine = "ultisnips" # Enable autocomplete layer [[layers]] name = 'autocomplete' auto_completion_return_key_behavior = "nil" auto_completion_tab_key_behavior = "smart" auto_completion_delay = 200 auto_completion_complete_with_key_sequence = "nil" auto_completion_complete_with_key_sequence_delay = 0.1 [[layers]] name = 'shell' default_position = 'top' default_height = 30 [[layers]] name = "lang#c" enable_clang_syntax_highlight = true [layer.clang_std] c = "c11" cpp = "c++1z" objc = "c11" objcpp = "c++1z" [[layers]] name = "lsp" filetypes = [ "c", "cpp" ] [layers.override_cmd] c = ["clangd", "--limit-results=5"] cpp = ["clangd", "--limit-results=5"]
如果要给输出的内容加元素,那么输出的字符串应该被以下模板包围:( \033[显示方式;前景色;背景色mYOUR_STRING \033[0m ), 如果想使用默认背景则可以选用以下模板( \033[显示方式;前景色mYOUR_STRING \033[0m)。 其中 \033[显示方式;前景色;背景色m 为设置接下来的字符串以何种颜色显示;\033[0m 为结束前面的设置。 接下来详细介绍 显示方式, 前景色,背景色的值。
- 显示方式
- 0 终端默认设置
- 1 高亮显示
- 4 使用下划线
- 5 闪烁
- 7 反白显示
- 8 不可见
- 前景色(文字颜色)
- 30 黑色
- 31 红色
- 32 绿色
- 33 黄色
- 34 蓝色
- 35 紫红色
- 36 青蓝色
- 37 白色
- 背景色
- 40 黑色
- 41 红色
- 42 绿色
- 43 黄色
- 44 蓝色
- 45 紫红色
- 46 青蓝色
- 47 白色
注意,一下命令都在 kali 中执行,其他系统请自行判断。
- 破解 zip file
使用 fcrackzip 命令, 详情请参考 man fcrackzip
fcrackzip -u -b -v -l 6-8 xxx.zip暴力破解,密码长度为 6 - 8 位的 zip 文件
fcrackzip -u -b -v -c 1aA -l 6 xxx.zip暴力破解,从字符集 [0-9,a-z,A-Z] 中选取破解字符
fcrackzip -u -D -p password.set xxx.zip从 password.set 字典中破解 xxx.zip 文件
locate wordlists查看当前系统中存在的字典库 - 扫描局域网内打开某端口的 IP
sudo masscan -p 22 --range 192.168.3.0/24或者sudo masscan -p 22 --range 192.168.3.1-192.168.3.100 - 扫描局域网中正在联网的设备
nmap -sP 192.168.0.1/24ornmap -sP 192.168.0.*ornmap -sP 192.168.0.1-255。 该方法为使用 ICMP 的 ping 来实现的,但有可能局域网中某些主机禁止了 ping 的响应,有可能检测不出某些联网设备
nmap -sS 192.168.2.224ornmap -sS 192.168.2.230-255ornmap -sS -p 0-30000 192.168.2.230-255。 该类方法 nmap 会通过发送 TCP SYN 数据包支持 TCP 半开放扫描,扫描主机 TCP 端口的开放状态。 SYN 扫描相比与完成三次握手的全开放扫描速度更快,也不易被检测。 nmap 默认会扫描 1-1024 端口和其他一些常用端口,如果要扫描其他端口可以用 -p 选项来指定。
nmap -sT 192.168.2.230-255ornmap -sT -p 0-30000 192.168.2.230-255。 nmap 的 Connect 扫描是通过 TCP 完成三次握手来检测的,所以速度相对于 SYN 半开放扫描要慢,但结果更可靠。 默认扫描端口及端口的指定与 SYN 扫描相同。
nmap -sU 192.168.2.230-255ornmap -sU -p 0-30000 192.168.2.230-255。 nmap也支持UDP端口的扫描。 UDP相比于TCP协议被防火墙拦截的几率更小。
-
最常用到的工具:
openssh-server,vim,git,gcc,g++,axel,automake,tree,htop,python2.7(3.4/3.6),python-pip,ipython,ctags/cscope,Vscode,octave,RStudio,Wireshark,cmake,nginx,node - Virtualbox 扩容
找到虚拟机挂载的盘,然后执行以下命令:
vboxmanage modifymedium YOUR.vdi --resize 102400(YOUR.vid 为你要修改盘大小的路径, --resize 后跟修改后的大小,单位为 M) - ssh 以及其相关
- ssh 登陆很慢!
两个步骤,第一步,关闭 gassp 认证,
vi /etc/ssh/ssh_config; GSSAPIAuthentication yes; GSSAPIDelegate Credentials no;;步骤二,关闭 ssh 的 UseDNS,vi /etc/ssh/ssh_config; UseDNS no;(关了这个,在登陆云的时候可能会出问题,谨慎使用。)。具体格式要百度到处都有了,思路就是这样的。如果这样还不行,那就去吐槽吧! - 添加公钥报错:
sign_and_send_pubkey: signing failed: agent refused operation执行下面两行代码可以解决这个问题:
eval "$(ssh-agent -s)" ssh-add
- ssh 登陆很慢!
- python
pip 修改更新源码,在
/etc/pip.conf或者~/.pip/pip.conf加入以下代码:[global] trusted-host = pypi.doubanio.com index-url = https://pypi.doubanio.com/simple
也可以在安装的时候用参数 i 手动指定源地址,如:
pip install web.py -i http://pypi.douban.com/simple - 在 Windows gitbash 中 使用 adb push 报错
在 Windows 的 GitBash 中使用 adb push 推送文件到设备中时可能推送 Windows 系统本地的目录中, 类似于C:/Users/xxx/AppData/Local/xxx
原因在于 GitBash 是基于 MSYS shell 开发的,而 MSYS shell 自己存在一些规则会自动补全命令中的路径,参考:https://stackoverflow.com/questions/16344985/how-do-i-pass-an-absolute-path-to-the-adb-command-via-git-bash-for-windows
解决方法就是在设备的绝对路径前再加上/来使 GitBash 防止自动补全到本地路径,如adb push ota //tmp/ota - 系统在执行 sudo 时出现 “sudo: unable to resolve host xxx”
如果你重新配置了
/etc/hostname,但又忘记在/etc/hosts里加反解,那么你在运行 sudo 是出现该警告是正常的,而且 sudo 会因为尝试去解析你的主机而造成系统变慢或者网络不好的假象。正确的姿势是在/etc/hosts里加上127.0.0.1 your_hostname和::1 your_hostname。 - 我的 chromium 插件(这里只记录名字)
AdBlock,ChromeReloadPlus,Dark Reader,EditThisCookie,Feedly Subscribe Button,Fika - Reader Mode,Flash Video Downloader,Focus To-Do: Pomodoro Timer & To Do List,Google Calendar,Google Translate,Grammarly for Chrome,Hackbar,Headless Recorder,Markdown Here,MeddleMonkey,Nimbus Screenshot & Screen Video Recorder,OneTab,Pomotodo,Proxy SwitchyOmega,Slack Deleter,Speedtest by Ookla,Tampermonkey,The Great Suspender,Video Downloader professional,Vimium,Web Scraper - Free Web Scraping,WorldBrain's Memex - sphinx
- 修改主题
1. 首先修改 sphinx 的 conf.py 文档中的两个变量, html_theme = "theme_name", html_theme_path = ["./theme"]。 2. 在 conf.py 文件目录下创建 theme 目录。 3. sphinx 安装目录下的 themes/sphinxdoc 目录复制到 theme 目录并重命名为主题的名字 theme_name。 4. 在 theme_name 目录下有一个 theme.conf 的文件,该文件是 sphinx 生成样式的模板文件,可在这里面加载自己的样式 css 或者 js, 附: 如果免的麻烦,可以直接修改上叙步骤 1 中的两个变量重定向到该主题.如何修改的详细步骤请参考本节下面的参考连接[link1]。
- 修改主题
- systemd
- systemd 查看 journalctl 占用空间大小
journalctl --disk-usage - 手动清理日志
journalctl --disk-usage或者rm -rf /var/log/journal/* - 自动清理: 限制日志保留一周
journalctl --vacuum-time=1w, 限制日志大小journalctl --vacuum-size=500M
- systemd 查看 journalctl 占用空间大小
- Linux 统计当前文件数目
// 统计当前文件夹数目 ls -l |grep "^d"|wc -l // 统计当前文件数目 ls -l |grep "^-"|wc -l // 递归统计当前文件夹下的文件数目 ls -lR|grep "^-"|wc -l // 递归统计当前文件夹下文件夹数目 ls -lR|grep "^d"|wc -l // 统计当前文件夹下文件以及目录数目 ls -lR|grep -E "^d|^-"|wc -l - FFmpeg 使用方法汇总
// 分离视频音频流 ffmpeg -i input_file -vcodec copy -an output_file_video //分离视频流 ffmpeg -i input_file -acodec copy -vn output_file_audio //分离音频流 // 视频解复用 ffmpeg –i test.mp4 –vcodec copy –an –f m4v test.264 ffmpeg –i test.avi –vcodec copy –an –f m4v test.264 // 视频转码 ffmpeg –i test.mp4 –vcodec h264 –s 352*278 –an –f m4v test.264 //转码为码流原始文件 ffmpeg –i test.mp4 –vcodec h264 –bf 0 –g 25 –s 352*278 –an –f m4v test.264 //转码为码流原始文件 ffmpeg –i test.avi -vcodec mpeg4 –vtag xvid –qsame test_xvid.avi //转码为封装文件 //-bf B帧数目控制,-g 关键帧间隔控制,-s 分辨率控制 // 高品质编码 ffmpeg -i in.mkv -preset slower -crf 18 out.mp4 -crf 该参数决定输出视频的质量,值的范围是 0-51, 默认 23, crf 越低,质量越高。 -preset 控制压缩过程的速度。存在这么几个选项(ultrafast / superfast / veryfast / faster / fast / medium / slow / slower / veryslow / placebo) https://trac.ffmpeg.org/wiki/Encode/H.264 // 视频封装 ffmpeg –i video_file –i audio_file –vcodec copy –acodec copy output_file // 视频剪切 ffmpeg –i test.avi –r 1 –f image2 image-%3d.jpeg //提取图片 ffmpeg -i vid.mp4 -y -f image2 -t 0.001 -ss 10 -s 1920x1080 haha.png //提取图片 ffmpeg -ss 0:1:30 -t 0:0:20 -i input.avi -vcodec copy -acodec copy output.avi //剪切视频 ffmpeg -ss 0:1:30 -t 0:0:20 -i input.avi -c output.avi //剪切视频 //-r 提取图像的频率,-ss 开始时间,-t 持续时间 ffmpeg -ss [start] -i in.mp4 -t [duration] -c:v libx264 -c:a aac -strict experimental -b:a 128k out.mp4 // -c:v 指定视频编码类型 // -c:a 指定音频编码类型 // -b:a 指定音频的码率 // -b:v 指定视频的码率 // -codec -c 等价 // --vcodec -c:v 等价 // -ab bitrate audio bitrate (please use -b:a) // -b bitrate video bitrate (please use -b:v) // ffmpeg -encodecs 查询支持的 A/V codec // ffmpeg -decoders 查询支持的 A/V codec https://superuser.com/questions/835048/difference-between-cv-and-vcodec-and-ca-and-acodec // 合并视频 ffmpeg -i in0.mp4 -i in1.mp4 -c copy -map 0:0 -map 1:1 -shortest out.mp4 // -i 指定输入 // -map 第一个数字指定第几个输入流, 第二个数字指定输入流中的第几个 stream // http://ffmpeg.org/ffmpeg.html#Advanced-options // 拼接视频 // 床家一个视频列表 echo -n "file 'in1.mp4'\nfile 'in2.mp4'\nfile 'in3.mp4'\nfile 'in4.mp4'\n" > /tmp/list.txt // 将文件中的视频拼接成一个视频 ffmpeg -f concat -i list.txt -c copy out.mp4 // 视频延迟播放 ffmpeg -i in.mp4 -itsoffset 3.84 -i in.mp4 -map 1:v -map 0:a -vcodec copy -acodec copy out.mp4 // 音频延迟播放 ffmpeg -i in.mp4 -itsoffset 3.84 -i in.mp4 -map 0:v -map 1:a -vcodec copy -acodec copy out.mp4 // 字幕转换 ffmpeg -i sub.srt sub.ass // 为视频添加字幕 ffmpeg -i in.mp4 -vf ass=sub.ass out.mp4 // 修改视频 metadata ffmpeg -i in.mp4 -map_metadata -1 -metadata title="My Title" -c:v copy -c:a copy out.mp4 // 将视频拆分成图片 ffmpeg -i xxx.mp4 %d.jpg // 手动指定每秒生成图片数量 ffmpeg -i vid.mp4 frame%03d.png -r 20 // 每秒截取一张图片 ffmpeg -i in.mp4 -fps=1 -vsync 0 out%d.png // 从视频的几个区间截取图片(1-5s 以及 11-15s) ffmpeg -i in.mp4 -vf select='between(t,1,5)+between(t,11,15)' -vsync 0 out%d.png // 将散列的图片拼凑成视频 ffmpeg -i frame%3d.png out.mp4 ffmpeg -r 1/5 -i img%03d.png -c:v libx264 -vf fps=25 -pix_fmt yuv420p out.mp4 // -r 指定图像的帧率,1/5 代表一张图片复制 5 帧 // -vf fps=25 则指定视频的帧率 // Deinterlace ffmpeg -i in.mp4 -vf yadif out.mp4 // 将视频顺时针旋转 90 度 // transpose // 0 = 90CounterCLockwise and Vertical Flip (default) // 1 = 90Clockwise // 2 = 90CounterClockwise // 3 = 90Clockwise and Vertical Flip // -vf "transpose=2,transpose=2" 翻转 180 度 ffmpeg -i in.mov -vf "transpose=1" out.mov 下载视频流 ffmpeg -i "path_to_playlist.m3u8" -c copy -bsf:a aac_adtstoasc out.mp4 如果下载的协议没有在默认的白名单中,还可以通过 -protocol_whitelist 设置支持协议 ffmpeg -protocol_whitelist "file,http,https,tcp,tls" -i "path_to_playlist.m3u8" -c copy -bsf:a aac_adtstoasc out.mp4 // 将视频中的某些时段设置为静音 ffmpeg -i in.mp4 -vcodec copy -af "volume=enable='lte(t,90)':volume=0" out.mp4 ffmpeg -i in.mp4 -vcodec copy -af "volume=enable='between(t,80,90)':volume=0" out.mp4 // 视频录制 ffmpeg –i rtsp://192.168.3.205:5555/test –vcodec copy out.avi // YUV序列播放 ffplay -f rawvideo -video_size 1920x1080 input.yuv // YUV序列转AVI ffmpeg –s w*h –pix_fmt yuv420p –i input.yuv –vcodec mpeg4 output.avi 转换成 Gif 图 ffmpeg -i vid.mp4 -vframes 5 -y -f gif out5.gif // 将视频的前五帧转换成 Gif 图 ffmpeg -ss 00:00:00.000 -i vid.mp4 -pix_fmt rgb24 -r 10 -s 320x240 -t 00:00:10.000 out6.gif // v4l2 列举所有设备 v4l2-ctl --list-devices // v4l2 列举设备支持的编码格式 v4l2-ctl -d /dev/video0 --list-formats // v4l2 列举设备编码格式支持的分辨率 v4l2-ctl -d /dev/video0 --list-framesizes=H264/MJPG/YUYV // 综合上叙两者信息 ffmpeg 给出的方案 ffmpeg -f v4l2 -list_formats all -i /dev/video0 // ffmpeg 从 video 导出视频 ffmpeg -f v4l2 -framerate 25 -video_size 640x480 -i /dev/video0 output.mkv // ffmpeg 指定格式导出视频 ffmpeg -f v4l2 -input_format mjpeg -i /dev/video0 -c:v copy output.mkv ffmpeg -f v4l2 -input_format yuyv422 -i /dev/video0 -c:v libx264 -vf format=yuv420p output.mp4 ffmpeg -f v4l2 -input_format yuyv422 -framerate 30 -video_size 640x480 -i /dev/video0 -c:v libx264 -vf format=yuv420p output.mp4 // 下面是 windows 相关的指令 // 列出当前系统中存在的 A/V 设备 ffmpeg -list_devices true -f dshow -i dummy // 查看指定设备支持的配置项 ffmpeg -f dshow -list_options true -i video="HP Truevision HD" // 捕获音视频流 ffmpeg -f dshow -i video="AJA Capture Source":audio="AJA Capture Source" ffmpeg -f dshow -s/-video-size 1080*1920 -framerate 60 -vcodec mjpeg -i video="AJA Capture Source" \ -f dshow -ac 2 -ar 8000 -i audio="AJA Capture Source" \ output.mkv // 如果发现 list 的 video 设备存在多个同名设备,ffmpeg 可以支持选定某个 pin 进行采集 // 具体配置请参考: https://www.ffmpeg.org/ffmpeg-devices.html#dshow ffmpeg -f dshow -audio_pin_name "Audio Out" -video_pin_name 2 、 -i video=video="@device_pnp_\\?\pci#ven_1a0a&dxxxxx..xxxxxx23196}\{xxx...xxxx}":audio="Microphone" // 以下是一些参考网站,之前的一些因为年代久远就没有列举在这里了 // https://superuser.com/questions/494575/ffmpeg-open-webcam-using-yuyv-but-i-want-mjpeg // https://trac.ffmpeg.org/wiki/Capture/Desktop // https://www.ffmpeg.org/ffmpeg-devices.html#dshow // https://www.bogotobogo.com/VideoStreaming/ffmpeg_webcam_capture_Windows_Linux.php - mp4box
- Linux 安装 dota2
- 1. 安装 staem
- 2. 从 http://store.steampowered.com/app/570/?cc=us 处打开开始安装。
- virtualbox 挂载实体硬盘
首先用
lsblk找到你需要挂在的硬盘。然后用
sudo vboxmanage internalcommands createrawvmdk -filename ./sugr_cop_rawdisk.vmdk -rawdisk /dev/sdc -relative来生成实体硬盘的维护信息。其中
-filename参数用于指定存放实体硬盘维护信息的文件路径,之后创建虚拟机的时候也就是直接挂载这个文件,用于启动;-rawdisk参数用于指定你想要挂载的实体硬盘。需要注意的是这个硬盘一定是普通用户可读的,因为一盘你在 Linux 上运行虚拟机都是在普通用户运行,所以如果你挂载的硬盘是 /dev/sdc 那么你需要执行这条命令(sudo chmod 666 /dev/sdc)来开放普通用户对硬盘的读写权限。最后按照下面的步骤你就可以成功的将你实体硬盘上的系统跑起来了:(假设你的系统是 ubuntu 64)
open virtualbox Manager -> Machine -> new -> name( your machine name ) -> type( Linux ) -> Ubuntu (64-bit) -> next -> 内存分配 -> next -> select : Use an existing virtual hard disk file -> select : 你之前创建的文件 -> create, - 多线程下载工具
多线程下载工具 axel,mwget。(暂时还没有看到那个比较好的评价)
- 查看网卡的 UUID
NetworkManager 中提供的 nmcli 这个程序可以查看网卡的 UUID,用法:
nmcli con | sed -n '1,2p' - GRUB
- HTTPS
Let’s Encrypt 是一个于2015年推出的数字证书认证机构,将通过旨在消除当前手动创建和安装证书的复杂过程的自动化流程,为安全网站提供免费的SSL/TLS证书。(以上的信息来自 wikipedia, 更详细的信息请去 wikipedia 获取)
如果你要用 certbot 你可以先按照他 官网 的说明来安装好 certbot 的环境。基本上类 unix 平台上的 apache2, nginx, haproxy... 都支持,
- Mysql 更改密码
首先停掉 mysql 服务
/etc/init.d/mysqld stop,然后运行以下命令mysqld_safe --skip-grant-tables&;再这之后,直接运行 mysql 可以进入 mysql 终端界面;到这之后运行下面的命令就可以更新你的密码了:update user set authentication_string=password('YOUR_PASSWOR') where user='root'; - mysql 报 No directory, logging in with HOME=/
执行以下命令
sudo service mysql stop sudo usermod -d /var/lib/mysql/ mysql sudo service mysql start - Shell
- 在命令行生成随机数字:使用
$$RANDOM变量 - 使用
/dev/random或者/dev/urandom, 如cat /dev/urandom | head -n 10 | md5sum - 使用 Linux UUID 机制,如
cat /proc/sys/kernel/random/uuid - 创建 SHELL 数组:
arr_name=(1 2 3 4 5 6);获取数组大小:arr_size=${#arr_name[*]};
- 在命令行生成随机数字:使用
- linux /proc 下文件的详细说明
man 5 proc - /proc/diskstate 的格式说明文档 Linux 内核源码工程的 Documentation/iostats.txt 文件
- AS 控制台乱码
快速按下 shift 按键,搜索 Edit Custom VM Options..., 并在其中配置如下选项-Dfile.encoding1=UTF-8, 该配置文件在 ${AS_CONFIG_PATH}/AndoirdStudio4.0/config/studio64.exe.vmoptions - Android 工程升级到 1.8
在 build.gradle 中加入以下配置:android{ compileOptions{ sourceCompatibility JavaVersion.VERSION_1_8 targetCompatibility JavaVersion.VERSION_1_8 } } - Execution failed for task ':app:checkDebugDuplicateClasses' ...
首先确认你发生冲突的包是哪些,然后根据实际情况判断做法, 如果你的系统是定制系统,有可能为了编译通过你需要引入你司定制类,而你司定制类与原生依赖有冲突,则可能出现此问题, 而如果出现此问题,的解决方案就是与你司定制依赖的开发人员协商,看如何处理。 比如说 push 定制依赖支持你所应用功能集,或者 push 依赖独立冲突类。 还一种解决方法是跟据你的实际情况采用 compileOnly( provided )选项来处理依赖。 - 电脑设备带宽列表
PCIe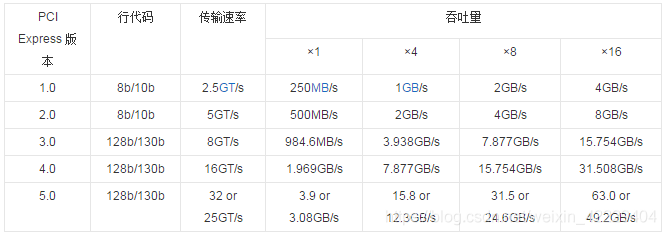
其他请参考 电脑设备带宽列表 - 硬件虚拟化项目
VMWare, Xen, KVM - 生成各格雷码的函数
def bitcode2graycode(x): return x^(x>>1) def graycode2bitcode(x): x = x ^ (x>>16) x = x ^ (x>>8) x = x ^ (x>>4) x = x ^ (x>>2) x = x ^ (x>>1) return x - 设计模式
设计模式无处不再,不仅仅是在面向对象的代码编写中。如果你打开 Linux 内核, ffmpeg, chromium,你会看到很多模式很一致的结构代码,个人觉得设计模式是为了解决一类问题从而 Build 的一个模型,随着经验的增加也会创造出很多属于自己的模式
不过对于面试过程中所用到的,可以参考此书: https://refactoringguru.cn/design-patterns - 前端开发
响应式 Web 设计, 随着移动设备的普及,如何让用户通过移动设备浏览您的网站获得良好的视觉效果,已经是一个不可避免的问题了。响应式 Web 设计就是为实现这个目的的有效方法。响应式 Web 设计是一个让用户通过各种尺寸的设备浏览网站获得良好的视觉效果的方法。例如,您先在计算机显示器上浏览一个网站,然后再智能手机上浏览,智能手机的屏幕尺寸远小于计算机显示器,但是你却没有感觉到任何差别,两者的用户体验几乎一样,这说明这个网站在响应式设计方面做得很好。 - 敏捷开发
- 搭建 jenkins 持续集成平台
1. 安装 jenkins 1. openjdk(版本请参考 jenkins 需求) 2. daemon(版本请参考 jenkins 需求) 3. tomcat(版本请参考 jenkins 需求) 4. 下载 jenkins deb 安装包,运行 sudo dpkg -i jenkins.deb 5. 配置 jenkins 1. 确定 jenkins 服务有没有起来,默认的端口是 8080,修改默认端口请到 /etc/default/jenkins 修改 HTTP_PORT 环境变量,修改之后记得重启。 2. 如果还是没有启动服务,请查看端口是否被占用,依赖是否都有安装。服务是否启动成功。 3. 在 /var/lib/jenkins/secrets/initialAdminPassword 中拷贝 jenkins 的初始密码进入 jenkins 管理界面。 4. 可在浏览器里面访问 http://jenkins_host:jenkins_port/jenkins/restart 重启 jenkins.
- 搭建 jenkins 持续集成平台
- 计算机原理(名词解释)
ABI (Application Binary Interface)
AL( 8bit ) + AH( 8bit ) == AX( 16bit ) == EAX( 32bit ) 累加器(Accumulator)
BL( 8bit ) + BH( 8bit ) == BX( 16bit ) == EBX( 32bit ) 基地址寄存器(Base Register)
CL( 8bit ) + CH( 8bit ) == CX( 16bit ) == ECX( 32bit ) 计数寄存器(Count Register)
DL( 8bit ) + DH( 8bit ) == DX( 16bit ) == EDX( 32bit ) 数据寄存器(Data Register)
BP( 16bit ) == EBP( 32bit ) 堆基指针 (base pointer)
SI( 16bit ) == ESI( 32bit ) 变址寄存器 ( index register )
DI( 16bit ) == EDI( 32bit ) 变址寄存器
SP( 16bit ) == ESP( 32bit ) 堆栈顶指针(stack Point)
- 一个服务器的一个端口理论支持多大连接数
答: 源地址(IPV4 /IPV6) * 源端口范围。 比如说 IPV4 有 (2^32 * 2^16 - n) 个,为什么要减 n,是因为一些专有(保留)地址和保留端口要除开。 - 如何提高一个服务器的并发
修改文件可打开数量,系统级修改file-max属性,临时修改执行命令echo "YOUR_NUMBERS" >/proc/sys/fs/file-max, 永久修改,修改/etc/sysctl.conf文件,添加一行属性fs.file-max = YOUR_NUMBERS, 修改之后最好运行网络重启/etc/rc.d/init.d/network restart或者systemctl restart NetworkManager, 具体依据你的系统而定。
如果是用户级别,则修改/etc/security/limits.conf, 具体的使用方法请参考man limits.conf中的内容。 比如限制 test 用户最大仅能打开 1000 个文件,user hard nofile 1000
进程级别修改fs.nr_open, 和修改 fs.file-max 类似
关于 fs 下的更多配置参考:Documentation/sysctl/fs.txt - 修改接收缓冲区大小
查看接受缓冲区大小:sysctl -a | grep rmem
查看发送缓冲区大小:sysctl -a | grep wmem
关于具体属性的描述请参考Documentation/sysctl/net.txt, 属性的配置方法,参考fs.file-max - 系统可配置项
sysctl -a | grep -E "tcp|net"
建议: 一般为了使 10G 的网卡能得达到全速,最大的输入输出缓冲区最好设置大小超过 16M,其中涉及的参数有net.core.rmem_max,net.core.wmem_max
启用 tcp 缓冲区自动调节tcp_moderate_rcvbuf, 其中要指定net.ipv4.tcp_rmem,net.ipv4.tcp_wmem, 如net.ipv4.tcp_rmem = 1024 65536 16777216
tcp 半开连接挤压队列大小:tcp_max_sync_backlog = 4096, accept 监听队列大小net.core.somaxconn = 1024
每 cpu 网络设备积压队列长度:net.core.netdev_max_backlog
查看支持的 tcp 阻塞控制算法:sysctl -a | grep "congestion_control“,指定算法sysctl net.ipv4.tcp_congestion_control = cubic
启用 SACK 扩展:net.ipv4.tcp_sack
启用 FACK 扩展:net.ipv4.tcp_fack
重用 TIMEWAIT 会话:net.ipv4.tcp_tw_resue, 还一个不太安全的属性net.ipv4.tcp_tw_recycle - 修改 TX 队列长度
ifconfig INTERFACE txqueuelen QUEUELEN_NUMBS - 其他优化网络性能的方法
巨型帧,如果基础网络支持的话
链路聚合,将多个物理网络接口的带宽聚合为一个接口
socket 参数调节(下面有简要介绍) - 查看活动连接数
ss -n | grep ESTAB | wc -l - 网络性能分析工具
netstat多种网络栈和接口统计信息
sssocket 统计信息
lsof统计进程打开文件
sar统计信息历史
ifconfig接口配置
ip网络接口统计信息
nicstat网络接口吞吐量和使用率
ping测试网络连通性
traceroot测试网络路由
pathchar确定网络路径特征
tcpdump网络数据包嗅探器
Wireshark图形化网络数据包检查器
DTrace / perfTCP/IP 跟踪,连接,数据包,丢包,延时
nethogs / iftop网络吞吐量
/proc/net网络信息统计文件 - 关于 socket 的设置
获取 socket 的配置可以参考man getsockopt, 设置 socket 的属性可以参考man setsockopt, 其中 linux 中支持的属性可以参考include/uapi/asm-generic/socket.h
下面是一些 SOL_SOCKET 常用属性的说明:
SO_BROADCAST设置是否允许发布广播数据,常用在 UDP 广播,多播场景
SO_DEBUG将该 socket 设置为 Debug 模式,其会记录 socket 建立时候的参数, 采用的具体协议,以及出错的代码都,记录位置
SO_DONTROUTE不查找路由
SO_ERROR获取 socket 错误信息
SO_KEEPALIVE设置保持链接属性,其中配套的可能还要设置发送心跳包的 interval 和次数。
SO_OOBINLINE带外数据放入正常数据流
SO_SNDTIMEO设置 socket 的发送超时
SO_RCVTIMEO设置 socket 的接收超时
SO_RCVBUF设置 socket 的接收缓冲区大小,如果你能快速的处理完接收的数据,而又不希望经历由系统缓冲区到 socket 缓冲区的多次拷贝影响性能,则可以把接收缓冲区设置为 0
SO_SNDBUF设置 socket 的发送缓冲区大小,如果不希望经历由系统缓冲区到 socket 缓冲区的多次拷贝影响性能,则可以把发送缓冲区设置为 0
SO_RCVLOWAT设置最低接收缓冲区
SO_SNDLOWAT设置最高接收缓冲区
SO_TYPE获取 sokcet 类型
SO_BSDCOMPAT与 BSD 兼容
SO_CONDITIONAL_ACCEPT设置为 ture 则 socket 不会主动的 accept 客户端的连接请求, 除非服务端主动调用 accept() 明确指示,参考 这里。
SO_REUSEADDR调用 closesocket 之后想重用该 socket 则对 socket 设置该选项为 ture;
SO_DONTLINGER如果想在 closesocket 之后不经历 TIMEWAIT 过程则,设置此项为 ture;
SO_LINGER, 如果想在关闭 socket 之后等待数据发送完成之后才真正关闭, 则可以将struct linger中 l_onoff 属性设置为 1,而 l_linger 属性指定等待的超时时长。 另外,如果将 l_onoff 设置为 0 则和 SO_DONTLINGER 的功能类似。
- /proc/net/snmp
- /proc/net/netstat
- 性能分析方法 USE (Utilization Saturation and Errors Method)
USE 方法为分析软件性能问题的一个重要方法,其精髓可总结成一句话:对于所有资源,查看他的使用率,饱和度和错误, 其三个维度主要是指:- Utilization 使用率: 在规定时间内,资源用于服务的时间百分比。虽然资源繁忙,但资源还是有能力接受更多的工作,不能接受更多工作则以为着资源已经达到饱和
- Saturation 饱和度:资源在一定的时间内不能接受更多的工作,通常还会有工作队列长度的限制, 因此不仅仅是要判断是否饱和度已经达到 100%,还要判断等待队列是否超出目标值
- Error 错误:错误事件个数和具体类型(通常会存在各种日志里面,或者错误计数器中)
而是使用 USE 方法分析问题的过程可参考如下流程: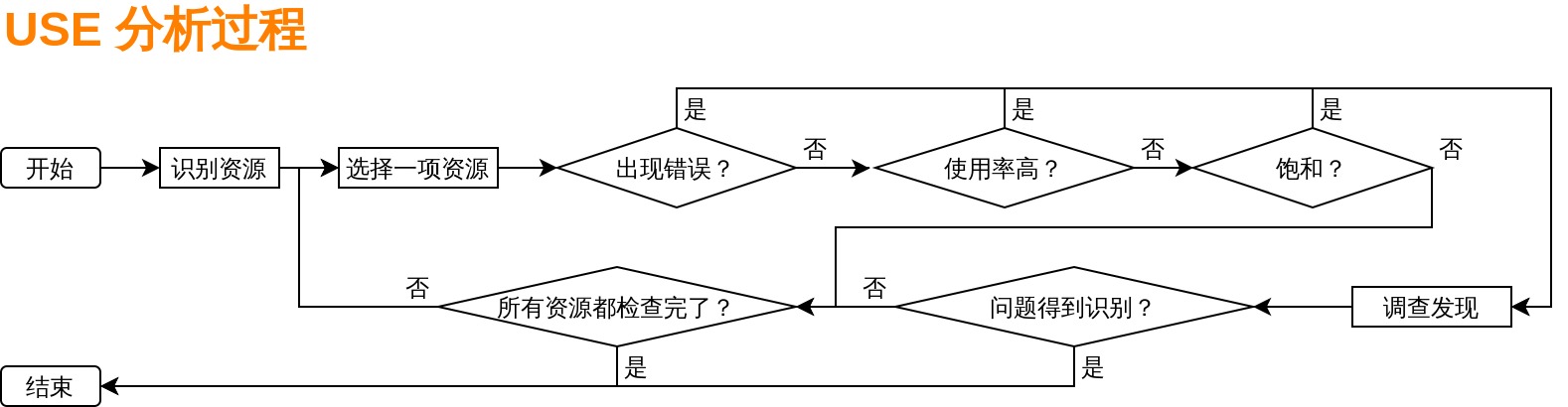
- Hash 锁
在设计程序的过程中,为了保证资源操作的一致性而给操作资源的方法加上了同一个锁,但某些资源可能因为资源本身的特性,从物理隔绝了操作, 这时我们可以引入 hash 锁,更具特性来选择性的选择 Hash Table 中的锁,从而避免不必要的程序阻塞导致的性能问题。 - AWG (American wire gauge) 线材规格
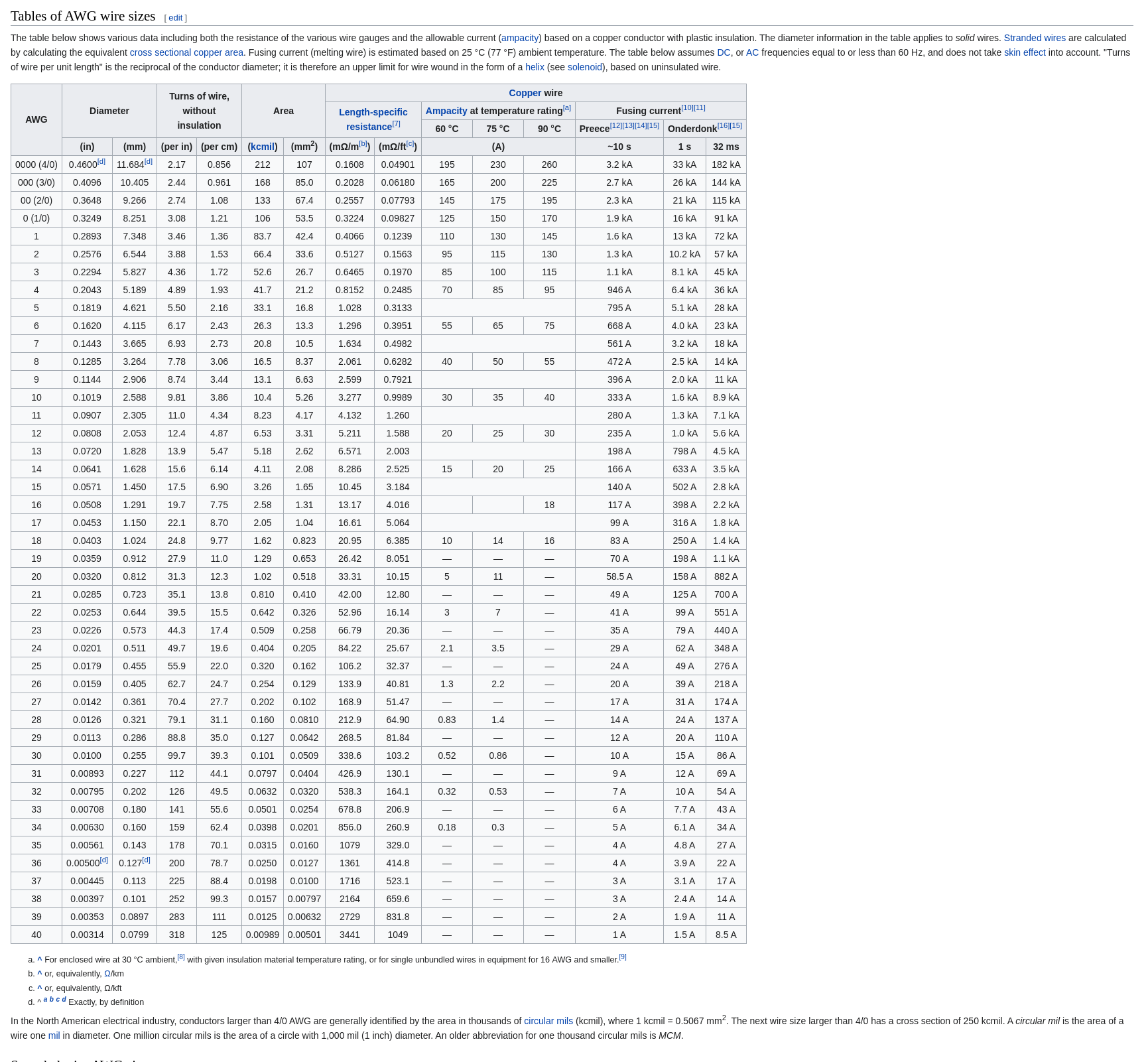
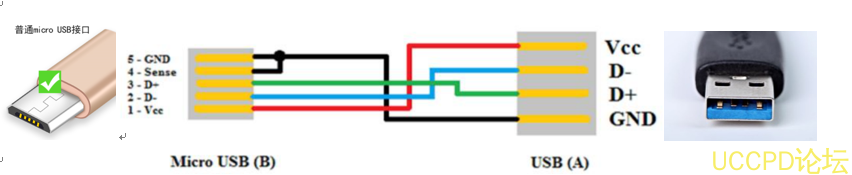
- USB 相关
- prometheus: Prometheus 受启发于 Google 的 Brogmon 监控系统(相似的 Kubernetes 是从 Google 的 Brog 系统演变而来), 从 2012 年开始由前 Google 工程师在 Soundcloud 以开源软件的形式进行研发, 并且于 2015 年早期对外发布早期版本。 2016 年 5 月继 Kubernetes 之后成为第二个正式加入 CNCF 基金会的项目, 同年 6 月正式发布 1.0 版本。2017 年底发布了基于全新存储层的 2.0 版本,能更好地与容器平台、云平台配合。 其中文的介绍可参考 https://yunlzheng.gitbook.io/prometheus-book/introduction
- [PROTAL1]FFMPEG视音频编解码零基础学习方法
- [PROTAL2]FFmpeg发送流媒体的命令(UDP,RTP,RTMP)
- [PROTAL3]使用curl指令測試REST服務
- [link]Sphinx 如何修改主题格式
- [PROTAL1]ARM MMU工作原理剖析
- systemd.service 中文手册
- systemd使用配置教程
- FFMPEG常用命令持续更新
- USB、PCI、SATA等各接口速度/带宽总结
- The Linux Document Project
- Linux HOWTOs: The Linux HOWTOs are detailed "how to" documents on specific subjects. The HOWTO index lists all HOWTOs along with short descriptions. The HOWTOs are written in SGML or XML, and translated to different output formats using SGML-Tools (Linuxdoc DTD) or the DocBook/DSSSL tools. Join the LDP announcements mailing list for news on HOWTO updates.
- NAND Flash基础知识简介
- [link]23 种设计模式
- [link]Scrum 敏捷开发
- [link]为Linux应用构造有限状态机(ps: 比较详细的介绍了有限状态机,也就是有限自动机的定义,原理,以及有限状态机应该具备的要素,还有就是详细的介绍了如何使用 linux 下的 FSME 来构建有限状态机,以及自动生成 c++ 代码,当然这个工具也能自动生成 python 代码。)
- [link]敏捷开发中的持续集成
- 网友总结的关于 Linux 系统层面需要知道的一些基本知识(其他章节有补充其他方面的知识)
- SpaceVim 一个 vim 的社区发布版本
- vim help 选项使用说明
-a, --all
相当于 -h -l -S -s -r -d -V -A -I 的集合-h, --file-header
显示 ELF 文件开始的文件头信息-l, --program-headers, --segments
显示 segments(段)头信息-S, --section-headers, --sections
显示 section 头信息-g, --section-groups
显示 section 的组信息-t, --section-details
显示 section 详细信息-e, --headers
显示全部头信息,相当于 -h -l -S-s, --syms, --symbols
包含静态符号表信息,显示符号表节信息,包含静态符号表信息.symtab,和动态符号表信息.dynsym。
如果只关心动态符号表可以直接使用--dyn-syms
如果符号有相应的版本信息,则会显示该版本信息
版本字符串显示为符号名称的后缀,并以 @ 字符开头,例如foo@Ver_1
在解析未版本化引用的符号时,如果该版本是要使用的默认版本,则将显示为后缀,其后跟两个--dyn-syms
显示文件的动态符号表部分中的条目(如果有)。输出格式与 --syms 选项使用的格式相同。--lto-syms
显示文件中任何 LTO 符号表的内容。输出格式与 --syms 选项使用的格式相同。--sym-base=[0, 8, 10, 16]
强制符号表的大小字段使用给定的基数。
任何无法识别的选项都将被视为“0”。
--sym-base=0 代表默认和旧的行为。 对于小于 100000 的数字,这会将大小输出为十进制。 对于大小 100000 和更大的十六进制符号,将使用 0x 前缀。
--sym-base=8 将以八进制给出符号大小。 --sym-base=10 将始终以十进制给出符号大小。 --sym-base=16 将始终以带有 0x 前缀的十六进制给出符号大小。--demangle=style, --no-demangle
将低级符号名称解码(解码)为用户级名称。 这使得 C++ 函数名称可读。 不同的编译器有不同的修饰风格。 可选的 demangling 样式参数可用于为您的编译器选择合适的 demangling 样式。
参见 c++filt ,了解更多关于 demangling 的信息。--quiet
禁止 “no symbols” 诊断。--recurse-limit, --no-recurse-limit, --recursion-limit, --no-recursion-limit
启用或禁用在对字符串进行分解时执行的递归量的限制。 由于名称修饰格式允许无限级别的递归,因此可以创建字符串,其解码将耗尽主机上可用的堆栈空间量,从而触发内存故障。 该限制试图通过将递归限制为 2048 级嵌套来防止这种情况发生。
默认情况下启用此限制,但可能需要禁用它才能解开真正复杂的名称。 但是请注意,如果禁用递归限制,则可能会耗尽堆栈,并且任何有关此类事件的错误报告都将被拒绝。-U [d|i|l|e|x|h]或者--unicode=[default|invalid|locale|escape|hex|highlight]
控制标识符名称中非 ASCII 字符的显示。 默认(--unicode=locale 或--unicode=default)是将它们视为多字节字符并在当前语言环境中显示它们。
此选项的所有其他版本将字节视为 UTF-8 编码值并尝试解释它们。 如果它们无法被解释或者如果使用了 --unicode=invalid 选项,那么它们将显示为十六进制字节序列,并用花括号括起来。
使用 --unicode=escape 选项会将字符显示为 unicode 转义序列 (\uxxxx)。 使用 --unicode=hex 会将字符显示为用尖括号括起来的十六进制字节序列。
使用 --unicode=highlight 会将字符显示为 unicode 转义序列,但它也会以红色突出显示它们,假设输出设备支持着色。 着色旨在提醒人们注意可能不存在的 unicode 序列。
-n, --notes
显示 NOTE 段和/或部分的内容(如果有)。-r, --relocs
显示文件的重定位部分的内容(如果有的话)。-u, --unwind
显示文件展开部分的内容(如果有)。
当前仅支持 IA64 ELF 文件的展开部分以及 ARM 展开表 (.ARM.exidx / .ARM.extab)。 如果您的架构尚未实现支持,您可以尝试使用 --debug-dump=frames 或 --debug-dump=frames-interp 选项转储 .eh_frames 部分的内容。-d, --dynamic
显示文件的动态部分的内容(如果有的话)。-V, --version-info
显示文件中版本部分的内容,(如果它们存在的话)。-A, --arch-specific
显示文件中特定于体系结构的信息(如果有)。-D, --use-dynamic
显示符号时,此选项使 readelf 使用文件动态部分中的符号哈希表,而不是符号表部分。
显示重定位时,此选项使 readelf 显示动态重定位而不是静态重定位。-L, --lint, --enable-checks
显示有关正在检查的文件可能存在问题的警告消息。 如果单独使用,则将检查文件的所有内容。 如果与转储选项之一一起使用,则只会为正在显示的内容生成警告消息。-x <number or name>, --hex-dump=<number or name>
将指定部分的内容显示为十六进制字节。编号通过节表中的索引标识特定节;任何其他字符串标识目标文件中具有该名称的所有部分。-p <number or name>, --string-dump=<number or name>
将指定部分的内容显示为可打印字符串。编号通过节表中的索引标识特定节;任何其他字符串标识目标文件中具有该名称的所有部分。-R <number or name>, --relocated-dump=<number or name>
将指定部分的内容显示为十六进制字节。 编号通过节表中的索引标识特定节; 任何其他字符串标识目标文件中具有该名称的所有部分。 该部分的内容将在显示之前重新定位。-z, --decompress
请求由 x、R 或 p 选项转储的部分在显示之前解压缩。如果部分未压缩,则它们按原样显示。-c, --archive-index
显示包含在二进制归档文件头部分的文件符号索引信息。执行与 ar 的 t 命令相同的功能,但不使用 BFD 库。见 ar。-w[lLiaprmfFsoORtUuTgAck]或者--debug-dump[=rawline,=decodedline,=info,=abbrev,=pubnames,=aranges,=macro,=frames,=frames-interp,=str,=str-offsets,=loc,=Ranges,=pubtypes,=trace_info,=trace_abbrev,=trace_aranges,=gdb_index,=addr,=cu_index,=links]
显示文件中 DWARF 调试部分的内容(如果存在)。 压缩的调试部分在显示之前会自动(临时)解压缩。 如果开关后面有一个或多个可选字母或单词,则只会转储那些类型的数据。 字母和单词指的是以下信息:a,=abbrev
显示 “.debug_abbrev” 部分的内容。A,=addr
显示 “.debug_addr” 部分的内容。c,=cu_index
显示 “.debug_cu_index” 和/或 “.debug_tu_index” 部分的内容。f,=frames
显示 “.debug_frame” 部分的原始内容。F,=frames-interp
显示 “.debug_frame” 部分的解释内容。g,=gdb_index
显示 “.gdb_index” 和/或 “.debug_names” 部分的内容。i,=info
显示 “.debug_info” 部分的内容。 注意:此选项的输出也可以通过使用 --dwarf-depth 和 --dwarf-start 选项来限制。k,=links
显示 “.gnu_debuglink”、 “.gnu_debugaltlink” 和 “.debug_sup” 部分的内容(如果存在)。 如果它们由 “.debug_info” 部分中的 DW_AT_GNU_dwo_name 或 DW_AT_dwo_name 属性指定,还显示指向单独的 dwarf 对象文件 (dwo) 的任何链接。K,=follow-links
显示在链接的单独调试信息文件中找到的任何选定调试部分的内容。 如果同一调试部分存在于多个文件中,这可能会导致显示多个版本。
另外,在显示 DWARF 属性时,如果发现表单引用了单独的调试信息文件,那么也会显示引用的内容。
注意 - 在某些发行版中,此选项默认启用。 它可以通过 N 调试选项禁用。 通过 --enable-follow-debug-links=yes 或 --enable-follow-debug-links=no 选项配置 binutils 时可以选择默认值。 如果不使用这些,则默认启用以下调试链接。N,=no-follow-links
禁用以下链接到单独的调试信息文件。l,=rawline
以原始格式显示“.debug_line”部分的内容。L,=decodedline
显示 “.debug_line” 部分的解释内容。m,=macro
显示 “.debug_macro” 和/或 “.debug_macinfo” 部分的内容。o,=loc
显示 “.debug_loc” 和/或 “.debug_loclists” 部分的内容。O,=str-offsets
显示 “.debug_str_offsets” 部分的内容。p,=pubnames
显示 “.debug_pubnames” 和/或 “.debug_gnu_pubnames” 部分的内容。r,=aranges
显示 “.debug_aranges” 部分的内容。R,=Ranges
显示 “.debug_ranges” 和/或 “.debug_rnglists” 部分的内容。s,=str
显示 “.debug_str”、“.debug_line_str” 和/或 “.debug_str_offsets” 部分的内容。t,=pubtype
显示 “.debug_pubtypes” 和/或 “.debug_gnu_pubtypes” 部分的内容。T,=trace_aranges
显示 “.trace_aranges” 部分的内容。u,=trace_abbrev
显示 “.trace_abbrev” 部分的内容。U,=trace_info
显示 “.trace_info” 部N分的内容。
注意:目前并不是所有平台都支持上面的这些指令。-P, --process-links
显示在链接到主文件的单独 debuginfo 文件中找到非调试部分的内容。此选项自动带 -wK 选项,并且仅显示其他命令行选项请求的部分。--dwarf-depth=n
将 .debug_info 部分的转储限制为 n 个子项。 这仅对 --debug-dump=info 有用。 默认打印所有DIE; n 的特殊值 0 也会产生这种效果。
如果 n 为非零值,则不会打印 n 级或更深的 DIE。 n 的范围是从零开始的。--dwarf-start=n
仅打印以编号为 n 的 DIE 开头的 DIE。 这仅对 --debug-dump=info 有用。
如果指定,此选项将禁止打印任何标题信息和编号为 n 的 DIE 之前的所有 DIE。 只会打印指定 DIE 的兄弟姐妹和孩子。
这可以与 --dwarf-depth 结合使用。--ctf=section
显示指定 CTF 节的内容。 CTF 部分本身包含许多子部分,所有子部分都按顺序显示。
默认情况下,显示名为 .ctf 的部分的名称,即 ld 发出的名称。--ctf-parent=section
如果 CTF 部分包含模糊定义的类型,它将包含许多 CTF 字典的存档,所有字典都继承自一个包含明确类型的字典。
该成员默认命名为 .ctf,就像包含它的部分一样,但可以在链接时使用 ctf_link_set_memb_name_changer 函数更改此名称。
当查看由使用名称更改器重命名父存档成员的链接器创建的 CTF 存档时,--ctf-parent 可用于指定用于父存档的名称。--ctf-symbols=sectionand--ctf-strings=section
指定 CTF 文件可以从中继承字符串和符号的另一个节的名称。 默认情况下,使用 .symtab 及其链接字符串表。
如果指定了 --ctf-symbols 或 --ctf-strings 中的任何一个,则还必须指定另一个。-I, --histogram
在显示符号表的内容时显示桶列表长度的直方图。-v, --version
显示 readelf 的版本号。-W, --wide
不要打破输出行以适应 80 列。 默认情况下,readelf 会中断 64 位 ELF 文件的节标题和段列表行,以便它们适合 80 列。 此选项使 readelf 分别打印每个节标题。 每个段都是单行,在超过 80 列的终端上可读性更高。-T, --silent-truncation
通常,当 readelf 显示符号名称时,它必须截断名称以适应 80 列显示,它会在名称中添加 [...] 的后缀。 此命令行选项禁用此行为,允许再显示 5 个名称的字符并恢复 readelf 的旧行为(发布 2.35 之前)。-H, --help
help info
ReactiveX 是一个库,用于通过使用可观察的序列来组成异步和基于事件的程序。支持的语言有 JAVA, C++, Python, PHP, JS, Net, Scale, Switft ...., 请参考 http://reactivex.io/languages.html
ReactiveX 大致的可以从 Observer, Operation, Single, Subject, Scheduler 这几个方面进行阐述。
- 浅拷贝
result = Object.assign({},target)
- 构建 Go 项目工程骨架
#!/usr/bin/env bash if [ "$1" = "" ]; then echo "Please input project name" exit -1 fi if [ -f $1 ] || [ -d $1 ]; then echo "File ( directory ) aready exist, please try another name" exit -1 fi mkdir $1 cd $1 echo "dir: pkg 共有依赖存放目录" mkdir pkg echo "dir: internal/pkg 私有依赖存放目录" mkdir -p internal/pkg echo "dir: internal/app 私有代码存放目录" mkdir -p internal/app echo "dir: cmd 可执行文件存放目录" mkdir -p cmd echo "dir: api 对外 API 接口定义文件存放目录" mkdir -p api echo "dir: scripts 工具脚本存放目录" mkdir -p scripts echo "dir: tests 测试代码存放目录" mkdir -p tests echo "dir: examples 事例代码存放目录" mkdir -p examples echo "dir: configs 配置文件存放目录" mkdir -p configs echo "dir: docs 工程文档存放目录" mkdir -p docs echo "dir: assets 工程依赖物料(图片,配置,...)存放目录" mkdir -p assets echo "dir: tools 辅助开发工具存放目录" mkdir -p tools echo "file: Makefile" touch Makefile echo "file: README.md" touch README.md
- How To Install Go on Ubuntu 18.04
- Go wiki
- Go 语言设计与实现
- 如何写出优雅的 Go 语言代码
- golang-standards / project-layout
- golang / mock
- DATA-DOG / go-sqlmock
- jarcoal / httpmock
- bouk / monkey
- stretchr / testify
- [LINK1]Gcc 中文手册(英文手册直接 man,非 Linux 用户自己去 google ),这个中文手册不健全,仅当参考
- [LINK2]C++静态库与动态库
- [LINK3]30分钟了解C++11新特性(注:该片文章下面还有到其他 C++11 介绍的传送门)
- [LINK4]C++开发者都应该使用的10个C++11特性
- [LINK5](转载)GUN gcc 中文手册
- [LINK6]Cmake 学习笔记(1)
- [LINK7]CMake 学习笔记(2)
- [LINK8]CMake 官方文档
- ReactiveX
- openssl 编译安装指南
- openssl 编译安装指南2
- Openssl 如何实现硬件加速
请等待更新...
- 常见库的数据类型定义
- stdlib.h
system()
- unistd.h
sleep()
- fcntl.h
O_RDWR O_CREATE ... - sys/stat.h
mkfifo
- inttypes.h
// 包含定义的数据类型 int8_t int16_t int32_t int64_t uint8_t uint16_t uint32_t uint64_t
- stdlib.h
- BLAS
libcurl 交叉编译
选择合适的 libcurl 版本 下载,解压之后,将以下的代码复制到 build.sh 中,更具自己的需求修改成自己的配置,然后执行 make -f build.sh 即可。
include ../../env.mk CONF_OPTION += --with-mbedtls=${MBEDTLS_INSTALL_PATH} all: config build config:export CROSS_COMPILE=mipsel-linux config:export ROOTDIR=$(DEPENDS_DIR) config:export PKG_CONFIG_PATH=$(ROOTDIR)/lib/pkgconfig config:export CPPFLAGS=-I${ROOTDIR}/include config:export LDFLAGS=-L${ROOTDIR}/lib config:export LIBS=-lmbedtls -lmbedx509 -lmbedcrypto config: configure --prefix=${ROOTDIR} --host=mipsel-linux $(CONF_OPTION) build:export CROSS_COMPILE=mipsel-linux build:export ROOTDIR=$(DEPENDS_DIR) build:export PKG_CONFIG_PATH=$(ROOTDIR)/lib/pkgconfig build:export CPPFLAGS=-I${ROOTDIR}/include build:export LDFLAGS=-L${ROOTDIR}/lib build:export LIBS=-lmbedtls -lmbedx509 -lmbedcrypto build:export AR=${CROSS_COMPILE}-ar build:export AS=${CROSS_COMPILE}-as build:export LD=${CROSS_COMPILE}-ld build:export RANLIB=${CROSS_COMPILE}-ranlib build:export CC=${CROSS_COMPILE}-gcc build:export NM=${CROSS_COMPILE}-nm build:export PKGCONFIG=${CROSS_COMPILE}-pkg-config build: make make install
crypto, ffrtmpcrypt, ffrtmphttp, file, gopher, hls, http, httpproxy, https, icecast, mmsh, mmst, md5, pipe, rtmp, rtmpe, rtmps, rtmpt, rtmpte, rtmpts, rtp, srtp, tcp, tls, udp, unix
- 打开输入文件
avconv.c ( main ), -->avconv_opt.c ( avconv_parse_options ), -->avconv_opt.c ( open_files ), -->avconv_opt.c ( open_input_file ), -->libavformat/utils.c ( avformat_open_input ), -->libavformat/utils.c ( init_input ), -->libavformat/utils.c( AVFormatContext->io_open ) == libavformat/options.c ( io_open_default ), -->libavformat/aviobuf.c ( avio_open2 ), -->libavformat/avio.c ( ffurl_open ), -->libavformat/avio.c ( ffurl_connect ),
- 这里只介绍 ubuntu 上的安装,如果想在 docker, mac ... 请查看
- .
- 安装 gcc, g++, python
caffe是主要是C/C++和Python编写的。所以需要先把 gcc, g++, python 安装好。
- 安装 cuda
- 安装 caffe 其他依赖
- opencv
- caffe 安装编译配置
docker attach container_name 登陆 docker 的容器后,怎么退出勒?我们可以用 ctrl + d, 但是这种方法会导致容器内部运行的工作都停止,因此,这里还介绍另外一种方法:Ctrl + p -> Ctrl + q。
- 监听端口
如需要修改 apache 的监听端口,可在
/etc/apache2/ports.conf中配置,语法为Listen port_num (such as: Listen 8080)。 - IfDefine & IfModule
Apache 允许使用 IfDefine 以及 IfModule 指令来快速而且更容易的更改配置。IfDefine 标签允许在命令行中使用某个标志来指定 IfDefine 内的配置选项否出于启用状态, IfModuole 标签具有类似的效果,其作用是先检查当前模块是否已经加载,若已经加载,则标签中的配置有效,若没有加载,则标签中的配置无效。
- 反向代理
个人理解反向代理及将接收到的请求分发给在其他可访问到的服务器,方便实现服务器的负载均衡,也可减少主服务器的压力。详细概念在这里就不再赘述了,请参考参考文档。这里只是记录一下自己在搭建反向代理中需要主要的一些问题。
1. 以集群域名创建的 upstream 对象应该放在 html 对象下; 2. 在 server 对象中设置目录反向代理的 proxy_pass 成员时,一个目录只能设置一个 proxy_pass; 3. proxy_pass 的参数为 upstream 对象的名字; 4. 如果你为 /abc/ 目录指定了反向代理服务器 www.test.com ,那么在 www.test.com 这个服务器集群的跟目录下一定要有 abc 这个文件夹。 5. /etc/nginx/site-avaliable 目录下只是可以用来配置的服务,启动 nginx 时真正引用的是 /etc/nginx/site-enabled 目录下的配置文件(apache2 也一样)。
- npm 报告 https://registry.npmjs.org/ 访问不到
可替换成谷内的源,比如在使用 npm 的时候可以这样使用npm install xxx --registry=https://registry.npm.taobao.org
或者你可以直接将 taobao 的源配置到当前用户,如npm config set registry https://registry.npm.taobao.org
如果想使用默认的则使用如下指令删除即可:npm config delete registry
配置之后可以通过如下指令来验证:npm config get registry或者npm info express - npm 如何检测一个包是否安装
运行npm ls ${PACKAGE}或者npm ls -g ${PACKAGE}, 然后用 $? 判断是否成功安装
LDAP 是一个开放的,中立的,工业标准的应用协议,通过IP协议提供访问控制和维护分布式信息的目录信息。LDAP的一个常用用途是单点登录,用户可以在多个服务中使用同一个密码,通常用于公司内部网站的登录中(这样他们可以在公司电脑上登入一次,便可以自动在公司内部网上登入)。
- LDAP特点
- LDAP的结构用树来表示,而不是用表格。正因为这样,就不能用SQL语句了
- LDAP可以很快地得到查询结果,不过在写方面,就慢得多
- LDAP提供了静态数据的快速查询方式
- Client/server模型,Server 用于存储数据,Client提供操作目录信息树的工具
- 这些工具可以将数据库的内容以文本格式(LDAP 数据交换格式,LDIF)呈现在您的面前
- LDAP是一种开放Internet标准,LDAP协议是跨平台的Interent协议
- 需要了解的知识点
增删改查,条目(Entry),属性(Attribute),schema,对象类(ObjectClass),必要属性(Must, Required),可选属性(May, Optional), 对象的三种类型结构类型(Structural)抽象类型(Abstract)辅助类型(Auxiliary),slapd,backends,database,openldap,bdb,TLS & SASL,LDIF。schema 一般在
/etc/ldap/schema/目录。它一般由条目、属性和值组成,这些成员又由对象类(ObjectClass)、属性类型(AttributeType)、语法(Syntax)来限制。 - 安装步骤
这里只介绍在 ubuntu 下的安装,以及配置过程中出现的问题,主要是参考 [6] 来搭建的,为了更好的阅读体验,建议读者直接产看 [6] 的安装步骤,如果遇到什么问题,再回头看看,这里是否有解决方法,或者思路。
// 安装 openldap apt-get install sladp ldap-utils openldap-utils phpldapadmin apache2 // apache2 主要是来做做 phpldapadmin 的 web 服务器的。 // 安装过程中会提示输入admin密码 // 从 2.4.x 版本开始 slapd.conf 配置形式官方已经废弃了但如果要用还是可以的,需要在 /etc/default/slapd 中指定 slapd.conf 配置文档路径, // 其中 SLAPD_CONF= 这个全局命令即是配置项目, 可以用一下命令配置你的 slapd.conf 所在的路径。 sed 's#SLAPD_CONF=#&/home/username/.config/slapd.conf#' -i /etc/default/slapd // 如果在想把你的 slapd.conf 转换成 slapd.d 配置目录的形式可以用以下命令,(注意用以下命令前先备份原始目录) slaptest -f /home/username/.config/slapd.conf -F /etc/ldap/slapd.d/ chown -R openldap:openldap /etc/ldap/slapd.d/ // 我们这个例子中使用默认的 slapd.d 配置目录的形式 // 如果需要重新配置 slapd 可以运行以下命令,需要管理员权限 dpkg-reconfigure slapd // 具体的配置过程中应该怎么选择可以参考 [6] // 需要注意的是,我在 docker 中搭建的 ldap, 用的是 ubuntu 1604,需要注意的是每次我调用 /etc/init.d/slapd restart 之后 ldap 都 fail // 用 ps 查看之后发现 slapd 并没有在 stop 的时候真正退出,因此当我重新配置了 slapd.d 之后我都会执行 ps -aux > /tmp/ps; cat /tmp/ps | grep "/usr/sbin/slapd" | awk '{print $2}' | xargs kill -9; /etc/ini.d/slapd start // 需要注意的是 https 搭建好之后,用浏览器打开会遇到网站安全性方面的问题,但不用担心,因为在这个例子中,网站的证书是我们自己颁发的。直接信任就可以了。 // 需要注意的是 /etc/ldap/slapd.d 下配置 (或用 dpkg-reconfigure 重新配置的)的用户名最好与 phpldapadmin 中的 servers->base, servers->bind_id 保持一致。 // 如果你的用户名是 admin 域名是 test.com 的话,需要修改 /etc/phpldapadmin/config.php 中的内容,如下: $servers->setValue('server','base',array('dc=test,dc=com')); $servers->setValue('login','bind_id','cn=admin,dc=test,dc=com'); // 创建 ssl 证书以及配置 apache2 支持 https 这个都比较容易,这里就不用再赘述了。
- [0]openldap 官网
- [1]LDAP 维基百科
- [2]LDAP服务器的概念和原理简单介绍 -- segmentfault
- [3]LDAP服务器的搭建 -- csdn
- [4]LDIF修改ldap记录或配置示例
- [5]OpenLDAP(2.4.3x)服务器搭建及配置说明
- [6]如何在Ubuntu 14.04服务器上配置并安装OpenLDAP和phpLDAPadmin
- [7]如何在Ubuntu 12.04 VPS上安装和配置基本LDAP服务器
- [8]OpenLdap 简易教程
- [9]Linux/UNIX OpenLDAP实战指南
- [10]Installation instructions
- [11]caffe 安装
- [12]cuda 安装
- [13]nodejs & npm 安装
- [14]nodejs 中文网站
- [15]nodejs 官方网站
- [16]mongoose 官方网站(文档)
Chart.js 官网: https://www.chartjs.org
- 关闭动效
在配置的时候将options.animation.duration设置成 0 即可 - 如歌更新
首先替换数据集myChart.data.datasets = [{...},{...}], 然后再调用 myChart.update()
- bootstrap 的图形库
- searxsearX 是一个开源的搜索引擎,汇总来自70多个搜索服务(包括谷歌)的结果,不跟踪也不分析用户。使用时,需要自己架设实例。这个网站列出了世界各地现有的实例,以及访问速度的实时统计。
- 在线工具秘籍 -- 这个中文仓库收集各种好用的在线小工具。
- Moment.js JavaScript 日期处理类库
- visxAirBnb 开源的一套可视化组建库
- [link_1]关于寻路算法的一些思考1
名词解释:
Dijkstra单元最短路径算法的一种,思想就是从起始点开始,层层遍历与之相近的节点,直到搜索到目标节点,终止搜索过程。其中经常与这个算法一并提起的还有Floyd 算法,『最短路径—Dijkstra算法和Floyd算法』 这篇文章有两个算法的简单对比。贪心最优优先搜索(greedy best first search):针对目标节点,给出一个估计方位(启发值),在搜索开始时选取偏向目标的节点优先搜索,直到发现目标节点,终止搜索。详细说明可以[link_1],里面有详细的图解。A*算法结合了贪心最好优先搜索算法和Dijsktra算法的优点。A*算法不仅拥有发式算法的快速,同时,A*算法建立在启发式之上,能够保证在启发值无法保证最优的情况下,生成确定的最短路径。
- [link_1]关于寻路算法的一些思考2
- [link_1]关于寻路算法的一些思考3
- [link_1]关于寻路算法的一些思考4
- [link_1]关于寻路算法的一些思考5
- [link_1]关于寻路算法的一些思考6
- [link_1]关于寻路算法的一些思考7
- [link_1]关于寻路算法的一些思考8
- [link_1]关于寻路算法的一些思考9
- [link_1]关于寻路算法的一些思考10
- [link_1]关于寻路算法的一些思考11
- [link_1]关于寻路算法的一些思考12
- [link_1_Attachments]Map representations
- [link_1_Attachments]Grids and Graphs
- [link_1_Attachments]Amit’s Thoughts on Grids
停止更新,停止更新,停止更新(重要的事情说三遍)。这个课程已经学完,开始的时候自己英语还有点问题,但到后面专业词汇也都熟悉了,感觉没那么难了。总的来说吴恩达讲的还是很生动易懂的,因此也就没觉得必要记录了。相比较而言以后还是记录一些调参的心得吧!
- 梯度下降算法
下面是基于 Andrew NG's ML 视频示例中的公式实现的代码,需要注意的是,根据输入参数要特别小心的选择 Alpha 的值, 初始化 Theta0 和 Theta1 的值, 同时 Alpha 的选择会影响最终收敛的速度,所以 Count 可能也会需要相应的改变。
alpha=0.01 theta_0 = 0 theta_1 = 0 dataSet0 = [ [3,4], [2,1], [4,3], [0,1] ] dataSet1 = [ [1,0.5], [2,1], [4,2], [0,0] ] dataSet2 = [ [1,-890], [2,-1411], [2,-1560], [3,-2220], [3,-2091], [4,-2878], [5,-3537], [6,-3268], [6,-3920], [6,-4163], [8,-5471], [10,-5157], ] predictX = 2 def gradient_convergence( theta0, theta1, dataSet ): m = len( dataSet ) tvTheta0MinusSum = 0 tvTheta1MinusSum = 0 for v in dataSet: # print( "k=",v[0], " v=" ,v[1]) tvTheta0MinusSum += theta0 + theta1*v[0] - v[1] tvTheta1MinusSum += ( theta0 + theta1*v[0] - v[1] ) * v[0] # print( "tvTheta0MinusSum = ", tvTheta0MinusSum, "tvTheta1MinusSum = ", tvTheta1MinusSum ) tvTheta0 = theta0 - tvTheta0MinusSum * alpha / m tvTheta1 = theta1 - tvTheta1MinusSum * alpha / m # print( "newTheta0=", tvTheta0, "newTheta1=", tvTheta1 ) # predictY = tvTheta0 + predictX*tvTheta1 # print( "predictY=", predictY ) # time.sleep(2) return tvTheta0, tvTheta1 count = 0 while count < 10000: count += 1 # theta_0, theta_1 = gradient_convergence( theta_0, theta_1, dataSet0) # theta_0, theta_1 = gradient_convergence( theta_0, theta_1, dataSet1) theta_0, theta_1 = gradient_convergence( theta_0, theta_1, dataSet2) print( "newTheta0=", theta_0, "newTheta1=", theta_1 ) - octave 求 dataset 的 costfunction
X 为因的集合,Y 为果的集合,theta 为线性参量,J 为成本果与线性函数的平均离差平方和。
function J = computeCost(X, y, theta) m = length(y); % J=sum( ( X * theta - y ) .^ 2 ) / ( 2 * m ); J = (X * theta - y)' * (X * theta - y )/m/2; end - octave 梯度下降法求拟合度最大的线性参量
X 为因的集合,Y 为果的集合,theta 为线性参量,alpha 为梯度下降的速度权重,num_iters 迭代次数,J_history 梯度下降时每次的期望与实际结果的鸿沟宽度。
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters) m = length(y); % number of training examples J_history = zeros(num_iters, 1); for iter = 1:num_iters theta = theta - ( alpha / m ) .* ( X' * ( X * theta - y )); J_history(iter) = computeCostMulti(X, y, theta); end end - octave 其矩阵各个元素的归一化值。
X m * n 的矩阵,mean 针对 X 中的每一列求平均值,std 求 X 每一列的标准差。
X_normal = (X-mean(X))/std(X); - octave 利用正规方程求预测线性函数各参量的精确解。
theta = pinv(X'*X) * X' * y;
- [link]二叉堆【1】(PS:图文分析, C 实现)
- [link]二叉堆【2】(PS:C++ 实现)
- [link]二叉堆【3】(PS:JAVA 实现)
- [link]左倾堆【1】(PS:图文分析, C 实现)
- [link]左倾堆【2】(PS:C++ 实现)
- [link]左倾堆【3】(PS:JAVA 实现)
- [link]斜堆【1】(PS:图文分析, C 实现)
- [link]斜堆【2】(PS:C++ 实现)
- [link]斜堆【3】(PS:JAVA 实现)
- [link]二项堆【1】(PS:图文分析, C 实现)
- [link]二项堆【2】(PS:C++ 实现)
- [link]二项堆【3】(PS:JAVA 实现)
- [link]斐波那契堆【1】(PS:图文分析, C 实现)
- [link]斐波那契堆【2】(PS:C++ 实现)
- [link]斐波那契堆【3】(PS:JAVA 实现)
- [link]BP神经网络模型与学习算法(PS:先读读这个入门)
- [link]脉络清晰的BP神经网络讲解,赞(PS:然后再读读这个梳理一下逻辑,加深一下理解,这个人写的其他东西也可看看,很多干货)
- [link]神经网络编程入门(PS:可以开始在 Matlab 上演练演练了)
- [link]传统激活函数、脑神经元激活频率研究、稀疏激活性(PS:写这货的人也是个牛人,博客里面其他的东西都可以看看)
- [link]HTK 隐马尔可夫模型工具包
- [link]声纹识别,听声辨人(注:对语音识别方面的一些理解)
- [link]中国科学院语言声学与内容理解重点实验室
- [link]高斯混合模型(声纹识别)
- [link]文本无关的声纹识别 验证
- [link]开源的声纹识别
- [link]CodeForge 声纹识别源代码
- [link]几个常见的语音交互平台的简介和比较
- [link]中文普通话拼音全集
- [link]ALIZE
- [link]RASR
- [link]Ekho 中文文本转语音引擎
- [link]Audacity 官网
- [link]Audacity 教程
- [link]人工智能中的常用搜索策略(衡量一个搜索策略的好坏,我们需要从四个方面对其进行判断:完备性、时间复杂度、空间复杂度和最优性)
- 缓冲区溢出 是针对程序设计缺陷,向程序输入缓冲区写入使之溢出的内容(通常是超过缓冲区能保存的最大数据量的数据),从而破坏程序运行、趁著中断之际并获取程序乃至系统的控制权。 传送门
- 内存泄露 是指申请了内存资源之后忘记释放,或者释放失败,从而导致内存泄露,其他程序不能申请该内存,也使用不了, 传送门
- 差一错误 是在计数时由于边界条件判断失误导致结果多了一或少了一的错误,通常指计算机编程中循环多了一次或者少了一次的程序错误,属于逻辑错误的一种。 传送门
- Secure Programming HOWTO - Creating Secure Software 传送门
- Android 官方安全文档 1 (最佳实践都在其中) 传送门
- Android 官方安全文档 2 (最佳实践都在其中) 传送门
- Blacklight 用于检查网站跟踪用户使用到的种类
为什么要写测试: 1. 保证代码的稳定性,在后期重构代码的时候知道输入的范围,输入对应的输出是什么,输入错误会发生什么事。 2. 保证和外界代码交互的稳定性。 3. 侧面验证设备的稳定性,如果代码不变,但是在不同机器上跑出了不同的测试结果,要么是测试样例设计不完善,要么是机器环境产生了未知的 Bug。
首先,在我们隔离了待测试方法中一些依赖之后,当函数的入参确定时,就应该得到期望的返回值。 如何控制待测试方法中依赖的模块是写单元测试时至关重要的,控制依赖也就是对目标函数的依赖进行 Mock 消灭不确定性,为了减少每一个单元测试的复杂度,我们需要: 1)尽可能减少目标方法的依赖,让目标方法只依赖必要的模块;2)依赖的模块也应该非常容易地进行 Mock;
单元测试的执行不应该依赖于任何的外部模块,无论是调用外部的 HTTP 请求还是数据库中的数据,我们都应该想尽办法模拟可能出现的情况,因为单元测试不是集成测试的, 它的运行不应该依赖除项目代码外的其他任何系统。
第一步,在 Gradle 工程中配置依赖,如下:
// 在 Mudule 的 build.gradle 中添加
dependencies {
testImplementation 'junit:junit:4.12'
}
假设我们有一个待测试类如下:
package com.example.test.junit;
public class Fibonacci {
public static int compute(int n) {
int result = 0;
if (n <= 1) {
result = n;
} else {
result = compute(n - 1) + compute(n - 2);
}
return result;
}
}
然后创建该类的测试类,此处有两个方法。方法一:右击类名 -> Goto -> Test -> 选择目标测试工具,以及默认要生成的测试方法 -> 选择保存测试类的路径 -> 创建成功, 因为我 AS 在我的 Linux 上存在一些兼容性问题,无法出现创建的菜单栏,此处不再演示。而方法二是直接在想要保存测试路径里创建该测试类即可,比如我的被测试类保存在 src/java/com/example/test/junit, 那 junit 的测试类一般保存在 test/java/com/example/test/junit。
然后编写测试文件,如下:
package com.example.mojies.mojies;
import org.junit.Test;
import static org.junit.Assert.*;
public class FibonacciTest {
@Test
public void test() {
assertEquals(0, Fibonacci.compute(0));
assertEquals(1, Fibonacci.compute(1));
assertEquals(1, Fibonacci.compute(2));
}
}
然后右击该测试类,然后点击 Run 'FibonacciTest' 则可以直接运行该测试类
当然如果你嫌弃一个一个写 assert 麻烦则可以采用以下这种写法:
import static org.junit.Assert.assertEquals;
import java.util.Arrays;
import java.util.Collection;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.junit.runners.Parameterized;
import org.junit.runners.Parameterized.Parameters;
@RunWith(Parameterized.class)
public class FibonacciTest {
@Parameters
public static Collection<object[]> data() {
return Arrays.asList(new Object[][] {
{ 0, 0 }, { 1, 1 }, { 2, 1 }, { 3, 2 }, { 4, 3 }, { 5, 5 }, { 6, 8 }
});
}
private int fInput;
private int fExpected;
public FibonacciTest(int input, int expected) {
this.fInput = input;
this.fExpected = expected;
}
@Test
public void test() {
assertEquals(fExpected, Fibonacci.compute(fInput));
}
}
JUnit 在判断测试是否通过主要是根据 assert 的执行结果来判断的,但在 @Test Annotation 指定的函数中可以执行除 assert 的判断函数外,还可以执行其他操作, 上叙采用 @Parameterized 方式麻烦的话写成下面这样也是可以的。
package com.example.mojies.mojies;
import org.junit.Test;
import static org.junit.Assert.*;
public class FibonacciTest {
@Test
public void test() {
int data[][] = {
{ 0, 0 }, { 1, 1 }, { 2, 1 }, { 3, 2 }, { 4, 3 }, { 5, 5 }, { 6, 8 }
};
for( int[] tc: data ){
assertEquals(tc[1], Fibonacci.compute(tc[0]));
}
}
}
但需要注意的是采用上面的方式如果 test() 中发生了异常, 那么该测试会直接退出。比如说如果 data[4] = {4,4}, 此时 data[5] data[6] 就不会测试了。
此外一个测试类中还能包含多个测试方法,而测试的顺序取决于你在文档中编排的顺序,当然前一个测试方法测试失败也并不会影响下一个测试方法的执行。
关于 JUnit 提供的 Assert 列表请参考: https://github.com/junit-team/junit4/wiki/Assertions
关于 JUnit 提供的 Annotation 方法请参考: JUnit 对 Annotation 的测试文档
在安卓中, 测试大致可以分为小/中/大形测试,而 小/中/大 的占比大约是 7:2:1, 其中小型测试主要以本地单元测试和插桩测试为主。 中形测试的测试范围大致包括:1)视图和视图模型之间的互动;2)应用的代码库层中的测试;3)测试特定屏幕上的互动;4)多 Fragment 测试,评估应用的特定区域。 而大型测试主要负责测试端到端的功能,交互流程是否和预期设计一致。
测试的结构在金字塔模型之前,流行的是冰淇淋模型。 包含了大量的手工测试、端到端的自动化测试及少量的单元测试。 造成的后果是,随着产品壮大,手工回归测试时间越来越长,质量很难把控;自动化case频频失败, 每一个失败对应着一个长长的函数调用,到底哪里出了问题? 单元测试少的可怜,基本没作用。 Mike Cohn 在他的著作《Succeeding with Agile》一书中提出了“测试金字塔”这个概念。 这个比喻非常形象,它让你一眼就知道测试是需要分层的。它还告诉你每一层需要写多少测试。 同时,我们对金字塔的理解绝不能止步于此,要进一步理解:我把金字塔模型理解为——冰激凌融化了。 就是指,最顶部的“手工测试”理论上全部要自动化,向下融化,优先全部考虑融化成单元测试,单元测试覆盖不了的 放在中间层(分层测试),再覆盖不了的才会放到UI层。 因此,UI层的case,能没有就不要有,跑的慢还不稳定。 按照乔帮主的说法,我不分单元测试还是分层测试,统一都叫自动化测试, 那就应该把所有的自动化case看做一个整体,case不要冗余,单元测试能覆盖,就要把这个case从分层或ui中去掉。 越是底层的测试,牵扯到相关内容越少,而高层测试则涉及面更广。 比如单元测试,它的关注点只有一个单元,而没有其它任何东西。 所以,只要一个单元写好了,测试就是可以通过的;而集成测试则要把好几个单元组装到一起才能测试,测试通过的前提条件是, 所有这些单元都写好了,这个周期就明显比单元测试要长;系统测试则要把整个系统的各个模块都连在一起,各种数据都准备好,才可能通过。 另外,因为涉及到的模块过多,任何一个模块做了调整,都有可能破坏高层测试,所以,高层测试通常是相对比较脆弱的,在实际的工作中, 有些高层测试会牵扯到外部系统,这样一来,复杂度又在不断地提升。 -- 摘自 谈有效的单元测试 腾讯效能团队
如果一个对象具有以下特征,比较适合使用mock对象: 1. 该对象提供非确定的结果(比如当前的时间或者当前的温度) 2. 对象的某些状态难以创建或者重现(比如网络错误或者文件读写错误) 3. 对象方法上的执行太慢(比如在测试开始之前初始化数据库) 4. 该对象还不存在或者其行为可能发生变化(比如测试驱动开发中驱动创建新的类) 5. 该对象必须包含一些专门为测试准备的数据或者方法(后者不适用于静态类型的语言,流行的Mock框架不能为对象添加新的方法。Stub是可以的。) -- 摘自 谈有效的单元测试 腾讯效能团队
关于 Mockito 的使用方法可以先参考 Mockito 官网首页中的实例,好有直观的认识。最好是把首页玩玩整整看一遍,因为 Guide 基本都在首页里面了。https://site.mockito.org/
首先是依赖,在你的 build.gradle 中添加 androidTestImplementation 'org.mockito:mockito-android:2.23.0', 现在的 mockito 版本已经到 3.x 了,但是 Mocktito 3.0 需要 JAVA8。
Mockito 的一般使用方法如下:
Handler handler = Mockito.mock(Handler.class);
Mockito.when(handler.sendMessageDelayed( Mockito.any(Message.class), Mockito.anyLong()))
.thenAnswer(new Answer() {
@Override
public Object answer(InvocationOnMock invocation) throws Throwable {
Object[] args = invocation.getArguments();
// Object mock = invocation.getMock();
// do something
return null;
}
});
yourClassInstance.setHandle( handler );
但你可能想要 mock void 方法,此时的使用方法如下: 以下这个例子在我的工程中没有跑成功,原因我现在也没找到,但是这个使用模式是对的, 如果你把 handle.removeMessages 换成其他 return void 的方法,在这里使用这个方法仅仅是为了介绍使用模式。
Handler handler = Mockito.mock(Handler.class);
// 如果你啥也不想处理
Mockito.doNothing().when(handler).removeMessages( 1 ); // 如果你不在乎匹配参数为 1 的调用也可以是 Mockito.anyInt()
// 如果你有异常想要抛出
Mockito.doThrow(new Exception()).doNothing().when(handler).removeMessages(anyInt(), Mockito.any(), Mockito.any());
// 如果你想处理一些什么
Mockito.doAnswer( new Answer(){
@Override
public Void answer(InvocationOnMock invocation) {
Object[] args = invocation.getArguments();
// Object mock = invocation.getMock();
// do something
return null;
}
} ).when( handler ).removeMessages(Mockito.anyInt());
yourClassInstance.setHandle( handler );
关于上叙 doReturn()|doThrow()| doAnswer()|doNothing()|doCallRealMethod() 之类的使用方法请参考: Mockito javadoc 中的说明
你可能注意到了,上面我使用 Mockito 去匹配 Handler.removeMessages 失败了,但是我用下面的方法成功了。 虽然可能需要在逻辑上判断 removeMessages 是否使用成功。
private class MockHandler extends Handler {
MockHandler() {
super(Looper.getMainLooper());
}
@Override
public void handleMessage(Message msg) {
// check your msg
}
}
{
...
Handler handler = new MockHandler();
yourClassInstance.setHandle( handler );
...
}
小节主要参考 stackover flow 上的一篇 帖子。 可能还有更好的办法,大家可以在评论区提出自己宝贵的建议。
一个通用的办法是用 square okhttp mockwebserver,这是 okhttp 使用的一个模拟 http server 的一个 mock 库。 如果你对如何使用该库有任何细节问题可以参考 okhttp 自己的 测试代码 。
下面是一个测试的例子:
// YOUR HTTP REQUEST CLASS BEING TESTED
public class HttpClient {
public String getBody() {
return body;
}
private String body;
public void getData( String url ) throws IOException {
OkHttpClient client = new OkHttpClient();
Request request = new Request.Builder()
.url( url )
.build();
try( Response response = client.newCall( request ).execute() ){
body = response.body().string();
}
}
}
// YOUR UNIT TEST CLASS
public class HttpClientTest {
@Test
public void getDataTest() throws IOException {
MockWebServer mockWebServer = new MockWebServer();
mockWebServer.enqueue(new MockResponse().setBody("success mojies return"));
HttpClient httpClient = new HttpClient();
httpClient.getData( mockWebServer.url("/").toString() );
System.out.println( httpClient.getBody() );
}
}
注意: 如果你的测试样例中包含 Url 组装部分,则这部分要单独测试。 mockWebServer.url("/").toString() 会返回你测试请求时候需要访问的 Url, 你必须通过这个 URL 去访问才能得到 Mock 的 response。 将该 URL 打印出来可以得到基本上是一个类似于这样的字符串 http://localhost.localdomain:59509/, 因此也可一推测 MockWebServer 的原理应该是在本地开一个 HTTP server, 同时引导测试代码访问该 Url,从而实现 HTTP Server Mock。
另外 stackoverflow 的那个例子中说必须要加上 @RunWith 注解是错误的,okhttp 并没有依赖 android 原生 API, 应该是作者在使用的时候用到了一些 Android 的 API。
而且 MockWebServer 还可以模拟以下情况,重定向,请求超时,请求失败(头信息错误,连接断开,发送响应消息过程中失败),延迟响应 ... (具体请参考上面提到的 MockWebServer 的自己的测试例子)
另外在测试的时候,你可能需要在 Test Case 里面等待整个请求的完成(因为 JUnit 一般认为程序执行跳出测试方法的作用域之后测试就完成了,而网络请求是需要时间的), 一个可行的方法是利用 mockwebserver 的请求同步方法,但是如果你的方法封装了很多东西,此方法可能不太适用。 另外一个方法是调用 await 库中的同步方法,该方法会周期性查询你设置的退出条件,在满足之后会停止阻塞,使程序往下走(参考 awaitility/awaitility )。
- 谈有效的单元测试 - 腾讯效能
- 干货 | 测试扁平化之必备神器:好的单元测试
- 单元测试两三问 - 腾讯效能
- 蘑菇街支付金融Android单元测试实践
- Android单元测试(一):JUnit框架的使用 (介绍了 JUnit 的一些基本用法)
- Android Studio中使用junit做单元测试
- JUnit 4 wiki
- 测试基础知识
- 软件测试基础知识总结
- Powermock 测试的几个例子
- PowerMock 的官方仓库
- PowerMock 的 Javadoc
- PowerMockito 1.6.4 的 JavaDoc
- Robolectric 官方文档
- 测试覆盖率 Jacoco 统计 Android 代码覆盖率 [instrument 方式]
- https://www.jianshu.com/p/9440937263f2
- awaitility/awaitility
- okhttp mockwebserver
- MockWebServerTest.java
- Android Studio 4.0 Run 窗口中文乱码
Help->Edit Custom VM Options -> 确认( 或者按 shift 两下激活全局搜索,然后搜索 Edit Custom VM Options )
增加-Dfile.encoding=UTF-8一行
File -> Invalidate Caches / Restart -> Just Restart - 内存分析
Memory Analyzer (MAT)
官方参考文档
注意从 Android studio 导出的 hprof 文件在 MAT 上打开需要用以下命令转换一下:hprof-conv heap-original.hprof heap-converted.hprof
YCbCr 或 Y'CbCr 有的时候会被写作:YCBCR 或是 Y'CBCR,是色彩空间的一种,通常会用于影片中的影像连续处理,或是数字摄影系统中。Y'和Y是不同的,Y就是所谓的流明(luminance), Y'表示光的浓度且为非线性,使用伽马修正(gamma correction)编码处理,而CB和CR则为蓝色和红色的浓度偏移量成分。
Y'CbCr 不是一种绝对的色彩空间,是一种针对 RGB 资讯所做的编码。真正的颜色显示是根据实际 RGB 色盘(colorant)来决定的。因此 Y'CbCr 所表示的值只有在标准 RGB 色盘或是 ICC 数据(ICC profile)有提供的时候才能计算。
YCbCr 不是一种绝对色彩空间,是 YUV 压缩和偏移的版本。YCbCr 的 Y 与 YUV 中的 Y 含义一致,Cb 和 Cr 与 UV 同样都指色彩,Cb 指蓝色色度,Cr 指红色色度,在应用上很广泛,JPEG、MPEG、DVD、摄影机、数字电视等皆采此一格式。 因此一般俗称的 YUV 大多是指 YCbCr。
YCbCr格式有:
- 4:4:4
- 4:2:2
- 4:1:1
- 4:2:0
NV12 是以 4:2:0 的方式进行采样的,其采样方式如下所示:(Y - Luma 代表明暗, Cb - Chroma 蓝色色度, Cr - Chroma 红色色度).
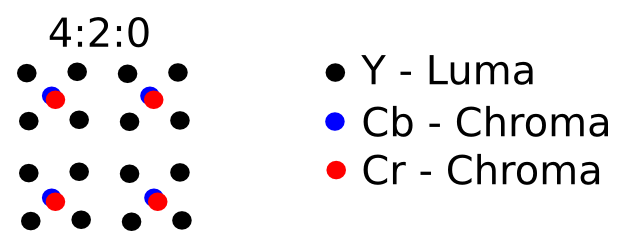
NV12 格式的文件大小为 W * H * 3 / 2,这里的 W 为图像的宽,H 为图像的高。比如如果 Y 部分为 640×480(307200),那么 Cb 和 Cr 部分分别为 640×480/4(76800),那么文件的总大小为 460800(307200 + 76800 + 76800);
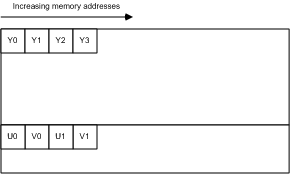
而 NV12 格式文件在内存中的排布如下所示:(其中 Y 部分被集中排列在文件开始,之后 U(Cb), V(Cr) 会以交替的方式排列在 Y 的部分之后)
NRZ-I 编码中,编码后电平只有正负电平之分,没有零电平,是不归零编码。 NRZ-I 电平的一次翻转来表示 Data 电平的逻辑 0,与前一个 NRZ-I 电平相同的电平表示 Data 电平的逻辑 1(翻转代表0,不变代表1)。 而由于上述特性,NRZ-I 编码信号即使反向后,其传输的内容还是不变的。
在USB 中,每一个USB的数据包,最开始的时候都有一个同步域,这个域定义为 0000 0001,这个域通过 NRZI 编码后,就是一个正负正负的方波,接收者可以通过这个方波计算频率,然后同步后面的数据。
但是,这样还会有一个问题,接收者可以主动和发送者之间频率匹配,但是两者之间总会有误差,假如数据是1000个逻辑0,经过 NRZI 编码后,很长时间都是同一个电平,这种情况下,即是接收者和发送者之间的频率相差千分之一,就是造成采样 999 个0或者是1001 个0。
USB 对这种问题的解决方法就是强制插一个 1,规定为传输 6 个 0 后在数据中插入一个 1,即发送前就会在第 6 个 0 后面强制插入一个 1,就让发送的信号强制出现翻转,从而强制接受者调整频率,接受者只要删除6个1之后的那个0,就可以恢复原有的数据。
但在 USB2.0 中各个 speed 模式对应的包结构都有细微差别:
- Low-speed Control Transfer Limits (15 SYNC bytes, 15 PID bytes, 6 Endpoint + CRC bytes, 6 CRC bytes, 8 Setup data bytes, and a 13-byte interpacket delay (EOP, etc.))
- Full-speed Control Transfer Limits (9 SYNC bytes, 9 PID bytes, 6 Endpoint + CRC bytes, 6 CRC bytes, 8 Setup data bytes, and a 7-byte interpacket delay (EOP, etc.))
- High-speed Control Transfer Limits (Based on 480Mb/s and 8 bit interpacket gap, 88 bit min bus turnaround, 32 bit sync, 8 bit EOP: (9x4 SYNC bytes, 9 PID bytes, 6 EP/ADDR+CRC,6 CRC16, 8 Setup data, 9x(1+11) byte interpacket delay (EOP, etc.))
- Full-speed Isochronous Transaction Limits (2 SYNC bytes, 2 PID bytes, 2 Endpoint + CRC bytes, 2 CRC bytes, and a 1-byte interpacket delay)
- High-speed Isochronous Transaction Limits (Based on 480Mb/s and 8 bit interpacket gap, 88 bit min bus turnaround, 32 bit sync, 8 bit EOP: (2x4 SYNC bytes, 2 PID bytes, 2 EP/ADDR+addr+CRC5, 2 CRC16, and a 2x(1+11)) byte interpacket delay (EOP, etc.))
- ...ref USB 2.0
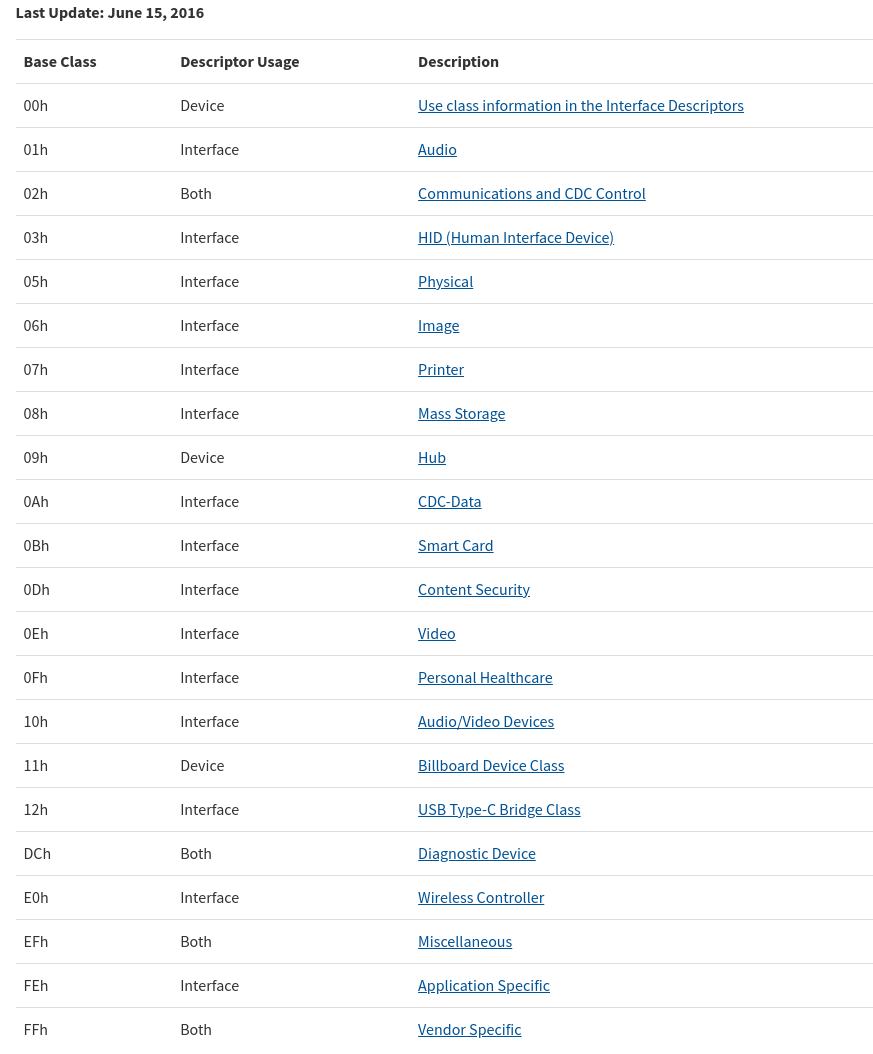
USB 定义了 class code 来区分设备的功能(functioinality)同时系统也可根据该 class code 来加载相应的驱动。 这部分信息总共分为三个字节,名为: Base Class, SubClass, and Protocol.(注意 Base Class 描述的是三个 byte 中的第一个字节,而 USB 规范中并没有使用 BaseClass 该术语)。 一个设备上有两个地方可以放置类代码信息,一个在设备描述( Device Descriptor),一个在(接口描述 Interface Descriptors)。 有一些定义的类代码只允许在设备描述符中使用,一些可以在设备和接口描述符中使用,还有一些只能在接口描述符中使用。 下表显示了当前定义的一组基类值、通用用途是什么以及可以使用基类的位置(设备或接口描述符或两者)。
参考上述 bInterfaceClass 类型
- 0x00 SC_UNDEFINED - 未定义
- 0x01 SC_VIDEOCONTROL - video control (VC) 类型接口,主要用于传输指令
- 0x02 SC_VIDEOSTREAMING - video stream (VS) 类型接口,主要用于传输流
- 0x03 SC_VIDEO_INTERFACE_COLLECTION
- 0x00 PC_PROTOCOL_UNDEFINE - 为定义
- 0x01 PC_PROTOCOL_15 - 参考 UVC 1.5,在 UVC 1.5 中该值是一个固定值
- 0x20 CS_UNDEFINE - 为定义
- 0x21 CS_DEVICE - 设备类型
- 0x22 CS_CONFIGURATION - 配置类型
- 0x23 CS_STRING - 字符串类型
- 0x24 CS_INTERFACE
- 0x25 CS_ENDPOINT
- 0x00 - VC_DESCRIPTOR_UNDEFINED - 未定义
- 0x01 - VC_HEADER
- 0x02 - VC_INPUT_TERMINAL -
- 0x03 - VC_OUTPUT_TERMINAL -
- 0x04 - VC_SELECTOR_UNIT - 选择器(选项器)单元
- 0x05 - VC_PROCESSING_UNIT - 处理单元
- 0x06 - VC_EXTENSION_UNIT - 扩展单元
- 0x07 - VC_ENCODING_UNIT - 编码单元
下面是一个 UVC 扩展指令的包的解析:
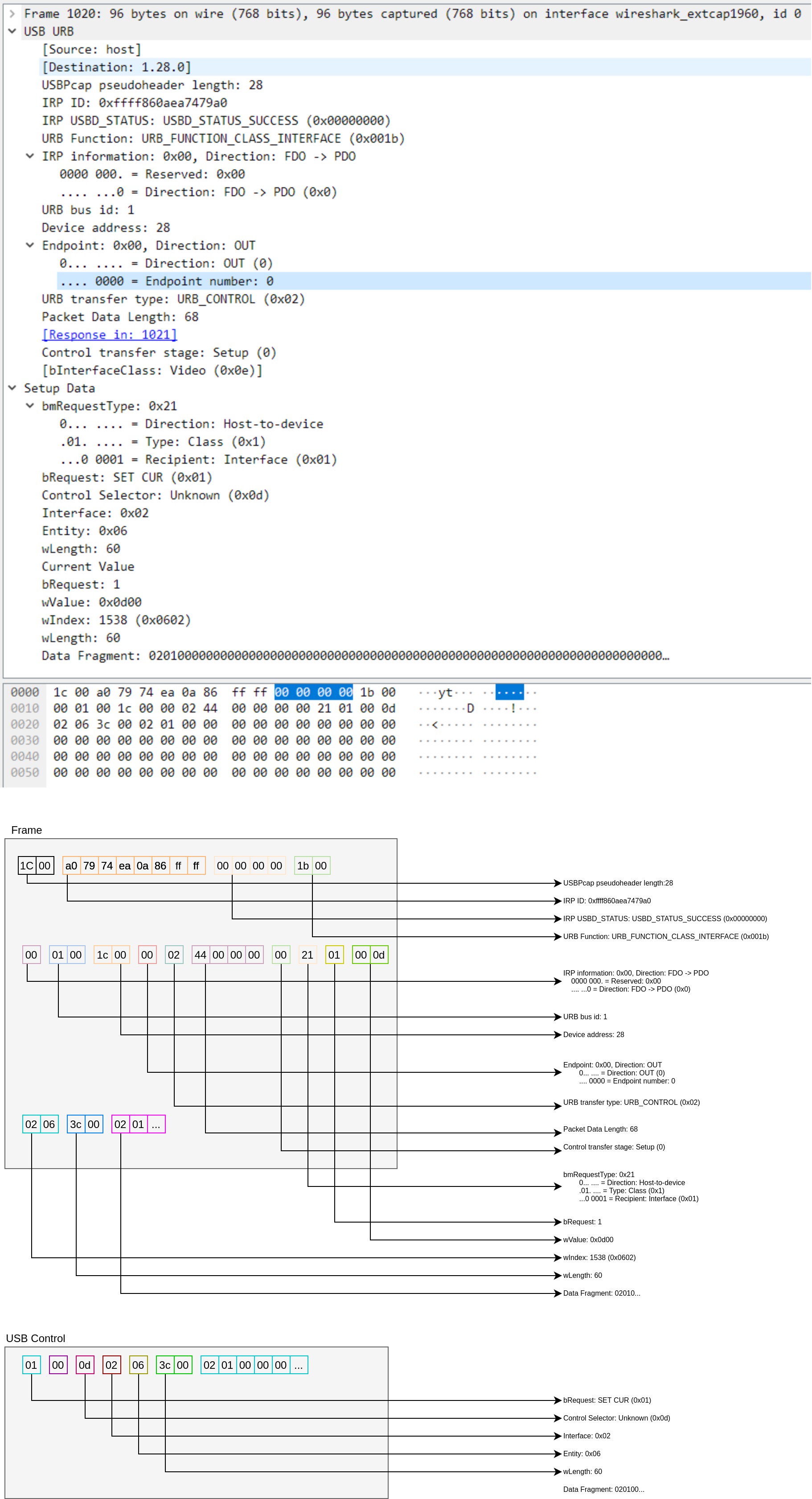
关于 libusb 的工程我们可以在这里获取:libusb,其 github 仓库为: libusb/libusb
虽然说此处的命令是以 libusb 来实现的,但是目前也有基于 libusb 的开源项目了,比如常见的库 libuvc/libuvc。
首先要初始化 libusb:
r = libusb_init(NULL);
然后获取系统中目标设备的设备描述:
// 获取设备列表
cnt = libusb_get_device_list(NULL, &devs);
// 获取目标 VID/PID 设备
for( i = 0; i < cnt; i++ ){
ret = libusb_get_device_descriptor(devs[i], &desc);
if( desc.idVendor == 0xxxx && desc.idProduct == 0xxxx ){
break;
}
}
获取系统中设备的更加详细描述:
// 打开操作句柄
libusb_device_handle *handle = NULL;
libusb_open( dev, &handle );
// 获取目标 endpoint
for (i = 0; i < desc->bNumConfigurations; i++) {
int i,j;
struct libusb_config_descriptor *config;
ret = libusb_get_config_descriptor(dev, i, &config);
const struct libusb_endpoint_descriptor endpoint;
for( i = 0; i < config->bNumInterfaces; i++ ){
for( j = 0; j < config->interface[i].num_altsetting; j++ ){
if( config->interface[i].altsetting[j].bInterfaceClass != 0x0E ) continue;
if( config->interface[i].altsetting[j].bInterfaceSubClass != 0x01 ) continue;
if( config->interface[i].altsetting[j].bNumEndpoints < 1 ) continue;
// 申明该设备占有权
int idx = config->interface[i].altsetting[j].bInterfaceNumber;
ret = libusb_detach_kernel_driver( handle, idx);
ret = libusb_claim_interface( handle, idx);
endpoint = config->interface[i].altsetting[j].endpoint[ 0 ];
}
}
libusb_free_config_descriptor(config);
}
// 建立 transfer 通道
libusb_fill_interrupt_transfer( status_xfer, handle, endpoint.bEndpointAddress, status_buf, sizeof(status_buf), NULL, NULL, 0);
ret = libusb_submit_transfer(status_xfer);
// 发送指令
unsigned char data[] = { 0x02, 0x01, ..... };
ret = libusb_control_transfer( handle, REQ_TYPE_SET, UVC_SET_CUR, 0x0D00, 0x0602, data, sizeof(data), 1000 );
最后释放工程
libusb_free_device_list(devs, 1);
libusb_exit(NULL);
USB CDC类的通信部分主要包含三部分:枚举过程、虚拟串口操作和数据通信。其中虚拟串口操作部分并不一定强制需要,因为若跳过这些虚拟串口的操作,实际上USB依然是可以通信的,这也就是为什么上图中,在操作虚拟串口之前会有两条数据通信的数据。之所以会有虚拟串口操作,主要是我们通常使用PC作为Host端,在PC端使用一个串口工具来与其进行通信,PC端的对应驱动将其虚拟成一个普通串口,这样一来,可以方便PC端软件通过操作串口的方式来与其进行通信,但实际上,Host端与Device端物理上是通过USB总线来进行通信的,与串口没有关系,这一虚拟化过程,起决定性作用的是对应驱动,包含如何将每一条具体的虚拟串口操作对应到实际上的USB操作。需要注意的是,Host端与Device端的USB通信速率并不受所谓的串口波特率影响,它就是标准的USB2.0全速(12Mbps)速度,实际速率取决于总线的实际使用率、驱动访问USB外设有效速率(两边)以及外部环境对通信本身造成的干扰率等因素组成。
————————————————
版权声明:本文为CSDN博主「king_jie0210」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
文链接:https://blog.csdn.net/king_jie0210/article/details/76713938
- [link]机器学习即服务之BigML特性介绍和入门教程
- [link]【深度开源 open经验】机器学习平台、框架、库和软件集合
- [link]软件形式化方法概述
- [link]形式化方法--百度百科
- [link]敏捷开发中的持续集成
- [link]github开源项目-算法实现之路
- 破解软件下载地址
- bearssl 在各个平台的 benchmark
- Crypto++ Windows 平台的 benchmark
- OpenWrt 给出的 openssl 在各个平台的 benchmark
- aes 在 x86 NI 指令集下的 performance
- Linux Kernel Crypto API
- X86 安卓镜像下载
- 如何在 Linux 安装 android 虚拟机
- 一句话激活 windows
- 下载 Youtube 视频
- wave-share利用声波传递信号的实现
- 设计模式
- 拆解特斯拉Model 3逆变器
- 特斯拉Model Y拆解调研数据
- 常用数据结构可视化操作
- Awesome Open Source该网站总结了各个领域的优秀开源项目
- Open-source self-hosted comments for a static website汇总了优秀的静态博客站解决方案
- Infer -- 一个静态检查工具
- Diagram Maker -- amazon 开源的一套画图工具
- 一家非常有格调的杂货店,卖的东西非常优雅
- 该仓库汇总最优质的计算机科学学习资料
- 网易云 VSCode 的插件
- 一个兼容很多数据库的管理工具
 |
 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号