通过python爬虫爬取淘宝信息
爬取内容
爬取淘宝上的裤子信息,包括裤子名字,图片,价格以及销售量
爬取过程
首先分析淘宝网页url
第一页:

第二页:

第三页:

最后的数字从零开始,每增加一页,数字增加44,由此可以根据第一页的url得到后面网页的url
十页网页url的列表:
original_url = "https://s.taobao.com/search?q=%E8%A3%A4%E5%AD%90&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20201213&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s="
url_list=list()
for i in range(1, 11):
url=original_url+str((i-1)*44)
url_list.append(url)
分析淘宝网页源码
元素审查找到具体信息,可以找到信息保存在div class="item J_MouserOnverReq item-ad "或div class="item J_MouserOnverReq "中
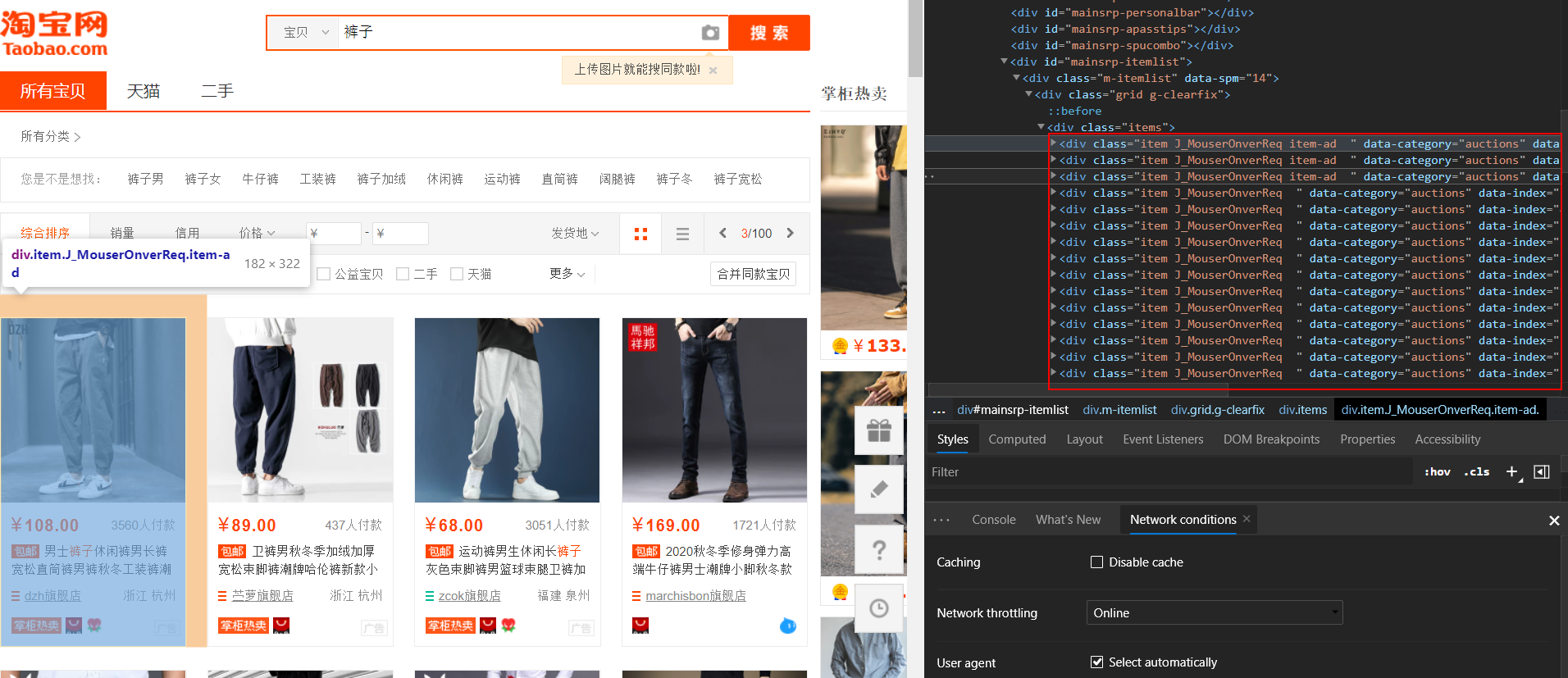
但是查看requests请求下来的网页代码和浏览器中元素审查不同,并没有div,class="item J_MouserOnverReq "的标签
论坛找到解答 https://www.cnblogs.com/yuantup/p/9761534.html

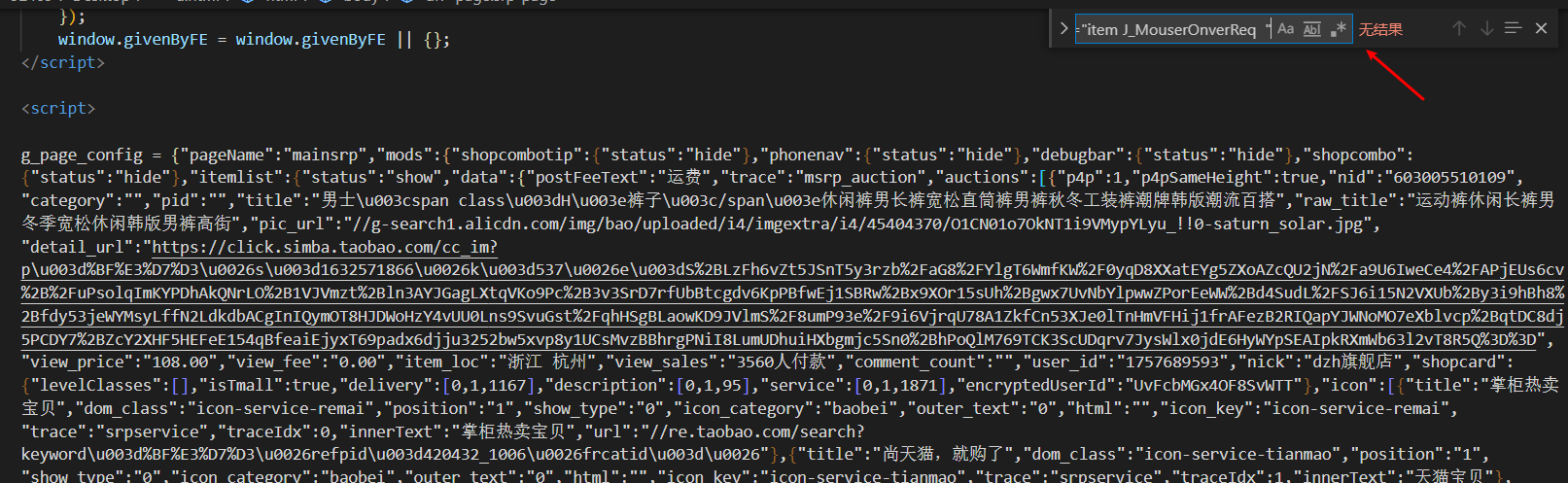
我的解决方法:直接利用爬取下来的网页源码进行正则表达式的匹配,找到所需要的信息
可以从源码中找到
raw_title: 对应商品名称
pic_url: 对应照片的url
view_price: 对应商品价格
view_sales: 对应商品的销量

利用正则表达式找到所有匹配的元素
name=re.findall(r'"raw_title":"(.*?)"', response)
pic=re.findall(r'"pic_url":"(.*?)"', response)
price=re.findall(r'"view_price":"(.*?)"', response)
sales=re.findall(r'"view_sales":"(.*?)"', response)
打印每个列表的长度
print(len(name))
print(len(pic))
print(len(price))
print(len(sales))
#44
#44
#44
#44
长度匹配,所以列表中相同下标对应相同元素
图片获取并向文件中写信息
fp=open("./image/info.md", 'w', encoding='utf-8')
slen=len(name)
print(slen)
for i in range(0, slen):
im_name=str(pic[i]).split('/')[-1]
im=open("./image/"+im_name, 'wb')
im_url = "http:"+str(pic[i])
image=requests.get(im_url, headers=headers).content
im.write(image)
im.close()
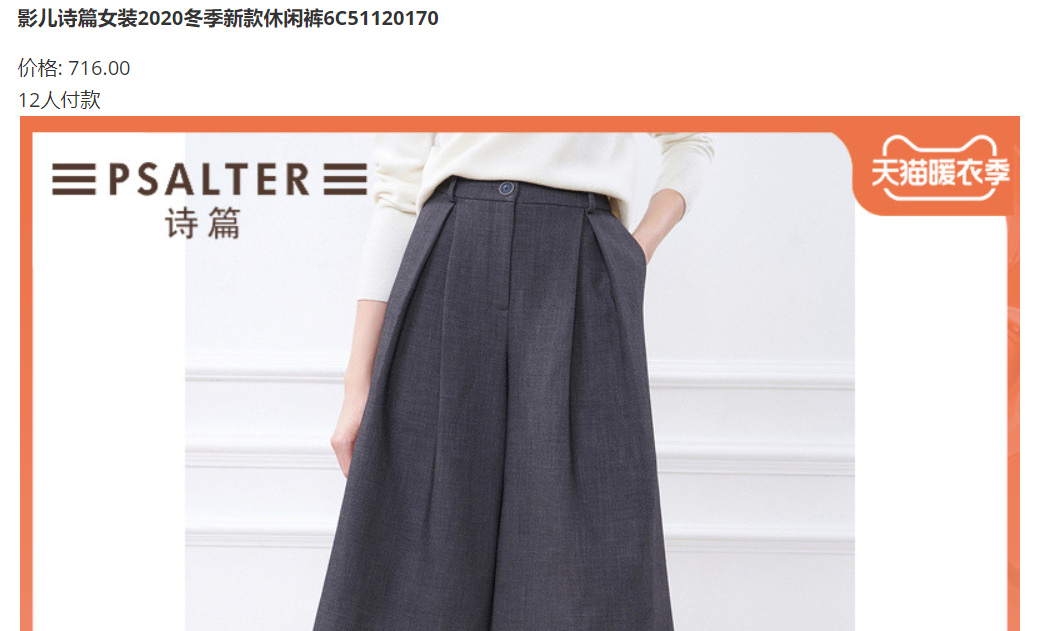
fp.write("##### "+str(name[i])+'\n'+"价格: "+str(price[i])+'\n'+str(sales[i])+'\n')
fp.write("!["+str(name[i])+"]("+im_name+")"+'\n')
#图片markdown格式:
time.sleep(1)
fp.close()
运行结果
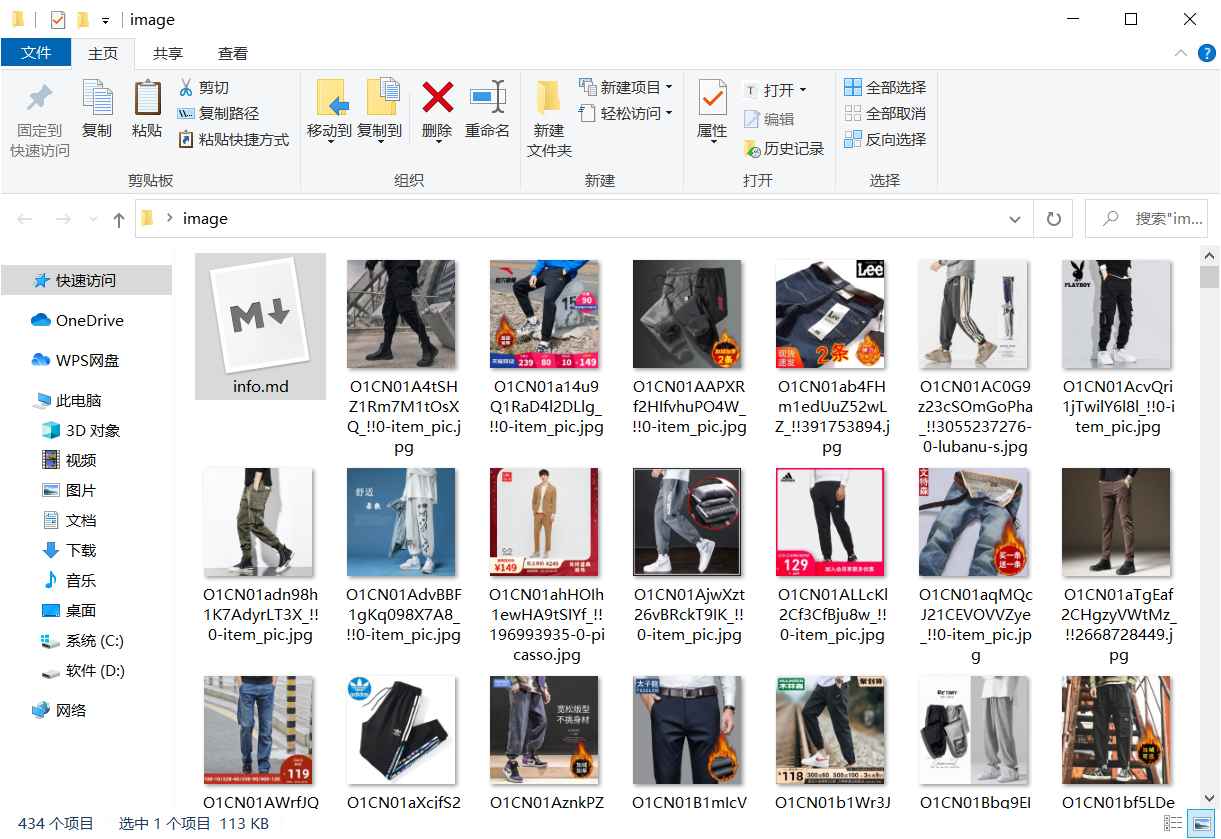
共433个图片
markdown文件中

最终代码
import requests
import re
import time
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.80 Safari/537.36 Edg/86.0.622.43",
"cookie": "请自行填充"
}
original_url = "https://s.taobao.com/search?q=%E8%A3%A4%E5%AD%90&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20201213&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s="
url_list=list()
for i in range(1, 11):
url=original_url+str((i-1)*44)
url_list.append(url)
fp=open("./image/info.md", 'w', encoding='utf-8')
for url in url_list:
response=requests.get(url, headers=headers).text
name=re.findall(r'"raw_title":"(.*?)"', response)
pic=re.findall(r'"pic_url":"(.*?)"', response)
price=re.findall(r'"view_price":"(.*?)"', response)
sales=re.findall(r'"view_sales":"(.*?)"', response)
slen=len(name)
print(slen)
for i in range(0, slen):
im_name=str(pic[i]).split('/')[-1]
im=open("./image/"+im_name, 'wb')
im_url = "http:"+str(pic[i])
image=requests.get(im_url, headers=headers).content
im.write(image)
im.close()
fp.write("##### "+str(name[i])+'\n'+"价格: "+str(price[i])+'\n'+str(sales[i])+'\n')
fp.write("!["+str(name[i])+"]("+im_name+")"+'\n')
#markdown图片格式:
time.sleep(1)
fp.close()
注意事项(反爬虫):User-Agent和cookie都不能缺少
缺少User-Agent会缺少访问权限
缺少cookie会抓取到登陆界面
另一种解决方法-利用selenium仿真,并返回网页源码
selenium不能用cookie,所以需要模拟登陆
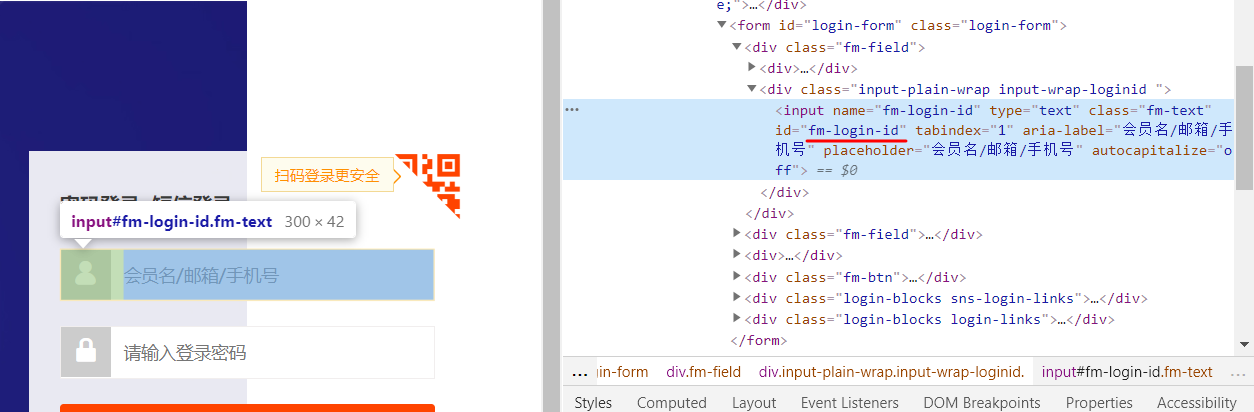
输入手机号的标签id
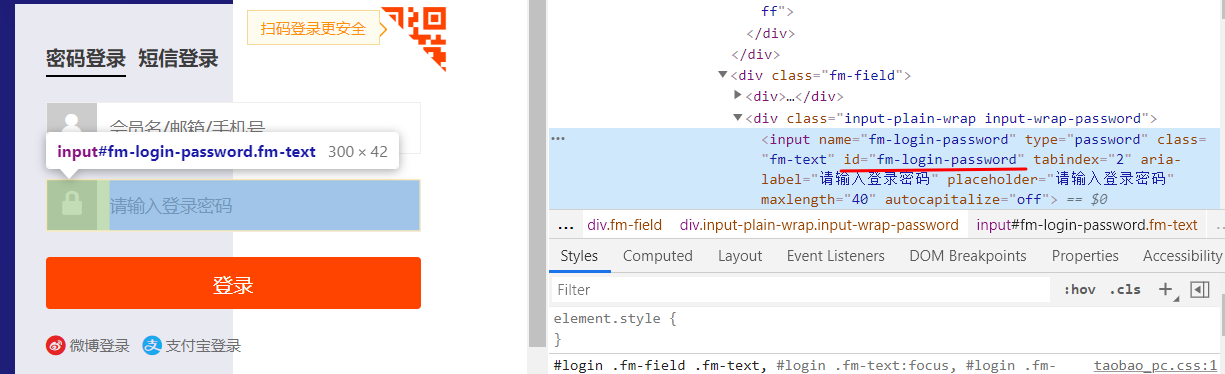
输入密码的标签id
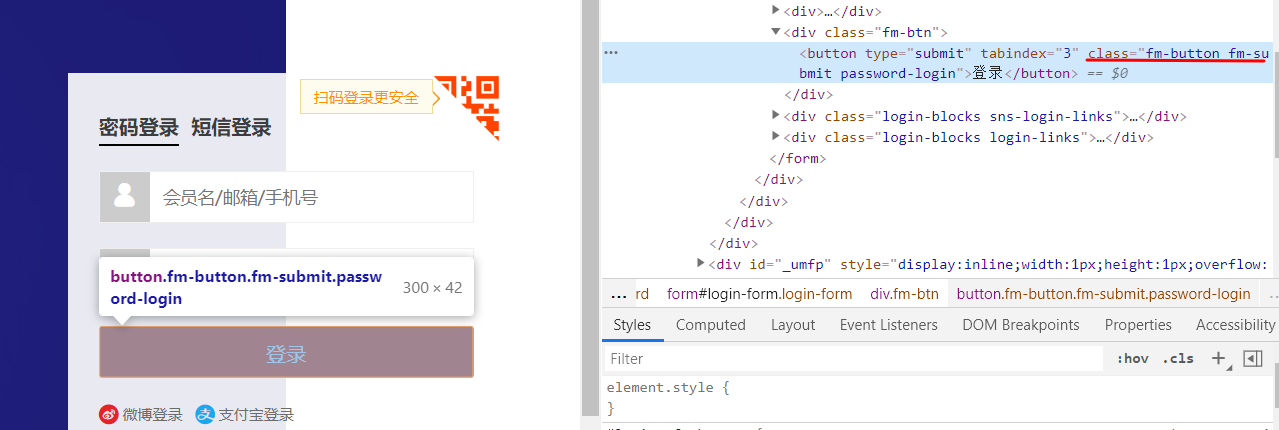
登陆按钮的class名字
登陆淘宝网并将网页返回传给BeautifulSoup
代码:
ori_url="https://s.taobao.com/search?q=%E8%A3%A4%E5%AD%90&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20201213&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s="
driver=webdriver.Chrome()
driver.maximize_window()
#模拟登录
driver.get(ori_url)
time.sleep(1)
driver.find_element_by_id('fm-login-id').clear()
driver.find_element_by_id('fm-login-id').send_keys('15703613658')
time.sleep(1)
driver.find_element_by_id('fm-login-password').clear()
driver.find_element_by_id('fm-login-password').send_keys('*********')#password
time.sleep(1)
driver.find_element_by_class_name('fm-button').click()
time.sleep(5)
data=driver.page_source.encode('utf-8')
soup=BeautifulSoup(data,features='lxml')
成功找到和图片有关标签


alt对应商品名称,src和data-src都有可能对应图片url,但data-src一定会对应,所以用data-src获取图片
保存图片
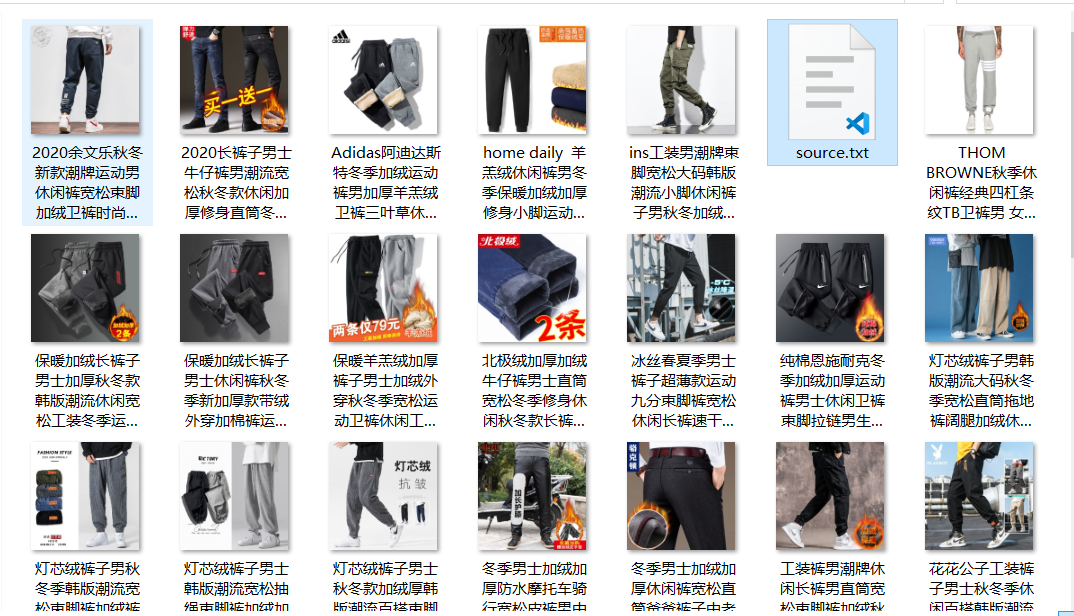
img_list=soup.find_all('img',class_="J_ItemPic img")
for img in img_list:
fp.write(str(img))
name=img['alt']
url='http:'+img['data-src']
image=requests.get(url).content
i=open('./selenium_image/'+name+'.jpg','wb')
i.write(image)
i.close()
print(name)
最终爬取到一页中商品名称和图片
最终代码
from selenium import webdriver
from bs4 import BeautifulSoup
import time
import re
import requests
ori_url="https://s.taobao.com/search?q=%E8%A3%A4%E5%AD%90&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20201213&ie=utf8&bcoffset=3&ntoffset=3&p4ppushleft=1%2C48&s="
driver=webdriver.Chrome()
driver.maximize_window()
#模拟登录
driver.get(ori_url)
time.sleep(1)
driver.find_element_by_id('fm-login-id').clear()
driver.find_element_by_id('fm-login-id').send_keys('15703613658')
time.sleep(1)
driver.find_element_by_id('fm-login-password').clear()
driver.find_element_by_id('fm-login-password').send_keys('********')#password
time.sleep(1)
driver.find_element_by_class_name('fm-button').click()
time.sleep(5)
data=driver.page_source.encode('utf-8')
soup=BeautifulSoup(data,features='lxml')
fp=open('./selenium_image/source.txt','w',encoding='utf-8')
img_list=soup.find_all('img',class_="J_ItemPic img")
for img in img_list:
fp.write(str(img))
name=img['alt']
url='http:'+img['data-src']
image=requests.get(url).content
i=open('./selenium_image/'+name+'.jpg','wb')
i.write(image)
i.close()
print(name)
fp.close()
注意事项
模拟点击登陆后,需要等待几秒再返回page_source,否则会返回之前的网页的源码

更多
更新到下一页,可以通过selenium模拟点击下一页按钮
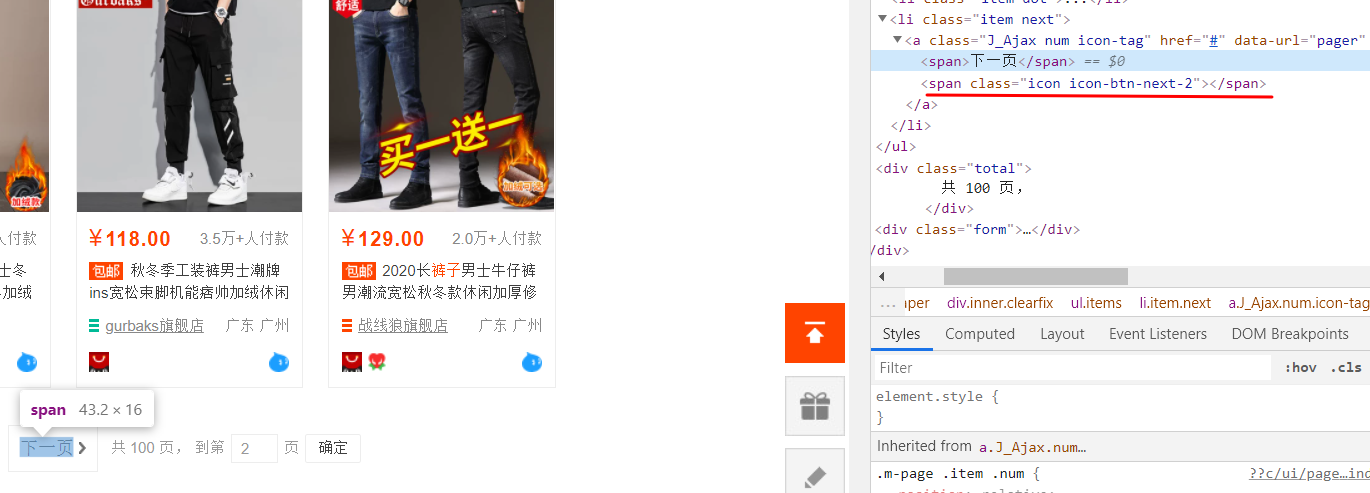
抓取价格和销售量信息
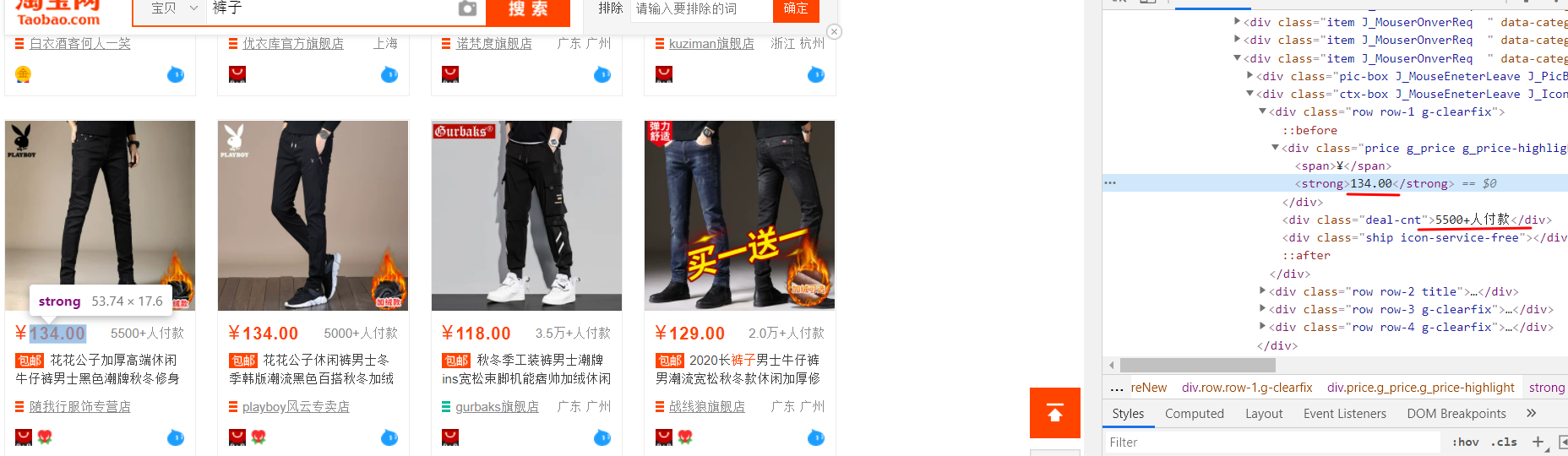
因为比较懒而且看起来很麻烦,所以没有做
集美大学 计算1913 李文轩

 浙公网安备 33010602011771号
浙公网安备 33010602011771号