
Python学习 day08
一、open打开文件
文件操作包含以下三个步骤:
1、文件路径
2、编码方式
3、操作方式:‘’只读‘’、“只写”、“读写” 等
1、只读 r (mode默认值)
例:
f = open('d:\python手册.txt', mode='r', encoding='utf-8') # mode='r'为只读模式 content = f.read() print(content) f.close() # 注意:文件打开后一定要关闭,一是占用内存,二是占用该文件则其他进程不可修改该文件
结果:

对于r模式打开文件,文件如果不存在,则报错
2、只写 w
例:
f = open('日志', mode='w', encoding='utf-8') f.write('今天天气好晴朗') f.close()
原文件夹内容:
执行代码后文件夹内容:
日志中的内容:
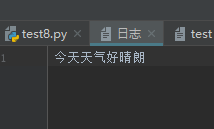
对于w模式打开文件,文件如果不存在,创建
3、追加 a
例:
f = open('日志', mode='a', encoding='utf-8') f.write('处处好风光 好风光') f.close()
查看日志内容:
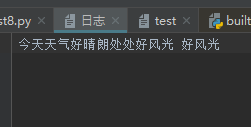
对于a模式打开文件,文件如果不存在,创建
4、读写 r+、w+、a+
r+、w+、a+都可以进行读写操作,不同的是:
r+ 可读可写
写入时覆盖写(取决于光标位置,类似于insert),例:
f = open('日志', mode='r+', encoding='utf-8') f.write('那一天,那一年') print(f.read()) f.close()
结果:
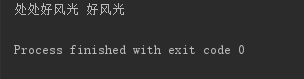
“日志”文件中内容:
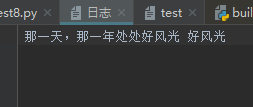
w+ 可写可读
写入时清空重写,例:
f = open('日志', mode='w+', encoding='utf-8') f.write('绿野茫茫天苍苍') print(f.read()) f.close()
‘日志’中的内容:
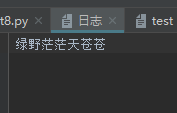
a+ 可追加可读
写入时追加写,同a一样,不再举例。
5、二进制文件读写
文件读写除了字符的读写方式(字符应该也是二进制读取后程序内部转成了字符串),还可以用二进制对文件进行读写
上面所说的所有模式后面加b即表示二进制流的读写。即:rb、wb、ab、r+b、w+b、a+b
举例,还是读取刚刚的‘日志’:
f = open('日志', mode='rb') # 因为是二进制的方式,不需要设置编码 content = f.read() print(content) print(content.decode('utf-8')) f.close()
结果:

- 可以看到,在打开文件时并没有设置encoding编码方式,因为文件存储本就是二进制的,直接读取
- 读取到的内容因为是二进制的,并且一开始‘日志’就是utf-8编码的,这里直接打印文件内容,得到的便是字符串的utf-8编码的二进制内容
- 可以用decode('utf-8')转码为str,然后就可以看到文件的字符内容
- 二进制操作多是用于影音等媒体文件,不能直接打开为文本的文件
其他的二进制读写模式类似,不再说明
6、其他说明
open()调用的是系统命令,即调用的操作系统的方法,本身python是不具有打开文件的权限的。既然调用的是系统命令,自然编码方式是按照系统编码来的,windows中文系统都是gbk编码,因此要将文件打开,写入读取都由str(unicode编码)- 文件内容(utf-8编码)之间转换,所以方法内部肯定封装了对编码的处理。
二、文件操作方法
读:
- read(n) 读取多少字符/字节,b方式打开的就表示读取多少字节,n不填则默认读取全部。
- readline() 一次读一行
存在的问题:1、不知道在哪儿结束;2、视频、图片不能用readline读,只能按字节读
- readlines() 按行一次性读取,并保存为列表,源代码注释:
Return a list of lines from the stream.
hint can be specified to control the number of lines read: no more
lines will be read if the total size (in bytes/characters) of all
lines so far exceeds hint.
- for循环(这是最好的文件读取方式) for ... in f 循环一行行读取文件内容,例:
for line in f: print(line) f.close()
结果:
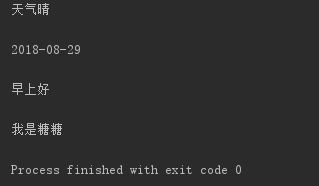
注意:在实际操作文件读写时,尽量不要一次性读取所有文件,尤其是在对文件大小不清楚的情况下!
写:
- write()
光标:
- seek(offset,whence) 调光标位置
offset:开始的偏移量,也就是代表需要移动偏移的字节数
whence:给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。whence值为空没设置时会默认为0。
源代码注释:
Change stream position.
Change the stream position to the given byte offset. The offset is
interpreted relative to the position indicated by whence. Values
for whence are:
* 0 -- start of stream (the default); offset should be zero or positive
* 1 -- current stream position; offset may be negative
* 2 -- end of stream; offset is usually negative
Return the new absolute position.
- tell() 返回当前光标位置(以字节为单位计),源代码注释:
Return current stream position.
- truncate(size) 将文档截取至size字节数,即后面内容全部删除(与光标位置无关)。源代码注释(他说的应该是size默认是当前光标位置,但是我试了跟光标没关系,默认是都不删除的):
Truncate file to size bytes.
File pointer is left unchanged. Size defaults to the current IO
position as reported by tell(). Returns the new size.
ps:文件io的源码文件为_io.py,可自行查看里面的函数说明
文件操作光标
基本跟java类似的,打开文件时光标位于开始位置,读取或写入都从光标当前所在位置开始,操作执行会移动光标,一次打开文件操作光标都是顺序往后移动,移动到最后也不会返回文件开头。
三、with open
每次打开文件,都必须要close,但是可能存在忘记的情况,这就比较麻烦了,所以就出了with open的打开文件方式,例:
with open('日志', mode='r+', encoding='utf-8') as f: print(f.readline())
是的,你没有看错,用with open的方式将不用再写close()了。之前说不知道什么时候关闭。。。自己真的是蠢,这里用了with open 。。。:,自然是里面内容执行完就表示不再使用该文件,自动关闭了
with open还有个功能,可以同时打开多个文件,如下:
with open('日志', mode='r+', encoding='utf-8') as f, \
open('test', mode='r', encoding='utf-8') as t: print(f.readline()) print(t.read(4))
注意:打开多个文件,分行写换行要加“\”,当然pycharm自己会给你加
四、文件路径的一些坑
在写文件路径时,‘d:\python手册’这样写没有报错,但如果打开的文件路径如'd:\123.txt',则会报FileNotFoundError错误,如下:
f = open('d:\123.txt', mode='r', encoding='utf-8') # 注意文件路径 content = f.read() print(content) f.close()
结果:
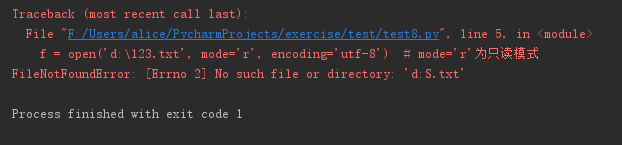
报的错误为No such file or directory:‘d:S.txt’,可以看到文件路径并非我们所写的'd:\123.txt'。其实在这里也能明白是‘\’转义符的问题,我们可以将‘\’改为‘\\’,或者用r'xxx'转义,又或者不用‘\’而使用'/',如下:
f1 = open('d:\\123.txt', mode='r', encoding='utf-8') content = f1.read() print(content) f1.close() f2 = open(r'd:\123.txt', mode='r', encoding='utf-8') content = f2.read() print(content) f2.close() f3 = open('d:/123.txt', mode='r', encoding='utf-8') content = f3.read() print(content) f3.close()
结果:
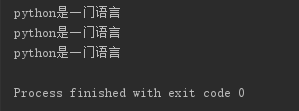
另外,我们看到原来的‘d:\123.txt’被转义为了'd:S.txt',所以这里的转义符是将123当做8进制,然后去找对应的ASCII码的值。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号