Redis学习
Redis基础学习
Redis基础组成:
- nosql详解
- 阿里巴巴架构演进
- nosql数据模型
- nisql四大分类
- cap
- BASE
- Redis入门
- Redis安装
- 五大基本数据类型
- String
- list
- set
- hash
- zset
- 三种特殊数据类型
- geo
- hyperloglog
- bitmap
- redis配置详解
- redis持久化
- RDB
- AOF
- redis 事务操作
- redis实现订阅发布
- redis主从复制
- redis哨兵模式(现在公司中的所有集群都是哨兵模式)
- 缓存穿透及解决方案
- 缓存击穿和解决方案
- 缓存雪崩及解决方案
- 基础API之Jedis详解
- springboot集成redis
- redis的实践分析
NoSql概述
为什么要用NoSql

大数据时代,一般的数据库无法对海量数据进行分析处理, 2006年Hadoop开始出现;
压力会越来越大, 适者生存 ! 一定要逼着自己学习 , 这是在这个社会生存的唯一法则 !
1 单机MySQL的时代 !
早期的网站访问量不大, 单个数据库基本够用 .
这个时候网站的瓶颈是什么?
- 数据量如果太大, 一个机器放不下 !
- 数据的索引 300万 就一定要建立索引了. (B+ tree)
- 访问量(读写混合) , 一个服务器承受不了~
2 Memcached(缓存) + MySQL + 垂直拆分(读写分离)
网站80%的情况都是在读 , 每次都要去查询数据库的话就十分的麻烦 , 所以我们希望减轻数据的压力 , 我们可以使用缓存来保证效率 !
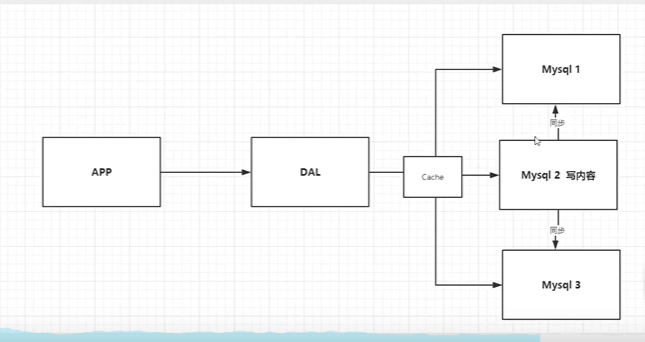
发展过程 : 优化数据结构和索引 --> 文件缓存(IO) --> Memcached(当时最热门的技术!)
3 分库分表 + 水平拆分 + MySQL集群
技术和业务在发展的同时对人的要求也越来越高了!
本质上 数据库就是读和写两种操作
早些年我们使用的MylSAM , 使用的表锁 , 十分影响效率 , 在高并发下就会出现严重的锁问题
随后我们就转换了InnoDB , 开始使用行锁 .
慢慢的我们就开始使用分库分表来解决写的压力 .
MySQL在那个年代推出了表分区 ,但是在这个技术并没有使用表分区 ,还有就是MySQL的集群
很好的解决了那个年代的需求
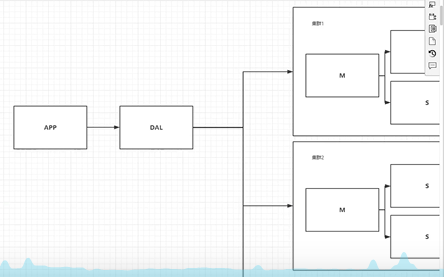
MySQL等关系型数据库就不够用了,数据量开始剧烈增长,变化也变得越来越快
MySQL有的使用它来存储一些比较大的文件博客图片 数据库表很大 效率就很低 如果有一种数据库来专门处理这种数据 那么MySQL的压力就会变得十分小 , 这个时候我们就可以研究如何处理这些问题
在大数据的IO压力下,表几乎没办法更改 如果有一亿条数据 表几乎没办法更大
灰度发布
什么是NoSQL?
nosql=Not only sql 不仅仅是sql
泛指非关系型数据库 , 随着web2.0互联网的诞生 , 传统的关系型数据库很难对付web2.0时代 . 尤其是超大规模的高并发的社区
nosql在当今的大数据环境下发展的什么迅速,redis是发展最快的
redis的特点
- 方便拓展(数据之间没有关系 , 很好扩展)
- 大数据量高性能(redis一秒写8万次 读取11万次)
- 数据烈性是多样性的 ! 不需要事先设计数据库 随取随用 如果是数据量十分大的表 很多人就无法设计了
- 传统的RDBMS和nosql
传统的RDBMS
- 结构化组织
- SQL
- 数据和关系都存在单独的表中
- 操作 数据定义语言
- 严格的一致性
- 基础的事务
nosql
- 不仅仅是数据
- 没有固定的查询语言
- 键值对存储 列存储 文档存储 图形数据库(社交关系)
- 最终一致性
- cap定力和base(异地多活)
- 高性能 高可用 高可扩
了解大数据的3V+3高
- 海量volume
- 多样varlety
- 实时velocity
三高:
- 高并发
- 高可扩
- 高性能
redis命令
DBSIZE 查看当前数据库
flushdb 清空当前数据库
flushall 清空所有数据库
keys * 查看当前数据库所有的key
redis是单线程的
redis是很快的,官方表示 redis是基于内存操作的 cpu不是redis的性能瓶颈 redis的瓶颈是根据机器的内存和网络带宽 既然可以使用单线程来实现,就使用单线程了
redis是c语言写的 官方提供的数据为100000+的qps 完全不比同样使用key-value的Memecache差
2 Redis概述与安装
- redis是一个开源的key-value存储系统
- 和memcached类似,它支持存储的value类型相对更多,包括string,list(链表),set(集合),zset(sorted set 有序集合)和hash(哈希类型)
- 这些数据类型都支持push/pop,add/remove及取交集并集差集以及其他更丰富的操作而且这些操作都是原子性的
- 在此基础上,redis支持各种不同方式的排序
- 和memcached一样 为了保证效率,数据都是缓存在内存里面的
- 区别是Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件.
2.1 应用场景
2.1.1 配合关系型数据库做高速缓存
- 高频次,热门访问的数据,降低数据库的IO
- 分布式架构,做session共享
2.1.2 多样的数据结构存储持久化数据
![image]()
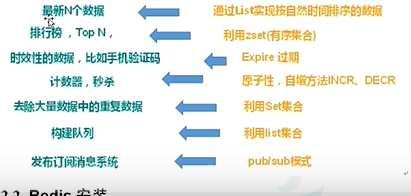
2.2 如何将redis注册成Windows服务
将目录切换到redis安装目录下之后输入命令
注册服务 redis-server --service-install redis.windows.conf
删除服务 redis-server --service-uninstall
开启服务 redis-server --service-start
停止服务 redis-server --service-stop
redis-server : redis服务启动器
redis-cli : redis客户端访问
ps -ef | grep redis 查看redis启动状态
redis-cli shutdown 关闭redis
2.3 redis相关知识
端口号 6379
默认16个数据库 下标从0开始 默认使用0数据库
统一密码管理 所有的库的密码都是相同的
DBSIZE 查看当前数据库的key的数量
flushdb 清空当前数据库
flushall 清空所有库
串行操作 一个一个来
多线程+锁 memached 不支持持久化
单线程+多路IO复用 redis 支持持久化
总结:与Memached的三点不同:支持多种数据类型,支持持久化,单线程+多路IO复用
2.4 五大常用数据类型
- string 字符串
- list 列表
- set 集合
- hash 哈希
- zset 有序集合
key操作
keys * 查看当前库所有key

 浙公网安备 33010602011771号
浙公网安备 33010602011771号