
作业三
作业①
要求:指定一个网站,爬取这个网站中的所有的所有图片。实现单线程和多线程的方式爬取。
import requests
import re
import os
from concurrent.futures import ThreadPoolExecutor, as_completed
url = "https://news.fzu.edu.cn/yxfd.htm"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64)"
}
response = requests.get(url, headers=headers)
response.encoding = "utf-8"
html = response.text
# 匹配所有图片
pattern = re.compile(r'src\s*=\s*["\']/?(__local/.*?\.(?:jpe?g|png))["\']', re.S)
results = re.findall(pattern, html)
# 拼接完整链接
base_url = "https://news.fzu.edu.cn/"
imgs = [base_url + img.lstrip("/") for img in results]
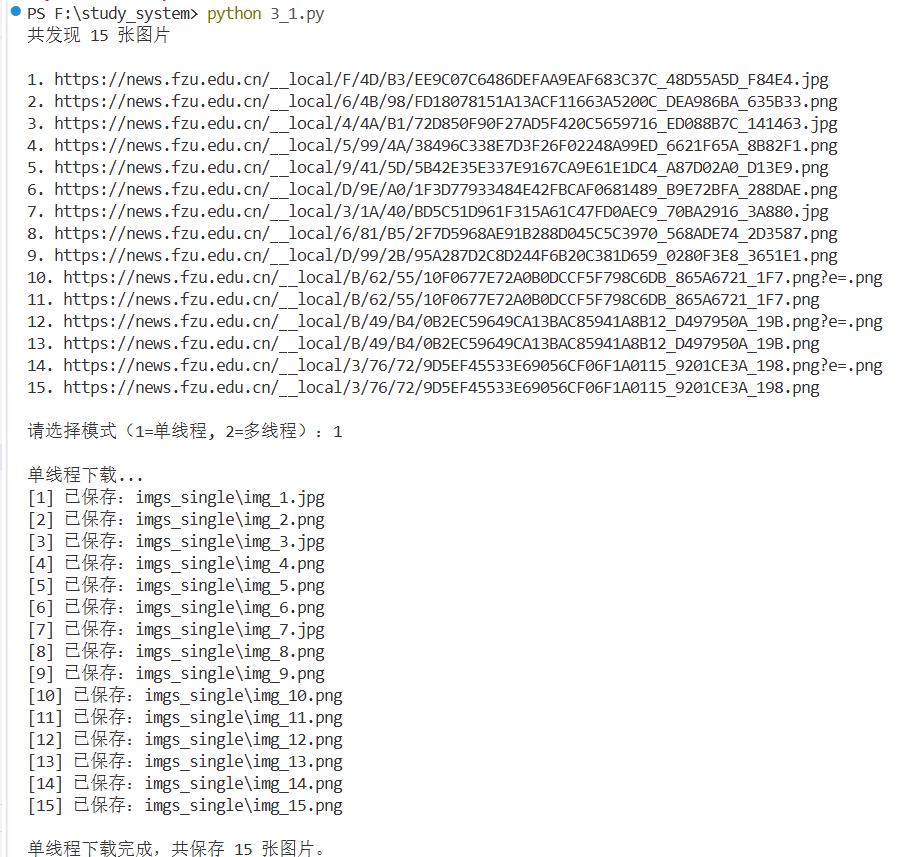
print(f"共发现 {len(imgs)} 张图片\n")
for i, j in enumerate(imgs, 1):
print(f"{i}. {j}")
# 下载图片函数
def download_image(index, img_url, save_dir):
ext = os.path.splitext(img_url)[1] or ".jpg"
filename = os.path.join(save_dir, f"img_{index}{ext}")
try:
img_data = requests.get(img_url, headers=headers, timeout=10).content
with open(filename, "wb") as f:
f.write(img_data)
return f"[{index}] 已保存:{filename}"
except Exception as e:
return f"[{index}] 下载失败:{img_url},原因:{e}"
# 下载模式选择
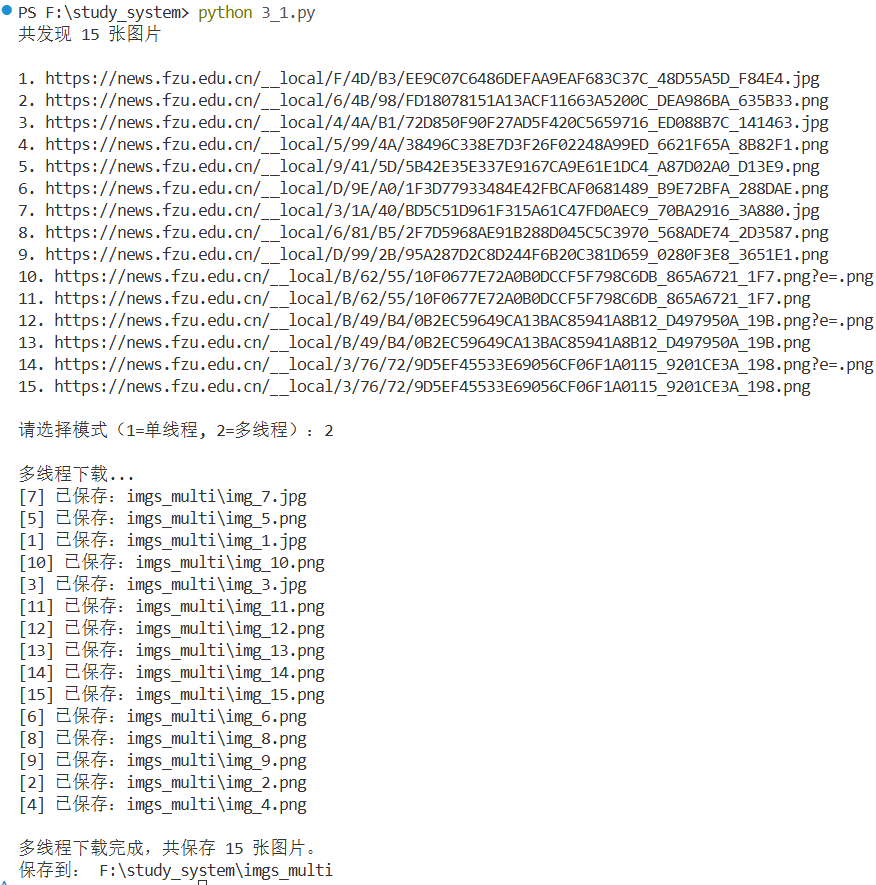
mode = input("\n请选择模式(1=单线程, 2=多线程):")
if mode == "1":
print("\n单线程下载...")
save_dir = "imgs_single"
os.makedirs(save_dir, exist_ok=True)
for i, img_url in enumerate(imgs, start=1):
result = download_image(i, img_url, save_dir)
print(result)
print(f"\n单线程下载完成,共保存 {len(imgs)} 张图片。")
print("保存到:", os.path.abspath(save_dir))
elif mode == "2":
print("\n多线程下载...")
save_dir = "imgs_multi"
os.makedirs(save_dir, exist_ok=True)
# 设置线程数
workers = 8
with ThreadPoolExecutor(max_workers=workers) as executor:
futures = [executor.submit(download_image, i, img_url, save_dir) for i, img_url in enumerate(imgs, start=1)]
for future in as_completed(futures):
print(future.result())
print(f"\n多线程下载完成,共保存 {len(imgs)} 张图片。")
print("保存到:", os.path.abspath(save_dir))心得体会
单线程:串行执行,每次只能下载一张图片,速度较慢。
多线程:并行下载多张图片,网络 IO 场景下优势明显,图片越多效果越明显。
作业②
要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法:Scrapy+Xpath+MySQL数据库存储技术路线爬取股票相关信息。http://finance.sina.com.cn/stock/

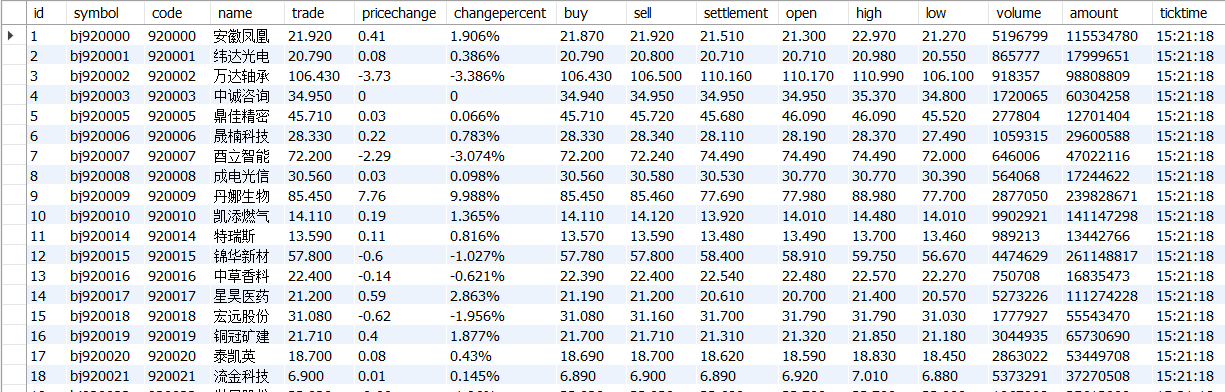
import scrapy
import json
from sina3_2.items import Sina3_2Item
class QuotesSpider(scrapy.Spider):
name = "quotes"
allowed_domains = ["vip.stock.finance.sina.com.cn"]
def start_requests(self):
base_url = "https://vip.stock.finance.sina.com.cn/quotes_service/api/json_v2.php/Market_Center.getHQNodeData"
for page in range(1, 11):
params = {
"page": page,
"num": 40,
"sort": "symbol",
"asc": 1,
"node": "hs_a",
"symbol": "",
"_s_r_a": "page"
}
yield scrapy.FormRequest(
url=base_url,
formdata={k: str(v) for k, v in params.items()},
callback=self.parse,
meta={"page": page}
)
def parse(self, response):
page = response.meta["page"]
try:
data = json.loads(response.text)
except json.JSONDecodeError:
self.logger.warning(f"第 {page} 页解析失败")
return
if not data:
self.logger.info("数据为空,爬取结束")
return
for stock in data:
item = Sina3_2Item()
for field in item.fields.keys():
item[field] = stock.get(field, "")
# 给涨幅百分比加%
if item["changepercent"] and not str(item["changepercent"]).endswith("%"):
item["changepercent"] = f"{item['changepercent']}%"
yield item心得体会
Xpath 对于结构化网页,定位精准、速度快。
作业③
要求:熟练掌握scrapy中Item、Pipeline数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数。https://www.boc.cn/sourcedb/whpj
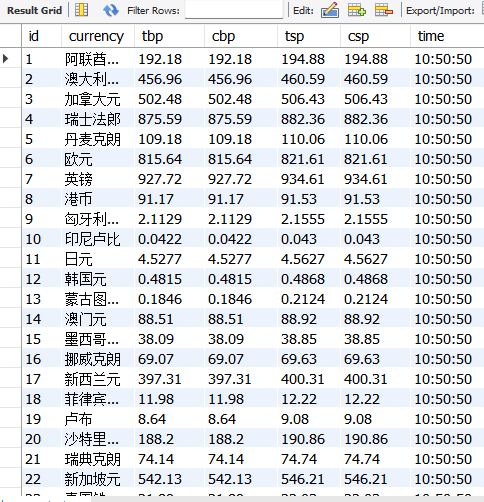
import scrapy
from boc.items import BocItem
class BocSpider(scrapy.Spider):
name = "bocspider"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
rows = response.xpath('//table[@align="left"]//tr[td]')
for r in rows:
cols = r.xpath('./td/text()').getall()
if len(cols) != 8:
continue
item = BocItem()
item['currency'] = r.xpath('./td[1]/text()').get(default="").strip()
item['tbp'] = r.xpath('./td[2]/text()').get(default="").strip()
item['cbp'] = r.xpath('./td[3]/text()').get(default="").strip()
item['tsp'] = r.xpath('./td[4]/text()').get(default="").strip()
item['csp'] = r.xpath('./td[5]/text()').get(default="").strip()
item['time'] = r.xpath('./td[8]/text()').get(default="").strip()
yield item心得体会
通过调整 XPath 并验证提取结果,我体会到了网页解析时分析结构比代码更关键。如果定位不准没办法提取到字段

 浙公网安备 33010602011771号
浙公网安备 33010602011771号