python 1.4 字符编码 encode+decode
1 进制转换
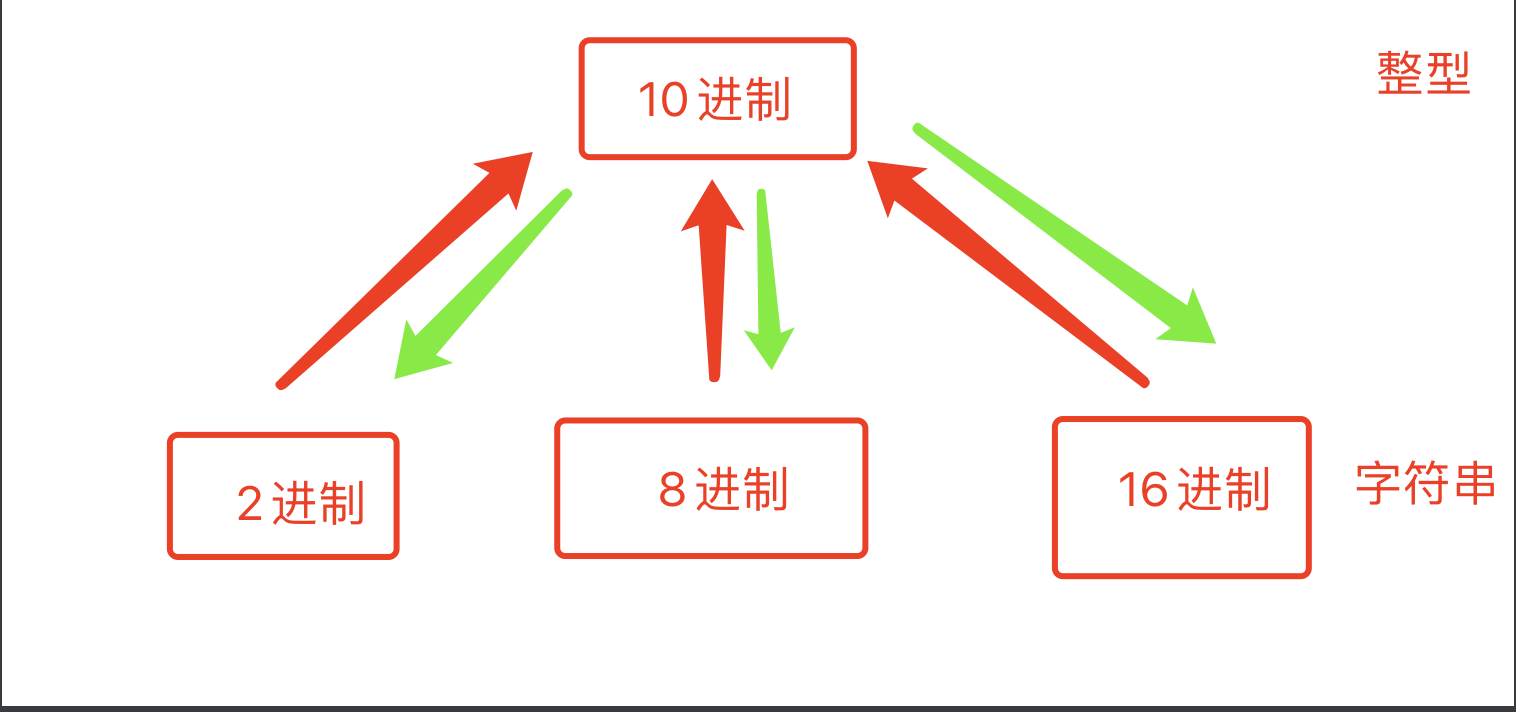
v1 = bin(25) # 十进制转换为二进制
print(v1) # "0b11001"
v2 = oct(23) # 十进制转换为八进制
print(v2) # "0o27"
v3 = hex(28) # 十进制转换为十六进制
print(v3) # "0x1c"
i1 = int("0b11001",base=2) # 25
i2 = int("0o27",base=8) # 23
i3 = int("0x1c",base=16) # 28
2 单位换算
由于计算机中本质上所有的东西以为二进制存储和操作的,为了方便对于二进制值大小的表示,所以就搞了一些单位。
-
b(bit),位
1,1位 10,2位 111,3位 1001,4位 -
B(byte),字节
8位是一个字节。 10010110,1个字节 10010110 10010110,2个字节 -
KB(kilobyte),千字节
1024个字节就是1个千字节。 10010110 11010110 10010111 .. ,1KB 1KB = 1024B= 1024 * 8 b -
M(Megabyte),兆
1024KB就是1M 1M= 1024KB = 1024 * 1024 B = 1024 * 1024 * 8 b -
G(Gigabyte),千兆
1024M就是1G 1 G= 1024 M= 1024 *1024KB = 1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 b -
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么1G流量可以通过网络传输多少汉字呢?(计算机传输本质上也是二进制)
1G = 1024MB = 1024*1024kb *1024 B /2 就是汉字的数量 536870912.0 -
假设1个汉字需要2个字节(2B=16位来表示,如:1000101011001100),那么500G硬盘可以存储多少个汉字?
268435456000.0 1024 mb * 1024kb *1024B /2 *500
3 编码
编码,文字和二进制之间的一个对照表。
ascii编码
ascii规定使用1个字节来表示字母与二进制的对应关系。
ascii 一个字节只有8位,有2**8 255种对应关系
gb-2312编码
gb-2312编码,由国家信息标准委员会制作(1980年)。
gbk编码,对gb2312进行扩展,包含了中日韩等文字(1995年)。
在与二进制做对应关系时,由如下逻辑:
-
单字节表示,用一个字节表示对应关系。2**8 = 256
-
双字节表示,用两个字节表示对应关系。2**16 = 65536中可能性。
4 unicode
unicode也被称为万国码,为全球的每个文字都分配了一个码位(二进制表示)。
-
ucs2
用固定的2个字节去表示一个文字。 00000000 00000000 悟 ... 2**16 = 65535 -
ucs4
用固定的4个字节去表示一个文字。 00000000 00000000 00000000 00000000 无 ... 2**32 = 4294967296
文字 十六进制 二进制
ȧ 0227 1000100111
ȧ 0227 00000010 00100111 ucs2
ȧ 0227 00000000 00000000 00000010 00100111 ucs4
乔 4E54 100111001010100
乔 4E54 01001110 01010100 ucs2
乔 4E54 00000000 00000000 01001110 01010100 ucs4
😆 1F606 11111011000000110
😆 1F606 00000000 00000001 11110110 00000110 ucs4
无论是ucs2和ucs4都有缺点:浪费空间?
文字 十六进制 二进制
A 0041 01000001
A 0041 00000000 01000001
A 0041 00000000 00000000 00000000 01000001
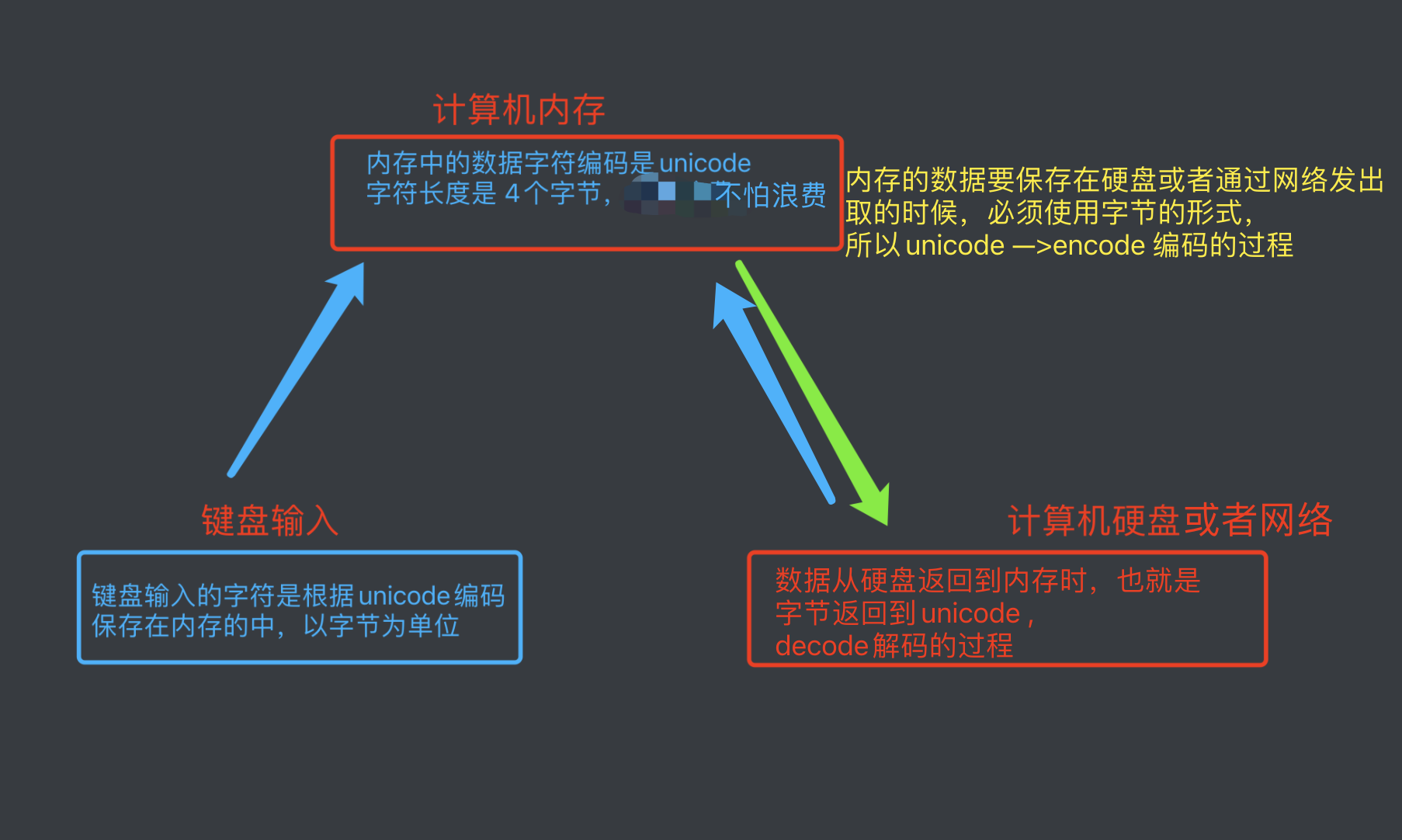
unicode的应用:在文件存储和网络传输时,不会直接使用unicode,而在内存中会unicode。
5 总结
-
计算机初始只表示英文字母和特殊符号,用ascii编码的255个范围就可以完成
-
但是其他国家的例如 中文,汉语 ,日语等等文字也需要编码表示自己的语言,所以也创建了一些字符编码 比如gb2312 等等,使用2个字节表示,比ascii 编码大了一倍。
-
后期为了能够为了统一编码,制作出了万国码 unicode 编码,unicode有两种规范,一个是usc2 使用2个字节,16位 一个是usc4 使用4个字节 32位。囊括了全球所有的文字信息。
-
弊端是 文件存储 和数据传输过程中,如果使用unicode, a这个字母就会占用4个字节,对比 ascii编码来说,翻4倍,浪费空间
-
为了解决浪费的问题,在文件存储和网络传输时不会直接使用unicode,而在内存中会unicode。
6 UTF8
- 为了避免unicode的浪费的问题,就需要一种机制 检查一个字符所在的位数,对应一种存储方式,那就是utf的压缩机制
- 比如一个A 可以使用 8位表达,那就使用1个字节取占位,如果是中文,那就用 2个字节,或者3个字节去占位
- 本质上:utf-8是对unicode的压缩,用尽量少的二进制去与文字进行对应。
unicode码位范围 utf-8
0000 ~ 007F 用1个字节表示
0080 ~ 07FF 用2个字节表示
0800 ~ FFFF 用3个字节表示
10000 ~ 10FFFF 用4个字节表示
具体压缩的流程:
-
第一步:选择转换模板
码位范围(十六进制) 转换模板 0000 ~ 007F 0XXXXXXX 0080 ~ 07FF 110XXXXX 10XXXXXX 0800 ~ FFFF 1110XXXX 10XXXXXX 10XXXXXX 10000 ~ 10FFFF 11110XXX 10XXXXXX 10XXXXXX 10XXXXXX 例如: "B" 对应的unicode码位为 0042,那么他应该选择的一个模板。 "ǣ" 对应的unicode码位为 01E3,则应该选择第二个模板。 "武" 对应的unicode码位为 6B66,则应该选择第三个模板。 "沛" 对应的unicode码位为 6C9B,则应该选择第三个模板。 "齐" 对应的unicode码位为 9F50,则应该选择第三个模板。 😆 对应的unicode码位为 1F606,则应该选择第四个模板。 注意:一般中文都使用第三个模板(3个字节),这也就是平时大家说中文在utf-8中会占3个字节的原因了。 -
第二步:在模板中填入数据
- "武" -> 6B66 -> 110 101101 100110 - 根据模板去套入数据 1110XXXX 10XXXXXX 10XXXXXX 1110XXXX 10XXXXXX 10100110 1110XXXX 10101101 10100110 11100110 10101101 10100110 在UTF-8编码中 ”武“ 11100110 10101101 10100110 - 😆 -> 1F606 -> 11111 011000 000110 - 根据模板去套入数据 11110000 10011111 10011000 10000110
字符总结
- 计算机所有的数据都是以二进制的形式存在的,不过是方便阅读,制作了不同的二进制和文字的对照表
- 内存的数据进行encode编码成字节,以utf-8 的形式存放,或者发送。
- 数据再次加载到内存时,要从字节转成字符,以utf-8编码 还原 。
扩展知识点
1、windows系统使用的GBK编码格式,Linux系统使用的UTF-8编码格式
2、文件路径的表现方式 /root/etc C:\user

 浙公网安备 33010602011771号
浙公网安备 33010602011771号