【javaSE】 Java基础
核心关键词:final、finally、finalize、static
1. static
-
基础知识
- static声明的成员变量为
静态成员变量,或类变量 - 类变量的
生命周期和类相同,在整个应用程序执行期间均有效
- static声明的成员变量为
-
细节
- static修饰的成员变量和方法,从属于类
- 普通变量和方法,从属于对象
- 静态方法不能调用非静态成员,编译将报错
- 被static修饰的方法或者变量,不需要依靠对象进行访问,只要类被加载,即类的生命周期开始,就可以通过类名进行访问。
- 在访问权限足够的情况下,对象是可以访问静态方法和静态变量的。所以通过this代表对象是可以访问静态方法和静态变量的。
- Java语法规定,static不允许修饰局部变量。
-
用途
便于在没有创建对象的情况下进行调用(方法/变量)。
1.修饰类的成员方法、类的成员变量
2.编写静态代码块,优化程序性能 -
实例
- 静态方法
静态方法不依赖于任何对象就可以直接访问,因此不需要this,也无法使用this,所有根据此特性,静态方法无法访问非静态成员变量和非静态方法,因为非静态成员变量和非静态方法都必须依赖于具体对象进行调用。 - 静态变量
静态变量被所有对象共享,在内存中只有一个副本,在类初次加载时即被初始化。
非静态变量是对象拥有的,在创建对象时初始化,存在多个副本,各个对象拥有的副本,互不影响。 - 静态代码块
构造方法用于对象的初始化。静态初始化快,用于类的初始化操作。
在静态代码块中不能直接访问非static成员。
作用:提升程序性能。
原因:减少重复对象的生成,降低空间浪费。
- 静态方法
-
面试点
情景:B继承A,A和B类都有自己的静态代码块和构造器,main方法,new一个B对象,说明两个类的静态代码块和构造器的执行顺序。
答案:执行main之前需要加载B类。加载时发现B继承A,于是先加载A类。加载A类时发现有staic块,先①执行static块。A类加载完,加载B类,发现B有static块,②执行static块。A、B加载之后,执行main方法,new一个B对象,④调用B(子)类构造器前,先③调用A(父)类构造器。
结果:A静态代码块 → B静态代码块 → A构造器 → B构造器
补充情景:C类含静态代码块和构造器,A和B类中均有一个C类对象C c = new C();
结果:A静态代码块 → B静态代码块 → C静态代码块 → C构造器 → A构造器 → C构造器 → B构造器
细节:调用B类构造器生成对象前,需要先初始化父类A的成员变量,执行C c = new C();,发现C未加载,加载C,发现C有静态代码块,执行静态代码块,再执行C构造器。调用父类A构造器,完成父类A初始化,再初始化B类成员变量,执行C类构造器。
2.final
-
基础知识
被final修饰的类是最终类,不能有子类
如:String类 -
细节
- 被final修饰的方法为最终方法,子类可以继承使用,但是不能修改
- 被final修饰的变量(常量,一旦被复制,不可修改,必须再初始化对象时赋值):
- 成员变量:必须声明时初始化或构造器中初始化,否则编译报错
- 局部变量:必须声明时赋值,否则声明不报错,调用时编译报错
- 方法参数:方法中,不可改变该参数,例:
public void Test(final Integer i)
- 被final修饰的数据类型:
- 大多修饰基本数据类型,实际变量值不变
- 修饰引用类型,引用地址不变,即不能再指向别的对象,所指对象内容是可以改变的
- final不能修饰
- 不能修饰抽象类:因为抽象类被继承才会有作用,儿final修饰的类不能被继承
- 不能修饰构造器:因为构造器既不能被继承,也不能被重写,因此使用final无意义
- final关键词有点
- 使用final关键词提高性能,JVM和Java应用都会缓存final变量
- final变量可以安全地在多线程环境下共享,而不需要额外同步开销
- 使用final关键词,JVM会对方法、变量、类进行优化
3.finally
-
基础知识
finally与try、catch组合使用,用于捕捉异常进行处理。 -
细节
- finally块中内容先于try中return的执行。
如果finally中有return,则直接会在finally中返回,这也是不建议在finally中返回的原因。 - try语句在返回前,将其他所有的操作执行完,保留好要返回的值,而后转入执行finally中的语句,而后分为以下三种情况:
- 如inally中有return语句,则会将try中的return语句”覆盖“掉,直接执行finally中的return语句,得到返回值,这样便无法得到try之前保留好的返回值。
- 如果finally中没有return语句,也没有改变要返回值,则执行完finally中的语句后,会接着执行try中的return语句,返回之前保留的值。
- 如果finally中没有return语句,但是改变了要返回的值,这里有点类似与引用传递和值传递的区别,分以下两种情况,:
1)如果return的数据是基本数据类型或文本字符串,则在finally中对该基本数据的改变不起作用,try中的return语句依然会返回进入finally块之前保留的值。
2)如果return的数据是引用数据类型,而在finally中对该引用数据类型的属性值的改变起作用,try中的return语句返回的就是在finally中改变后的该属性的值。
- finally块中内容先于try中return的执行。
4.finalize
-
基础知识
- finalize()是Object的protected方法,子类可以覆盖该方法以实现资源清理工作,GC在回收对象之前调用该方法。
- finalize()与C++中的析构函数不是对应的。C++中的析构函数调用的时机是确定的(对象离开作用域或delete掉),但Java中的finalize的调用具有不确定性
- 不建议用finalize方法完成“非内存资源”的清理工作,但建议用于:
① 清理本地对象(通过JNI创建的对象);
② 作为确保某些非内存资源(如Socket、文件等)释放的一个补充:在finalize方法中显式调用其他资源释放方法。
-
原理
- Jvm会给每个实现了finalize方法的实例创建一个监听,这个称为
Finalizer。每次调用对象的finalize方法时,JVM会创建一个java.lang.ref.Finalizer对象,这个Finalizer对象会持有这个对象的引用,由于这些对象被Finilizer对象引用了,当对象数量较多时,就会导致Eden区空间满了,经历多次youngGC后可能对象就进入到老年代了。
java.lang.ref.Finalizer类继承自java.lang.ref.FinalReference,因此Finalizer类里有一个引用队列,是JVM和垃圾回收器打交道的唯一途径,当垃圾回收器需要回收该对象时,会把该对象放到引用队列中,这样java.lang.ref.Finalizer类就可以从队列中取出该对象,执行对象的finalize方法,并清除和该对象的引用关系。需要注意的是只有finalize方法实现不为空时JVM才会执行上述操作,JVM在类的加载过程中会标记该类是否为finalize类。 - 当老年代空间达到了OldGC条件时,JVM执行一次OldGC,当OldGC执行后JVM检测到这些对象只被Finalizer对象引用,这些对象会被标记成要被清除的对象,GC会把所有的Finalizer对象放入到一个引用队列:java.lang.ref.Finalizer.ReferenceQueue。
- JVM默认会创建一个finalizer线程来处理Finalizer对象。这个线程唯一的职责就是不断的从java.lang.ref.Finalizer.ReferenceQueue队列中取对象,当一个对象进入到队列中,finalizer线程就执行对象的finalize方法并且把对象从队列中删除,因此在下一次GC周期中可以看到这个对象和Finalizer对象都被清除了。
大部分场景finalizer线程清理finalizer队列是比较快的,但是一旦你在finalize方法里执行一些耗时的操作,可能导致内存无法及时释放进而导致内存溢出的错误,在实际场景还是推荐尽量少用finalize方法。
- Jvm会给每个实现了finalize方法的实例创建一个监听,这个称为
补充:
目前主流的虚拟机实现都采用了分代收集的思想,把整个堆区划分为新生代和老年代;新生代又被划分成Eden 空间、 From Survivor 和 To Survivor 三块区域。
我们把Eden : From Survivor : To Survivor 空间大小设成 8 : 1 : 1 ,对象总是在 Eden 区出生, From Survivor 保存当前的幸存对象, To Survivor 为空。一次 gc 发生后:
- Eden 区活着的对象 + From Survivor 存储的对象被复制到 To Survivor ;
- 清空 Eden 和 From Survivor ;
- 颠倒 From Survivor 和 To Survivor 的逻辑关系: From 变 To , To 变 From 。可以看出,只有在 Eden 空间快满的时候才会触发 Minor GC 。而 Eden 空间占新生代的绝大部分,所以 Minor GC 的频率得以降低。当然,使用两个 Survivor 这种方式我们也付出了一定的代价,如 10% 的空间浪费、复制对象的开销等。
String相关
字符型常量和字符串常量的区别
形式上: 字符常量是单引号引起的一个字符,字符串常量是双引号引起的若干个字符
含义上: 字符常量相当于一个整形值(ASCII值),可以参加表达式运算,字符串常量代表一个地址值(该字符串在内存中存放位置)
占内存大小:字符常量只占一个字节,字符串常量占若干个字节(至少一个字符结束标志)
什么是字符串常量池
-
基础知识
字符串常量池又称为:字符串池,全局字符串池,英文也叫String Pool。 在工作中,String类是我们使用频率非常高的一种对象类型。JVM为了提升性能和减少内存开销,避免字符串的重复创建,其维护了一块特殊的内存空间,这就是我们今天要讨论的核心:字符串常量池。字符串常量池由String类私有的维护。
在JDK7之前字符串常量池是在永久代里边的,但是在JDK7之后,把字符串常量池分进了堆里,如下图所示:
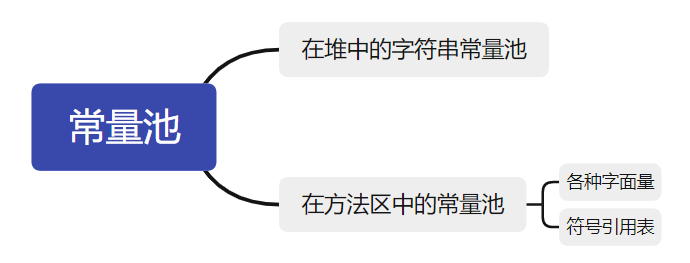
在堆中的字符串常量池:堆里边的字符串常量池存放的是字符串的引用或者字符串(两者都有) -
细节
- 创造字符串的两种方式:
采用字面值的方式创建一个字符串"aaa"。
JVM首先会去字符串池中查找是否存在"aaa"这个对象,
如果不存在,则在字符串池中创建"aaa"这个对象,然后将池中"aaa"这个对象的引用地址返回给字符串常量str,这样str会指向池中"aaa"这个字符串对象;
如果存在,则不创建任何对象,直接将池中"aaa"这个对象的地址返回,赋给字符串常量。采用new关键字新建一个字符串对象。
JVM首先在字符串常量池中查找有没有"aaa"这个字符串对象,
如果有,则不在池中再去创建"aaa"这个对象了,直接在堆中创建一个"aaa"字符串对象,然后将堆中的这个"aaa"对象的地址返回赋给引用str1,这样,str1就指向了堆中创建的这个"aaa"字符串对象;
如果没有,则首先在字符串常量池池中创建一个"aaa"字符串对象,然后再在堆中创建一个"aaa"字符串对象,然后将堆中这个"aaa"字符串对象的地址返回赋给str1引用,这样,str1指向了堆中创建的这个"aaa"字符串对象。
- 创造字符串的两种方式:
字符串池的实现有一个前提条件:String对象是不可变的。因为这样可以保证多个引用可以同时指向字符串池中的同一个对象。如果字符串是可变的,那么一个引用操作改变了对象的值,对其他引用会有影响,这样显然是不合理的。
String、StringBuffer、StringBuilder
-
String 和 StringBuffer,StringBuilder
相同点:String,StringBuffer,StringBuilder都是可以用来存储字符串的
不同点:- String存储的字符串是不可变的,StringBuffer、StringBuilder存储的字符串是可变的。
其中在String中增加字符串时,有两种方法:用 “+” 拼接和concat()添加【注意:这里拼接后的字符串是重新的一个字符串。这个字符串如果在常连池存在就直接指向,如果不在就是创建之后放入常连池,再指向,而并不是在原来的基础上拼接】 - 一般StringBuffer和StringBuilder添加字符串的速度比String添加的快【因为String是重新创建一个字符串,在重新指向;而StringBuffer和StringBuilder是直接在后面拼接】
- String存储的字符串是不可变的,StringBuffer、StringBuilder存储的字符串是可变的。
-
StringBuffer 和 StringBuilder
相同点:共用一套API,StringBuilder是在StringBuffer的基础上产生的;
不同点:
- StringBuffer线程安全,StringBuilder线程不安全;
- StringBuilder速率比StringBuffer速率快;(有点在某些方面有时候就是缺点,StringBuffer慢的原因就是有锁安全,因此就慢,想象一下自己在排队过安检的时候)
包装类型
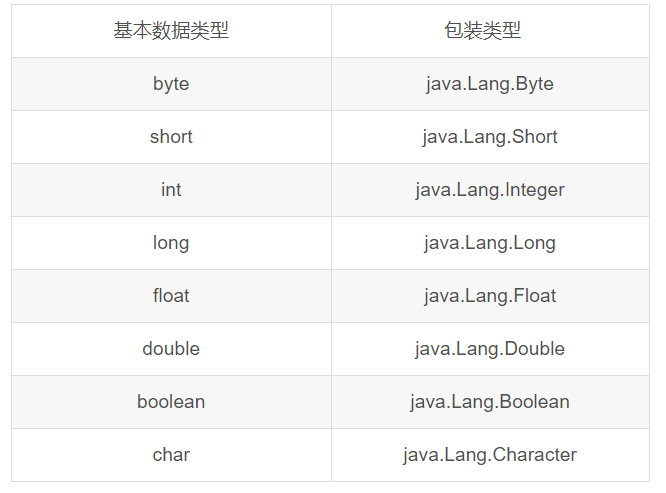
前六个的父类是抽象类Number,Number在继承Object,后两个直接继承Object。
- Number提供了拆箱的方法。将基本数据类型变为包装类型成为装箱,反之为拆箱。
- Integer类的构造方法。Integer(int value)和integer( String s)两种构造方法
- Integer类提供两个常量:MAX_VALUE和MIN_VALUE
- 自JDK1.5之后,支持自动拆箱和装箱。
反射
什么是反射(内省)
反射是由Class对象开始的,从Class对象中,我们可以:
- 获取有关该类的全部成员的完整列表
- 找出该类的所有类型(它实现的接口和扩展的类)
- 发现关于类自身的信息(它所应用的修饰符public、abstract、final等等,或者它所在的包)
反射机制提供的功能主要有:
- 得到一个对象所属的类
- 获取一个类的所有成员变量和方法
- 在运行时创建对象
- 在运行时调用对象的方法
获取类的三种方法(返回类型都是Class类型)
- Class.forName("类的路径带包名")
- 类名.Class
- 对象.getClass
注:必须先获得Class才能获取Method、Constructor、Field。
通过反射实例化对象
对象.newInstance()
注:newInstance()方法内部实际上调用了无参数构造方法,必须保证无参构造存在才可以。 否则会抛出java.lang.InstantiationException异常。
举例:
class ReflectTest02{
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException {
// 下面这段代码是以反射机制的方式创建对象。
// 通过反射机制,获取Class,通过Class来实例化对象
Class c = Class.forName("javase.reflectBean.User");
// newInstance() 这个方法会调用User这个类的无参数构造方法,完成对象的创建。
// 重点是:newInstance()调用的是无参构造,必须保证无参构造是存在的!
Object obj = c.newInstance();
System.out.println(obj);
}
}
重点
- JDBC重点(Class.forName导致类加载)
情景:只希望一个类的静态代码块执行,其他代码不执行,可以使用:Class.forName("完整类名");
这个方法的执行会导致类加载,类加载时,静态代码块执行 - set()可以访问私有属性嘛?不可以,需要打破封装,才可以。

// 可以访问私有的属性吗?
Field nameField = studentClass.getDeclaredField("name");
// 打破封装(反射机制的缺点:打破封装,可能会给不法分子留下机会!!!)
// 这样设置完之后,在外部也是可以访问private的。
nameField.setAccessible(true);
// 给name属性赋值
nameField.set(obj, "xiaowu");
// 获取name属性的值
System.out.println(nameField.get(obj));
方法应用
- 反编译一个类的属性Field
//通过反射机制,反编译一个类的属性Field(了解一下)
class ReflectTest06{
public static void main(String[] args) throws ClassNotFoundException {
StringBuilder s = new StringBuilder();
Class studentClass = Class.forName("javase.reflectBean.Student");
s.append(Modifier.toString(studentClass.getModifiers()) + " class " + studentClass.getSimpleName() + " {\n");// Class类的getName方法
//获取所有的属性
Field[] fields = studentClass.getDeclaredFields();
for (Field f : fields){
s.append("\t");
// 获取属性的修饰符列表,返回的修饰符是一个数字,每个数字是修饰符的代号
// 用Modifier类的toString转换成字符串
s.append(Modifier.toString(f.getModifiers()));
if (f.getModifiers() != 0) s.append(" ");
s.append(f.getType().getSimpleName());// 获取属性的类型
s.append(" ");
s.append(f.getName());// 获取属性的名字
s.append(";\n");
}
s.append("}");
System.out.println(s);
}
}
- 通过反射机制访问一个java对象的属性
/*
必须掌握:
怎么通过反射机制访问一个java对象的属性?
给属性赋值set
获取属性的值get
*/
class ReflectTest07{
public static void main(String[] args) throws ClassNotFoundException, InstantiationException, IllegalAccessException, NoSuchFieldException {
//不使用反射机制给属性赋值
Student student = new Student();
/**给属性赋值三要素:给s对象的no属性赋值1111
* 要素1:对象s
* 要素2:no属性
* 要素3:1111
*/
student.no = 1111;
/**读属性值两个要素:获取s对象的no属性的值。
* 要素1:对象s
* 要素2:no属性
*/
System.out.println(student.no);
//使用反射机制给属性赋值
Class studentClass = Class.forName("javase.reflectBean.Student");
Object obj = studentClass.newInstance();// obj就是Student对象。(底层调用无参数构造方法)
// 获取no属性(根据属性的名称来获取Field)
Field noField = studentClass.getDeclaredField("no");
// 给obj对象(Student对象)的no属性赋值
/*
虽然使用了反射机制,但是三要素还是缺一不可:
要素1:obj对象
要素2:no属性
要素3:22222值
注意:反射机制让代码复杂了,但是为了一个“灵活”,这也是值得的。
*/
noField.set(obj, 22222);
// 读取属性的值
// 两个要素:获取obj对象的no属性的值。
System.out.println(noField.get(obj));
}
- 通过反射机制调用一个对象的方法
/*
重点:必须掌握,通过反射机制怎么调用一个对象的方法?
五颗星*****
反射机制,让代码很具有通用性,可变化的内容都是写到配置文件当中,
将来修改配置文件之后,创建的对象不一样了,调用的方法也不同了,
但是java代码不需要做任何改动。这就是反射机制的魅力。
*/
class ReflectTest10{
public static void main(String[] args) throws Exception {
// 不使用反射机制,怎么调用方法
// 创建对象
UserService userService = new UserService();
// 调用方法
/*
要素分析:
要素1:对象userService
要素2:login方法名
要素3:实参列表
要素4:返回值
*/
System.out.println(userService.login("admin", "123") ? "登入成功!" : "登入失败!");
//使用反射机制调用方法
Class userServiceClass = Class.forName("javase.reflectBean.UserService");
// 创建对象
Object obj = userServiceClass.newInstance();
// 获取Method
Method loginMethod = userServiceClass.getDeclaredMethod("login", String.class, String.class);
// Method loginMethod = userServiceClass.getDeclaredMethod("login");//注:没有形参就不传
// 调用方法
// 调用方法有几个要素? 也需要4要素。
// 反射机制中最最最最最重要的一个方法,必须记住。
/*
四要素:
loginMethod方法
obj对象
"admin","123" 实参
retValue 返回值
*/
Object resValues = loginMethod.invoke(obj, "admin", "123");//注:方法返回值是void 结果是null
System.out.println(resValues);
}
}
/*
反编译一个类的Constructor构造方法。
*/
class ReflectTest11{
public static void main(String[] args) throws ClassNotFoundException {
StringBuilder s = new StringBuilder();
Class vipClass = Class.forName("javase.reflectBean.Vip");
//public class UserService {
s.append(Modifier.toString(vipClass.getModifiers()));
s.append(" class ");
s.append(vipClass.getSimpleName());
s.append("{\n");
Constructor[] constructors = vipClass.getDeclaredConstructors();
for (Constructor c : constructors){
//public Vip(int no, String name, String birth, boolean sex) {
s.append("\t");
s.append(Modifier.toString(c.getModifiers()));
s.append(" ");
// s.append(c.getName());//包名+类名
s.append(vipClass.getSimpleName());//类名
s.append("(");
Class[] parameterTypes = c.getParameterTypes();
for (int i = 0; i < parameterTypes.length; i++){
s.append(parameterTypes[i].getSimpleName());
if (i != parameterTypes.length - 1 ) s.append(", ");
}
s.append("){}\n");
}
s.append("}");
System.out.println(s);
}
}
- 反编译一个类的构造方法Constructor
/*
反编译一个类的Constructor构造方法。
*/
class ReflectTest11{
public static void main(String[] args) throws ClassNotFoundException {
StringBuilder s = new StringBuilder();
Class vipClass = Class.forName("javase.reflectBean.Vip");
//public class UserService {
s.append(Modifier.toString(vipClass.getModifiers()));
s.append(" class ");
s.append(vipClass.getSimpleName());
s.append("{\n");
Constructor[] constructors = vipClass.getDeclaredConstructors();
for (Constructor c : constructors){
//public Vip(int no, String name, String birth, boolean sex) {
s.append("\t");
s.append(Modifier.toString(c.getModifiers()));
s.append(" ");
// s.append(c.getName());//包名+类名
s.append(vipClass.getSimpleName());//类名
s.append("(");
Class[] parameterTypes = c.getParameterTypes();
for (int i = 0; i < parameterTypes.length; i++){
s.append(parameterTypes[i].getSimpleName());
if (i != parameterTypes.length - 1 ) s.append(", ");
}
s.append("){}\n");
}
s.append("}");
System.out.println(s);
}
}
反射机制的优缺点
-
优点: 运行期类型的判断,动态加载类,提高代码灵活度。
-
缺点: 性能瓶颈:反射相当于一系列解释操作,通知 JVM 要做的事情,性能比直接的java代码要慢很多。
反射机制的原理
流程
- 准备阶段:编译期装载所有的类,将每个类的元信息保存至Class类对象中,每一个类对应一个Class对象
- 获取Class对象:调用x.class/x.getClass()/Class.forName() 获取x的Class对象clz
- 进行实际反射操作:通过clz对象获取Field/Method/Constructor对象进行进一步操作
反射机制的应用场景
反射是框架设计的灵魂。
在我们平时的项目开发过程中,基本上很少会直接使用到反射机制,但这不能说明反射机制没有用,实际上有很多设计、开发都与反射机制有关,例如模块化的开发,通过反射去调用对应的字节码;动态代理设计模式也采用了反射机制,还有我们日常使用的 Spring/Hibernate 等框架也大量使用到了反射机制。
举例:
- 我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
- Spring框架也用到很多反射机制,最经典的就是xml的配置模式。Spring 通过 XML 配置模式装载 Bean 的过程:
- 将程序内所有 XML 或 Properties 配置文件加载入内存中;
- Java类里面解析xml或properties里面的内容,得到对应实体类的字节码字符串以及相关的属性信息;
- 使用反射机制,根据这个字符串获得某个类的Class实例;
- 动态配置实例的属性
泛型
-
什么是泛型
Java泛型是JDK5中引入的新特性,泛型提供了编译时类型安全检测机制,该机制允许程序员在编译时检测到非法的类型。 -
泛型的好处
- 保证了类型的安全性。
在没有泛型之前,从集合中读取到的每一个对象都必须进行类型转换,如果不小心插入了错误的类型对象,在运行时的转换处理就会出错。
有了泛型后,定义好的集合names在编译的时候add错误类型的对象就会编译不通过。
相当于告诉编译器每个集合接收的对象类型是什么,编译器在编译期就会做类型检查,告知是否插入了错误类型的对象,使得程序更加安全,增强了程序的健壮性。 - 消除强制转换
泛型的一个附带好处是,消除源代码中的许多强制类型转换,这使得代码更加可读,并且减少了出错机会。

- 避免了不必要的装箱、拆箱操作,提高程序的性能
在非泛型编程中,将筒单类型作为Object传递时会引起Boxing(装箱)和Unboxing(拆箱)操作,这两个过程都是具有很大开销的。引入泛型后,就不必进行Boxing和Unboxing操作了,所以运行效率相对较高,特别在对集合操作非常频繁的系统中,这个特点带来的性能提升更加明显。
泛型变量固定了类型,使用的时候就已经知道是值类型还是引用类型,避免了不必要的装箱、拆箱操作。
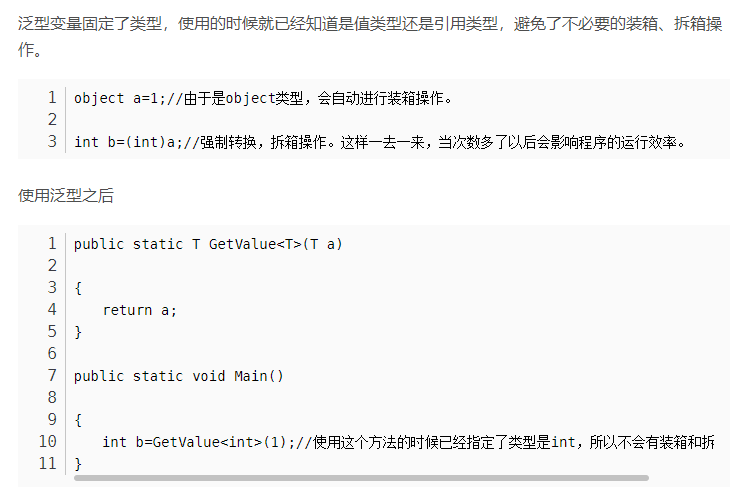
- 提高了代码的重用性。
- 泛型的原理?什么是类型擦除
泛型本质是将数据类型参数化,它通过擦除的方式来实现,即编译器会在编译期间「擦除」泛型语法并相应的做出一些类型转换动作。
例如泛型类 ,只是用来现丁类型的,我们不知道其具体类型。反编译该类,会发现编译器 擦除Caculate类后面的两个尖括号,并且将num的类型定义为Object类型。- 大部分泛型类型都以Object进行擦除
public class Caculate<T>{
private T num; //→ private Object num;
}
2. 使用extends和super语法的有界类型,T会被String擦除,如:
//这是一个类型限定的语法,它限定 T 是 String 或者 String 的子类
//也就是构建 Caculate 实例的时候只能限定 T 为 String 或者 String 的子类
//所以无论限定T为什么类型,String 都是父类,不会出现类型不匹配的问题,于是可以使用 String 进行类型擦除。
public class Caculate<T extends String>
{
private T num; //→ private String num;
}
-
什么是泛型中的限定通配符和非限定通配符 ?
-
List<? extends T>和List <? super T>之间有什么区别?
- 限定通配符:
- 表示类型的上界,格式为:<? extends T>,即类型必须为T类型或者T子类
- 表示类型的下界,格式为:<? super T>,即类型必须为T类型或者T的父类
- 非限定通配符:类型为
,可以用任意类型来替代。
- 限定通配符:
-
可以把List
传递给一个接受List

 浙公网安备 33010602011771号
浙公网安备 33010602011771号