基于TKE+gitlab+jenkins搭建Prometheus告警系统
#公司的环境是 TKE + gitlab+ jenkins
整体思路
需要安装 node exporter容器来监控node节点及k8s服务本身
需要安装 kube-state-metrics容器来监控pod运行状态等信息
需要安装 cAdvisor(目前cAdvisor集成到了kubelet组件内) 来监控pod性能信息#包括CPU、内存使用情况、网络吞吐量及文件系统使用情况.TKE默认开启 不过需要在 rbac权限里面加入授权
需要安装grafana容器来图形化界面#其中grafana可以去官网下载图表模板不过需要修改才能用
需要安装 alertmanager容器来添加报警模块#需要配置告警规则
一.安装Prometheus本体
1.gitlab上新建Prometheus代码仓库项目
-存放Prometheus的dockerfile文件#拉取镜像
dockerfile:


FROM prom/prometheus ADD ./prometheus.yml /etc/prometheus/ ADD ./*rules.yml /etc/prometheus/
-存放Prometheus的配置文件#配置监控的全局设置比如抓取间隔/抓取任务等
global: scrape_interval: 30s # By default, scrape targets every 15 seconds. # Attach these labels to any time series or alerts when communicating with # external systems (federation, remote storage, Alertmanager). external_labels: monitor: 'codelab-monitor' # A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. - job_name: 'prometheus' # Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 30s static_configs: - targets: ['localhost:9090'] - job_name: 'node' # Override the global default and scrape targets from this job every 5 seconds. scrape_interval: 30s static_configs: - targets: ['10.0.0.129:9100','10.0.4.124:9100','10.0.1.107:9100','10.0.3.246:9100'] labels: group: 'production' - job_name: 'kubernetes-apiservers' scheme: https kubernetes_sd_configs: - role: endpoints tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-cadvisor' scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token kubernetes_sd_configs: - role: node relabel_configs: - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor target_label: __metrics_path__ - action: labelmap regex: __meta_kubernetes_node_label_(.+) - source_labels: [__meta_kubernetes_node_name] action: replace target_label: node - source_labels: [__meta_kubernetes_node_label_node] action: replace target_label: node_name - job_name: 'kubernetes-service-endpoints' scrape_timeout: 30s kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - source_labels: [__meta_kubernetes_pod_container_port_number] action: replace target_label: container_port - job_name: mysql static_configs: - targets: ['xd-mysqld-exporter'] labels: instance: DB alerting: # 告警配置文件 alertmanagers: # 修改:使用静态绑定 - static_configs: # 修改:targets、指定地址与端口 - targets: ["xd-alertmanager-service"] rule_files: ## rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载 - "/etc/prometheus/*rules.yml"
-存放告警规则文件#
groups: - name: node-rules rules: - alert: NodeFilesystemSpaceFillingUp #node节点磁盘使用率告警 expr: ( node_filesystem_avail_bytes{job="node-exporter",fstype!=""} / node_filesystem_size_bytes{job="node-exporter",fstype!=""} * 100 < 15 and predict_linear(node_filesystem_avail_bytes{job="node-exporter",fstype!=""}[6h], 4*60*60) < 0 and node_filesystem_readonly{job="node-exporter",fstype!=""} == 0 ) for: 1h #for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending。 labels: severity: critical annotations: #annotations:用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager. summary: node节点磁盘使用率告警 description: 集群 {{ $labels.cluster }}/node {{ $labels.instance }}/设备 {{ $labels.device }} 只剩下 {{ printf "%.2f" $value }}%的可用空间 - alert: NodeClockSkewDetected #node时间异常检测告警 expr: ( node_timex_offset_seconds > 0.05 and deriv(node_timex_offset_seconds[5m]) >= 0 ) or ( node_timex_offset_seconds < -0.05 and deriv(node_timex_offset_seconds[5m]) <= 0 ) for: 10m labels: severity: warning annotations: summary: node时间异常检测告警 description: 集群 {{ $labels.cluster_id }}/node {{ $labels.instance }}的时钟漂移超过300秒, 请检查NTP是否正常配置 - alert: KubePersistentVolumeErrors #PV资源不足告警 expr: kube_persistentvolume_status_phase{phase=~"Failed|Pending",job="kube-state-metrics"} > 0 for: 10m labels: severity: critical annotations: summary: PV资源不足告警 description: 集群{{ $labels.cluster }}/pv {{ $labels.persistentvolume }}状态{{ $labels.phase }} - alert: KubeletTooManyPods #node资源不足告警 expr: count by(cluster,node) ( (kube_pod_status_phase{job="kube-state-metrics",phase="Running"} == 1) * on(instance,pod,namespace,cluster) group_left(node) topk by(instance,pod,namespace,cluster) (1, kube_pod_info{job="kube-state-metrics"}) ) / max by(cluster,node) ( kube_node_status_capacity_pods{job="kube-state-metrics"} != 1 ) > 0.95 for: 15m labels: severity: critical annotations: summary: node资源不足告警 description: 集群 {{ $labels.cluster }}/node {{ $labels.node }} 运行pod量占容量的{{ $value | humanizePercentage}}
groups: - name: pod-rules rules: - alert: PODCpu90 #podCPU使用率超过90%告警 expr: sum(rate(container_cpu_usage_seconds_total{}[2m]))by(container,namespace)/(sum(container_spec_cpu_quota{}/100000)by(container,namespace))*100 > 90 for: 10m #for:评估等待时间,可选参数。用于表示只有当触发条件持续一段时间后才发送告警。在等待期间新产生告警的状态为pending. labels: severity: warning annotations: #用于指定一组附加信息,比如用于描述告警详细信息的文字等,annotations的内容在告警产生时会一同作为参数发送到Alertmanager. summary: podCPU使用率超过90%告警 description: "{{ $labels.namespace }}环境的 {{ $labels.container }}项目CPU使用率达 {{ $value | humanizePercentage }}." - alert: PodMemoryLimitRate #POD内存超过90%告警 expr: sum (container_memory_working_set_bytes) by (container,namespace)/ sum(container_spec_memory_limit_bytes) by (container,namespace) * 100 > 90 for: 15m labels: severity: warning annotations: summary: pod内存使用率超过90%告警 description: "{{ $labels.namespace }}环境的 {{ $labels.container }}项目内存使用率达 {{ $value | humanizePercentage }}." - alert: pod_status_no_running #POD状态异常告警 expr: sum (kube_pod_status_phase{phase=~"Pending|Unknown"}) by (pod,phase,namespace) > 0 for: 10m labels: severity: warning annotations: summary: POD状态异常告警 description: "{{ $labels.namespace }}环境的 {{ $labels.container }}项目处于NotReady状态超过10分钟" - alert: PodCrashLooping #POD重启频繁告警 expr: sum (increase (kube_pod_container_status_restarts_total{}[2m])) by (namespace,container) >0 for: 5m labels: severity: warning annotations: summary: POD重启频繁告警 description: "{{ $labels.namespace }}环境的 {{ $labels.container }} 项目最近5分钟重启{{ $value }} 次" - alert: KubeDeploymentReplicasMismatch #pod数量没达到预期数目告警(可能node资源不足) expr: ( kube_deployment_spec_replicas{job="kube-state-metrics"} != kube_deployment_status_replicas_available{job="kube-state-metrics"} ) and ( changes(kube_deployment_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning annotations: summary: pod数量没达到预期数目告警(可能node资源不足) description: "集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/deployment {{ $labels.deployment }} 没有达到预期副本数超过15分钟" - alert: KubeStatefulSetUpdateNotRolledOut #pod部分没有更新 expr: ( max without (revision) ( kube_statefulset_status_current_revision{job="kube-state-metrics"} unless kube_statefulset_status_update_revision{job="kube-state-metrics"} ) * ( kube_statefulset_replicas{job="kube-state-metrics"} != kube_statefulset_status_replicas_updated{job="kube-state-metrics"} ) ) and ( changes(kube_statefulset_status_replicas_updated{job="kube-state-metrics"}[5m]) == 0 ) for: 15m labels: severity: warning annotations: summary: pod部分没有更新 description: "集群 {{ $labels.cluster }}/namespace {{ $labels.namespace }}/statefulset {{ $labels.statefulset }} 部分Pod未更新" - alert: KubePersistentVolumeFillingUp #pod挂载磁盘空间不足告警 expr: kubelet_volume_stats_available_bytes{job="kubelet"} / kubelet_volume_stats_capacity_bytes{job="kubelet"} < 0.03 for: 1m labels: severity: critical annotations: summary: pod挂载磁盘空间不足告警 description: "集群{{ $labels.cluster }}/namespace {{ $labels.namespace }}/pvc {{ $labels.persistentvolumeclaim }}的存储空间只剩{{ $value | humanizePercentage }}可用"
groups: - name: test-rule rules: - alert: NodeMemoryUsage expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 80 for: 2m labels: team: node annotations: summary: "{{$labels.instance}}: High Memory usage detected" description: "{{$labels.instance}}: Memory usage is above 20% (current value is: {{ $value }}" - alert: InstanceDown expr: up == 0 for: 1m labels: severity: error annotations: summary: "Instance {{ $labels.instance }} down2" description: "{{ $labels.instance }} of job2 {{ $labels.job }} has been down for more than 5 minutes."
2.配置Prometheus的容器配置文件
-deployment.yml#设置容器名称/资源大小等
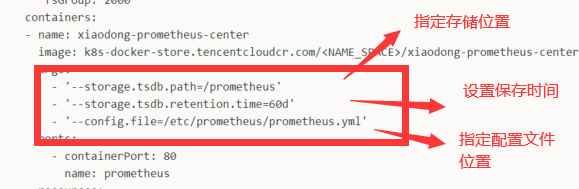
apiVersion: apps/v1 kind: Deployment metadata: name: xiaodong-prometheus-center labels: app: xiaodong-prometheus-center spec: revisionHistoryLimit: 10 replicas: 1 strategy: type: Recreate selector: matchLabels: app: xiaodong-prometheus-center template: metadata: labels: app: xiaodong-prometheus-center spec: serviceAccountName: prometheus securityContext: runAsUser: 1000 runAsGroup: 3000 fsGroup: 2000 containers: - name: xiaodong-prometheus-center image: k8s-docker-store.tencentcloudcr.com/<NAME_SPACE>/xiaodong-prometheus-center:<TAG> args: - '--storage.tsdb.path=/prometheus' - '--storage.tsdb.retention.time=60d' - '--config.file=/etc/prometheus/prometheus.yml' ports: - containerPort: 80 name: prometheus resources: requests: cpu: 2 memory: 2048Mi limits: cpu: 4 memory: 4096Mi volumeMounts: - name: default-storage mountPath: /prometheus volumes: - name: default-storage persistentVolumeClaim: claimName: xiaodong-prometheus-center-storage
如果想设置Prometheus的数据存储时间(默认是15d),现在想改成60天 需要在deployment.yml的添加以下配置
-service.yml #定义容器网络情况
apiVersion: v1 kind: Service metadata: name: xd-prometheus-center labels: app: xd-prometheus-center spec: type: LoadBalancer selector: app: xd-prometheus-center ports: - protocol: TCP port: 80 targetPort: 9090
-rac_prom.yml# 设置Prometheus的访问集群权限
--- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: prometheus rules: - apiGroups: [""] resources: - nodes - nodes/metrics - nodes/proxy - pods - endpoints - services verbs: ["get", "list", "watch"] - nonResourceURLs: ["/metrics"] verbs: ["get"] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: prometheus roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: prometheus subjects: - kind: ServiceAccount name: prometheus namespace: devops --- apiVersion: v1 kind: ServiceAccount metadata: name: prometheus namespace: devops
-PersistentVolumeClaim.yml #定义对PV资源的请求包括指定使用何种存储资源,使用多少GB,以何种模式使用PV等信息
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: xd-prometheus-center-storage
spec:
accessModes:
- ReadWriteOnce
storageClassName: xd-prometheus-center
resources:
requests:
storage: 200Gi
-StorageClass.yml # 持久化存储
![]() StorageClass.yml
StorageClass.yml
apiVersion: storage.k8s.io/v1
allowVolumeExpansion: true
kind: StorageClass
metadata:
name: xd-prometheus-center
parameters:
diskType: CLOUD_PREMIUM
provisioner: com.tencent.cloud.csi.cbs
reclaimPolicy: Delete
volumeBindingMode: Immediate
3.创建Prometheus Jenkins项目
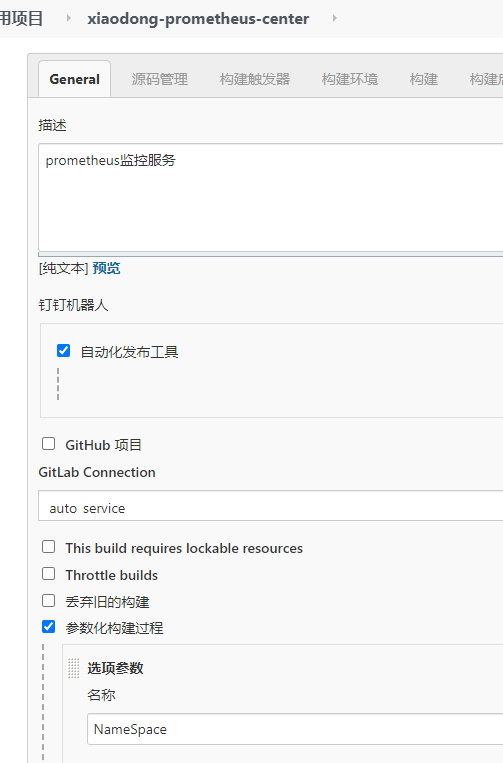
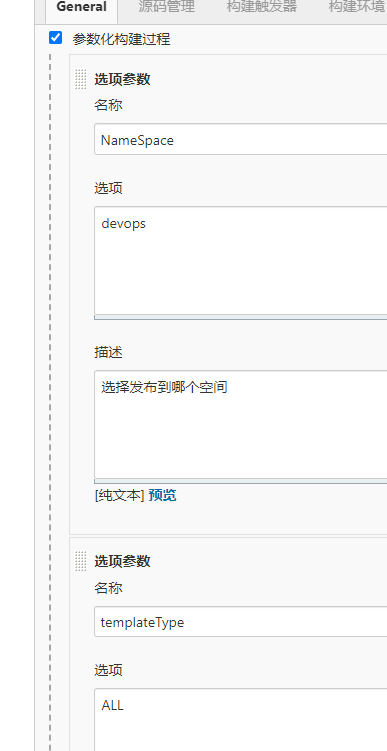
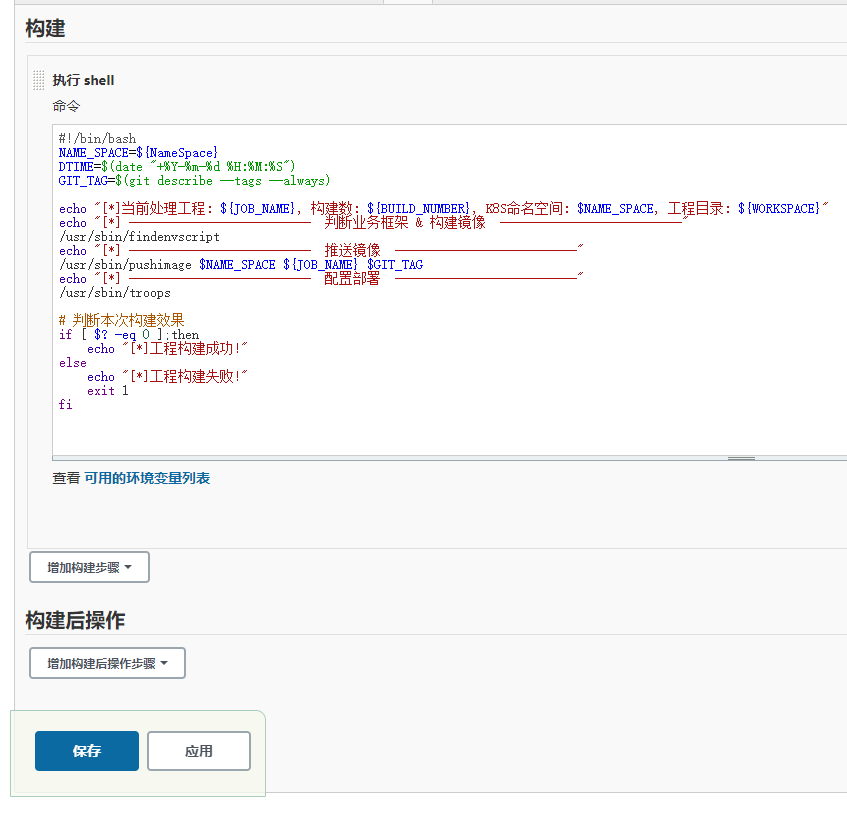
Jenkins相关脚本:
#!/bin/bash NAME_SPACE=${NameSpace} DTIME=$(date "+%Y-%m-%d %H:%M:%S") GIT_TAG=$(git describe --tags --always) echo "[*]当前处理工程: ${JOB_NAME}, 构建数: ${BUILD_NUMBER}, K8S命名空间: $NAME_SPACE, 工程目录: ${WORKSPACE}" echo "[*] -------------------------- 判断业务框架 & 构建镜像 --------------------------" /usr/sbin/findenvscript echo "[*] -------------------------- 推送镜像 --------------------------" /usr/sbin/pushimage $NAME_SPACE ${JOB_NAME} $GIT_TAG echo "[*] -------------------------- 配置部署 --------------------------" /usr/sbin/troops # 判断本次构建效果 if [ $? -eq 0 ];then echo "[*]工程构建成功!" else echo "[*]工程构建失败!" exit 1 fi
#!/bin/bash ############################################ # # 环境判断脚本 # 判断基础环境是什么,配置对应的dockerfile # ############################################ NAME_SPACE=${NameSpace} ENV_CHOICE=${envChoice} TEMPLATE_TYPE=${templateType} GIT_TAG=$(git describe --tags --always) # 先删除模版 rm -rf dockerfile-template # 获取所有的模版 git clone git@git.xiaodongai.com:devops/dockerfile-template.git # 判断业务类型 if [ $TEMPLATE_TYPE = "PHP" ]; then # 判断是不是PHP的逻辑 if [ -f 'think' ]; then # 确认肯定是tp框架 TP_NAME=$(cat think |grep "ThinkPHP" | wc -l) if [ $TP_NAME -gt 0 ]; then # TP的框架 cp -R dockerfile-template/php/thinkphp/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi else # 判断是否是CI框架 if [ -f 'index.php' ]; then TP_NAME=$(cat index.php |grep "* CodeIgniter" | wc -l) if [ $TP_NAME -gt 0 ]; then cp -R dockerfile-template/php/codeIgniter/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi fi # 判断是否是老的TP版本 if [ -d 'ThinkPHP' ]; then if [ -f 'config.inc.php' ]; then cp -R dockerfile-template/php/thinkphp_old/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi fi # 判断是否是laravel if [ -f 'server.php' ]; then LA_NAME=$(cat server.php |grep "Laravel" | wc -l) if [ $LA_NAME -gt 0 ]; then cp -R dockerfile-template/php/laravel/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi fi fi elif [ $TEMPLATE_TYPE = "VUE" ]; then if [ -d frontend-config ]; then rm -rf frontend-config fi # 如果是VUE的项目,则拉取配置文件 git clone git@git.xiaodongai.com:devops/frontend-config.git # 如果存在这个目录,则读取这个目录下的配置文件 if [ -d frontend-config/$NAME_SPACE/${JOB_NAME} ]; then rm -rf default.conf rm -rf Dockerfile # 拷贝nginx配置 cp -R frontend-config/$NAME_SPACE/${JOB_NAME}/default.conf . # 拷贝dockerfile文件 cp -R dockerfile-template/vue/${JOB_NAME}/Dockerfile . # 构建镜像 /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi elif [ $TEMPLATE_TYPE = "PYTHON" ]; then #判断是py2还是py3的框架 if [ -d 'python35' ]; then cp -R dockerfile-template/python3/${JOB_NAME}/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . else #执行py2模板 cp -R dockerfile-template/python/${JOB_NAME}/Dockerfile . /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi elif [ $TEMPLATE_TYPE = "JAVA" ]; then rm -rf Dockerfile # 打包&编译 docker run -it --rm -v "$(pwd)":/usr/src/mymaven -w /usr/src/mymaven maven:3.6.1-jdk-8-alpine mvn clean package # 构建镜像 /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . else if [ -f 'Dockerfile' ]; then /usr/bin/docker build -t k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/${JOB_NAME}:$GIT_TAG . fi fi
#!/bin/bash NAME_SPACE=$1 IMAGE_NAME=$2 GIT_TAG=$3 echo "[*] Push image starting...." echo "[*] NameSpace: $NAME_SPACE, Image: $IMAGE_NAME, GitTag: $GIT_TAG" docker login k8s-docker-store.tencentcloudcr.com --username 100017072018 --password ey****** if [ "$?" -eq 0 ]; then docker push k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/$IMAGE_NAME:$GIT_TAG if [ "$?" -eq 0 ]; then docker rmi k8s-docker-store.tencentcloudcr.com/$NAME_SPACE/$IMAGE_NAME:$GIT_TAG else exit 1 fi else exit 1 fi
#!/bin/bash ###################################### # # 按照不同的环境部署不同的业务 # ###################################### NAME_SPACE=${NameSpace} KUBECTL=/usr/bin/kubectl GIT_TAG=$(git describe --tags --always) CHECK_BUILD_COUNT=0 TEMPLATE_TYPE=${templateType} # 删除临时的内容 rm -rf k8s # 先确保k8s的配置是最新的 git clone git@git.xiaodongai.com:devops/k8s.git # 判断这个环境是否有这个配置 if [ -d "k8s/$NAME_SPACE/${JOB_NAME}" ]; then # 查configmap并且配置configmap if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/configmap.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/configmap.yml -n $NAME_SPACE --record fi # 查deployment并且配置deployment if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/deployment.yml" ];then sed -i "s/<TAG>/$GIT_TAG/g" k8s/$NAME_SPACE/${JOB_NAME}/deployment.yml sed -i "s/<NAME_SPACE>/$NAME_SPACE/g" k8s/$NAME_SPACE/${JOB_NAME}/deployment.yml $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/deployment.yml -n $NAME_SPACE --record fi # 查damonset并且配置damonset if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/damonset.yml" ];then sed -i "s/<TAG>/$GIT_TAG/g" k8s/$NAME_SPACE/${JOB_NAME}/damonset.yml sed -i "s/<NAME_SPACE>/$NAME_SPACE/g" k8s/$NAME_SPACE/${JOB_NAME}/damonset.yml $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/damonset.yml -n $NAME_SPACE --record fi # 查ingress并且配置ingress if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/ingress.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/ingress.yml -n $NAME_SPACE --record fi # 查service并且配置service if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/service.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/service.yml -n $NAME_SPACE --record fi # 查secret并配置secret if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/secret.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/secret.yml -n $NAME_SPACE --record fi # 查PersistentVolumeClaim并配置PersistentVolumeClaim if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/PersistentVolumeClaim.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/PersistentVolumeClaim.yml -n $NAME_SPACE --record fi # 查StorageClass并配置StorageClass if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/StorageClass.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/StorageClass.yml -n $NAME_SPACE --record fi # 查rbac_prom并配置rbac_prom if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/rbac_prom.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/rbac_prom.yml -n $NAME_SPACE --record fi # 查cluster-role并配置cluster-role if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/cluster-role.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/cluster-role.yml -n $NAME_SPACE --record fi # 查cluster-role-binding并配置cluster-role-binding if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/cluster-role-binding.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/cluster-role-binding.yml -n $NAME_SPACE --record fi # 查service-account并配置service-account if [ -f "k8s/$NAME_SPACE/${JOB_NAME}/service-account.yml" ];then $KUBECTL apply -f k8s/$NAME_SPACE/${JOB_NAME}/service-account.yml -n $NAME_SPACE --record fi # 部署发布 $KUBECTL describe deployment ${JOB_NAME} -n $NAME_SPACE # 首次获取job的数字判断是否发布成功 JOB=`kubectl get pods -n $NAME_SPACE |grep ${JOB_NAME} |grep "Running" | wc -l` while [ $JOB -lt 1 ] do if [ $CHECK_BUILD_COUNT -eq 10 ]; then exit 1 fi CHECK_BUILD_COUNT=$((CHECK_BUILD_COUNT + 1)) echo "当前启动中..." JOB=`kubectl get pods -n $NAME_SPACE |grep ${JOB_NAME} |grep "Running" | wc -l` sleep 3 done # 获取ip信息 K8S_OUT_IP=$($KUBECTL get svc ${JOB_NAME} -o jsonpath='{.status.loadBalancer.ingress[0].ip}' -n $NAME_SPACE) echo "[*] 发布部署后的IP是: $K8S_OUT_IP" fi
之后的项目的Jenkins配置类似,不再提供截图了.
然后拉取Prometheus的Jenkins项目 如果有报错解决它 正常起来后
访问地址 容器IP+端口
二.安装node-exporter容器
1.新建gitlab 项目
-dockerfile.yml:
FROM prom/node-exporter:latest
2.创建容器配置文件
apiVersion: apps/v1 kind: DaemonSet metadata: name: xd-node-exporter-center spec: template: metadata: labels: app: xd-node-exporter-center spec: containers: - name: xd-node-exporter-center image: k8s-docker-store.tencentcloudcr.com/<NAME_SPACE>/xd-node-exporter-center:<TAG> ports: - name: scrape containerPort: 9100 resources: requests: cpu: 0.5 memory: 256Mi limits: cpu: 1 memory: 512Mi hostNetwork: true hostPID: true restartPolicy: Always
apiVersion: v1 kind: Service metadata: annotations: prometheus.io/scrape: 'true' labels: app: xd-node-exporter-center name: xd-node-exporter-center name: xd-node-exporter-center spec: clusterIP: None ports: - name: scrape port: 9100 protocol: TCP selector: app: xd-node-exporter-center
3.创建对应Jenkins项目
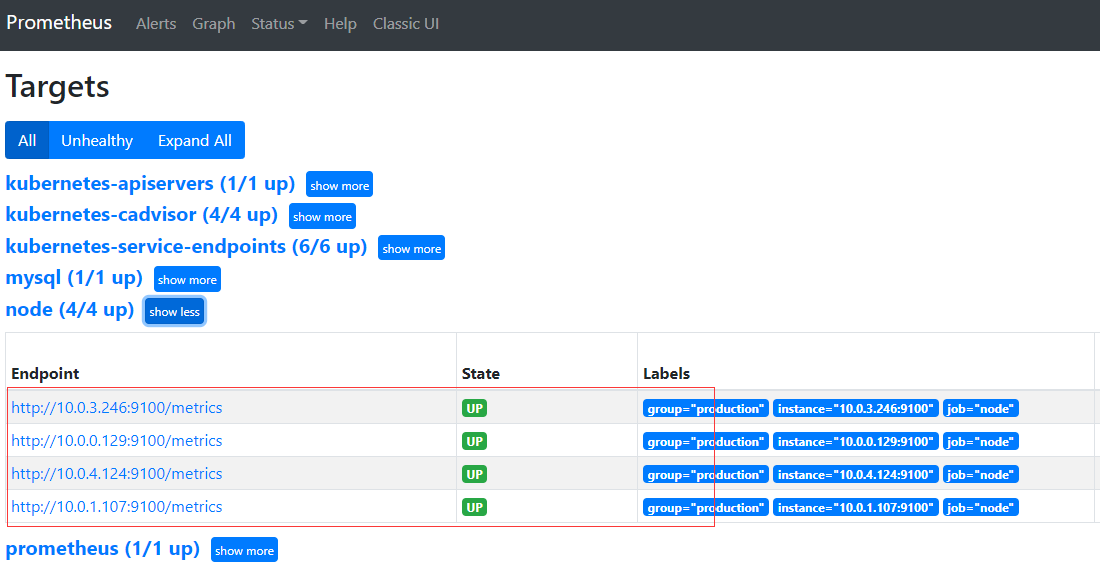
容器启动之后 Prometheus上面会多出新增的node节点
三.实现api server 监控
在prometheus.yml中加上api server监控的job:(上面文件里面已经包含了)
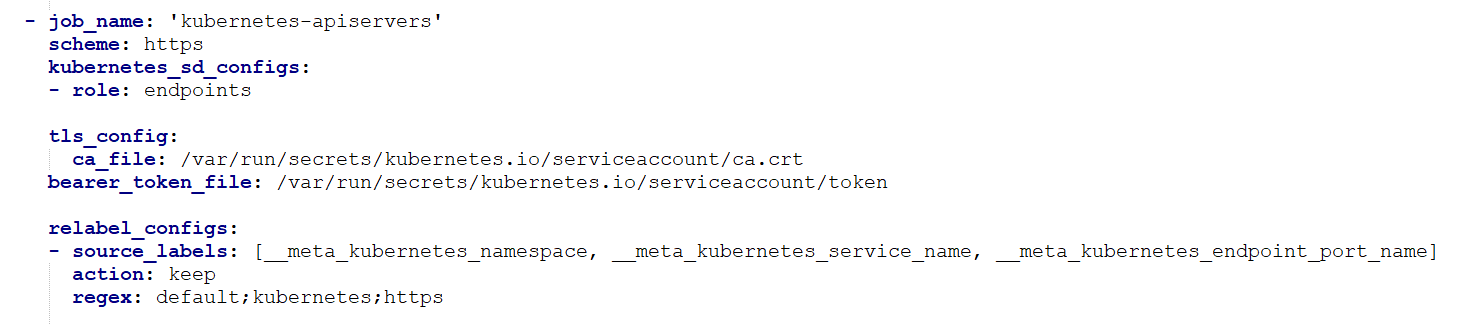
参数解释如下:
scheme:http还是https协议,默认是http,api server采用https方式通信,因此这些要写成https
role:prometheus对于k8s的监控,分为几种角色,node、pod、endpoint、ingress等。api server暴露的是endpoint类型接口。
tlc_config:指的是https认证的证书信息,其中ca_file指的是认证证书。bearer_token_file指的是用token进行认证。
relabel_configs表示,对label进行二次过滤或命名。对source_labels的内容中匹配__meta_kubernetes_namespace=default,__meta_kubernetes_service_name=kubernetes,__meta_kubernetes_endpoint_port_name=https的,keep,即保留。其他值则全部丢弃。
然后重启prometheus pod后,web ui的target处会多出kubernetes-apiservers的target: 表明api server监控成功。
四.安装kube-state-metrics容器
1.创建对应gitlab项目仓库用来构建镜像.
-dockerfile.yml:
FROM quay.io/coreos/kube-state-metrics:v1.9.
2.创建容器配置文件
-deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
prometheus_io_scrape: true
labels:
app.kubernetes.io/name: xiaodong-kube-state-metrics-center
app.kubernetes.io/version: v1.9.8
name: xiaodong-kube-state-metrics-center
spec:
revisionHistoryLimit: 10
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: xiaodong-kube-state-metrics-center
template:
metadata:
labels:
app: xiaodong-kube-state-metrics-center
spec:
serviceAccountName: xiaodong-kube-state-metrics-center
containers:
- name: xiaodong-kube-state-metrics-center
image: k8s-docker-store.tencentcloudcr.com/<NAME_SPACE>/xiaodong-kube-state-metrics-center:<TAG>
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: xiaodong-kube-state-metrics-center
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
resources:
requests:
cpu: 0.1
memory: 128Mi
limits:
cpu: 0.5
memory: 256Mi
nodeSelector:
kubernetes.io/os: linux
-service.yml
![]() service.yml
service.yml
apiVersion: v1 kind: Service metadata: labels: app.kubernetes.io/name: xd-kube-state-metrics-center app.kubernetes.io/version: v1.9.8 name: xd-kube-state-metrics-center namespace: devops annotations: prometheus.io/scrape: "true" spec: type: LoadBalancer ports: - name: http-metrics port: 8080 targetPort: http-metrics - name: telemetry port: 8081 targetPort: telemetry selector: app: xd-kube-state-metrics-center
-cluster-role.yml #一组权限的集合
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: app.kubernetes.io/name: xd-kube-state-metrics-center app.kubernetes.io/version: v1.9.8 name: xd-kube-state-metrics-center rules: - apiGroups: - "" resources: - configmaps - secrets - nodes - pods - services - resourcequotas - replicationcontrollers - limitranges - persistentvolumeclaims - persistentvolumes - namespaces - endpoints verbs: - list - watch - apiGroups: - extensions resources: - daemonsets - deployments - replicasets - ingresses verbs: - list - watch - apiGroups: - apps resources: - statefulsets - daemonsets - deployments - replicasets verbs: - list - watch - apiGroups: - batch resources: - cronjobs - jobs verbs: - list - watch - apiGroups: - autoscaling resources: - horizontalpodautoscalers verbs: - list - watch - apiGroups: - authentication.k8s.io resources: - tokenreviews verbs: - create - apiGroups: - authorization.k8s.io resources: - subjectaccessreviews verbs: - create - apiGroups: - policy resources: - poddisruptionbudgets verbs: - list - watch - apiGroups: - certificates.k8s.io resources: - certificatesigningrequests verbs: - list - watch - apiGroups: - storage.k8s.io resources: - storageclasses - volumeattachments verbs: - list - watch - apiGroups: - admissionregistration.k8s.io resources: - mutatingwebhookconfigurations - validatingwebhookconfigurations verbs: - list - watch - apiGroups: - networking.k8s.io resources: - networkpolicies verbs: - list - watch
-cluster-role-binding.yml #基于上面的配置文件授予对应的用户及用户组
apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: app.kubernetes.io/name: xd-kube-state-metrics-center app.kubernetes.io/version: v1.9.8 name: kube-state-metrics roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: xd-kube-state-metrics-center subjects: - kind: ServiceAccount name: xd-kube-state-metrics-center namespace: devops
-service-account.yml #为Pod中的进程和外部用户提供身份信息
apiVersion: v1 kind: ServiceAccount metadata: labels: app.kubernetes.io/name: xd-kube-state-metrics-center app.kubernetes.io/version: v1.9.8 name: xd-kube-state-metrics-center namespace: devops
3.创建对应Jenkins项目
起来后 可以通过 容器IP+端口访问 说明服务部署成功
4.集成到Prometheus里面
在prometheus.yml里面添加以下内容(上面的prometheus.yml里面已经添加过)

重启Prometheus服务之后正常情况下 prometheus上面会看到 以下信息
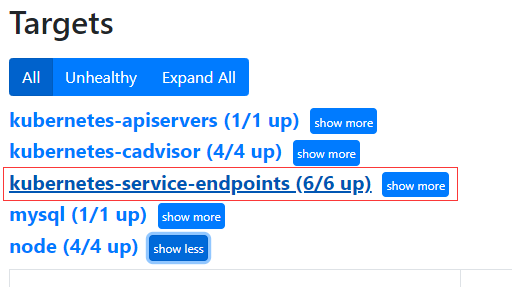
因为kube-state-metrics只能看状态信息 想要监控pod的资源信息还需要cadvisor
五.安装cadvisor
因TKE已经集成了cadvisor 我们需要做的 只是开放权限 在prometheus的rbac_prom.yml的文件里面 添加这行 - nodes/proxy即可 重新拉取服务就课题在Prometheus页面看到cadvisor监控项
六.安装grafana容器
1.部署对应gitlab项目
dockerfile.yml内容如下:
FROM grafana/grafana:latest
2.部署配置容器项目
-deployment.yml#设置容器名称/资源大小等
apiVersion: apps/v1 kind: Deployment metadata: name: xd-grafana-center labels: app: xd-grafana-center spec: revisionHistoryLimit: 10 replicas: 1 strategy: type: Recreate selector: matchLabels: app: xd-grafana-center template: metadata: labels: app: xd-grafana-center spec: containers: - name: xd-grafana-center image: k8s-docker-store.tencentcloudcr.com/<NAME_SPACE>/xd-grafana-center:<TAG> ports: - containerPort: 80 name: grafana env: - name: GF_SECURITY_ADMIN_USER value: admin - name: GF_SECURITY_ADMIN_PASSWORD value: xd readinessProbe: failureThreshold: 10 httpGet: path: /api/health port: 3000 scheme: HTTP initialDelaySeconds: 60 periodSeconds: 10 successThreshold: 1 timeoutSeconds: 30 livenessProbe: failureThreshold: 3 httpGet: path: /api/health port: 3000 scheme: HTTP periodSeconds: 10 successThreshold: 1 timeoutSeconds: 1 resources: requests: cpu: 0.5 memory: 512Mi limits: cpu: 1 memory: 2048Mi volumeMounts: - name: default-storage mountPath: /var/lib/grafana securityContext: fsGroup: 472 runAsUser: 472 volumes: - name: default-storage persistentVolumeClaim: claimName: xd-grafana-center-storage
-service.yml #定义容器网络情况
apiVersion: v1 kind: Service metadata: name: xd-grafana-center labels: app: xd-grafana-center spec: type: LoadBalancer selector: app: xd-grafana-center ports: - protocol: TCP port: 80 targetPort: 3000
-PersistentVolumeClaim.yml #定义对PV资源的请求包括指定使用何种存储资源,使用多少GB,以何种模式使用PV等信息
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: xd-grafana-center-storage
spec:
accessModes:
- ReadWriteOnce
storageClassName: xd-grafana-center
resources:
requests:
storage: 200Gi
-StorageClass.yml # 持久化存储
apiVersion: storage.k8s.io/v1
allowVolumeExpansion: true
kind: StorageClass
metadata:
name: xd-grafana-center
parameters:
diskType: CLOUD_PREMIUM
provisioner: com.tencent.cloud.csi.cbs
reclaimPolicy: Delete
volumeBindingMode: Immediate
3.部署对应Jenkins项目
容器起来之后 访问界面如下
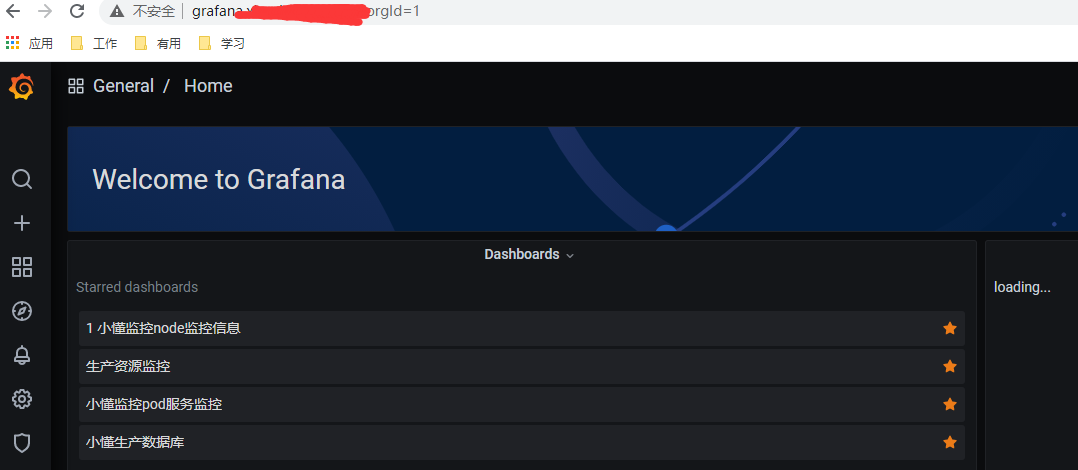
grafana官网上面有很多模板可以下载 地址:https://grafana.com/grafana/dashboards
根据需要下载即可
4.根据自身情况修改promsql语句以便更好的展示监控信息
-修改数据源
-检查监控数据是否准确
主要是看模板的自定义变量是不是能用
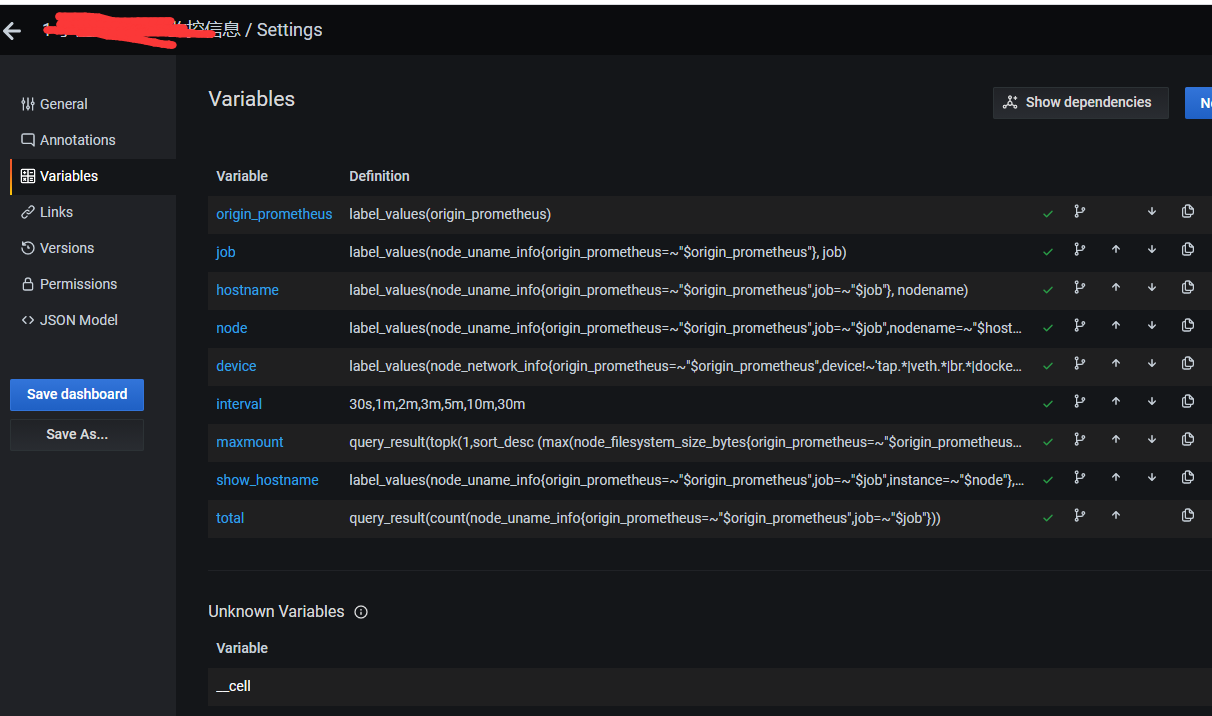
这个地方要设定好
七.安装alertmanager容器
1.部署对应gitlab项目
dockerfile.yml内容如下:
FROM prom/alertmanager
2.部署配置容器项目
-deployment.yml#设置容器名称/资源大小等
apiVersion: apps/v1 kind: Deployment metadata: name: xd-alertmanager-service labels: app: xd-alertmanager-service spec: revisionHistoryLimit: 10 replicas: 1 strategy: type: RollingUpdate selector: matchLabels: app: xd-alertmanager-service template: metadata: labels: app: xd-alertmanager-service spec: containers: - name: xd-alertmanager-service image: k8s-docker-store.tencentcloudcr.com/<NAME_SPACE>/xd-alertmanager-service:<TAG> ports: - containerPort: 9093 protocol: TCP volumeMounts: - mountPath: "/etc/alertmanager" name: alertmanager resources: requests: cpu: 0.5 memory: 256Mi limits: cpu: 1 memory: 512Mi volumes: - name: alertmanager configMap: name: xd-alertmanager-service
-configmap.yml#定义邮箱配置及发送邮件告警规则
apiVersion: v1 kind: ConfigMap metadata: name: xd-alertmanager-service data: alertmanager.yml: | global: resolve_timeout: 5m # 告警自定义邮件 smtp_smarthost: 'smtp.exmail.qq.com:465' smtp_from: 'yunwei@xdai.com' smtp_auth_username: 'yunwei@xdai.com' smtp_auth_password: 'Yw@12345' smtp_hello: '告警通知' smtp_require_tls: false # 定义路由树信息 route: group_by: ['alertname'] # 报警分组名称 group_wait: 10s # 最初即第一次等待多久时间发送一组警报的通知 group_interval: 10s # 在发送新警报前的等待时间 repeat_interval: 2h # 发送重复警报的周期 receiver: 'email' # 发送警报的接收者的名称,以下receivers name的名称 receivers: - name: 'email' email_configs: - to: '67373783@qq.com' #send_resolved: true
-service.yml
apiVersion: v1 kind: Service metadata: name: xd-alertmanager-service labels: app: xd-alertmanager-service spec: type: NodePort selector: app: xd-alertmanager-service ports: - name: http port: 80 targetPort: 9093 protocol: TCP
3.部署对应Jenkins项目
4.在prometheus.yml里面添加告警模块信息(上面Prometheus.yml里面已经添加过了)
alerting:
# 告警配置文件
alertmanagers:
# 修改:使用静态绑定
- static_configs:
# 修改:targets、指定地址与端口
- targets: ["xd-alertmanager-com:9093"] #k8s里面同一命名空间的pod之间可以通过pod域名+端口直接访问
rule_files: ## rule配置,首次读取默认加载,之后根据evaluation_interval设定的周期加载
- "/etc/prometheus/*rules.yml"
服务起来之后可以通过节点公网IP+节点端口访问如下
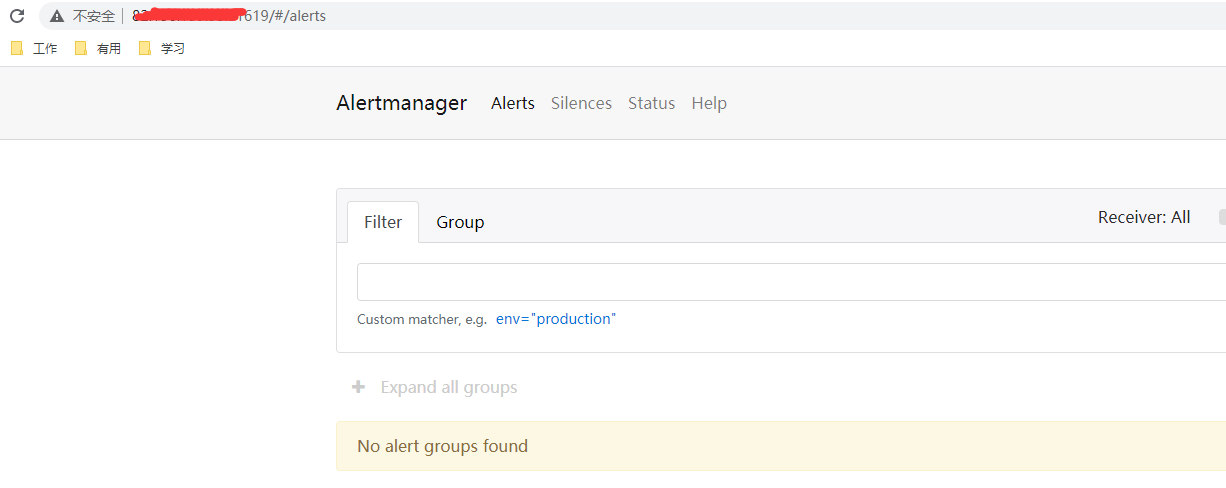
至此整个Prometheus+grafana体系搭建完成.搭建其实不难 ,之后处理监控数据才是比较麻烦的地方.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号