
作业四
作业①
要求:
熟练掌握 Selenium 查找 HTML 元素、爬取 Ajax 网页数据、等待 HTML 元素等内
容。
使用 Selenium 框架+ MySQL 数据库存储技术路线爬取“沪深 A 股”、“上证 A 股”、
“深证 A 股”3 个板块的股票数据信息。
一个板块爬了两页
根据html写XPath然后爬就行,要注意的是跳过tds[2]
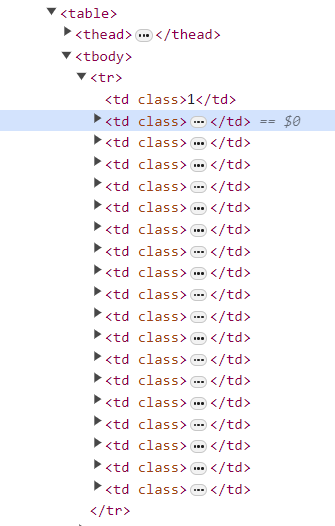
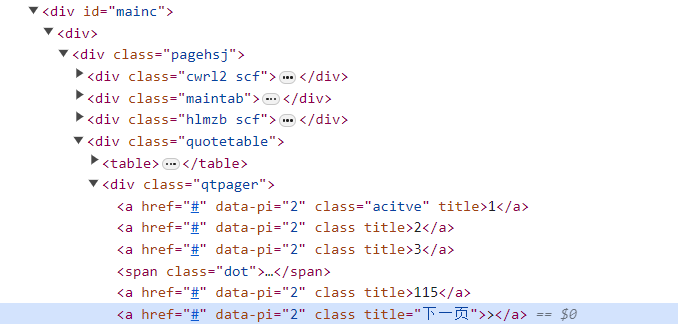

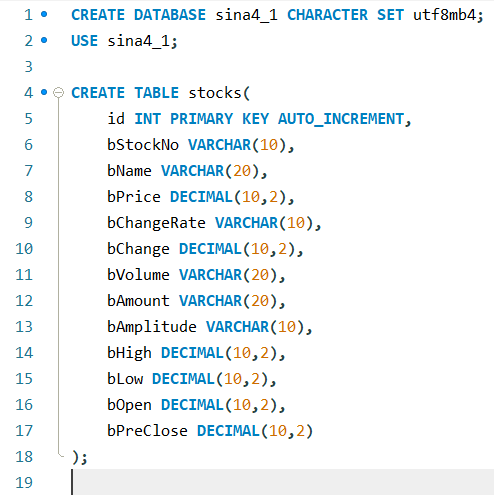
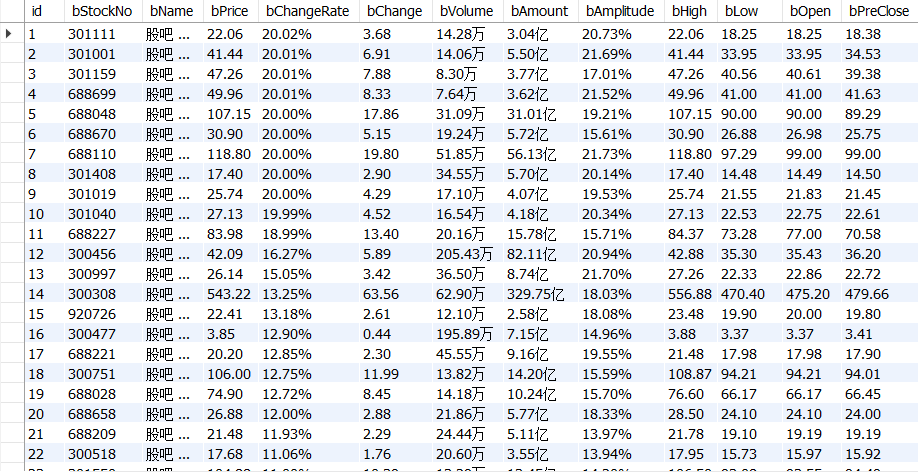
代码
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# MySQL 连接
db = pymysql.connect(
host="localhost",
user="root",
password="22qwer22",
database="sina4_1",
charset="utf8mb4"
)
cursor = db.cursor()
# 插入函数
def save(data):
sql = """
INSERT INTO stocks(
bStockNo, bName, bPrice, bChangeRate, bChange,
bVolume, bAmount, bAmplitude, bHigh, bLow, bOpen, bPreClose
) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)
"""
cursor.execute(sql, data)
db.commit()
# 抓取板块
def crawl_board(board_name, url):
print(f"\n>>> 正在抓取板块:{board_name}")
driver.get(url)
wait = WebDriverWait(driver, 15)
time.sleep(2)
for page in range(1, 3):
wait.until(EC.presence_of_element_located((By.XPATH, "//table//tbody/tr")))
rows = driver.find_elements(By.XPATH, "//table//tbody/tr")
for r in rows:
tds = r.find_elements(By.TAG_NAME, "td")
if len(tds) < 13:
continue
bStockNo = tds[1].text.strip()
bName = tds[3].text.strip()
bPrice = tds[4].text.strip()
bChangeRate = tds[5].text.strip()
bChange = tds[6].text.strip()
bVolume = tds[7].text.strip()
bAmount = tds[8].text.strip()
bAmplitude = tds[9].text.strip()
bHigh = tds[10].text.strip()
bLow = tds[11].text.strip()
bOpen = tds[12].text.strip()
bPreClose = tds[13].text.strip()
if not bStockNo.isdigit():
continue
data = (
bStockNo, bName, bPrice, bChangeRate, bChange,
bVolume, bAmount, bAmplitude, bHigh, bLow, bOpen, bPreClose
)
save(data)
# 用 XPath 翻页
if page < 2:
try:
next_btn = wait.until(
EC.element_to_be_clickable(
(By.XPATH, '//*[@id="mainc"]/div/div/div[4]/div/a[@title="下一页"]')
)
)
next_btn.click()
print(" > 翻页成功")
time.sleep(2)
except Exception as e:
print(" - 找不到下一页按钮,提前结束:", e)
break
print(f"{board_name} —— 抓取完成")
if __name__ == "__main__":
driver = webdriver.Chrome()
boards = {
"沪深A股": "https://quote.eastmoney.com/center/gridlist.html#hs_a_board",
"上证A股": "https://quote.eastmoney.com/center/gridlist.html#sh_a_board",
"深证A股": "https://quote.eastmoney.com/center/gridlist.html#sz_a_board",
}
for name, url in boards.items():
crawl_board(name, url)
driver.quit()
db.close()
print("\n全部板块爬取成功!")心得体会
XPath要从有id或者class属性的开始往下逐级找,不然很容易爬错
作业②
要求:
熟练掌握 Selenium 查找 HTML 元素、实现用户模拟登录、爬取 Ajax 网页数据、
等待 HTML 元素等内容。
使用 Selenium 框架+MySQL 爬取中国 mooc 网课程资源信息(课程号、课程名
称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)

代码
import json
import os
import time
import pymysql
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
COOKIE_FILE = "cookies.json"
# 加载 cookie
def load_cookies(driver):
if not os.path.exists(COOKIE_FILE):
print("cookies.json 不存在,请先生成 cookie!")
exit()
driver.get("https://www.icourse163.org/")
time.sleep(2)
with open(COOKIE_FILE, "r", encoding="utf-8") as f:
cookies = json.load(f)
for cookie in cookies:
cookie.pop("sameSite", None)
cookie.pop("expiry", None)
try:
driver.add_cookie(cookie)
except:
pass
driver.get("https://www.icourse163.org/")
time.sleep(2)
print("使用 cookie 登录成功!")
# 获取 text
def safe_text(driver, wait, xpath):
try:
return wait.until(EC.presence_of_element_located((By.XPATH, xpath))).text.strip()
except:
return ""
def safe_attr(driver, wait, xpath, attr):
try:
return wait.until(EC.presence_of_element_located((By.XPATH, xpath))).get_attribute(attr)
except:
return ""
# 课程爬取
def crawl_course(driver, wait, url, cursor, db):
print(f"\n正在爬取:{url}")
driver.get(url)
time.sleep(2)
cCourse = safe_text(driver, wait, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[2]/div[1]/span[1]")
cCollege = safe_attr(driver, wait, "/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/a/img", "alt")
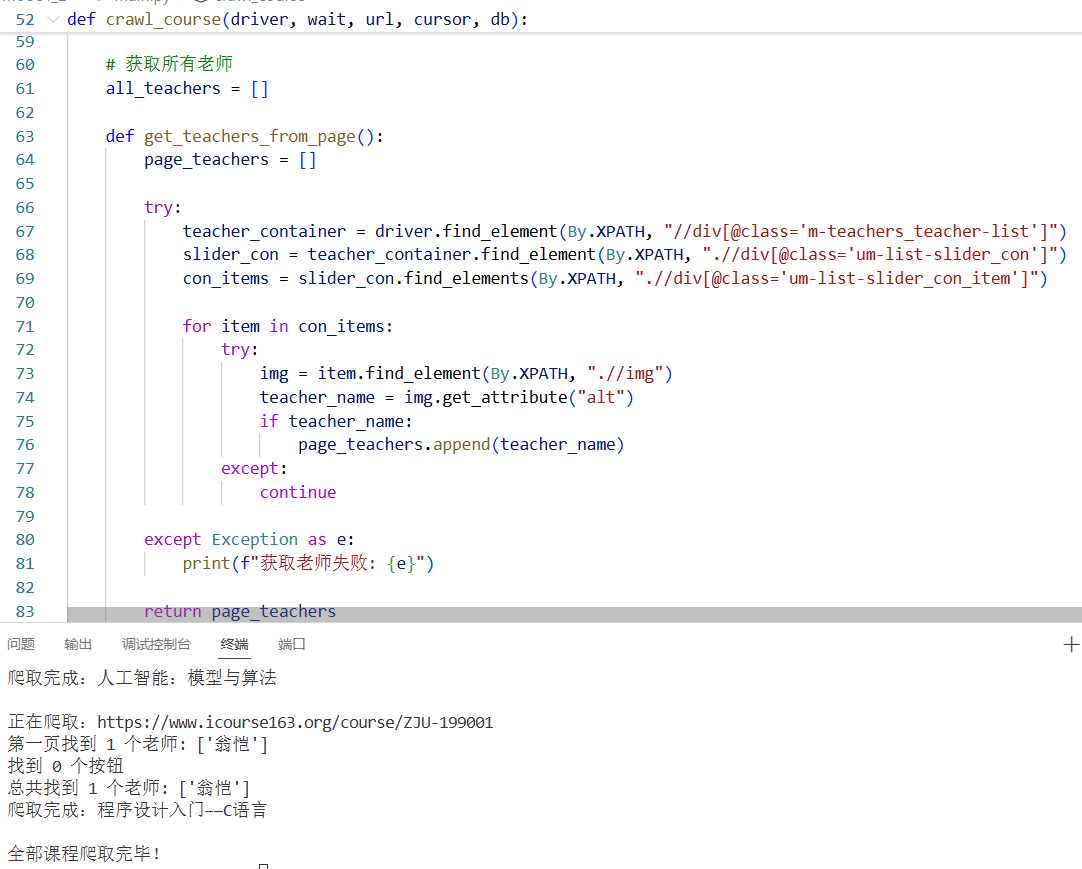
# 获取所有老师
all_teachers = []
def get_teachers_from_page():
page_teachers = []
try:
teacher_container = driver.find_element(By.XPATH, "//div[@class='m-teachers_teacher-list']")
slider_con = teacher_container.find_element(By.XPATH, ".//div[@class='um-list-slider_con']")
con_items = slider_con.find_elements(By.XPATH, ".//div[@class='um-list-slider_con_item']")
for item in con_items:
try:
img = item.find_element(By.XPATH, ".//img")
teacher_name = img.get_attribute("alt")
if teacher_name:
page_teachers.append(teacher_name)
except:
continue
except Exception as e:
print(f"获取老师失败: {e}")
return page_teachers
# 爬第一页
first_page_teachers = get_teachers_from_page()
all_teachers.extend(first_page_teachers)
print(f"第一页找到 {len(first_page_teachers)} 个老师: {first_page_teachers}")
# 检查是否有下一页按钮
try:
buttons = driver.find_elements(By.XPATH,
"/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div[1]/span"
)
print(f"找到 {len(buttons)} 个按钮")
# 如果有按钮(说明有下一页)
if buttons:
buttons[0].click()
time.sleep(2)
# 从第二页开始循环
while True:
page_teachers = get_teachers_from_page()
all_teachers.extend(page_teachers)
print(f"当前页找到 {len(page_teachers)} 个老师: {page_teachers}")
# 检查当前页按钮数量
buttons = driver.find_elements(By.XPATH,
"/html/body/div[5]/div[2]/div[2]/div[2]/div[2]/div[2]/div[2]/div/div/div[2]/div/div[1]/span"
)
# 如果有两个按钮,点击第二个(下一页)
if len(buttons) == 2:
buttons[1].click()
time.sleep(2)
# 如果只有一个按钮,说明是最后一页,结束循环
else:
break
except Exception as e:
print(f"翻页过程出错: {e}")
# 第一个老师作为cTeacher,所有老师作为cTeam
cTeacher = all_teachers[0] if all_teachers else ""
cTeam = ",".join(all_teachers)
print(f"总共找到 {len(all_teachers)} 个老师: {all_teachers}")
# 参加人数
try:
elem = wait.until(EC.presence_of_element_located((
By.XPATH, "/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[4]/span[2]"
)))
cCount = elem.text.strip()
except:
cCount = ""
# 进度
cProcess = safe_text(driver, wait,
"/html/body/div[5]/div[2]/div[1]/div/div/div/div[2]/div[2]/div/div[3]/div/div[1]/div[2]/div/span[2]"
)
# 简介
cBrief = safe_text(driver, wait,
"/html/body/div[5]/div[2]/div[2]/div[2]/div[1]/div[1]/div[2]/div[2]/div[1]"
)
cursor.execute("""
INSERT INTO course_info(url, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief)
VALUES (%s,%s,%s,%s,%s,%s,%s,%s)
""", (url, cCourse, cCollege, cTeacher, cTeam, cCount, cProcess, cBrief))
db.commit()
print(f"爬取完成:{cCourse}")
def main():
db = pymysql.connect(
host="localhost",
user="root",
password="22qwer22",
database="mooc",
charset="utf8mb4")
cursor = db.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS course_info(
id INT AUTO_INCREMENT PRIMARY KEY,
url VARCHAR(255),
cCourse VARCHAR(255),
cCollege VARCHAR(255),
cTeacher VARCHAR(255),
cTeam TEXT,
cCount VARCHAR(50),
cProcess VARCHAR(255),
cBrief TEXT
);
""")
db.commit()
# Selenium
options = webdriver.ChromeOptions()
options.add_experimental_option('excludeSwitches', ['enable-logging'])
driver = webdriver.Chrome(options=options)
wait = WebDriverWait(driver, 20)
# 使用 cookie 免登录
load_cookies(driver)
# 读取课程 url
with open("courses.txt", "r", encoding="utf-8") as f:
urls = [line.strip() for line in f if line.strip()]
for url in urls:
crawl_course(driver, wait, url, cursor, db)
driver.quit()
db.close()
print("\n全部课程爬取完毕!")
if __name__ == "__main__":
main()心得体会
爬老师的时候有按钮,XPath老弄错,纯脑抽了
作业③
要求:
掌握大数据相关服务,熟悉 Xshell 的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume 日志采集实验(部
分)v2.docx 中的任务,即为下面 5 个任务,具体操作见文档。
环境搭建:
任务一:开通 MapReduce 服务
实时分析开发实战:
任务一:Python 脚本生成测试数据
任务二:配置 Kafka
任务三: 安装 Flume 客户端
任务四:配置 Flume 采集数据
输出:实验关键步骤或结果截图。
开通MapReduce服务

安全组
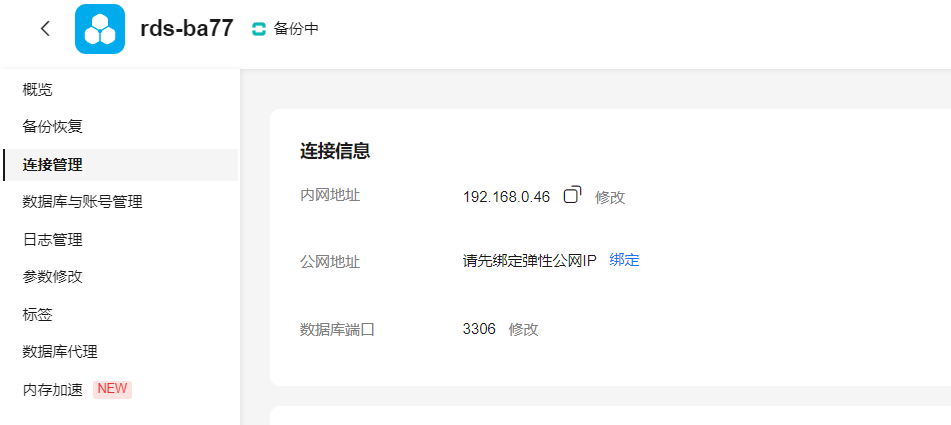
 开通云数据库服务RDS
开通云数据库服务RDS
开通数据湖探索服务(DLI)
资源池

配置跨源链接

开通数据可视化服务(DLV)
DLV
Python脚本生成测试数据
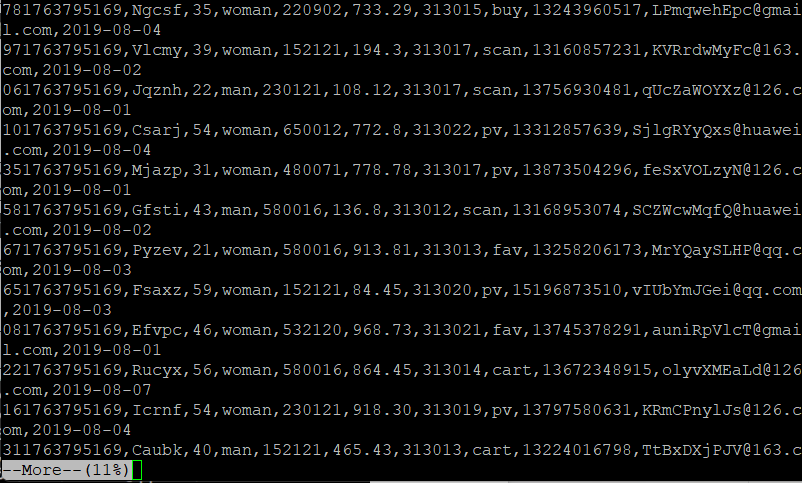
配置Kafka
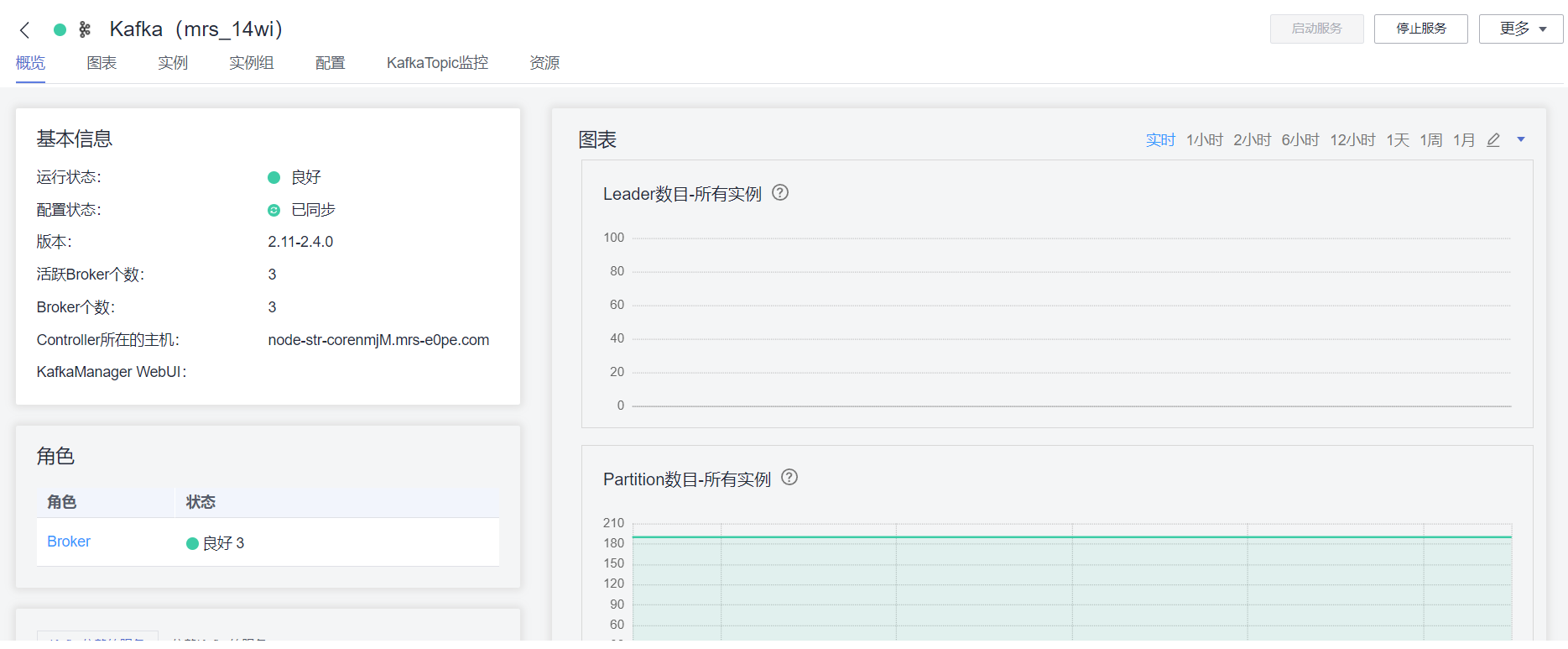
安装客户端
创建topic
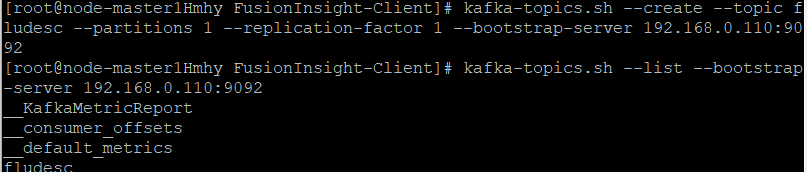
安装flume
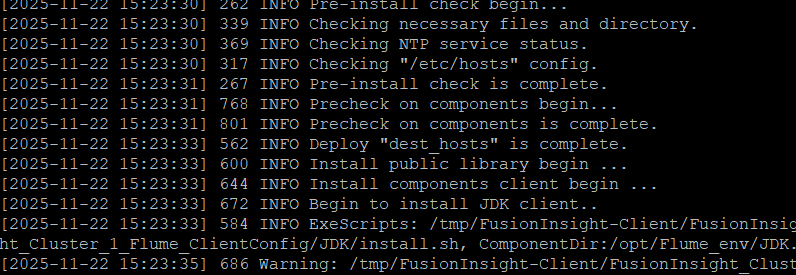
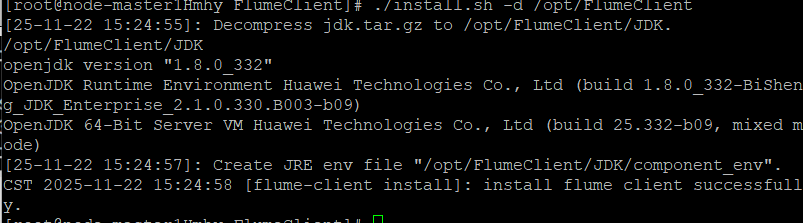
重启flume

配置Flume采集数据
创建数据,打通Flume到Kafka
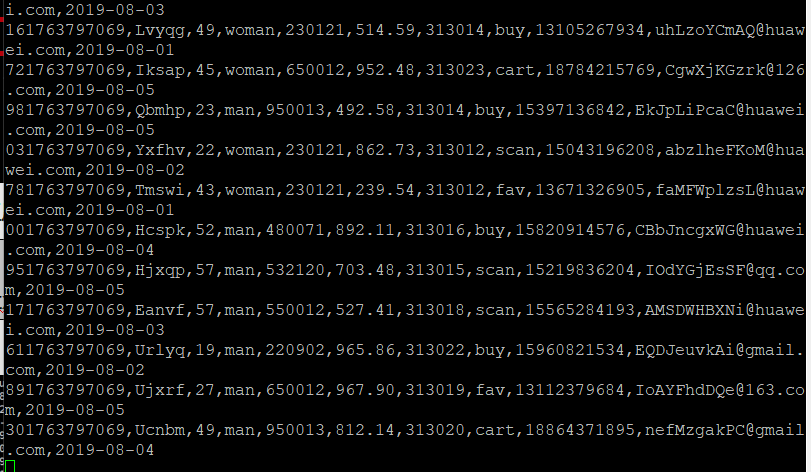
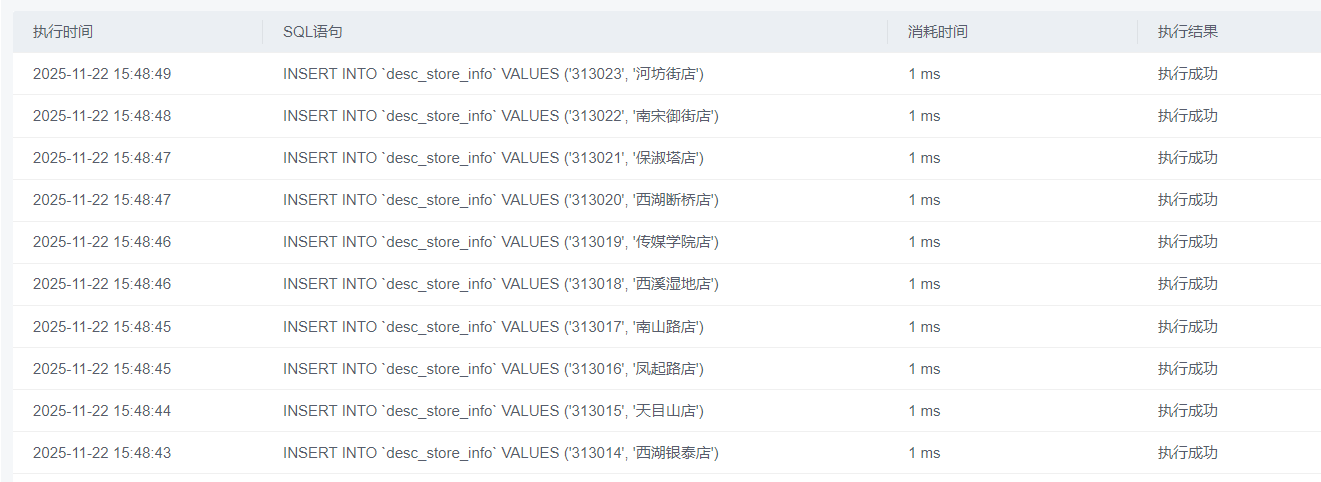
MySQL中准备结果表与维度表数据
Sql插入数据
使用DLI中的Flink作业进行数据分析
测试连通性
作业运行详情

验证数据分析
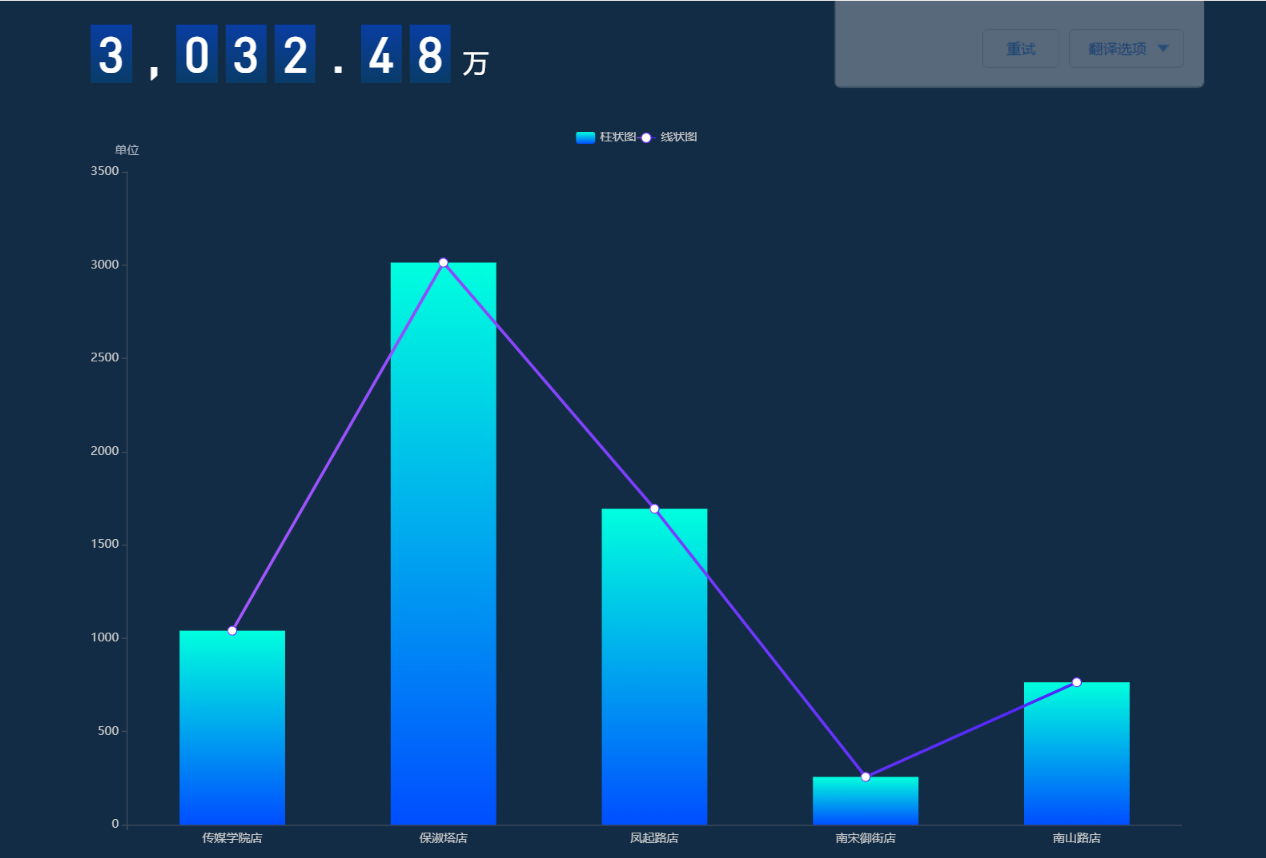
DLV数据可视化
创建大屏
展示实时交易总金额
心得体会
集群好贵要早点做完释放掉,不然就要被冻结账号了
首先要搭建环境,包括开通MRS、配置 Kafka、安装 Flume
然后实现可视化,重点就是打通各服务之间数据流通

 浙公网安备 33010602011771号
浙公网安备 33010602011771号