

[NLP]Transformer模型解析
简介[2]
Attention Is All You Need是2017年google提出来的一篇论文,论文里提出了一个新的模型,叫Transformer,这个结构广泛应用于NLP各大领域,是目前比较流行的模型。该模型没有选择大热的RNN/LSTM/GRU的结构,而是只使用attention layer和全连接层就达到了较好的效果,同时解决了RNN/LSTM/GRU中的long dependency problem,以及传统RNN训练并行度以及计算复杂度高的问题。缺点是输入固定长度的序列,需要对原始文本进行裁剪和填充,导致不能学习到序列中更长距离的依赖关系。
Transformer总体结构[1]
Transformer采用Encoder-Decoder架构。
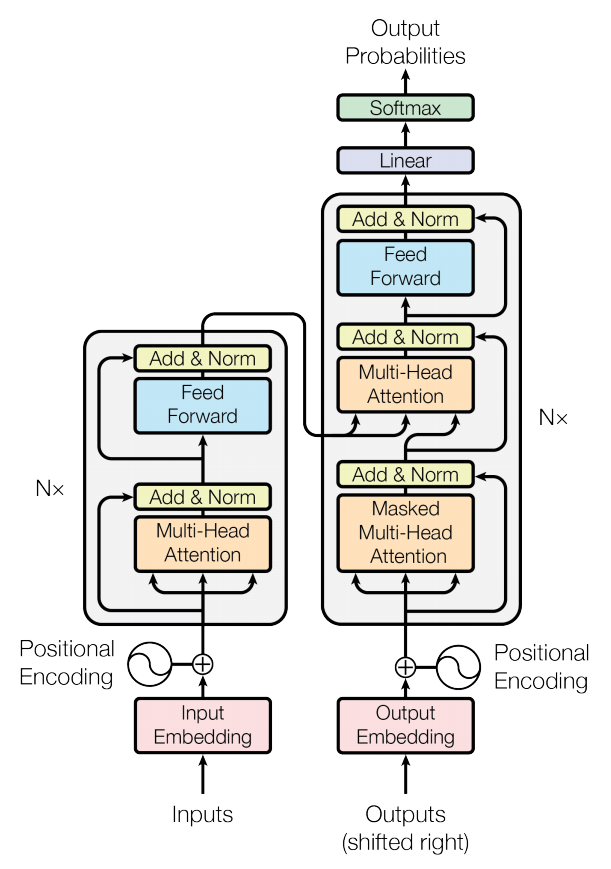
上图就是论文中提出的Transformer结构。其中左半部分是encoder右半部分是decoder.
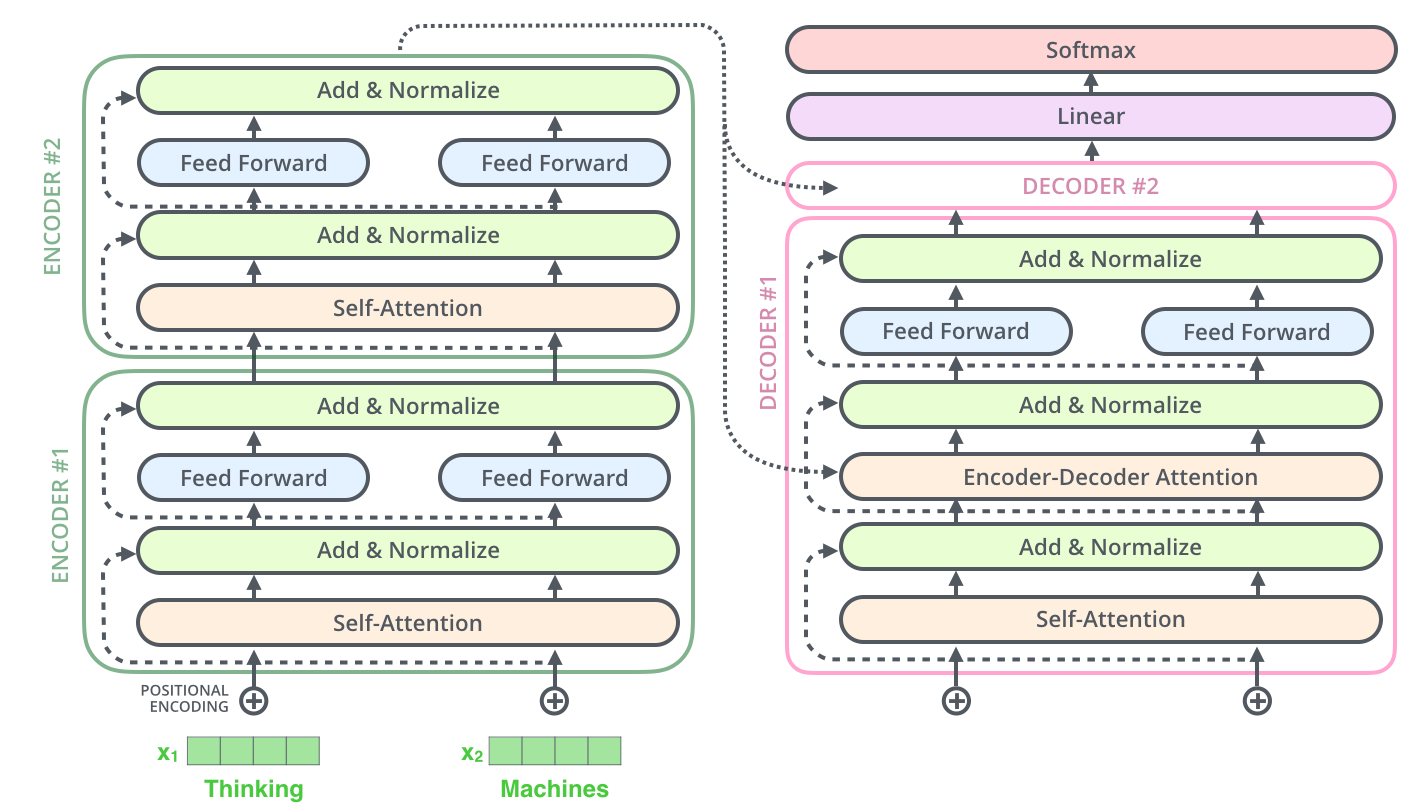
Encoder层中有6个一模一样的层结构,每个层结构包含了两个子层,第一个子层是多头注意力层(Multi-Head Attention,橙色部分),第二个子层是前馈连接层(Feed Forward,浅蓝色部分)。除此之外,还有一个残差连接,直接将input embedding传给第一个Add & Norm层(黄色部分)以及 第一个Add & Norm层传给第二个Add & Norm层(即图中的粉色-黄色1,黄色1-黄色2部分运用了残差连接)。该层的重点-注意力层会在下文中进行解释。
Decoder层中也有6个一模一样的层结构,但是比Endoer层稍微复杂一点,它有三个子层结构,第一个子层结构是遮掩多头注意力层(Masked Multi-Head Attention,橙色部分),第二个子层是多头注意力结构(Multi-Head Attenion,橙色部分),第三个子层是前馈连接层(Feed Forward,浅蓝色部分)。
注1:这一部分的残差连接是粉色-黄色1,黄色1-黄色2,黄色2-黄色3三个部分
注2:该层的重点是第二个子层,即多头注意力层,它的输入包括两个部分,第一个部分是第一个子层的输出,第二个部分是Encoder层的输出(这是与encoder层的区别之一),这样则将encoder层和decoder层串联起来,以进行词与词之间的信息交换,这里信息交换是通过共享权重WQ,WV,WK得到的。
注3:第一个子层中的mask,它的作用就是防止在训练的时候使用未来的输出的单词。比如训练时,第一个单词是不能参考第二个单词的生成结果的,此时就会将第二个单词及其之后的单词都mask掉。总体来讲,mask的作用就是用来保证预测位置i的信息只能基于比i小的输出。因此,encoder层可以并行计算,一次全部encoding出来,但是decoder层却一定要像rnn一样一个一个解出来,因为要用上一个位置的输入当做attention的query.
注4:残差结构是为了解决梯度消失问题,可以增加模型的复杂性。残差结构:x+F(x),这样会进一步扩大方差,因此需要增加一个norm层来缩小方差。
注5:LayerNorm层是为了对attention层的输出进行分布归一化,转换成均值为0方差为1的正态分布。cv中经常会用的是batchNorm,是对一个batchsize中的样本进行一次归一化,而layernorm则是对一层进行一次归一化,二者的作用是一样的,只是针对的维度不同,一般来说输入维度是(batch_size,seq_len,embedding),batchnorm针对的是batch_size层进行处理,而layernorm则是对seq_len进行处理(即batchnorm是对一批样本中进行归一化,而layernorm是对每一个样本进行一次归一化)。
注6:使用ln而不是bn的原因是因为输入序列的长度问题,每一个序列的长度不同,虽然会经过padding处理,但是padding的0值其实是无用信息,实际上有用的信息还是序列信息,而不同序列的长度不同,所以这里不能使用bn一概而论。
注7:FFN是两层全连接:w * [delta(w * x + b)] + b,其中的delta是relu激活函数。这里使用FFN层的原因是:为了使用非线性函数来拟合数据。如果说只是为了非线性拟合的话,其实只用到第一层就可以了,但是这里为什么要用两层全连接呢,是因为第一层的全连接层计算后,其维度是(batch_size,seq_len,dff)(其中dff是超参数的一种,设置为2048),而使用第二层全连接层是为了进行维度变换,将dff转换为初始的d_model(512)维。
注8:decoder层中中间的多头自注意力机制的输入是两个参数——encoder层的输出和decoder层中第一层masked多头自注意力机制的输出,作用在本层时是:q=decoder的输出,k=v=encoder的输出。
注9:encoder的输入包含两个,是一个序列的token embedding + positional embedding,用正余弦函数对序列中的位置进行计算(偶数位置用正弦,奇数位置用余弦)
Self-Attention[2]
self-Attention是Transformer用来找到并重点关注与当前单词相关的词语的一种方法。如下述例子:
The animal didn’t cross the street because it was too tired.
这里的it究竟是指animal还是street,对于算法来说是不容易判断的,但是self-attention是能够把it和animal联系起来的,达到消歧的目的。
这里描述self-attention的具体过程如下图所示:
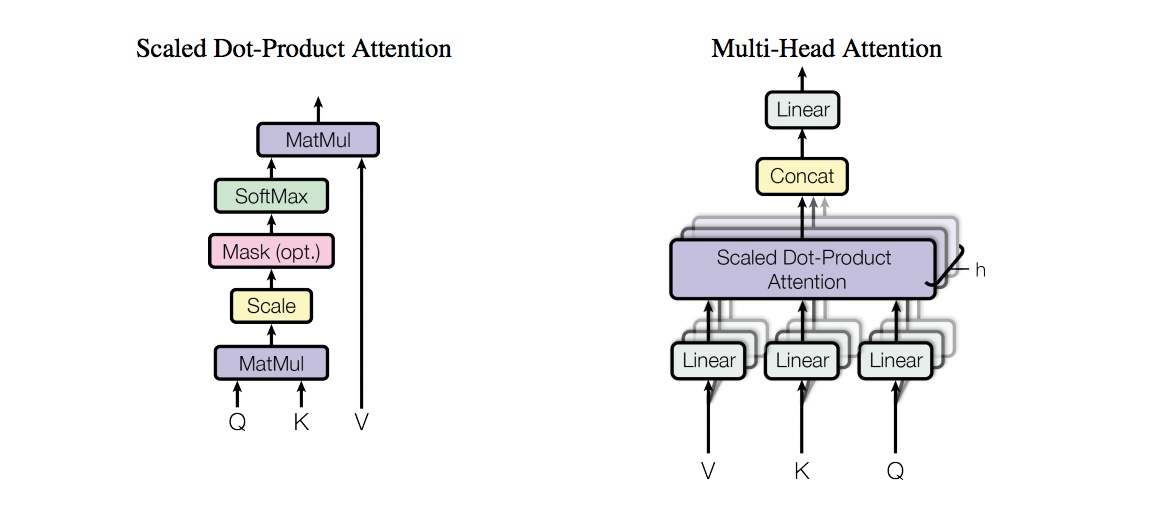
从上图可以看出,attention机制中主要涉及三个向量Q(Query),K(Key),V(Value),这三个向量的计算过程如下图所示:
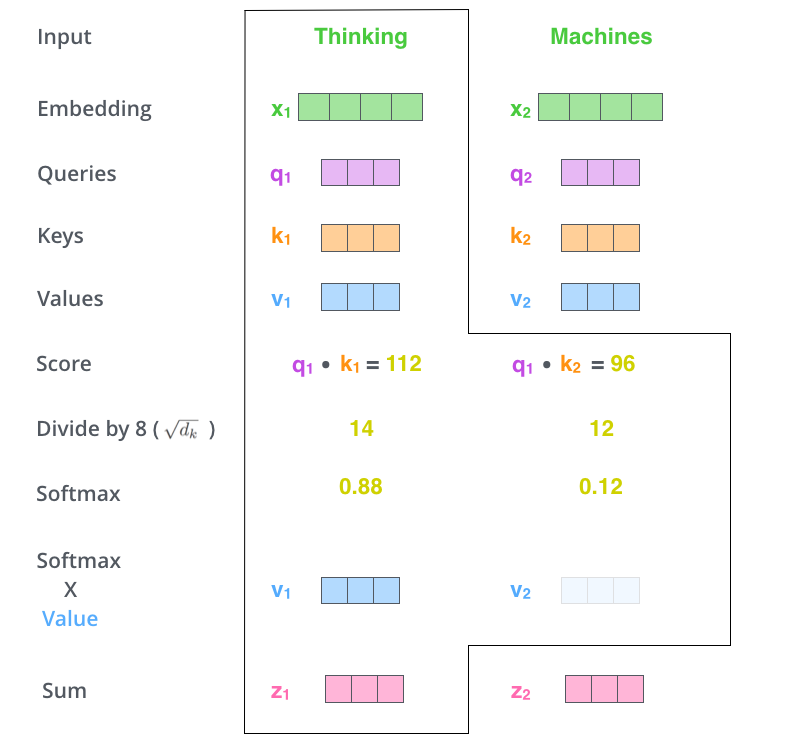
上图中,WQ,WV,WK是三个随机初始化的矩阵,每个特征词的向量计算公式如下所示:
Queries: q1 = x1 · WQ q2 = x2 · WQ
Keys: k1 = x1 · WK k2 = x2 · WK
Values: v1 = x1 · WV v2 = x2 · WV
Score: s1 = q1 · k1=112 s2 = q2 · k2 = 96
Divide by 8: d1 = s1 / 8 = 14 d2 = s2 / 8 = 12
Softmax: sm1 = e14/ (e14 + e12) = 0.88 sm2 = e12 / (e14 + e12) = 0.12
Softmax * value: v1 = sm1 * v1 v2 = sm2 * v2
注1:score表示关注单词的相关程度.
注2:这种通过 query 和 key 的相似性程度来确定 value 的权重分布的方法被称为scaled dot-product attention。
注3:attention与self-attention的区别[5]:self-attention是一般attention的特殊情况,在self-attention中,Q=K=V每个序列中的单元和该序列中所有单元进行attention计算。Google提出的多头attention通过计算多次来捕获不同子控件上的相关信息。self-attention的特点在于无视词之间的距离直接计算依赖关系,能够学习一个句子的内部结构,实现也较为简单并且可以并行计算。从一些论文中看到,self-attention可以当成一个层和RNN,CNN,FNN等配合使用,成功应用于其他NLP任务。
注4:attention中除以根号d_k具备缩放的原因是因为原始表征x1是符合均值为0方差为1的正态分布的,而q*k后方差变为d,所以为了使结果符合均值为0方差为1的数据分布,这里需要除以根号d,这样数据分布并未改变,q*k经过softmax层后不会变成one hot而出现梯度消失的情况。(e^d可能非常大而e^(-d)非常小,这样经过softmax层后,attention层的分布会非常接近one hot分布,这样会带来严重的梯度消失问题,导致训练效果非常差。)
注意力机制的优点:
①一步到位获取全局与局部的关系,不会像RNN那样对长期依赖的捕捉会受到序列长度的限制。
②每步的结果不依赖于上一步,可以做成并行的模式
③相比CNN与RNN,参数少,模型复杂度低。
注意力机制的缺点:
①没法捕捉位置信息,即没法学习序列中的顺序关系。这点可以通过加入位置信息,如通过位置向量来改善,具体如bert模型。
Multi-Headed Attention
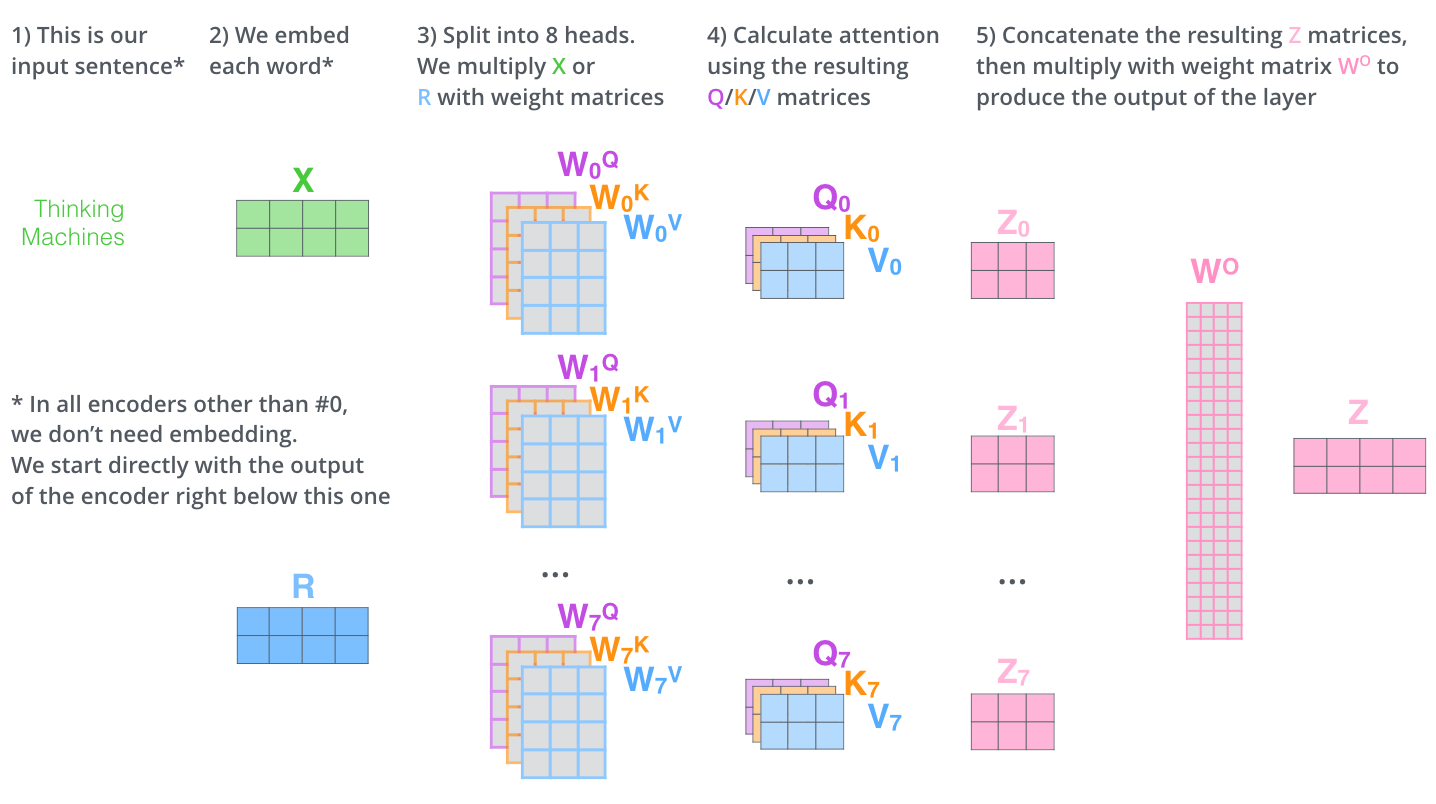
多头注意力机制是指有多组Q,K,V矩阵,一组Q,K,V矩阵代表一次注意力机制的运算,transformer使用了8组,所以最终得到了8个矩阵,将这8个矩阵拼接起来后再乘以一个参数矩阵WO,即可得出最终的多注意力层的输出。全部过程如下图所示:

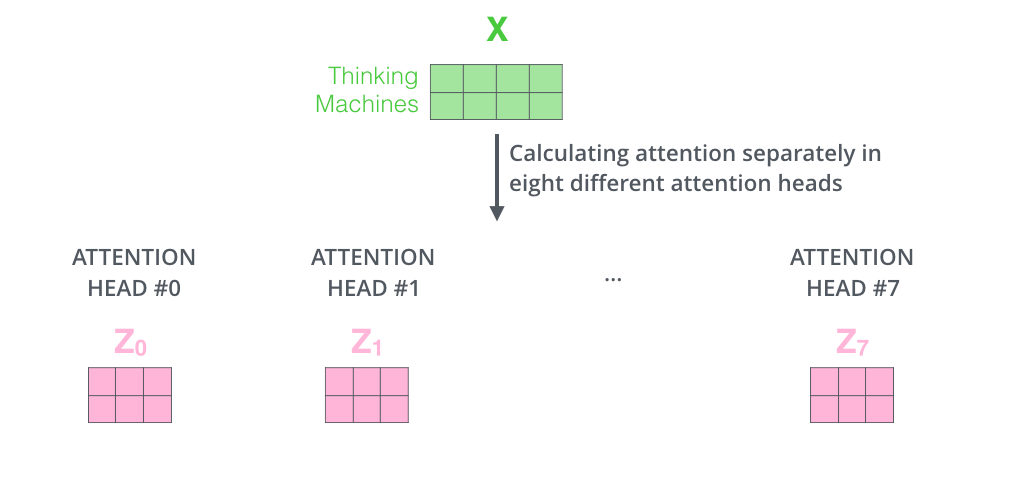
左图表示使用多组Q,K,V矩阵,右图表示8组Q,K,V矩阵计算会得出8个矩阵,最终我们还需将8个矩阵经过计算后输出为1个矩阵,才能作为最终多注意力层的输出。如下图所示,其中WO是随机初始化的参数矩阵。
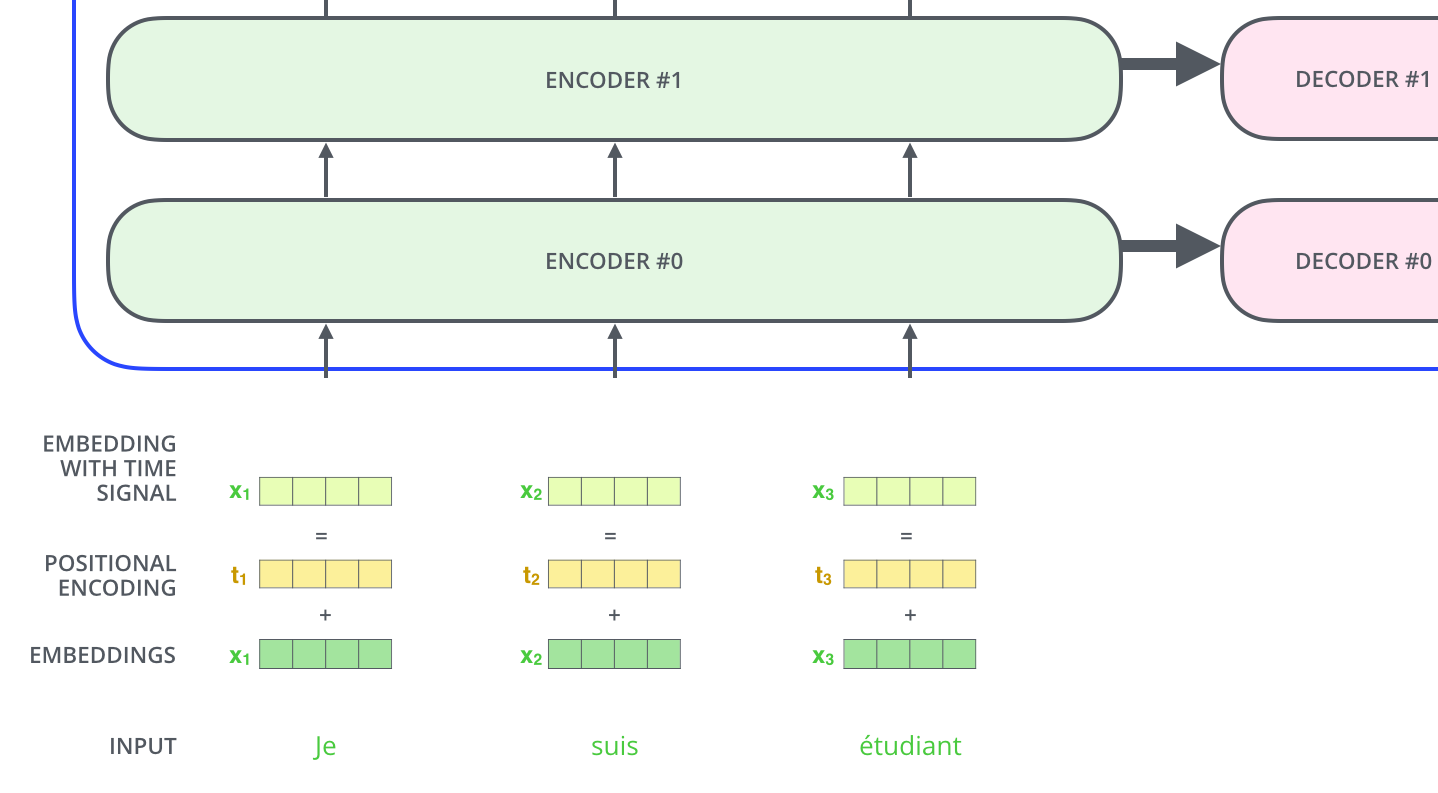
Positional Encoding
在图figure 1中,还有一个向量positional encoding,它是为了解释输入序列中单词顺序而存在的,维度和embedding的维度一致。这个向量决定了当前词的位置,或者说是在一个句子中不同的词之间的距离。论文中的计算方法如下:
PE(pos,2 * i) = sin(pos / 100002i/dmodel)
PE(pos,2 * i + 1) = cos(pos / 100002i/dmodel)
其中pos指当前词在句子中的位置,i是指向量中每个值的index,从公式中可以看出,句子中偶数位置的词用正弦编码,奇数位置的词用余弦编码。最后把positional encoding的值与embedding的值相加作为输入传进transformer结构中,如下图所示:
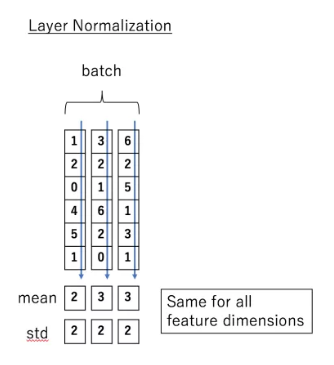
Layer normalization
在transformer中,每一个子层(自注意力层,全连接层)后都会有一个Layer normalization层,如下图所示:

Normalize层的目的就是对输入数据进行归一化,将其转化成均值为0方差为1的数据。LN是在每一个样本上都计算均值和方差,如下图所示:
LN的公式如下:
LN(xi) = α * (xi - μL / √(σ2L + ε)) + β
以上是encoder层的全部内容,最后再展示一下将两个encoder叠加在一起的内部图:
其他细节
1、Transformer中包含两种mask:padding mask 在所有的scaled dot-product attention 里面都需要用到,而sequence mask 只有在decoder的self-attention里面用到。
Padding Mask是为了解决填充0的无意义的位置而存在的,具体的说,因为要对输入序列进行对齐,当输入序列较短时,需要在输入序列后填充0,但是这些填充的数据没什么意义,attention机制不应该把注意力放在这些位置上,因此我们需要做一些统一的处理。具体的做法是把这些位置的值加上一个非常大的负数,这样经过softmax处理的话,这些位置的值就会接近0。
参考资料:
[1] https://www.jianshu.com/p/ef41302edeef?utm_source=oschina-app
[2] https://blog.csdn.net/u012526436/article/details/86295971
[3] https://zhuanlan.zhihu.com/p/47282410
[4] https://zhuanlan.zhihu.com/p/44121378
[5]https://www.cnblogs.com/robert-dlut/p/8638283.html
[6]https://zhuanlan.zhihu.com/p/57672079
[7] https://kexue.fm/archives/8620

 浙公网安备 33010602011771号
浙公网安备 33010602011771号