吴恩达深度学习笔记-8.2(机器学习策略-下)
误差分析
对已经建立的机器学习模型进行错误分析(error analysis)十分必要,而且有针对性地、正确地进行error analysis更加重要。
举个例子,猫类识别问题,已经建立的模型的错误率为10%。为了提高正确率,我们发现该模型会将一些狗类图片错误分类成猫。一种常规解决办法是扩大狗类样本,增强模型对够类(负样本)的训练。但是,这一过程可能会花费几个月的时间,耗费这么大的时间成本到底是否值得呢?也就是说扩大狗类样本,重新训练模型,对提高模型准确率到底有多大作用?这时候我们就需要进行error analysis,帮助我们做出判断。
方法很简单,我们可以从分类错误的样本中统计出狗类的样本数量。根据狗类样本所占的比重,判断这一问题的重要性。假如狗类样本所占比重仅为5%,即时我们花费几个月的时间扩大狗类样本,提升模型对其识别率,改进后的模型错误率最多只会降低到9.5%。相比之前的10%,并没有显著改善。我们把这种性能限制称为ceiling on performance。相反,假如错误样本中狗类所占比重为50%,那么改进后的模型错误率有望降低到5%,性能改善很大。因此,值得去花费更多的时间扩大狗类样本。
这种error analysis虽然简单,但是能够避免花费大量的时间精力去做一些对提高模型性能收效甚微的工作,让我们专注解决影响模型正确率的主要问题,十分必要。
这种error analysis可以同时评估多个影响模型性能的因素,通过各自在错误样本中所占的比例来判断其重要性。例如,猫类识别模型中,可能有以下几个影响因素:
-- 狗被误认作猫
-- 大型猫科动物被误认作猫
-- 对于模糊图片的误判
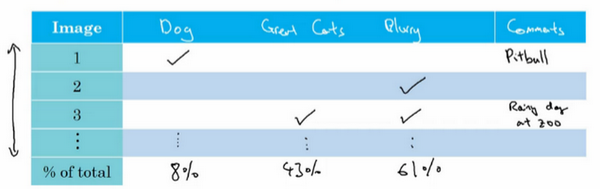
通常来说,比例越大,影响越大,越应该花费时间和精力着重解决这一问题。这种error analysis让我们改进模型更加有针对性,从而提高效率。
清除标签错误的数据
监督式学习中,训练样本有时候会出现输出y标注错误的情况,即incorrectly labeled examples。如果这些label标错的情况是随机性的(random errors),DL算法对其包容性是比较强的,即健壮性好,一般可以直接忽略,无需修复。然而,如果是系统错误(systematic errors),这将对DL算法造成影响,降低模型性能。
刚才说的是训练样本中出现incorrectly labeled data,如果是dev/test sets中出现incorrectly labeled data,该怎么办呢?
方法很简单,利用上节内容介绍的error analysis,统计dev sets中所有分类错误的样本中incorrectly labeled data所占的比例。根据该比例的大小,决定是否需要修正所有incorrectly labeled data,还是可以忽略。举例说明,若:
-- 总体验证集误差:10%
-- 由于错误标签导致的错误:0.6%
-- 由于其他原因导致的错误:9.4%
上面数据表明Errors due incorrect labels所占的比例仅为0.6%,占dev set error的6%,而其它类型错误占dev set error的94%。因此,这种情况下,可以忽略incorrectly labeled data。
如果优化DL算法后,出现下面这种情况:
-- 总体验证集误差:2%
-- 由于错误标签导致的错误:0.6%
-- 由于其他原因导致的错误:1.4%
上面数据表明Errors due incorrect labels所占的比例依然为0.6%,但是却占dev set error的30%,而其它类型错误占dev set error的70%。因此,这种情况下,incorrectly labeled data不可忽略,需要手动修正。
我们知道,dev set的主要作用是在不同算法之间进行比较,选择错误率最小的算法模型。但是,如果有incorrectly labeled data的存在,当不同算法错误率比较接近的时候,我们无法仅仅根据Overall dev set error准确指出哪个算法模型更好,必须修正incorrectly labeled data。
关于修正incorrect dev/test set data,有几条建议:
- 将优化手段同时作用到验证集和测试集上面,以确保他们仍然来自同一个分布
- 检查算法分类正确和错误的例子,也许由于某种原因,在特殊的情况下算法分类正确了,但是随着对算法的优化,又会将这些正确的数据进行错误的分类
- 因为通常情况下验证集和测试集会比训练集小得多得多,那么可以不必对训练集和验证/测试集进行同样的优化操作
快速原型法
对于如何构建一个机器学习应用模型,吴恩达给出的建议是先快速构建第一个简单模型,然后再反复迭代优化。
- 建立训练、验证/测试集以及相应的性能指标
- 快速建立原型系统
- 运用偏差/方差分析以及误差分析来确定下一步优先做什么
在不同的分布上进行训练并测试
当train set与dev/test set不来自同一个分布的时候,我们应该如何解决这一问题,构建准确的机器学习模型呢?
以猫类识别为例,train set来自于网络下载(webpages),图片比较清晰;dev/test set来自用户手机拍摄(mobile app),图片比较模糊。假如train set的大小为200000,而dev/test set的大小为10000,显然train set要远远大于dev/test set。

虽然dev/test set质量不高,但是模型最终主要应用在对这些模糊的照片的处理上。面对train set与dev/test set分布不同的情况,有两种解决方法。
第一种方法是将train set和dev/test set完全混合,然后在随机选择一部分作为train set,另一部分作为dev/test set。例如,混合210000例样本,然后随机选择205000例样本作为train set,2500例作为dev set,2500例作为test set。这种做法的优点是实现train set和dev/test set分布一致,缺点是dev/test set中webpages图片所占的比重比mobile app图片大得多。例如dev set包含2500例样本,大约有2381例来自webpages,只有119例来自mobile app。这样,dev set的算法模型对比验证,仍然主要由webpages决定,实际应用的mobile app图片所占比重很小,达不到验证效果。因此,这种方法并不是很好。
第二种方法是将原来的train set和一部分dev/test set组合当成train set,剩下的dev/test set分别作为dev set和test set。例如,200000例webpages图片和5000例mobile app图片组合成train set,剩下的2500例mobile app图片作为dev set,2500例mobile app图片作为test set。其关键在于dev/test set全部来自于mobile app。这样保证了验证集最接近实际应用场合。这种方法较为常用,而且性能表现比较好。
不同分布的偏差/方差分析
我们之前介绍过,根据human-level error、training error和dev error的相对值可以判定是否出现了bias或者variance。但是,需要注意的一点是,如果train set和dev/test set来源于不同分布,则无法直接根据相对值大小来判断。例如某个模型human-level error为0%,training error为1%,dev error为10%。根据我们之前的理解,显然该模型出现了variance。但是,training error与dev error之间的差值9%可能来自算法本身(variance),也可能来自于样本分布不同。比如dev set都是很模糊的图片样本,本身就难以识别,跟算法模型关系不大。因此不能简单认为出现了variance。
在可能伴有train set与dev/test set分布不一致的情况下,定位是否出现variance的方法是设置train-dev set。吴恩达给train-dev set的定义是:“Same distribution as training set, but not used for training.”也就是说,从原来的train set中分割出一部分作为train-dev set,train-dev set不作为训练模型使用,而是与dev set一样用于验证。
这样,我们就有training error、training-dev error和dev error三种error。其中,training error与training-dev error的差值反映了variance;training-dev error与dev error的差值反映了data mismatch problem,即样本分布不一致。
举例说明,如果training error为1%,training-dev error为9%,dev error为10%,则variance问题比较突出。如果training error为1%,training-dev error为1.5%,dev error为10%,则data mismatch problem比较突出。通过引入train-dev set,能够比较准确地定位出现了variance还是data mismatch。
总结一下human-level error、training error、training-dev error、dev error以及test error之间的差值关系和反映的问题:

一般情况下,human-level error、training error、training-dev error、dev error以及test error的数值是递增的,但是也会出现dev error和test error下降的情况。这主要可能是因为训练样本比验证/测试样本更加复杂,难以训练。
处理数据不匹配问题
如果训练集和验证/测试集来自不同的分布,此时通过错误分析显示系统中有一个数据不匹配的问题该怎么办?这个问题没有完全系统的解决方案,但通常可以从下面的两个方面入手进行尝试。
-- 人工进行误差分析来搞清楚训练集和验证/测试集之间的差异
-- 使训练集样本和验证/测试集的样本更相似
举个例子,比如说开发一款语音驱动的智能导航软件。开发人员应该要去听听验证/测试集中的样本和训练集中的样本有什么不同。比方说,可能会发现验证集中的样本噪音很多,有许多汽车的噪音。而训练集中更多的是相对纯净的人声。这就是数据集之间的差异。
当你发现这些集合之间的相异性时,也许会觉得,正是这种明显的差异,导致了学习算法性能的低下,那么可以尝试把这三个数据集变得更加相似,或者也可以收集更多类似与验证集和测试集的数据,来支撑算法的训练。
比如说,如果发现车辆背景噪音是主要的差异来源,那么你可以模拟车辆噪声数据,进行人工数据合成,在训练集上添加车辆噪声。这样会使模型训练的效果更准确。
但是,需要注意的是,我们不能给每段语音都增加同一段背景噪声,这样会出现对背景噪音的过拟合,效果不佳。这就是人工数据合成需要注意的地方。
总而言之,如果认为存在数据不匹配问题,做错误分析是可行的,或者看看训练集,看看验证/测试集,尝试找出,或者去了解这些数据分布到底有什么不同,然后看看是否有办法收集更多看起来更相似的数据作训练。
迁移学习
深度学习中最强大的理念之一就是,有的时候神经网络可以从一个任务中习得知识(网络结构),并将这些知识(网络结构)应用到另一个独立的任务中。例如,也许已经训练好一个神经网络,能够识别像猫这样的对象,然后使用那些知识,或者部分习得的知识去处理X光片预测疾病的任务,这就是所谓的迁移学习。
如果我们已经有一个训练好的神经网络,用来做图像识别。现在,我们想要构建另外一个通过X光片进行诊断的模型。迁移学习的做法是无需重新构建新的模型,而是利用之前的神经网络模型,只改变样本输入、输出以及输出层的权重系数\(W^{[L]},\ b^{[L]}\)。也就是说对新的样本(X,Y),重新训练输出层权重系数\(W^{[L]},\ b^{[L]}\),而其它层所有的权重系数\(W^{[L]},\ b^{[L]}\)保持不变。
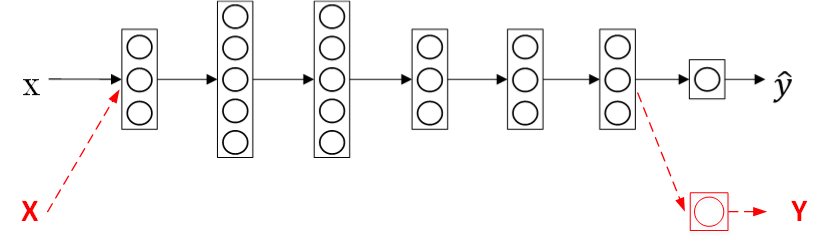
迁移学习,重新训练权重系数,如果需要构建新模型的样本数量较少,那么可以像刚才所说的,只训练输出层的权重系数\(W^{[L]},\ b^{[L]}\),保持其它层所有的权重系数\(W^{[L]},\ b^{[L]}\)不变。这种做法相对来说比较简单。如果样本数量足够多,那么也可以只保留网络结构,重新训练所有层的权重系数。这种做法使得模型更加精确,因为毕竟样本对模型的影响最大。选择哪种方法通常由数据量决定。
顺便提一下,如果重新训练所有权重系数,初始\(W^{[L]},\ b^{[L]}\)由之前的模型训练得到,这一过程称为pre-training(预训练)。之后,不断调试、优化\(W^{[L]},\ b^{[L]}\)的过程称为fine-tuning(微调)。pre-training和fine-tuning分别对应上图中的黑色箭头和红色箭头。
迁移学习之所以能这么做的原因是,神经网络浅层部分能够检测出许多图片固有特征,例如图像边缘、曲线等。使用之前训练好的神经网络部分结果有助于我们更快更准确地提取X光片特征。二者处理的都是图片,而图片处理是有相同的地方,第一个训练好的神经网络已经帮我们实现如何提取图片有用特征了。 因此,即便是即将训练的第二个神经网络样本数目少,仍然可以根据第一个神经网络结构和权重系数得到健壮性好的模型。
迁移学习可以保留原神经网络的一部分,再添加新的网络层。具体问题,具体分析,可以去掉输出层后再增加额外一些神经层。
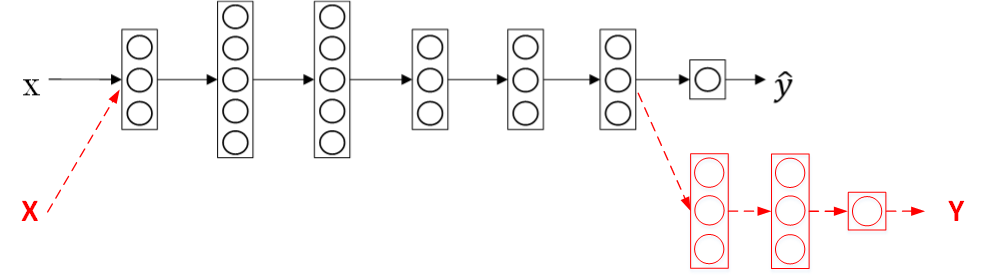
总体来说,迁移学习的应用场合主要包括三点:
-- 任务A、B有相同的输入X
-- 任务A的数据比任务B的数据多得多
-- 任务A的低层次特征有助于任务B的训练
多任务学习
顾名思义,多任务学习(multi-task learning)就是构建神经网络同时执行多个任务。这跟二元分类或者多元分类都不同,多任务学习类似将多个神经网络融合在一起,用一个网络模型来实现多种分类效果。如果有C个,那么输出y的维度是\((C,1)\)。例如汽车自动驾驶中,需要实现的多任务为行人、车辆、交通标志和信号灯。如果检测出汽车和交通标志,则y为:
多任务学习模型的cost function为:
其中,j表示任务下标,总有c个任务。对应的loss function为:
值得一提的是,Multi-task learning与Softmax regression的区别在于Softmax regression是single label的,即输出向量y只有一个元素为1;而Multi-task learning是multiple labels的,即输出向量y可以有多个元素为1。
多任务学习是使用单个神经网络模型来实现多个任务。实际上,也可以分别构建多个神经网络来实现。但是,如果各个任务之间是相似问题(例如都是图片类别检测),则可以使用多任务学习模型。另外,多任务学习中,可能存在训练样本Y某些label空白的情况,这并不影响多任务模型的训练。
总体来说,多任务学习的应用场合主要包括三点:
-- 当训练的一组任务可以共用低层次的特征时
-- 当每个任务的大部分数据非常相似时
-- 当能训练出足够大的网络来完成所有任务时
端到端的深度学习
端到端(end-to-end)深度学习就是将所有不同阶段的数据处理系统或学习系统模块组合在一起,用一个单一的神经网络模型来实现所有的功能。它将所有模块混合在一起,只关心输入和输出。
以语音识别为例,传统的算法流程和end-to-end模型的区别如下:
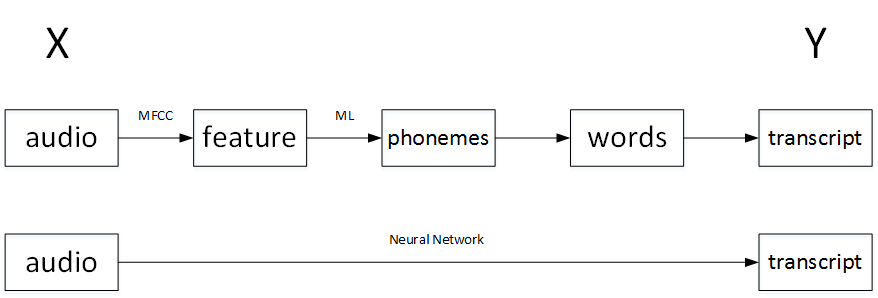
传统上,语音识别需要很多阶段的处理。首先你会提取一些特征,一些手工设计的音频特征,也许你听过MFCC,这种算法是用来从音频中提取一组特定的人工设计的特征。在提取出一些低层次特征之后,你可以应用机器学习算法在音频片段中找到音位,所以音位是声音的基本单位,比如说“Cat”这个词是三个音节构成的,Cu-、Ah-和Tu-,算法就把这三个音位提取出来,然后你将音位串在一起构成独立的词,然后你将词串起来构成音频片段的听写文本。
和这种有很多阶段的流水线相比,端到端深度学习做的是,训练一个巨大的神经网络,输入是一段音频,输出直接是听写文本。
如果训练样本足够大,神经网络模型足够复杂,那么end-to-end模型性能比传统机器学习分块模型更好。实际上,end-to-end让神经网络模型内部去自我训练模型特征,自我调节,增加了模型整体契合度。
是否必要采用端到端深度学习?
假设正在搭建一个机器学习系统,需要决定是否使用端对端方法,下面来看看端到端深度学习的一些优缺点,这样就可以根据一些准则,判断你的机器学习系统是否有必要使用端到端方法。
端到端学习有这样两个好处:
-- 让数据说话
-- 所需手工设计的组件更少
首先端到端学习真的只是让数据说话。如果你有足够多的数据对(x,y),那么不管从x到y最适合的函数映射是什么,如果你训练一个足够大的神经网络,那么这个神经网络可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
例如,在语音识别领域,早期的识别系统有这个音位概念,就是基本的声音单元,如cat单词的“cat”的Cu-、Ah-和Tu-,音位是人类语言学家生造出来的,如果强迫学习算法以音位为单位思考,那么它的表现可能并不会太好。如果你让你的学习算法学习它想学习的任意表示方式,而不是强迫你的学习算法使用音位作为表示方式,那么其整体表现可能会更好。
端到端深度学习的第二个好处是这样,所需手工设计的组件更少,所以这能够简化设计工作流程,不需要花太多时间去手工设计功能,手工设计这些中间表示方式。
反之,端到端学习有这样一些缺点:
-- 庞大的数据
-- 可能排除有用的组件
首先,它可能需要大量的数据。要直接学到这个x到y的映射,可能需要大量(x,y)数据对。
另一个缺点是,它排除了可能有用的手工设计组件。吴恩达表示他认为学习算法有两个主要的知识来源,一个是数据,另一个是你手工设计的任何东西,可能是组件,功能,或者其他东西。
当你有大量数据时,手工设计的东西就不太重要了,但是当你没有太多的数据时,构造一个精心设计的系统,实际上相当于,将人类对这个问题的很多认识直接注入到问题里,体现在算法里,这对算法性能将会是挺有帮助的。
那么是否使用端到端学习的关键就在于,能否获得足以支撑直接学到x到y的复杂映射的庞大数据。
再举一个更复杂一些的例子,现在非常火热的无人驾驶技术,车辆前方的传感器获取周围环境的数据,输入到车辆中的计算机,弄清楚自身车辆处于什么位置或什么样的状态,接下来就要规划自己的行进路线,那么就需要对方向盘进行控制,甚至之间还要发出对油门和制动恰当的指令。
如果在这里使用端到端学习的话,直接通过输入的图像或其他什么数据,来对方向盘进行操控,至少目前来说,是难以实现的,这样类型的数据是无法或者说很难收集到的。
从这个例子来说,纯粹的端到端学习,并不是前景非常广的一中学习模式。因为目前能收集到的数据,还有现在训练神经网络的能力,是十分有限的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号