树、二叉树、查找算法总结
树、二叉树、查找算法总结
一、思维导图
二、重要概念的笔记
三、疑难问题及解决方案
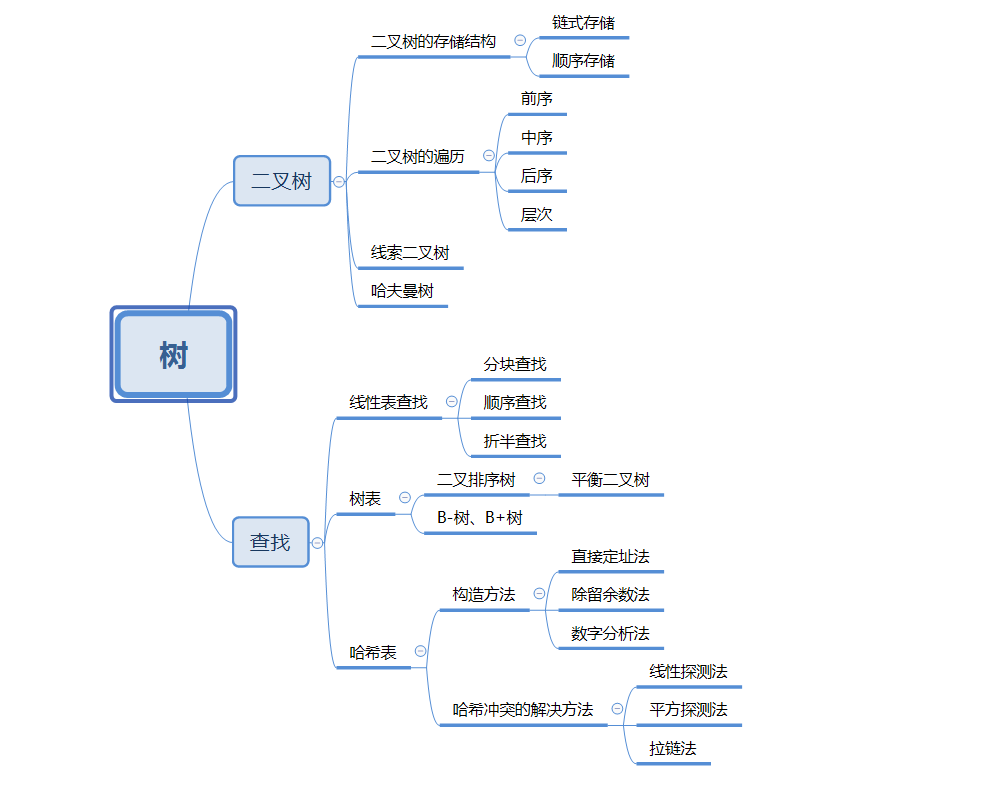
思维导图
重要概念的笔记
树的定义:
1.树是由n个结点组成的有限集合。n=0时,为空树。
2.树性质:树的结点数等于所有结点度数和加1。
二叉树定义:
1.有限的节点集合,集合为空或者由一个根节点和两棵互不相交的左右子树组成。
typedef struct node
{
ElemType data;
struct node *lchild,*rchild;
}BTNode;
二叉树的先序、中序、后序、层次遍历:
先序、中序、后序都可通过递归实现:
1.先序遍历代码:
void PreOrder(BTnode*bt){
if(bt){
cout<<bt->data<<" ";//访问根节点
PreOrder(bt->left); //先序遍历左子树
PreOrder(bt->right); //先序遍历右子树
}
}
2.中序遍历代码:
void InOrder(BTnode*bt){
if(bt){
InOrder(bt->left);
cout<<bt->data<<" ";
InOrder(bt->right);
}
}
3.后续遍历:
void PostOrder(BTnode*bt){
if(bt){
PostOrder(bt->left);
PostOrder(bt->right);
cout<<bt->data<<" ";
}
}
- 层序遍历:
oid Order(BTnode*bt){
BTNode*ans[101];
int head = 0,tail = 0;
ans[tail++] = bt;
while(head!=tail){
bt = ans[head++];
if(bt){
cout<<bt->data<<" ";
ans[tail++] = bt->left;
ans[tail++] = bt->right;
}
}
}
5.先序、中序、后序遍历原理与栈的进退栈原理相似,故也可以用非递归算法:
先序:
void Preorder(BTnode* t)
{
BTnode* Seqstack[MAXSIZE];
int top = -1;
BTnode* p;
if(t != NULL)
{
top++;
Seqstack[top] = t; // 先将根结点压栈
while(top > -1) // 栈不为空时循环
{
p = Seqstack[top]; // 栈顶元素出栈
top --;
printf("%d ", p->data); // 访问栈顶元素
if(p->rchild != NULL) // 如果右孩子不为空,则进栈
{
top ++;
Seqstack[top] = p->rchild;
}
if(p->lchild != NULL) // 如果左孩子不为空,则进栈
{
top ++;
Seqstack[top] = p->lchild;
}
}
}
}
中序:
void PreOrder(BTnode* b)
{
BTnode* p;
SqStack* st;
IniStack(st);
p = b;
while (!StackEmpty(st) || p != NULL)
{
while (p != NULL)
{
count << p->data << ' ';
push(st, p);
p = p->lchild;
}
if (!StackEmpty(st))
{
pop(st, p);
p = p->rchild;
}
}
}
哈夫曼树:
1.哈夫曼树是特殊的二叉树,夫曼树是将最小的两个数据构成一棵二叉树,根结点为两子树的和,然后将其放入集合中,重复上述操作,直到集合中的所有数据构成一棵二叉树,
2.哈夫曼结点类型:
typedef struct
{
char data;
double weight;
int parent;
int lchild;
int rchild;
}HTNode;
查找:
1.顺序查找:
基本思路为从表一端向表另一端将元素关键字与定值k比较,相等则查找成功。
2.折半查找(半分查找)效率很高的算法,必须是有序表,思路为先确定先找区间的中间位置,再将待查关键字与R[mid].key比较大小,若相等,则查找成功,若小于,再对R[low,mid-1]进行半分查找,若大于,再对R[mid+1,high]进行半分查找。
疑难问题及解决方案
1.折半查找的时间复杂度计算。
解决:折半查找过程可以用二叉树来描述,时间复杂度与二叉树高度有关,时间复杂度为O(log2n);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号