
大作业之jieba
import jieba
from collections import Counter
import re
name_mapping = {
"孙悟空": "孙悟空",
"孙行者": "孙悟空",
"行者": "孙悟空",
"猴王": "孙悟空",
"大圣": "孙悟空",
"齐天大圣": "孙悟空",
"孙猴子": "孙悟空",
"美猴王": "孙悟空",
"弼马温": "孙悟空",
"唐僧": "唐僧",
"玄奘": "唐僧",
"三藏": "唐僧",
"唐三藏": "唐僧",
"圣僧": "唐僧",
"猪八戒": "猪八戒",
"八戒": "猪八戒",
"悟能": "猪八戒",
"天蓬元帅": "猪八戒",
"沙僧": "沙僧",
"沙和尚": "沙僧",
"悟净": "沙僧",
"如来": "如来",
"如来佛祖": "如来",
"观音": "观音",
"观音菩萨": "观音",
"观世音": "观音",
"玉帝": "玉帝",
"玉皇大帝": "玉帝",
"白骨精": "白骨精",
"白骨夫人": "白骨精",
"红孩儿": "红孩儿",
"圣婴大王": "红孩儿",
"牛魔王": "牛魔王",
"平天大圣": "牛魔王",
}
def load_xiyouji_text(file_path):
"""加载西游记文本"""
with open(file_path, 'r', encoding='utf-8') as f:
text = f.read()
# 去除一些干扰字符
text = re.sub(r'[\s\u3000]+', '', text)
return text
def count_character_names(text):
"""统计人物名称出现频率"""
# 添加自定义词典
for name in name_mapping.keys():
jieba.add_word(name)
words = jieba.lcut(text)
name_counter = Counter()
for word in words:
if word in name_mapping:
standard_name = name_mapping[word]
name_counter[standard_name] += 1
return name_counter
def main():
file_path = "D:\《西游记》【爱上阅读_www.isyd.net】.txt"
try:
text = load_xiyouji_text(file_path)
name_counter = count_character_names(text)
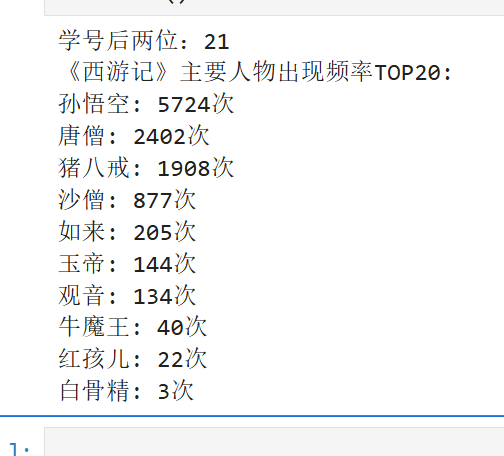
print("学号后两位:21")
print("《西游记》主要人物出现频率TOP20:")
for name, count in name_counter.most_common(20):
print(f"{name}: {count}次")
except FileNotFoundError:
print(f"错误:找不到文件 {file_path}")
except Exception as e:
print(f"发生错误: {str(e)}")
if name == "main":
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号