python 2.06 嵌套函数 装饰器
1. 函数嵌套
Python中以函数为作用域,在作用域中定义的相关数据只能被当前作用域或子作用域使用。
NAME = "武沛齐"
print(NAME)
def func():
print(NAME)
func()
1.1 函数在作用域中
其实,函数也是定义在作用域中的数据,在执行函数时候,也同样遵循:优先在自己作用域中寻找,没有则向上一接作用域寻找,例如:
# 1. 在全局作用域定义了函数func
def func():
print("你好")
# 2. 在全局作用域找到func函数并执行。
func()
# 3.在全局作用域定义了execute函数
def execute():
print("开始")
# 优先在当前函数作用域找func函数,没有则向上级作用域中寻找。
func()
print("结束")
# 4.在全局作用域执行execute函数
execute()
此处,有一个易错点:作用域中的值在被调用时到底是啥?
-
情景1
def func(): print("你好") func() def execute(): print("开始") func() print("结束") execute() def func(): print(666) func() -
情景2
def func(): print("你好") func() def execute(): print("开始") func() print("结束") def func(): print(666) func() execute()
1.2 函数定义的位置
上述示例中的函数均定义在全局作用域,其实函数也可以定义在局部作用域,这样函数被局部作用域和其子作用于中调用(函数的嵌套)。
def func():
print("沙河高晓松")
def handler():
print("昌平吴彦祖")
def inner():
print("朝阳大妈")
inner()
func()
print("海淀网友")
handler()
到现在你会发现,只要理解数据定义时所存在的作用域,并根据从上到下代码执行过程进行分析,再怎么嵌套都可以搞定。
现在的你可能有疑问:为什么要这么嵌套定义?把函数都定义在全局不好吗?
其实,大多数情况下我们都会将函数定义在全局,不会嵌套着定义函数。不过,当我们定义一个函数去实现某功能,想要将内部功能拆分成N个函数,又担心这个N个函数放在全局会与其他函数名冲突时(尤其多人协同开发)可以选择使用函数的嵌套。
def f1():
pass
def f2():
pass
def func():
f1()
f2()
def func():
def f1():
pass
def f2():
pass
f1()
f2()
"""
生成图片验证码的示例代码,需要提前安装pillow模块(Python中操作图片中一个第三方模块)
pip3 install pillow
"""
import random
from PIL import Image, ImageDraw, ImageFont
def create_image_code(img_file_path, text=None, size=(120, 30), mode="RGB", bg_color=(255, 255, 255)):
""" 生成一个图片验证码 """
_letter_cases = "abcdefghjkmnpqrstuvwxy" # 小写字母,去除可能干扰的i,l,o,z
_upper_cases = _letter_cases.upper() # 大写字母
_numbers = ''.join(map(str, range(3, 10))) # 数字
chars = ''.join((_letter_cases, _upper_cases, _numbers))
width, height = size # 宽高
# 创建图形
img = Image.new(mode, size, bg_color)
draw = ImageDraw.Draw(img) # 创建画笔
def get_chars():
"""生成给定长度的字符串,返回列表格式"""
return random.sample(chars, 4)
def create_lines():
"""绘制干扰线"""
line_num = random.randint(*(1, 2)) # 干扰线条数
for i in range(line_num):
# 起始点
begin = (random.randint(0, size[0]), random.randint(0, size[1]))
# 结束点
end = (random.randint(0, size[0]), random.randint(0, size[1]))
draw.line([begin, end], fill=(0, 0, 0))
def create_points():
"""绘制干扰点"""
chance = min(100, max(0, int(2))) # 大小限制在[0, 100]
for w in range(width):
for h in range(height):
tmp = random.randint(0, 100)
if tmp > 100 - chance:
draw.point((w, h), fill=(0, 0, 0))
def create_code():
"""绘制验证码字符"""
if text:
code_string = text
else:
char_list = get_chars()
code_string = ''.join(char_list) # 每个字符前后以空格隔开
# Win系统字体
# font = ImageFont.truetype(r"C:\Windows\Fonts\SEGOEPR.TTF", size=24)
# Mac系统字体
# font = ImageFont.truetype("/System/Library/Fonts/SFNSRounded.ttf", size=24)
# 项目字体文件
font = ImageFont.truetype("MSYH.TTC", size=15)
draw.text([0, 0], code_string, "red", font=font)
return code_string
create_lines()
create_points()
code = create_code()
# 将图片写入到文件
with open(img_file_path, mode='wb') as img_object:
img.save(img_object)
return code
code = create_image_code("a2.png")
print(code)
1.3 嵌套引发的作用域问题
基于内存和执行过程分析作用域。
name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
inner()
run()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return inner
v1 = run()
v1()
v2 = run()
v2()

name = "武沛齐"
def run():
name = "alex"
def inner():
print(name)
return [inner,inner,inner]
func_list = run()
func_list[2]()
func_list[1]()
funcs = run()
funcs[2]()
funcs[1]()
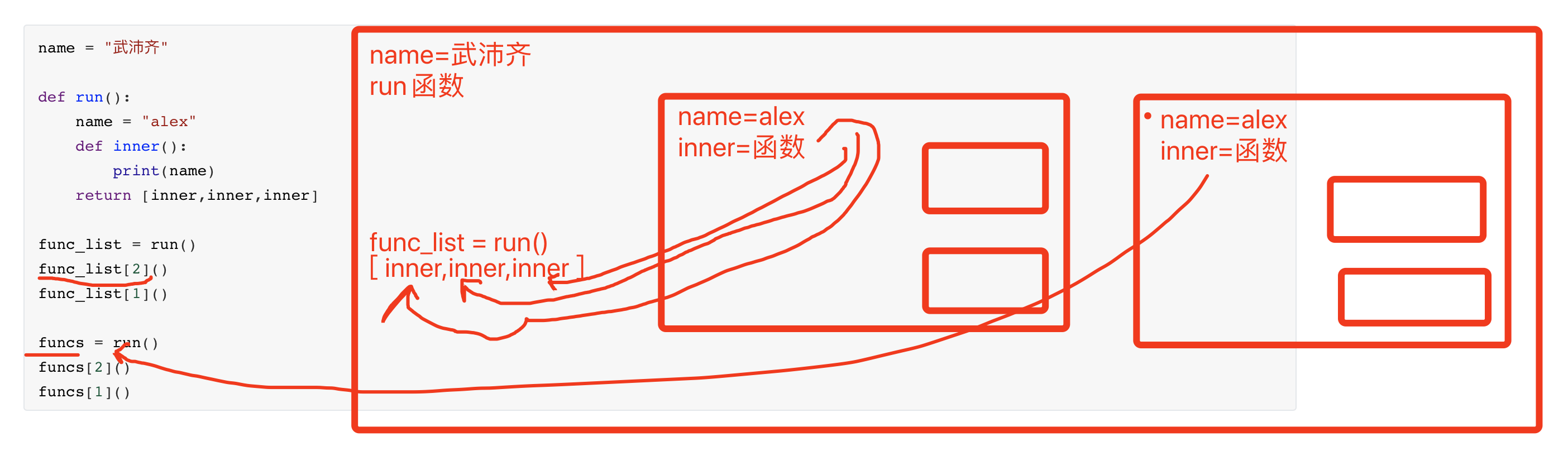
三句话搞定作用域:
- 优先在自己的作用域找,自己没有就去上级作用域。
- 在作用域中寻找值时,要确保此次此刻值是什么。
- 分析函数的执行,并确定函数
作用域链。(函数嵌套)
练习题
-
分析代码,写结果
name = '武沛齐' def func(): def inner(): print(name) res = inner() return res v = func() print(v) # 武沛齐 # None -
分析代码,写结果
name = '武沛齐' def func(): def inner(): print(name) return "alex" res = inner() return res v = func() print(v) # 武沛齐 # alex -
分析代码,写结果
name = 'root' def func(): def inner(): print(name) return 'admin' return inner v = func() result = v() print(result) # root # admin -
分析代码,写结果
def func(): name = '武沛齐' def inner(): print(name) return '路飞' return inner v11 = func() data = v11() print(data) v2 = func()() print(v2) -
分析代码,写结果
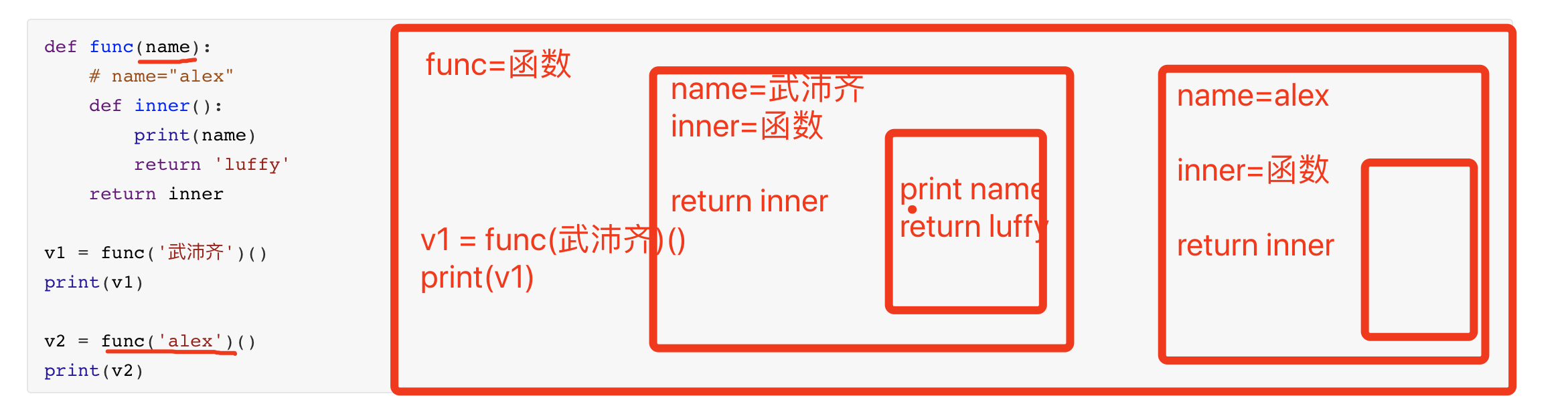
def func(name): # name="alex" def inner(): print(name) return 'luffy' return inner v1 = func('武沛齐')() print(v1) v2 = func('alex')() print(v2)![image-20201229140559322]()
def func(name): def inner(): print(name) return 'luffy' return inner v1 = func('武沛齐') v2 = func('alex') v1() v2()![image-20201229165929911]()
-
分析代码,写结果
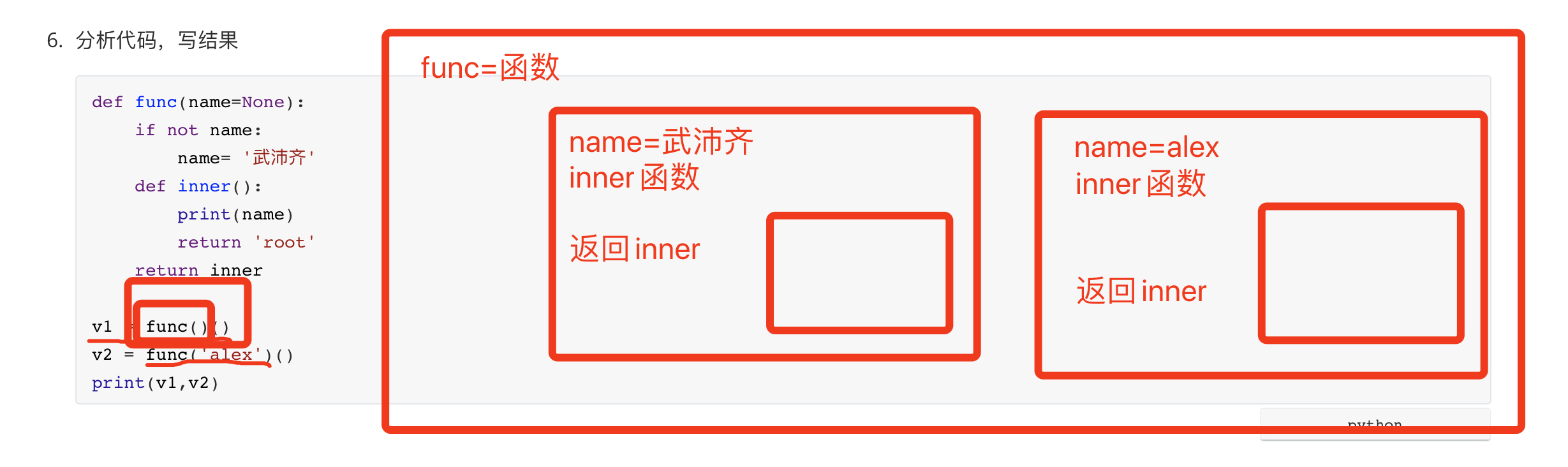
def func(name=None): if not name: name= '武沛齐' def inner(): print(name) return 'root' return inner v1 = func()() v2 = func('alex')() print(v1,v2) # 武沛齐 # alex # root root![image-20201229171258454]()

2.闭包
闭包,简而言之就是将数据封装在一个包(区域)中,使用时再去里面取。(本质上 闭包是基于函数嵌套搞出来一个中特殊嵌套)
-
闭包应用场景1:封装数据防止污染全局。
name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) def f4(): passdef func(age): name = "武沛齐" def f1(): print(name, age) def f2(): print(name, age) def f3(): print(name, age) f1() f2() f3() func(123) -
闭包应用场景2:封装数据封到一个包里,使用时在取。
![image-20201229181719550]()
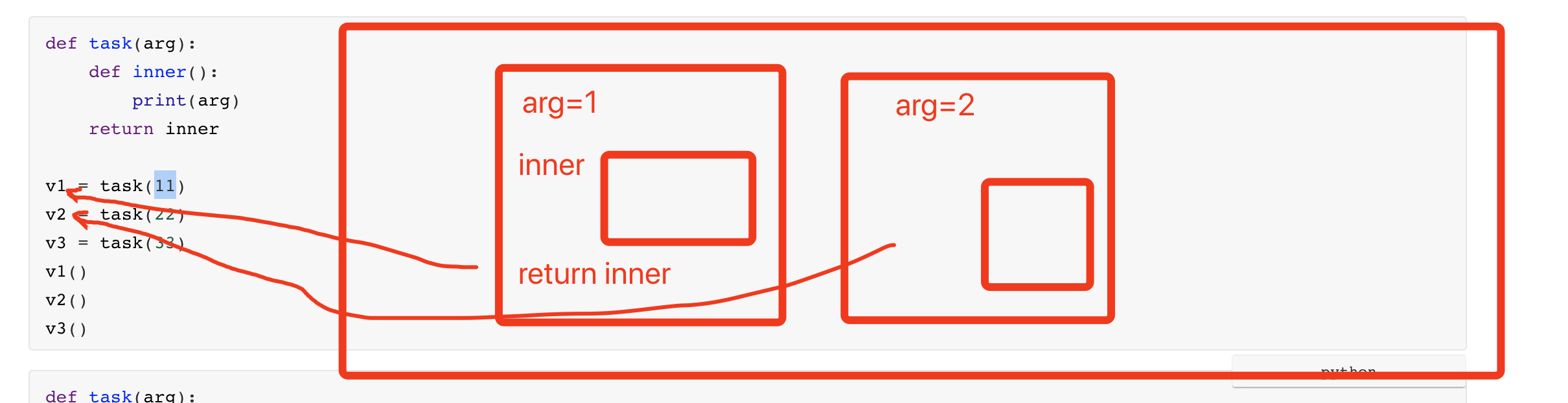
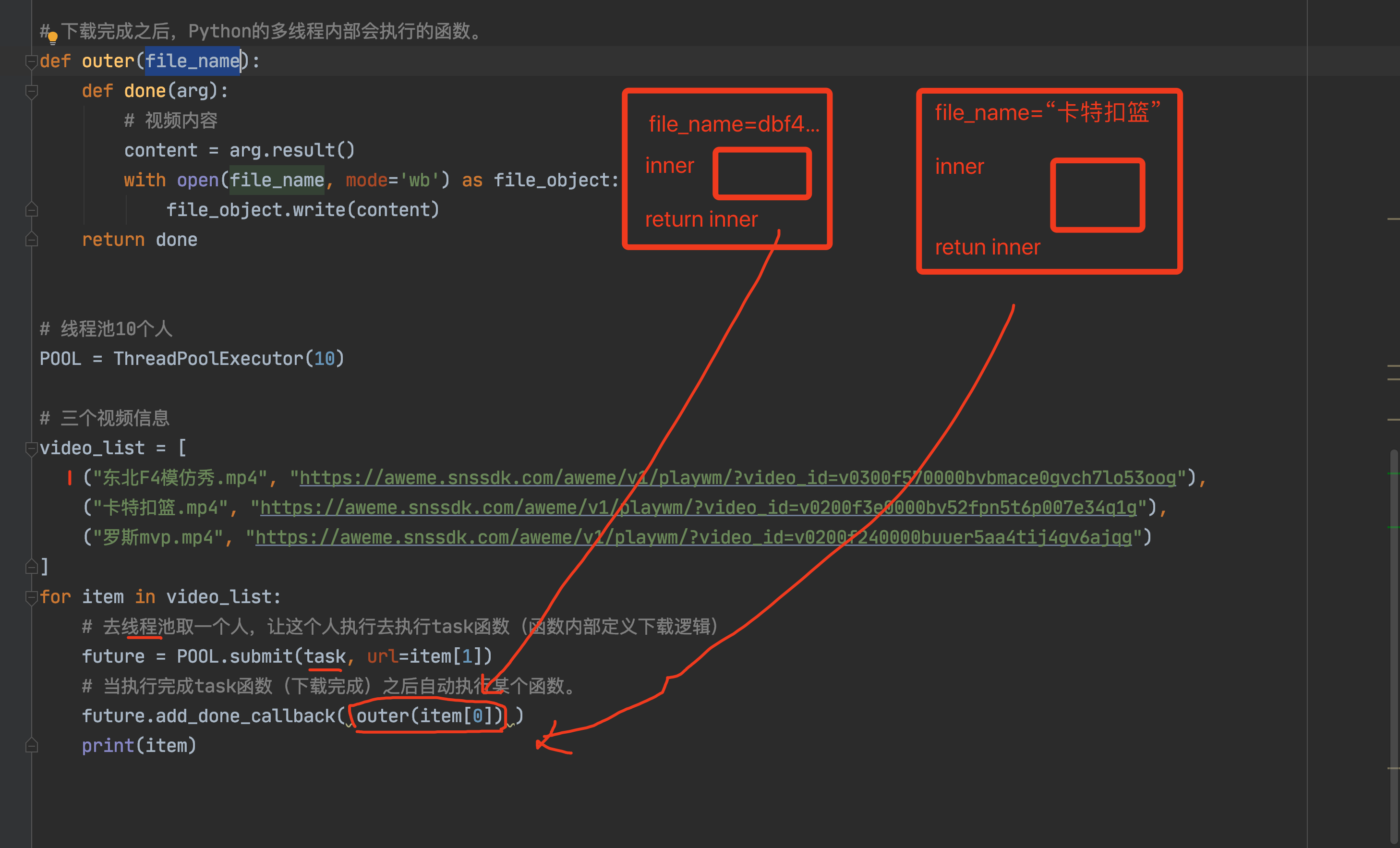
def task(arg): def inner(): print(arg) return inner v1 = task(11) v2 = task(22) v3 = task(33) v1() v2() v3()def task(arg): def inner(): print(arg) return inner inner_func_list = [] for val in [11,22,33]: inner_func_list.append( task(val) ) inner_func_list[0]() # 11 inner_func_list[1]() # 22 inner_func_list[2]() # 33""" 基于多线程去下载视频 """ from concurrent.futures.thread import ThreadPoolExecutor import requests def download_video(url): res = requests.get( url=url, headers={ "user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36 FS" } ) return res.content def outer(file_name): def write_file(response): content = response.result() with open(file_name, mode='wb') as file_object: file_object.write(content) return write_file POOL = ThreadPoolExecutor(10) video_dict = [ ("东北F4模仿秀.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0300f570000bvbmace0gvch7lo53oog"), ("卡特扣篮.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f3e0000bv52fpn5t6p007e34q1g"), ("罗斯mvp.mp4", "https://aweme.snssdk.com/aweme/v1/playwm/?video_id=v0200f240000buuer5aa4tij4gv6ajqg") ] for item in video_dict: future = POOL.submit(download_video, url=item[1]) future.add_done_callback(outer(item[0])) POOL.shutdown()![image-20201229185549102]()
装饰器推导过程 (有参无参)
闭包函数 推导过程
什么是装饰器 : 在不改变原来函数功能的前提,增加额外的功能
装饰器语法 @ 和执行顺序的问题
闭包函数定义在一个函数内部的函数(函数的嵌套定义)
闭: 该函数是封闭在一个函数内部的函数
包: 该函数访问了一个来自于外层函数的变量。(通过名称空间的作用,上层函数可以达到为内部函数提供传参的功能)
1、直接为函数体传参
def outter(x):
pass
outter(123)
2 直接包给函数 ,使用了名称空间的嵌套关系
def outter():
x = 1
def wrapper():
print(x)
wrapper()
3、原来的wrappper是在全局的函数,现在使用函数空间嵌套可以传参,那么如何在全局在调用
如何把函数再推回全局,在顶级函数中使用return 把函数名所对应的内存地址返回到全局中
def outter():
x = 1
def wrapper():
print(x)
return wrapper
wrapper = outter()
wrapper()
4 x= 1 相当于固定死了一个状态,如何变更的更加灵活
def outter(x):
# 为outter传参x,相当于 在outter 内部做了一个 x = 111
def wrapper():
print(x)
return wrapper
res1 = outter(111)
res2 = outter(222)
res1()
res2()
总结: 闭包函数的特点: 1、函数定义在一个函数的内部, 2、使用名称空间的嵌套关系,访问外层函数的变量作为自己的传参。
3、、return 函数名 结合了函数对象应用 ,把内部的函数变成了全局函数,在任意位置使用,但是用的值还是函数内部的值
全局函数的调用wrapper 携带了一种状态就是x=1 ,而且是定义阶段定义的
什么是装饰器 : 在不改变原来函数功能的前提,增加额外的功能
为什么用装饰器
在开发过程中,上线后的提供业务的系统要求是稳定的,同时还要扩展添加其他功能。
为了遵循开放封闭原则 :对扩展新功能开放,对修改源代码封闭
在不修改源代码的前提下,增加新的功能,所以使用装饰器
不修改被装饰对象指的是定义和调用都不能修改
案例1 查看一个函数运行的时间
import time
def index(x,y):
start_time = time.time()
time.sleep(1)
print('..........',x,y)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
index(4,5)
案例2 查看一个函数运行的时间,上面的函数变更了源代码。
import time
def index(x,y):
time.sleep(1)
print('..........',x,y)
start_time = time.time()
index(4,5)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
案例3 如果index函数被调用了N次,那么将在N个函数前后加上开始和结束时间,不实用,如何处理
import time
def index(x,y):
time.sleep(1)
print('..........',x,y)
def wrapper():
start_time = time.time()
index(4,5)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
wrapper()
wrapper()
案例4 3的代码可以简化了单一函数的调用,函数名写死了,但是如果要统计n个函数的运行时间,那么wrapper函数这种函数就要写重复代码了
如何把wrapper 函数写活
import time
def index(x,y):
time.sleep(1)
print('..........',x,y)
def wrapper(func):
start_time = time.time()
func(4,5) # 把要统计时间的函数的名字直接传到 wrapper函数内,调用warpper
stop_time = time.time()
print('run %s'%(stop_time-start_time))
wrapper(index)
问题1 改变了index函数的调用方式
案例5 如何在不改变源代码,不改变调用方式,不写重复代码的情况下,完成对原函数添加一个统计时间的功能
import time
def index(x,y):
time.sleep(1)
print('..........',x,y)
def home(x,y):
time.sleep(1)
print('..........',x,y)
def outter(func):
def wrapper():
start_time = time.time()
func(1,2)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
return wrapper
index=outter(index)
home=outter(home)
问题1 改变了index函数的调用方式,而且无法对 闭包函数 进行传参
已经把outter函数伪装成了index 但是伪装的还是不够全面,参数还不能传进去
案例6 如何在不改变源代码,不改变调用方式,不写重复代码的情况下,完成对原函数添加一个统计时间的功能
如何让使用者在调用index函数的时候,参数也能传进去
import time
def index(x,y):
time.sleep(1)
print('..........',x,y)
def home(name):
print("wecome %s"%(name))
time.sleep(2)
def outter(func):
def wrapper(*xargs,**kwxargs):
start_time = time.time()
func(*xargs,**kwxargs)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
return wrapper
index=outter(index)
home= outter(home)
index(1,2)
home('123')
问题 函数的4大特性, 定义 调用 传参 返回值
调用一致, 传参一致,,但是 实际调用的函数是wrapper函数 ,该函数的返回值是 是没有定义的,就算是定义了
也不是被装饰函数的返回值,如何把返回值伪装
案例7 返回值的伪装
要达到被伪装函数的返回值 直接赋值给调用的装饰器就可以了
import time
# 装饰器函数一般放在 最上方
def outter(func):
def wrapper(*xargs,**kwxargs):
start_time = time.time()
#func(*xargs,**kwxargs)
res = func(*xargs,**kwxargs)
# 把调用的函数的返回值赋值给变量,wrapper 返回这个变量就可以实现了
stop_time = time.time()
print('run %s'%(stop_time-start_time))
return res
return wrapper
def index(x,y):
time.sleep(1)
print('..........',x,y)
def home(name):
print("wecome %s"%(name))
time.sleep(2)
return 123
index=outter(index)
home= outter(home)
#
#
# print(index(1,2))
# print(home('123'))
# 证明 index函数的返回值是None home函数的返回值就是123
print(home.__name__) # 查看home 函数的实际函数名
print(home.__doc__) # 查看home函数的文档注释
# 问题: home函数的属性内容已经变成装饰器的属性了,不能查看
# 如何解决属性一致的问题
案例8 解决属性一致的问题
思考 装饰器函数属性和被装饰函数的属性要是一致的话,那么把被装饰函数的属性值赋值给装饰器
属性就可以了
import time
from functools import wraps # 导入一个函数 wraps
def outter(func):
@wraps(func) # 在装饰器功能的函数上 @wraps(func) 这个固定语法就可以实现函数属性的一致性
def wrapper(*xargs,**kwxargs):
# wrapper.__name__ == func.__name__ # 常规的做法变量值相等,
# wrapper.__doc__ == func.__doc__ # 但是函数的内置属性太多了,不便于自己写
# 有官方提供的标准函数使用
start_time = time.time()
res = func(*xargs,**kwxargs)
stop_time = time.time()
print('run %s'%(stop_time-start_time))
return res
return wrapper
def index(x,y):
'函数的文档属性'
time.sleep(1)
print('..........',x,y)
index=outter(index)
print(index.__name__) # 查看home 函数的实际函数名
print(index.__doc__) # 查看home函数的文档注释
装饰器语法 @ 和执行顺序的问题
问题 在案列8中 调用装饰器的代码复杂如何简化
案例9 简化装饰器的代码,使用装饰器语法糖@
装饰器@ 语法要放置到被装饰函数名的上方。
import time
def outter(func):
def wrapper(*xargs,**kwxargs):
start_time = time.time()
#func(*xargs,**kwxargs)
res = func(*xargs,**kwxargs)
# 把调用的函数的返回值赋值给变量,wrapper 返回这个变量就可以实现了
stop_time = time.time()
print('run %s'%(stop_time-start_time))
return res
return wrapper
@outter # 简化装饰器的语法书写
def index(x,y):
time.sleep(1)
print('..........',x,y)
index(1,2)
案例10 装饰器的书写精简的模板
def outter(func):
def wrapper(*xargs,**kwargs):
# 要添加装饰的功能
res = func(*xargs,**kwargs)
return res
return wrapper
延伸 案例10 装饰器的叠加使用
一个打印时间函数times的功能
为times添加一个统计时间的功能
为times 添加一个验证用户和密码的功能 验证用户名和密码后 才能调用
import time
def outter(func):
def wrapper(*xargs,**kwargs):
start_time = time.time()
time.sleep(1)
res = func(*xargs,**kwargs)
stop_time = time.time()
print('该函数运行的时间是%s秒'%(stop_time-start_time))
return res
return wrapper
def longin(func):
def wrapper(*xargs,**kwargs):
inm_name = input("输入用户名:")
inm_passwd = input("输入密码:")
if inm_name == "zhangsan" and inm_passwd == '123':
res = func(*xargs,**kwargs)
return res
else:
print('error')
return wrapper
# 添加一个身份识别的功能,识别成功调用,不成功打印错误。
@longin
# 添加一个统计运行时间的功能
@outter
def times():
print(time.time())
times()
总结
1、代码定义阶段是从下往上的顺序
2、代码执行时从上往下执行
无参装饰器模板
def outter(func):
def wrapper(*xargs,**kwargs):
res= func(*xargs,**kwargs)
return res
return wrapper
有参装饰器模板
def outter1(a,b,c,d,e):
def outter(func):
def wrapper(*xargs, **kwargs):
# 代码块
res = func(*xargs, **kwargs)
# 代码块
return res
return wrapper
return outter
@outter1(a=1,b=2,c=3,d=4,e=5)
def index():
pass
无参装饰器
@deco 语法意义: 程序运行到@时,会调用deco这个函数,并且把正下面一个函数当作参数传进来,把返回值赋值给原函数
无参装饰器的分析
def outter(func):
def wrapper(*xargs,**kwargs):
# codeing
res = func(*xargs,**kwargs)
return res
return wrapper
@outter
def index(a,b):
print('%s %s'%(a,b))
index(1,2)
1、装饰器本质为index函数添加额外的功能,让函数的调用方式,返回值不发生变化的一种手段。
2、当程序检测到@ 语法时,会把正下方的函数名作为参数传到 @函数内,相当于先运行了@后的函数。
当有多个@函数时按照从上到下的方式运行。
3、在上面例子装饰器函数中 第一层函数的参数为被装饰的函数名, 第二层函数的参数为被装饰函数的参数,
第二层函数的代码块是 添加的功能代码,和 源函数调用语句
有参装饰器
问题1、longin函数输入完用户和密码后 ,如何进行比对
用户和密码的来源有多种的途径 比如 数据库,文件,在装饰器过程中 如何抽取不同源的数据做认证。
也就是说为装饰器本身传参?
案列1 解决装饰器自身的传参问题
import time
def outter(func):
def wrapper(*xargs,**kwargs):
start_time = time.time()
time.sleep(1)
res = func(*xargs,**kwargs)
stop_time = time.time()
print('run %sS'%(stop_time-start_time))
return res
return wrapper
def outter1(engine):
def longin(func):
def wrapper(*xargs,**kwargs):
inm_name = input("user:")
inm_passwd = input("password:")
if engine == 'file':
print('file passwd')
if inm_name == '123' and inm_passwd=='123':
res = func(*xargs,**kwargs)
return res
elif engine == 'mysql':
print('mysql')
else:
print('未知的源数据')
return wrapper
return longin
loggin = outter1('mysql') # 代码多余如何精简
@loggin
@outter
def times():
print(time.time())
times()
问题 装饰器传参 本身是在装饰器的外层再加一层函数包起来,达到为函数内传参的效果。
查看代码后发现,需要精简代码?
import time
def outter1(engine):
def longin(func):
def wrapper(*xargs,**kwargs):
inm_name = input("user:")
inm_passwd = input("password:")
if engine == 'file':
print('file passwd')
if inm_name == '123' and inm_passwd=='123':
res = func(*xargs,**kwargs)
return res
elif engine == 'mysql':
print('mysql')
else:
print('未知的源数据')
return wrapper
return longin
# loggin = outter1('mysql') # 代码多余如何精简
@outter1('mysql') # 精简的写法 直接@ + 函数的返回值(使用了函数调用的多样性) + 函数的参数
def times():
print(time.time())
times()
有参装饰的总结:
1、三层函数的装饰器最外层可以添加多个额外的参数在,所以不需要在去包多层函数了最多三层
2、语法调用直接写装饰器最外层函数的返回值,把下面函数名作为参数传入装饰器内执行,返回值返回给原始的函数
3.装饰器
现在给你一个函数,在不修改函数源码的前提下,实现在函数执行前和执行后分别输入 "before" 和 "after"。
def func():
print("我是func函数")
value = (11,22,33,44)
return value
result = func()
print(result)
3.1 第一回合
你的实现思路:
def func():
print("before")
print("我是func函数")
value = (11,22,33,44)
print("after")
return value
result = func()
我的实现思路:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
origin()
print("after")
return inner
func = outer(func)
result = func()
处理返回值:
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
func = outer(func)
result = func()
3.2 第二回合
在Python中有个一个特殊的语法糖:
def outer(origin):
def inner():
print('inner')
res = origin()
print("after")
return res
return inner
@outer
def func():
print("我是func函数")
value = (11, 22, 33, 44)
return value
func()
3.3 第三回合
请在这3个函数执行前和执行后分别输入 "before" 和 "after"
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
你的实现思路:
def func1():
print('before')
print("我是func1函数")
value = (11, 22, 33, 44)
print("after")
return value
def func2():
print('before')
print("我是func2函数")
value = (11, 22, 33, 44)
print("after")
return value
def func3():
print('before')
print("我是func3函数")
value = (11, 22, 33, 44)
print("after")
return value
func1()
func2()
func3()
我的实现思路:
def outer(origin):
def inner():
print("before 110")
res = origin() # 调用原来的func函数
print("after")
return res
return inner
@outer
def func1():
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer
def func2():
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer
def func3():
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1()
func2()
func3()
装饰器,在不修改原函数内容的前提下,通过@函数可以实现在函数前后自定义执行一些功能(批量操作会更有意义)。
优化
优化以支持多个参数的情况。
def outer(origin):
def inner(*args, **kwargs):
print("before 110")
res = origin(*args, **kwargs) # 调用原来的func函数
print("after")
return res
return inner
@outer # func1 = outer(func1)
def func1(a1):
print("我是func1函数")
value = (11, 22, 33, 44)
return value
@outer # func2 = outer(func2)
def func2(a1, a2):
print("我是func2函数")
value = (11, 22, 33, 44)
return value
@outer # func3 = outer(func3)
def func3(a1):
print("我是func3函数")
value = (11, 22, 33, 44)
return value
func1(1)
func2(11, a2=22)
func3(999)
其中,我的那种写法就称为装饰器。
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
def outer(origin): def inner(*args, **kwargs): # 执行前 res = origin(*args, **kwargs) # 调用原来的func函数 # 执行后 return res return inner @outer def func(): pass func()
伪应用场景
在以后编写一个网站时,如果项目共有100个页面,其中99个是需要登录成功之后才有权限访问,就可以基于装饰器来实现。
pip3 install flask
基于第三方模块Flask(框架)快速写一个网站:
from flask import Flask
app = Flask(__name__)
def index():
return "首页"
def info():
return "用户中心"
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index)
app.add_url_rule("/info/", view_func=info)
app.add_url_rule("/login/", view_func=login)
app.run()
基于装饰器实现的伪代码:
from flask import Flask
app = Flask(__name__)
def auth(func):
def inner(*args, **kwargs):
# 在此处,判断如果用户是否已经登录,已登录则继续往下,未登录则自动跳转到登录页面。
return func(*args, **kwargs)
return inner
@auth
def index():
return "首页"
@auth
def info():
return "用户中心"
@auth
def order():
return "订单中心"
def login():
return "登录页面"
app.add_url_rule("/index/", view_func=index, endpoint='index')
app.add_url_rule("/info/", view_func=info, endpoint='info')
app.add_url_rule("/order/", view_func=order, endpoint='order')
app.add_url_rule("/login/", view_func=login, endpoint='login')
app.run()
重要补充:functools
你会发现装饰器实际上就是将原函数更改为其他的函数,然后再此函数中再去调用原函数。
def handler():
pass
handler()
print(handler.__name__) # handler
def auth(func):
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # inner
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
return func(*args, **kwargs)
return inner
@auth
def handler():
pass
handler()
print(handler.__name__) # handler
其实,一般情况下大家不用functools也可以实现装饰器的基本功能,但后期在项目开发时,不加functools会出错(内部会读取__name__,且__name__重名的话就报错),所以在此大家就要规范起来自己的写法。
import functools
def auth(func):
@functools.wraps(func)
def inner(*args, **kwargs):
"""巴巴里吧"""
res = func(*args, **kwargs) # 执行原函数
return res
return inner
总结
-
函数可以定义在全局、也可以定义另外一个函数中(函数的嵌套)
-
学会分析函数执行的步骤(内存中作用域的管理)
-
闭包,基于函数的嵌套,可以将数据封装到一个包中,以后再去调用。
-
装饰器
-
实现原理:基于@语法和函数闭包,将原函数封装在闭包中,然后将函数赋值为一个新的函数(内层函数),执行函数时再在内层函数中执行闭包中的原函数。
-
实现效果:可以在不改变原函数内部代码 和 调用方式的前提下,实现在函数执行和执行扩展功能。
-
适用场景:多个函数系统统一在 执行前后自定义一些功能。
-
装饰器示例
import functools def auth(func): @functools.wraps(func) def inner(*args, **kwargs): """巴巴里吧""" res = func(*args, **kwargs) # 执行原函数 return res return inner
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号