数据库索引咋搞啊?
- 索引的目的在于提高查询效率,与我们查阅图书所用的目录是一个道理,图书目录占用空间,所以索引也会占用空间,索引太多或者太低都不好。当对表中的数据进行增加、删除、修改时,索引也需要动态的维护。一般是在没有数据之前先建立索引,再往数据库插入数据。索引是用来查询的,所以会降低写入的效率。
- 查看某个查询是否使用了索引:如explain select * from book
explain 可以帮助我们分析 select 语句,让我们知道查询效率低下的原因

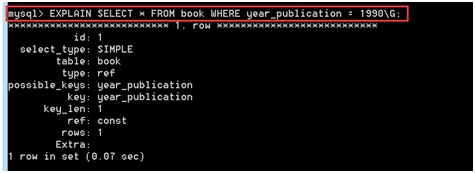
explain不会告诉我们关于触发器、存储过程的信息或用户自定义函数对查询的影响情况,EXPLAIN不考虑各种Cache,EXPLAIN不能显示MySQL在执行查询时所作的优化工作,部分统计信息是估算的,并非精确值,EXPALIN只能解释SELECT操作,其他操作要重写为SELECT后查看执行计划。
id:SQL执行的顺序的标识,越大越先执行,如果说数字一样大,那么就从上往下依次执行
select_type:表示每个select子句的类型,如SIMPLE,PRIMARY,UNION,DERIVED;SIMPLE,简单的SELECT,表示不用UNION或子查询的select;PRIMARY,需要union操作或者含有子查询的select;UNION,UNION连接句之后的所有select;DERIVED,from字句中出现的子查询select
table:数据表的名字。他们按被读取的先后顺序排列,这里因为只查询一张表,所以只显示book
type:指定本数据表和其他数据表之间的关联关系
possible_keys:MySQL在搜索数据记录时可以选用的各个索引,查询涉及到的字段上若存在索引,则该索引将会被列出,但不一定被当前查询实际使用。
key:实际选用的索引,若为null,则没有使用到索引
key_len:计算使用了的索引长度,以字节为单位,字段类型 int为4个,date为3,datetime为4,char(n)为3n,varchar(n)为3n+2个
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
extra:提供了与关联操作有关的信息,如Using filtersort文件排序(没有索引),Using index使用了索引
rows :查询返回的行数
- 建立索引注意事项?
- 索引列不应该存储null值,在mysql里,null值的列也是走索引的,但含有空值的列很难进行查询优化
- where索引的列可以进行<,<=,=,>,>=,BETWEEN,IN操作(IN情况复杂,需具体分析),但不能用NOT IN 、<>、!=操作,<>表示不等于
- 索引列不应该含重复数据比较多,如性别只有男女两种取值,该列会大量重复数据
- 在经常需要排序 (order by) ,分组 (group by) , distinct的列上加索引
- like语句,前导模糊查询 like "%XXX" 不能使用索引,而非前导模糊查询 like "XXX%" 则可以,
解决前导模糊查询:建立全文索引,或者使用覆盖索引(某个索引包含了当前select需要查询出来的所有字段)
- 对于那些定义为text, image和bit数据类型的列不应该建索引。这是因为,这些列的数据量要么相当大,要么取值很少。
- 当update修改性能远远大于检索性能时,不应该创建索引。修改性能和检索性能是互相矛盾的。当增加索引时,会提高检索性能,但是会降低修改性能。当减少索引时,会提高修改性能,降低检索性能
- 开启索引缓存,直接在内存中查找索引,不要在磁盘中查
- 建立索引是有代价的,当update、delete语句执行时,会使得索引更新,将耗掉更多的时间
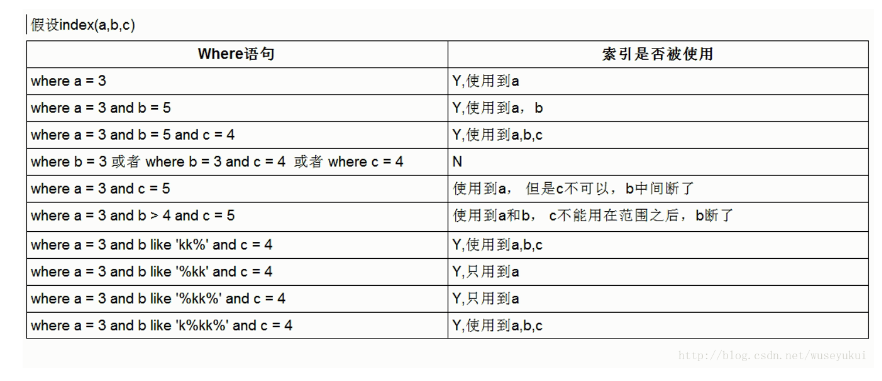
总结:(索引生效的条件)

1、2句就是最左前缀原则;
3句,不要对有索引的列做任何操作(计算、函数、自动/手动类型转换),不然会导致索引失效而转向全表扫描,组合索引中不能继续使用有范围条件(bettween、<、>、in等)的索引列右边的列(不含当前索引列)
4句,就是like规则,上面已讲;只查询索引的列(索引列和查询列一模一样),减少select *而写select name,age具体字段
5句,JOIN 查询中,join前join后的字段是被建过索引的,而且类型相同,字符集相同
6句,索引字段上使用(!= 或者 < >或者is null / is not null)判断时,会导致索引失效而转向全表扫描;索引字段是字符串varchar型数字,但查询时不加单引号,会导致索引失效而转向全表扫描;索引字段使用 or 时,会导致索引失效而转向全表扫描;
6句,order by时select*是个大忌;where+order by只看order by,若order by后跟的是单字段则必是索引的最左字段,若跟多字段则也必紧跟索引最左字段,而且多字段排序方式要一致(同为asc或desc);where+order by只看order by,如果order by后的紧跟字段不为索引最左字段且where条件是个常量(如where age=20),则该where条件会顺延给order by(即order by age),此时若age为索引最左字段,则符合“order by后跟的是单字段则必是索引的最左字段”,此时索引生效
举例:
![]()
- 什么时候建索引?
表的主键、外键必须建索引(没有则数据库为它们自动创建一个普通索引);数据量超过300的表应该建索引;经常与其他表进行连接的表,在连接字段上应该建立索引;经常用到排序的列上应该建索引,因为索引已经排序;
- 都有哪几种索引?
普通索引index:最基本的索引,仅加速查询,是我们大多数情况下使用到的索引。
//为book表的bookname字段创建了名为index_bookBookname的索引
create index index_bookBookname on book(bookname)
唯一索引unique index:与普通索引区别是,加速查询 + 列值唯一(可以有null)
create unique index index_bookBookname on book(bookname)
组合索引:在表的多个字段上创建一个组合索引,为user表的name和age字段建索引
create index index_bookBooknameAndAuthors on book(bookname,authors)
或者
create table user(
id int(20),
name VARCHAR(32) ,
age VARCHAR(32) ,
INDEX index_bookBooknameAndAuthors (bookname,authors)
) ;
- mysql创建索引时如果是blob 和 text 类型,索引里面必须指定length,如:
create index index_bookBookname on book(bookname(25))
- 组合索引必遵循最左前缀原则
利用索引中最左边的列集来匹配行,比如新建索引 (bookname,authors,info) 最左边为bookname字段,查询的字段若为(bookname)、(bookname,authors)、(bookname,authors,info)则会启用索引,若为(authors)、(authors,info)则不会启用索引,(bookname,info)只会用到bookname列
全文索引:即FULLTEXT索引,它在很多文字中,通过关键字匹配就能够找到该记录。全文搜索的限制比较多,只有mysql的MyISAM存储引擎支持全文索引(mysql有InnoDB和MyISAM引擎);并且只能为CHAR、VARCHAR和TEXT列建索引;搜索的关键字默认至少要4个字符(关键字太短就会被忽略掉);使用全文搜索时,必须借助MATCH函数
创建 create fulltext index index_bookBookname on book(bookname)
create fulltext index index_bookBookname on book(bookname,authors)
select * from book where match(bookname) against('万历十五年');
select * from book where match(bookname,authors) against('万历十五年',"鲁迅");
- 为什么不能建太多索引
索引也要占空间;过多的组合索引,在有单一字段索引的情况下,没有什么价值;索引降低update修改的性能
- 实用sql
查看一张表中所创建的索引:show index from user
删除索引:alter table book drop index index_bookBookname
或drop index index_bookBookname on book
- 索引底层数据结构:B+树

 浙公网安备 33010602011771号
浙公网安备 33010602011771号