

[NLP]LSTM理解
简介
LSTM(Long short-term memory,长短期记忆)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失问题。以下先从RNN介绍。
简说RNN
RNN(Recurrent Neural Network,循环神经网络)是一种处理序列数据的神经网络。下图是它的结构:
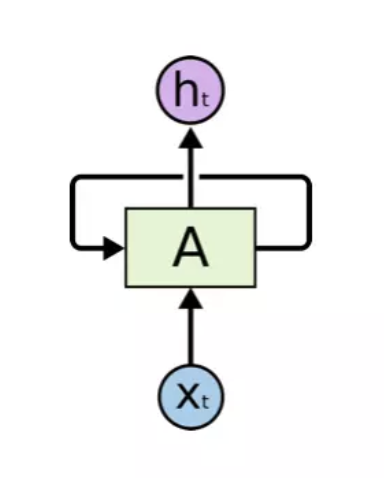
从上图可以看出,RNN循环获取输入序列,并保存上一次输入的计算结果,与当前输入进行计算后,将计算结果输出并保存当前的计算结果,这样不断循环输入并计算,即可获取上文信息。
RNN内部网络如下图所示,从图中可以看出,在神经元内部的计算过程:先将上一个神经元细胞的输出ht-1与当前状态下神经元细胞的输入xt拼接后进行tan计算。
注:输出的ht-1(下图中的紫色圆圈)通常是将ht-1输入到一个线性层(主要是进行维度映射),然后使用softmax进行分类得到需要的数据。具体的计算方式要看模型的使用方式。
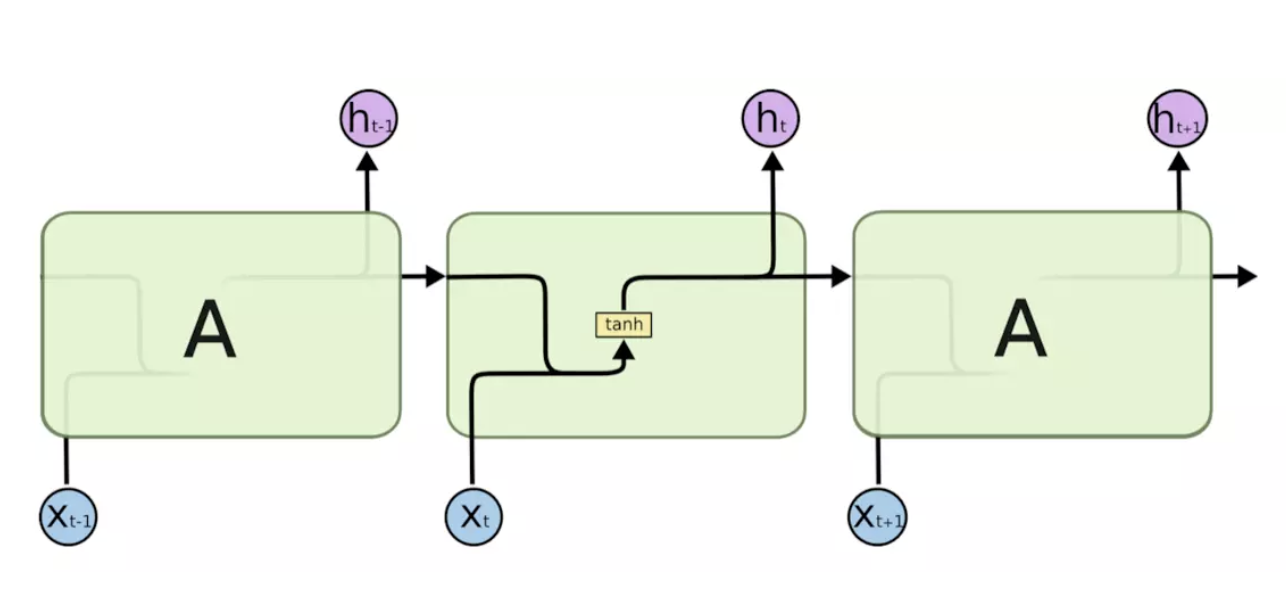
RNN优点:它能处理序列数据,并且有记忆能力,能够利用上文信息。
RNN缺点:
- 梯度消失:对于获取长距离依赖的效果不是很好(即如果上文信息离当前输入距离太远的话,理论上它是能够记得上文信息,但是事实上并不是这样,所以它并不能很好地处理长距离依赖问题)
- 梯度爆炸
- RNN较难训练
解决方法:lstm可以解决梯度消失问题;梯度爆炸问题需要使用梯度裁剪来做(比如,可以设置梯度范围为[-0.5,0.5]之间,如果梯度值为1.8,可以取其四分之一变为0.425即符合要求,我们知道梯度是一个多维空间中的向量,如果将梯度的长度进行裁剪并不会改变其方向,因此梯度仍然是会按照函数下降的方向前行,最终依然会达到控制loss的目的)
注:长距离依赖处理效果不佳的原因是使用tanh或者relu作为激活函数。(如果是sigmoid函数则不会)
LSTM结构
LSTM也是一种RNN,因此它也是一种循环结构,不同的是RNN神经元内部只用tan层进行计算,而LSTM是有4个全连接层进行计算的,LSTM的内部结构如下图所示。 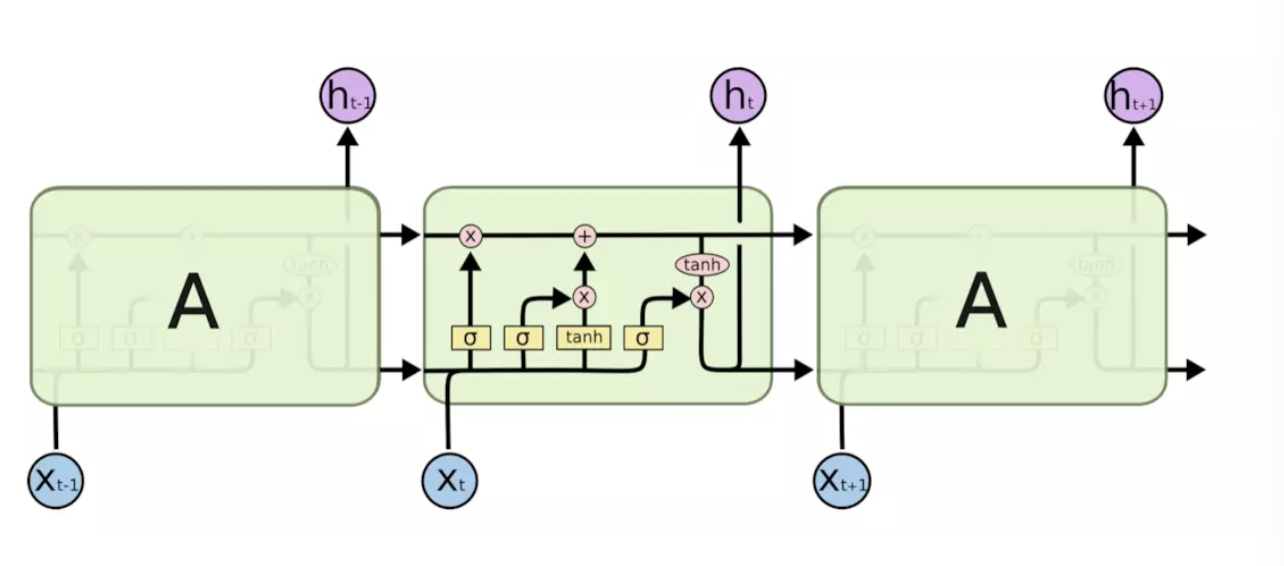
上图中符号的含义如下图所示,黄色方框类似于CNN中的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,下图中第四个符号表示两个向量的连接操作,第五个符号表示向量的拷贝操作,且上图中的σ表示sigmoid层(该层的输出时0-1的值,0表示不能通过,1表示能通过)。

现在来描述LSTM的内部操作,具体内容如下图所示:

LSTM的核心是细胞状态——最上层的横穿整个细胞的水平线,它通过门来控制信息的增加或者删除。
那么什么是门呢?门是一种用来选择信息通过与否的方式,它由一个sigmoid层和点乘操作组成。LSTM共有三个门,分别是遗忘门,输入门和输出门,具体内容如下所述:
(1)遗忘门:遗忘门决定丢弃哪些信息,输入是上一个神经元细胞的计算结果ht-1以及当前的输入向量xt,二者联接并通过遗忘门后(sigmoid会决定哪些信息留下,哪些信息丢弃),会生成一个0-1向量Γft(维度与上一个神经元细胞的输出向量Ct-1相同),Γft与Ct-1进行点乘操作后,就会获取上一个神经元细胞经过计算后保留的信息。
(2)输入门:表示要保存的信息或者待更新的信息,如上图所示是ht-1与xt的连接向量,经过sigmoid层后得到的结果Γit,这就是输入门的输出结果了。
但是接下来我们要计算该神经元细胞的输出结果,即新细胞的更新状态:Ct,Ct = Ct-1· Γft + Γit · ~ct(其中~ct = tanh(ht-1,xt)),文字描述是:输入门的计算结果点乘 ht-1与xt的连接向量经过tanh层计算的结果后,再与上一个神经元细胞经过计算后保留的信息进行相加,则是最终要输出的Ct。
(3)输出门:输出门决定当前神经原细胞输出的隐向量ht,ht与Ct不同,ht要稍微复杂一点,它是Ct进过tanh计算后与输出门的计算结果进行点乘操作后的结果,用公式描述是:ht = tanh(ct) · Γot
LSTM具体实现步骤[5]
1、首先,输入上一个神经元细胞输出的隐藏层向量和当前神经元细胞的输入,并将其连接起来。
2、将步骤1中的结果传入遗忘门中,该层将删除不相关的信息。
4、一个备选层将用步骤1中的结果创建,这一层将保存可能的会加入细胞状态的值或者说信息。
3、将步骤1中的结果传入输入门中,这一层决定步骤4的备选层中哪些信息应该加入到细胞状态中去。
5、步骤2、3、4计算结束后,用这三个步骤计算后的向量和上一个神经元细胞传出的细胞状态向量来更新当前细胞的细胞状态。
6、结果就被计算完了。
7、将结果和新的细胞状态进行点乘则是当前细胞状态的隐向量。
LSTM如何避免梯度消失与梯度爆炸
RNN中的梯度消失/爆炸与CNN中的含义不同,CNN中不同的层有不同的参数,每个参数都有自己的梯度;而RNN中同样的权重在各个时间步中共享,所以最终的梯度等于各个时间步的梯度和。因此,RNN中的梯度不会消失,它只会遗忘远距离的依赖关系,而被近距离的梯度所主导。但是LSTM中的梯度传播有很多条路径,最主要的一条是当前细胞的状态更新这一过程,该过程中只有逐元素的相乘和相加操作,梯度流最稳定,因此基本不会发生梯度消失或者梯度爆炸;但是其他的传播路径依然有梯度消失或者爆炸风险,而最终的梯度计算是各个梯度路径的和,因此LSTM仍然有梯度消失或者爆炸的风险,只是这个风险被大幅降低了。
LSTM变种-GRU
GRU是LSTM的变种,它也是一种RNN,因此是循环结构,相比LSTM而言,它的计算要简单一些,计算量也降低,但是二者的效果却不能一概而论,需要针对不同的case进行尝试才能知道哪一个模型效果更好。GRU使用隐向量进行信息交换(LSTM使用细胞状态),它有2个门:重置门和更新门。
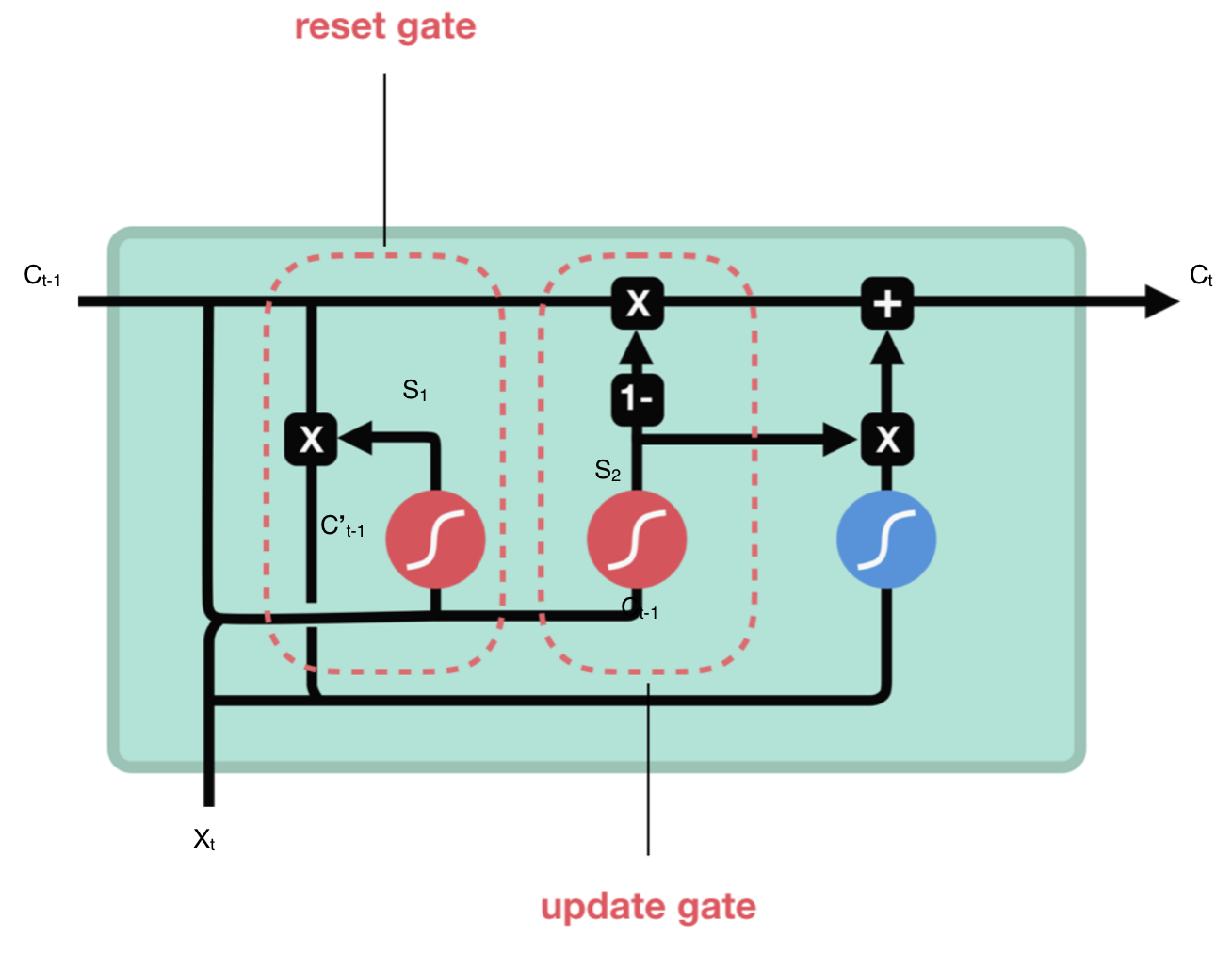
如上图所示,现分别介绍两个门:
- 重置门:用来决定需要丢弃哪些上一个神经元细胞的信息,它的计算过程是将Ct-1与当前输入向量xt进行连接后,输入sigmoid层进行计算,结果为S1,再将S1与Ct-1进行点乘计算,则结果为保存的上个神经元细胞信息,用C’t-1表示。
公式表示为:C’t-1 = Ct-1 · S1,S1 = sigmoid(concat(Ct-1,Xt))
- 更新门:更新门类似于LSTM的遗忘门和输入门,它决定哪些信息会丢弃,以及哪些新信息会增加。
总结
LSTM优点:LSTM降低了梯度消失或者梯度爆炸的风险,并且比RNN具有更强的长距离依赖能力。
LSTM缺点:
- LSTM处理长距离依赖的能力依然不够,因此Transformer横空出世,它具有比LSTM更强的长距离依赖处理能力。
- 它的计算很费时。每个细胞中都有4个全连接层(MLP),因此如果LSTM的时间跨度很大的话,计算量会很大也很费时。
注:LSTM+CRF做ner时,LSTM 只能通过输入判断输出,但是 CRF 可以通过学习转移矩阵,看前后的输出来判断当前的输出。这样就能学到一些规律(比如“O 后面不能直接接 I”“B-brand 后面不可能接 I-color”),这些规律在有时会起到至关重要的作用
参考资料
[1] https://zhuanlan.zhihu.com/p/32085405
[2] https://www.jianshu.com/p/95d5c461924c
[3] https://www.zhihu.com/question/34878706
[4] https://r2rt.com/written-memories-understanding-deriving-and-extending-the-lstm.html(待学习)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号