python 2.081 深浅copy 迭代器 引出生成器
1.存放数据的容器
字符 布尔 整形 列表 字典 集合 元组 都可以存放数据
特点1 可变数据类型 ,这种数据容器就是id不变,值可变,不可以hash ,元素可以任意更改
不可变数据类型 ,这种数据容器就是id不变,值不可变,可以hash ,元素不可以更改,如果更改了那就变成另一个变量了。
特点2 有序 和 无序 就是数据类型的元素有没有索引 列表是有序的对象集合 字典是无序的对象集合(3.9以上版本支持)
也就是说索引是数字,从0开始,元素有多个值。
列表 有序,可修改,可重复
字典 无序,可修改,key不可重复
元组 有序,不可修改,可重复
集合 无序,可修改,不可重复
特点3 数据类型的强弱
python 是强类型 解释型语言
针对特点1 数据类型的可变特性,引申出另一个问题就是复制数据的时候 copy
可变数据类型 ,复制是完全复制内存地址数据,新数据,旧数据修改,完全不相干。
不可变数据类型,复制数据,是多了一个指定内存地址的变量名,数据共用一份,若修改,则全变。
1.3 深浅拷贝
-
浅拷贝
-
不可变类型,不拷贝。
import copy v1 = "武沛齐" print(id(v1)) # 140652260947312 v2 = copy.copy(v1) print(id(v2)) # 140652260947312按理说拷贝v1之后,v2的内存地址应该不同,但由于python内部优化机制,内存地址是相同的,因为对不可变类型而言,如果以后修改值,会重新创建一份数据,不会影响原数据,所以,不拷贝也无妨。
-
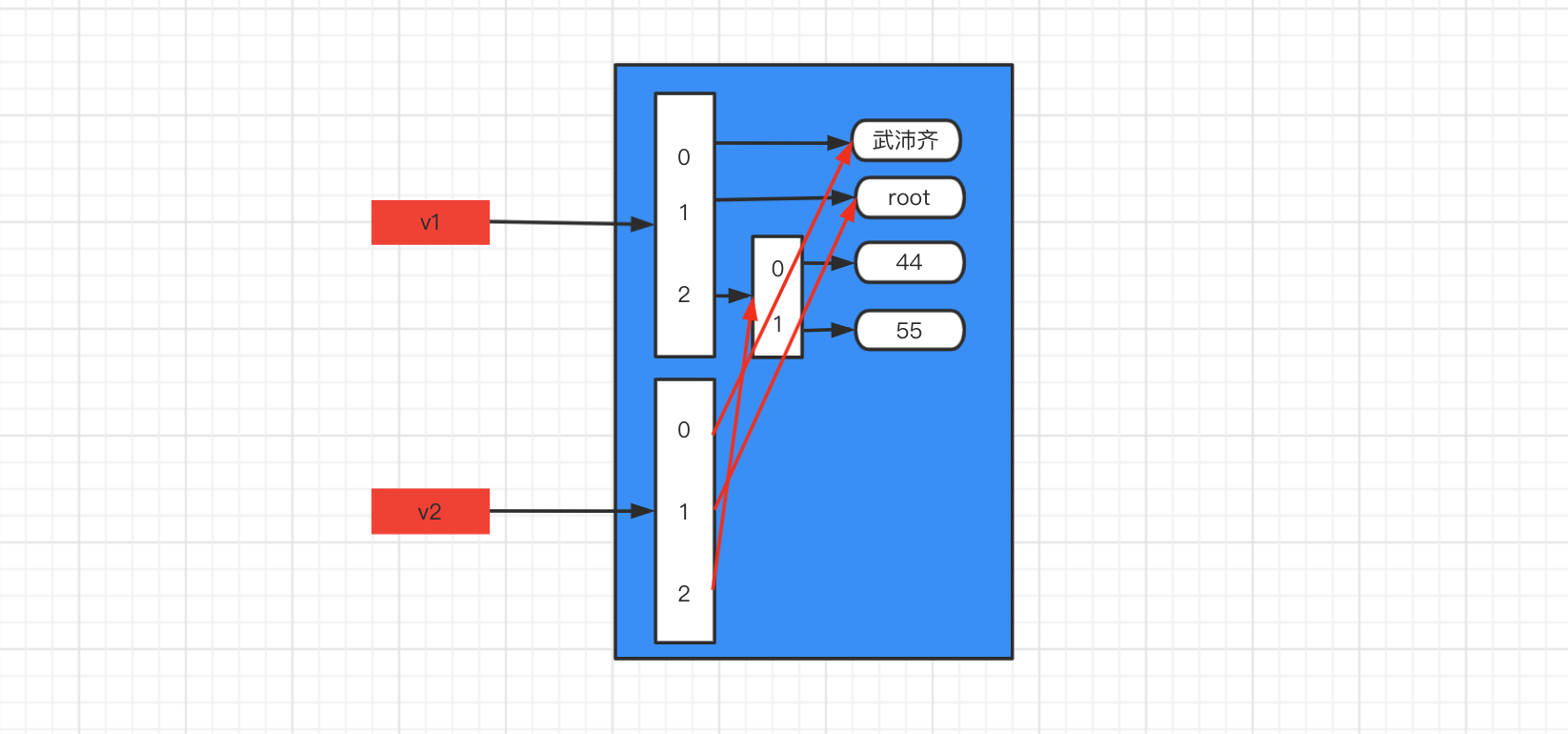
可变类型,只拷贝第一层。
import copy v1 = ["武沛齐", "root", [44, 55]] print(id(v1)) # 140405837216896 print(id(v1[2])) # 140405837214592 v2 = copy.copy(v1) print(id(v2)) # 140405837214784 print(id(v2[2])) # 140405837214592![image-20210106151332792]()
-
-
深拷贝
-
不可变类型,不拷贝
import copy v1 = "武沛齐" print(id(v1)) # 140188538697072 v2 = copy.deepcopy(v1) print(id(v2)) # 140188538697072特殊的元组:
-
元组元素中无可变类型,不拷贝
import copy v1 = ("武沛齐", "root") print(id(v1)) # 140243298961984 v2 = copy.deepcopy(v1) print(id(v2)) # 140243298961984 -
元素元素中有可变类型,找到所有【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ("武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]) v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784
-
-
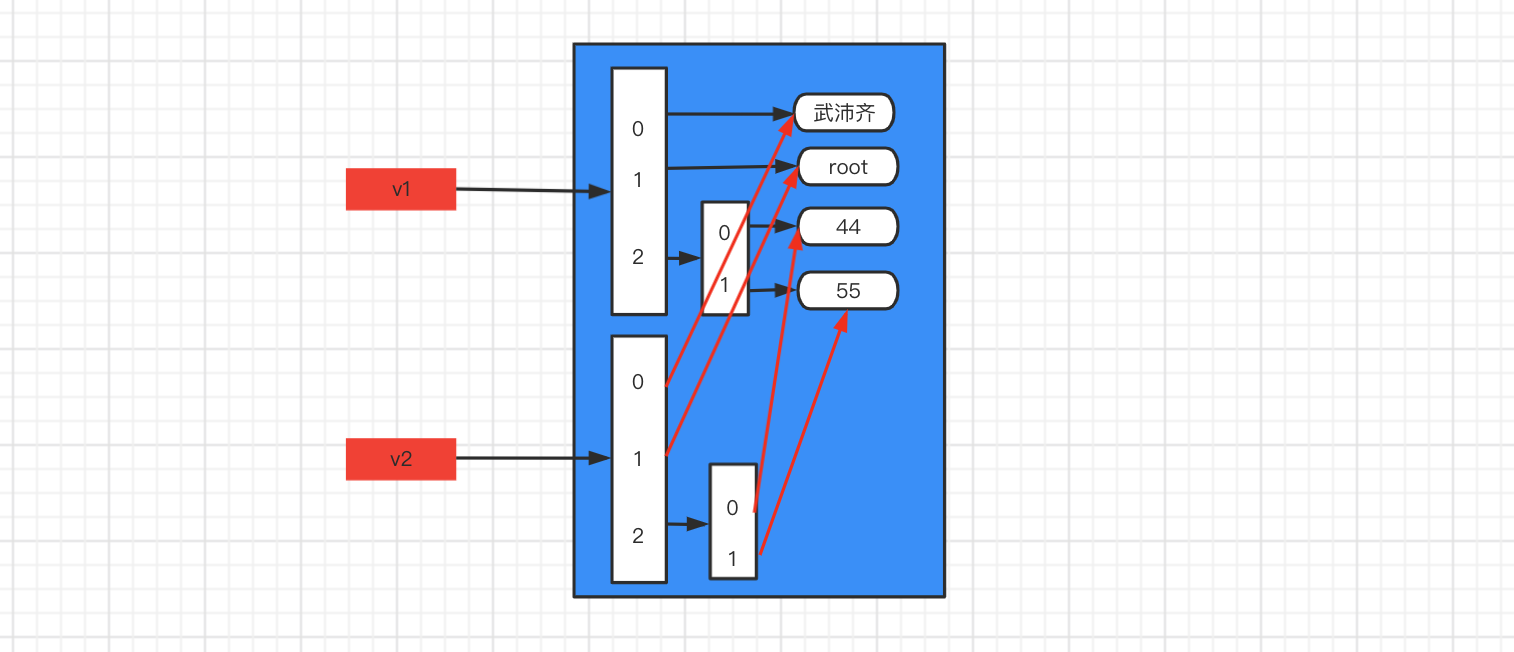
可变类型,找到所有层级的 【可变类型】或【含有可变类型的元组】 均拷贝一份
import copy v1 = ["武沛齐", "root", [11, [44, 55], (11, 22), (11, [], 22), 33]] v2 = copy.deepcopy(v1) print(id(v1)) # 140391475456384 print(id(v2)) # 140391475456640 print(id(v1[2])) # 140352552779008 print(id(v2[2])) # 140352552920448 print(id(v1[2][1])) # 140642999940480 print(id(v2[2][1])) # 140643000088832 print(id(v1[2][2])) # 140467039914560 print(id(v2[2][2])) # 140467039914560 print(id(v1[2][3])) # 140675479841152 print(id(v2[2][3])) # 140675480454784import copy v1 = ["武沛齐", "root", [44, 55]] v2 = copy.deepcopy(v1) print(id(v1)) # 140405837216896 print(id(v2)) # 140405837214784 print(id(v1[2])) # 140563140392256 print(id(v2[2])) # 140563140535744![image-20210106152704591]()
-
迭代器
针对特点2 数据类型的有序特性和无序特性,引申一个问题,要把一个变量的值依次取出,有序类型设置了索引值,根据索引取值,那么没有索引的类型如何依次取值。
比如 字典 集合 文件,不依赖索引的取值方式是什么?
迭代:是一个重复的过程,但每次重复都是基于上一次的结果而来的。
迭代器: 不依赖索引的取值工具,简单点就是能把字典 集合 文件的值依次取出来
dict_value = {
'name':"aa",
'age':"bb",
'gender':"cc",
}
字典的迭代取值的需求如何实现 ,
详细过程解剖:
dict_iterator = dict_value.__iter__() #字典内置了一个iter方法,调用,就是做成了一个迭代器,
res1 = dict_iterator.__next__() # 字典的迭代器调用next方法,就可以一个一个的取值。
res2 = dict_iterator.__next__()
res3 = dict_iterator.__next__()
print(res1)
print(res2)
print(res3)
简化代码 dit
dict_iterator = dict_value.__iter__()
while True:
try:
res = dict_iterator.__next__()
print(res)
except StopIteration:
break
StopIteration 报错
name
age
gender
有__iter__方法的
没有索引的
1 字典
2 集合
3 文件对象或者句柄
有索引的
1、字符串
2、列表
3、元组
总结 python 不仅为有索引的数据类型配置了迭代取值的功能,也为没有索引的数据类型配置迭代取值的功能
迭代取值是python的通用的取值功能
这些数据类型就是通过__iter__的方法形成一个 可以迭代的数据类型,简称可迭代类型 或者可迭代对象
字典内置了一个iter方法,调用,就是做成了一个迭代器,
迭代器的对象有一个 __next__ 方法取值,, 为什么也有一个 __iter__()方法,
实验 迭代器对象调用iter方法 返回的是本身。
print(dict_iterator.__iter__() is dict_iterator)
返回值 True
print([11,222,444].__iter__())
print({'name':"aa", 'age':"bb",'gender':"cc",}.__iter__())
dict_value = {
'name':"aa",
'age':"bb",
'gender':"cc",
}
dict_iterator = dict_value.__iter__()
for 调用可迭代对象的iter方法,然后调用 迭代器对象的next的方法,依次读出数据
for item in dict_value:
print(item)
for 调用迭代器对象的的iter方法,然后调用 迭代器对象的next的方法,依次读出数据
for item in dict_iterator:
print(item)
最后 for 循环捕捉异常解释循环
while True:
try:
res = dict_iterator.__next__()
print(res)
except StopIteration:
break
结论
1、在python的设计中,迭代取值是数据类型的通用方法,
不论是可迭代对象 或者是迭代器对象 都是可以通过 iter方法返回成 迭代器对象调用next方法迭代取值。
有iter方法的就是可迭代对象 所有的数据类型都是可迭代对象
有next方法的就是迭代器对象
只有 文件 既是迭代器对象,也是可迭代对象 只有文件才有可能有非常庞大的数据,所以直接做成 迭代器对象
2、迭代器 可以 惰性计算 ,节省内存。
目前使用的数据是已经创建的容器(比如字典中有100万个值),而要使用迭代器省内存就必须存进去100万个值,这样内存早就撑死了。
也就是目录使用的迭代器就是以现有数据转成的迭代器,达不到节省内存的效果、
引出自定义容器,也就是生成器。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号