pytorch 手写汉字识别
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from PIL import Image
from torchsummary import summary
from torch.optim.lr_scheduler import StepLR # 学习率衰减
确保中文路径正常读取
import matplotlib.pyplot as plt
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
1. 自定义数据集加载类
class ChineseCharDataset(Dataset):
def init(self, root_dir, num_class, transforms=None):
super().init()
self.images = [] # 存储照片路径
self.labels = [] # 存储照片对应的类别
self.transforms = transforms
# 验证根目录是否存在
if not os.path.exists(root_dir):
raise ValueError(f"数据集目录不存在: {root_dir}")
# 遍历root_dir下的类别文件夹
class_folders = sorted([f for f in os.listdir(root_dir)
if os.path.isdir(os.path.join(root_dir, f))])
# 检查是否有类别文件夹
if not class_folders:
raise ValueError(f"在 {root_dir} 中未找到任何类别文件夹")
# 只取前num_class个类别
selected_classes = class_folders[:num_class]
# 遍历每个类别文件夹,收集照片路径和标签
for cls_name in selected_classes:
cls_dir = os.path.join(root_dir, cls_name)
# 遍历文件夹下所有照片文件
img_files = [f for f in os.listdir(cls_dir)
if f.lower().endswith(('.png', '.jpg', '.jpeg', '.bmp', '.gif'))]
if not img_files: # 跳过空文件夹
print(f"警告: 类别文件夹 {cls_dir} 中未找到图片文件,已跳过")
continue
for img_name in img_files:
img_path = os.path.join(cls_dir, img_name)
self.images.append(img_path)
try:
self.labels.append(int(cls_name)) # 类别名转数字作为标签
except ValueError:
raise ValueError(f"类别文件夹名 {cls_name} 不是数字,无法转换为标签")
def __getitem__(self, index):
# 读取并处理照片(失败时自动重试下一张)
try:
img = Image.open(self.images[index]).convert('RGB')
except Exception as e:
print(f"照片读取失败: {self.images[index]}, 错误: {e}")
return self.__getitem__((index + 1) % len(self))
label = self.labels[index]
if self.transforms:
img = self.transforms(img)
return img, label
def __len__(self):
return len(self.images)
2. 优化后的CNN网络模型
class CharRecognitionNet(nn.Module):
def init(self, num_classes=100):
super().init()
# 卷积块:加深网络+BatchNorm+池化
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32, 3, padding=1), # 1→32通道,3x3卷积(补边保尺寸)
nn.BatchNorm2d(32), # 标准化:加速收敛
nn.ReLU(),
nn.MaxPool2d(2, 2) # 2x2池化,尺寸减半
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3, padding=1), # 32→64通道
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
self.conv3 = nn.Sequential( # 新增第3个卷积块
nn.Conv2d(64, 128, 3, padding=1),# 64→128通道
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2, 2)
)
# 全连接层输入维度:128通道 × 16×16尺寸(128/2^3=16)
self.fc_input_dim = 128 * 16 * 16
self.fc1 = nn.Sequential(
nn.Linear(self.fc_input_dim, 512),
nn.ReLU(),
nn.Dropout(0.5) # Dropout防过拟合
)
self.fc2 = nn.Sequential(
nn.Linear(512, 256),
nn.ReLU(),
nn.Dropout(0.3)
)
self.fc3 = nn.Linear(256, num_classes) # 输出层:匹配类别数
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(-1, self.fc_input_dim) # 展平为全连接层输入
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
3. 标签平滑损失(提升泛化能力)
class LabelSmoothingLoss(nn.Module):
def init(self, num_classes, smoothing=0.1):
super().init()
self.num_classes = num_classes
self.smoothing = smoothing
self.confidence = 1.0 - smoothing
def forward(self, logits, labels):
logits = logits.log_softmax(dim=1) # 对数softmax
# 构建平滑标签
one_hot = torch.zeros_like(logits).scatter(1, labels.unsqueeze(1), 1)
smooth_label = one_hot * self.confidence + (1 - one_hot) * (self.smoothing / (self.num_classes - 1))
# 计算交叉熵损失
loss = (-smooth_label * logits).mean(dim=1).sum()
return loss
4. 计算全量数据集准确率
def calculate_full_accuracy(model, dataloader, device):
model.eval()
total_correct = 0
total_samples = 0
if len(dataloader.dataset) == 0:
print("警告: 数据集为空,无法计算准确率")
return 0.0, 0, 0
with torch.no_grad(): # 关闭梯度计算,加速推理
for photos, labels in dataloader:
photos, labels = photos.to(device), labels.to(device)
outputs = model(photos)
_, predicted = torch.max(outputs, 1)
total_samples += labels.size(0)
total_correct += (predicted == labels).sum().item()
if total_samples == 0:
print("警告: 未找到任何样本,无法计算准确率")
return 0.0, 0, 0
accuracy = total_correct / total_samples
model.train() # 恢复训练模式
return accuracy, total_correct, total_samples
5. 主函数(完整逻辑)
def main():
# 基础配置(根据你的环境调整)
root = "D:\pytorch\data"
train_photo_dir = os.path.join(root, "train")
test_photo_dir = os.path.join(root, "test")
num_class = 100 # 你的汉字类别数
batch_size = 32 # 批次大小(GPU显存不足可改16)
epochs = 15 # 训练轮次
lr = 0.001 # 初始学习率
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}\n")
# 数据增强(训练集加扰动,测试集仅预处理)
train_transform = transforms.Compose([
transforms.Resize((128, 128)), # 尺寸从64→128,保留更多细节
transforms.Grayscale(), # 转灰度图
transforms.RandomRotation(10), # 随机旋转±10度
transforms.RandomAffine(0, translate=(0.1, 0.1)), # 随机平移±10%
transforms.RandomResizedCrop(128, scale=(0.8, 1.0)),# 随机缩放80%-100%
transforms.GaussianBlur(kernel_size=(3,3), sigma=(0.1, 0.5)),# 高斯模糊
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,)) # 标准化
])
test_transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 加载数据集(带异常处理)
print("正在加载照片数据集...")
try:
train_dataset = ChineseCharDataset(
root_dir=train_photo_dir,
num_class=num_class,
transforms=train_transform
)
test_dataset = ChineseCharDataset(
root_dir=test_photo_dir,
num_class=num_class,
transforms=test_transform
)
except Exception as e:
print(f"数据集加载失败: {e}")
return
# 验证数据集非空
if len(train_dataset) == 0:
print(f"错误: 训练集目录 {train_photo_dir} 中未找到有效图片")
return
if len(test_dataset) == 0:
print(f"错误: 测试集目录 {test_photo_dir} 中未找到有效图片")
return
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0, # Windows设0,Linux/Mac可设4
pin_memory=True
)
test_loader = DataLoader(
test_dataset,
batch_size=64,
shuffle=False,
num_workers=0,
pin_memory=True
)
print(f"加载完成:训练照片{len(train_dataset)}张,测试照片{len(test_dataset)}张\n")
# 初始化模型、损失函数、优化器
model = CharRecognitionNet(num_classes=num_class).to(device)
summary(model, (1, 128, 128)) # 打印网络结构
criterion = LabelSmoothingLoss(num_classes=num_class, smoothing=0.1) # 标签平滑
optimizer = torch.optim.Adam(
model.parameters(),
lr=lr,
weight_decay=1e-5 # 权重衰减防过拟合
)
scheduler = StepLR(optimizer, step_size=5, gamma=0.5) # 每5轮学习率×0.5
# 模型训练(带最优模型保存)
print("\n开始训练模型...")
best_test_acc = 0.0 # 记录最优测试准确率
for epoch in range(epochs):
model.train()
total_train_loss = 0.0
total_train_correct = 0
total_train_samples = 0
for step, (photos, labels) in enumerate(train_loader):
photos, labels = photos.to(device), labels.to(device)
batch_size_current = photos.size(0)
# 前向传播
outputs = model(photos)
loss = criterion(outputs, labels)
# 计算准确率
_, predicted = torch.max(outputs, 1)
batch_correct = (predicted == labels).sum().item()
total_train_correct += batch_correct
total_train_samples += batch_size_current
# 反向传播更新参数
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_loss += loss.item()
# 每20批次打印日志
if (step + 1) % 20 == 0:
avg_loss = total_train_loss / (step + 1)
avg_train_acc = total_train_correct / total_train_samples if total_train_samples > 0 else 0
test_acc, _, _ = calculate_full_accuracy(model, test_loader, device)
print(f"【轮次 {epoch+1}/{epochs} | 批次 {step+1} | 学习率 {scheduler.get_last_lr()[0]:.6f}】")
print(f" - 训练平均损失: {avg_loss:.4f}")
print(f" - 训练平均准确率: {avg_train_acc:.4f} (正确{total_train_correct}/{total_train_samples})")
print(f" - 测试集准确率: {test_acc:.4f}\n")
# 轮次结束处理
scheduler.step() # 学习率衰减生效
final_train_acc, train_corr, train_total = calculate_full_accuracy(model, train_loader, device)
final_test_acc, test_corr, test_total = calculate_full_accuracy(model, test_loader, device)
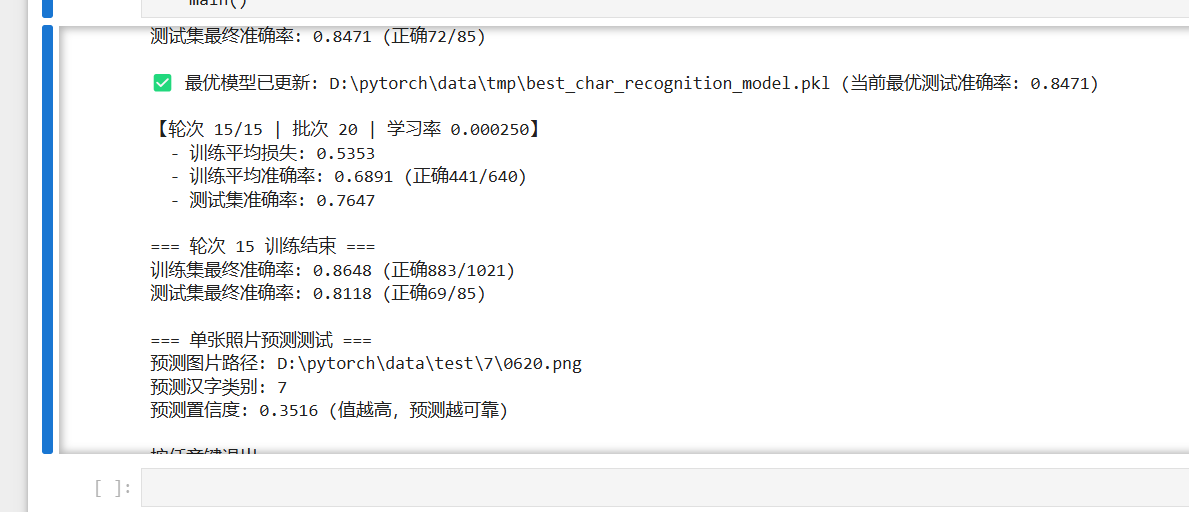
print(f"=== 轮次 {epoch+1} 训练结束 ===")
print(f"训练集最终准确率: {final_train_acc:.4f} (正确{train_corr}/{train_total})")
print(f"测试集最终准确率: {final_test_acc:.4f} (正确{test_corr}/{test_total})\n")
# 保存最优模型
if final_test_acc > best_test_acc:
best_test_acc = final_test_acc
save_dir = os.path.join(root, "tmp")
os.makedirs(save_dir, exist_ok=True)
best_model_path = os.path.join(save_dir, "best_char_recognition_model.pkl")
torch.save(model.state_dict(), best_model_path)
print(f"✅ 最优模型已更新: {best_model_path} (当前最优测试准确率: {best_test_acc:.4f})\n")
# 单张照片预测(使用最优模型)
print("=== 单张照片预测测试 ===")
best_model = CharRecognitionNet(num_classes=num_class)
best_model_path = os.path.join(root, "tmp", "best_char_recognition_model.pkl")
try:
# 加载最优模型权重
if not os.path.exists(best_model_path):
raise FileNotFoundError(f"最优模型文件不存在: {best_model_path}")
best_model.load_state_dict(torch.load(best_model_path, map_location=device))
best_model.to(device)
best_model.eval() # 切换到推理模式
# 测试图片路径(请替换为你的实际测试图片路径)
test_single_photo = "D:\\pytorch\\data\\test\\7\\0620.png"
if not os.path.exists(test_single_photo):
raise FileNotFoundError(f"预测图片不存在: {test_single_photo}")
# 图片预处理(与测试集一致)
img = Image.open(test_single_photo).convert('RGB')
img = test_transform(img).to(device)
img = img.unsqueeze(0) # 增加batch维度(模型要求输入格式:[batch, channel, H, W])
# 推理预测
with torch.no_grad():
output = best_model(img)
_, predicted_cls = torch.max(output, 1) # 取概率最大的类别
confidence = F.softmax(output, dim=1)[0][predicted_cls].item() # 计算置信度
# 打印预测结果
print(f"预测图片路径: {test_single_photo}")
print(f"预测汉字类别: {predicted_cls.item()}")
print(f"预测置信度: {confidence:.4f} (值越高,预测越可靠)")
except Exception as e:
print(f"单张照片预测失败: {e}")
# 防止Windows控制台闪退(可选,根据需要保留)
print("\n按任意键退出...")
input()
if name == "main":
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号