

作业一
作业①
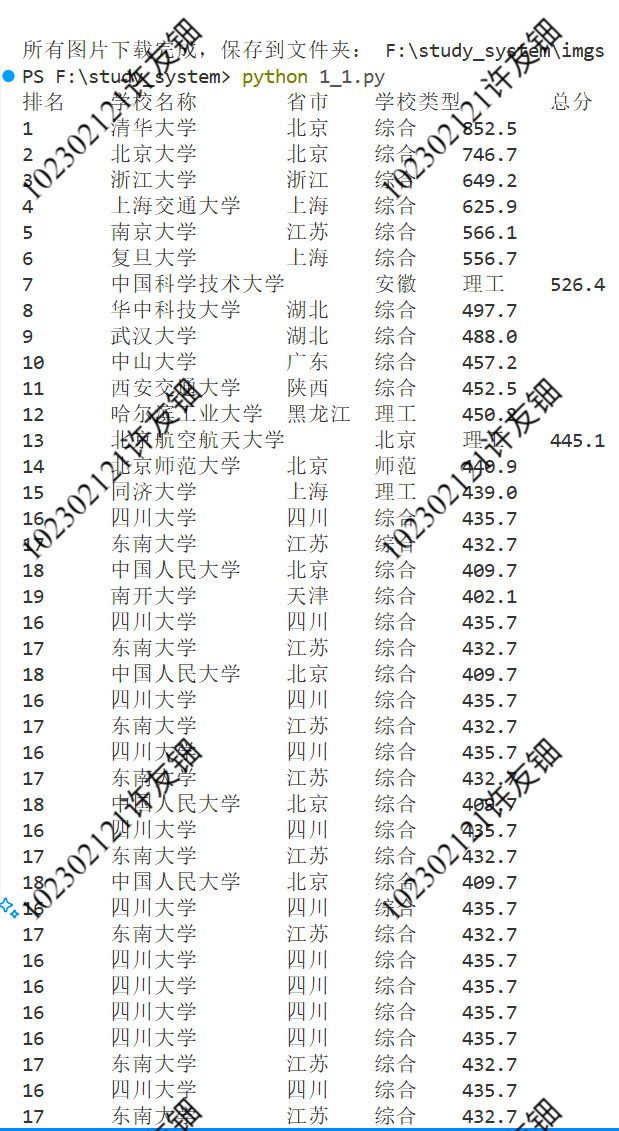
- 用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。

2.心得体会
有些网站实际编码可能与声明编码不一致,所以用apparent_encoding自动检测是最合适的,在对院校名称爬取时会附带双一流985等,通过.split('\n')[0]只提取名称即可。这是一个较为通用的爬取模板。
作业②
- 用requests和re库方法设计某个商城(百联网)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。


2.心得体会
发现在爬取动态加载页面时requests和re库没办法直接根据网页爬到有效信息,所以先在终端贴出源码,然后再根据源码的格式写正则表达式,爬取模板大差不差,主要的难点还是在正则表达式上。
作业③
- 爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件



2.心得体会
先爬出网址路径,然后根据路径下载图片保存到本地即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号