
Python学习 day07
一、关于解决问题的思路
1、删除列表中索引为单数的元素。
别人的思路:
- 利用切片
li = [11, 22, 33, 44, 55] li = li[::2] print(li)
思考:虽然学了python,学了切片,但一直都没好好利用过
- 建立新列表
li = [11, 22, 33, 44, 55] li1 = [] for i in range(len(li)): if i % 2 == 0: li1.append(li[i]) li = li1 print(li)
思考:写程序一定不能思维定式,表面呈现并不一定就是内部过程
- 倒叙删除
li = [11, 22, 33, 44, 55] for i in range(len(li) - 1, -1, -1): if i % 2 == 1: print(i) li.pop(i) # del li[i] print(li)
思考:如果正序循环,删除元素会影响后面元素的索引,而倒叙则不会,是一种好方法
自己的思路:
- 第一种
li = [11, 22, 33, 44, 55] i = 0 while i < len(li) - 1: i += 1 del li[i] print(li)
- 第二种
li = [11, 22, 33, 44, 55] flag = True for i in li: if flag: flag = False continue li.remove(i) print(li)
反思:自己写的两种方法比较讨巧,第二种更是经过了debug探寻了for循环的运行情况才想到的,之后再看很可能都不知道自己为什么这么写。for in循环应该也是按索引循环的,因此删除一个元素后,该元素紧邻的后面元素就不会取到了。
自己写的整个思路相较上面的思路实在是太死板了。。。
2、删除dic中key值含有‘k’的键值对
- 建立新字典
dic = {'k1': 'v1', 'k2': 'v2', 'a3': 'v3', 'k4': 'v4', 'a5': ' v5'}
dic1 = {}
for i in dic:
if i.find('k') == -1: # if 'k' not in i:
dic1[i] = dic[i]
dic = dic1
print(dic)
- 列表保存含‘k’的键,删除
dic = {'k1': 'v1', 'k2': 'v2', 'a3': 'v3', 'k4': 'v4', 'a5': ' v5'}
li = []
for i in dic:
if 'k' in i:
li.append(i)
for i in li:
dic.pop(i)
print(dic)
思考:这个题自己没做,只能参考下别人的思路。第一种同上面列表删除的第二种方法。第二种方法,因为dict在循环中不能做修改操作,会报错,所以要把要删除的键保存下来。
二、dict的fromkeys()方法
fromkeys(*args, **kwargs) -- 直接看源代码注释:
Returns a new dict with keys from iterable and values equal to value.
再看示例:
dic = dict.fromkeys([1, 2, 3]) print(dic) dic = dict.fromkeys([1, 2, 3], 'python') print(dic) dic = dict.fromkeys([1, 2, 3], ['python']) print(dic)
结果:
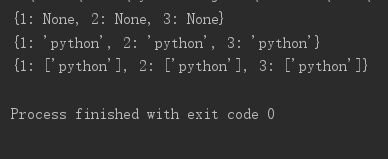
这个方法基本就这么个意思了。
重点:这里有个小坑,如下:
dic = dict.fromkeys([1, 2, 3], ['python']) print(dic) dic[1].append('java') print(dic) dic[2].extend('C++') print(dic) dic[3] = 'js' print(dic)
结果:

由上例可看出,使用fromkeys()创建的dict,在对任何一个键的列表做修改操作时会同时修改所有键下的值。而赋值操作却对其他的键的值没有影响。
这是因为fromkeys()在生成dict时,因为每个键对应的值相同,所以直接将所有key的value指向了同一个地址。。。因此,对所有值是可变元素的value,修改其中一个,所有的都会变。。。直接赋值是因为将该value指向了新的地址。。。类似浅复制,理解原理都好说,就是要记得这个坑!!!
三、set
set的创建,两种方式:
1、s = {1, 2, 3}
2、s = set([1, 2, 3])
其实也就是一种方式,第二种创建方式仔细看其实就是用set()方法转化,将list转化为set
至于set为什么用{}表示呢,因为set的性质基本与dict的key相同,再就是因为。。。刚刚想到。。这是集合呀,当然要用{}
set的基本性质:无序、不重复、可哈希、且set的元素只能是不可变数据类型(因此若需要去重的,可直接转为set,至于去重比较的是值还是地址就不清楚了,因为不可变元素在python的内存中都只存在一份,应该跟java一样是值和地址吧)
增
add()
update() -- 类似list的extend,是迭代的增加的
删
pop() -- 随机删除
remove() -- 按元素删除
clear() -- 清空
del 删除
改
改是不可能改的,都是不可变元素怎么改呢 ╮(╯_╰)╭
查
只能用for in循环查
set的重点
1、交集 & 或 intersection()
2、并集 | 或 union()
3、反交集/补集 ^ 或 symmetirc_difference()
4、差集 - 或 difference()
5、包含关系
< 或 issubset() 真子集
> 或 issuperset() 这个。。叫真母集嘛
>= <= == 这些都可以用,一看就明白
frozenset
创建即用frozenset(),参数是个可迭代的就可以
frozenset就是个冻结的集合,不能增、删(当然可以删除整个集合),只能查
四、深浅拷贝
1、赋值
说深浅拷贝前先说说赋值,我们都知道赋值即是把对象地址赋给新变量,两个变量指向同一个地址。如下例:
li = [1,2,3] li[1] = li print(li)
结果:
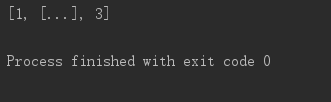
可以看到li[1]变成了[...],即内容为无限的,这是因为li[1]又指向了li这个对象,li里的1又指向了li,无限循环。
2、浅拷贝
浅拷贝有四种形式:切片操作,list的copy方法(set、list、dict都有这个方法,tuple没有,其他的对象以后遇到再查源码),工厂函数,copy模块中的copy方法
li = [1, 2, 3] li1 = li[:] # 切片 li2 = li.copy() # copy方法 li3 = list(li) # 工厂函数 import copy li4 = copy.copy(li) #copy模块中的copy方法 print(li, id(li)) print(li1, id(li1)) print(li2, id(li2)) print(li3, id(li3)) print(li4, id(li4))
结果:
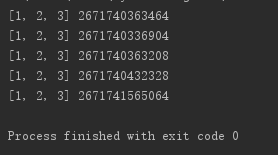
可以看到,都实现了复制操作,原li对象地址与所有复制得到的变量地址均不同
再看li[1] = li的例子,只用一种浅拷贝方法测试:
li = [1, 2, 3] li[1] = li.copy() print(li)
结果:
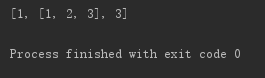
可以看到,浅拷贝不同于赋值操作,变量li[1]指向的不再是原来的li,所以在底层是确确实实做了一次拷贝工作的。
浅拷贝的最大问题就是,当拷贝的内容出现引用类型时,如:
li1 = [1, [2, 3], 4] li2 = li1[:] li2[1].append(5) print(li1) print(li2) print(id(li1[1])) print(id(li2[1]))
结果:
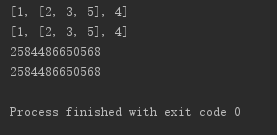
从上可看出,浅拷贝对于元素内部的引用类型,拷贝时只是将新拷贝的对象里的该元素指向了原对象里的该元素的地址,即新旧元素中的引用对象是同一个
3、深拷贝
深拷贝使用copy中的deepcopy()方法,深拷贝即相对于浅拷贝,解决了上面所述的问题。deepcopy 本质上是递归 copy,例:
import copy li1 = [1, [2, 3], 4] li2 = copy.deepcopy(li1) print(id(li1[1])) print(id(li2[1]))
结果:
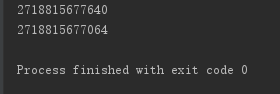
总结
赋值即最外层元素是同一个地址
浅拷贝即最外层元素不是同一个,但里面的引用都是同一个
深拷贝则所有的元素,不管外层父元素还是内层子元素等等全部都是新的
小知识
1、关于转化成bool
转化成bool值是False的有:None 、0 、‘’ 、[] 、() 、{} 、set() (即0和所有空的东西)
2、元祖表示的问题,例:
tu = (1) print(tu, type(tu)) tu = (1,) print(tu, type(tu)) tu = ([1, 2]) print(tu, type(tu)) tu = ([1, 2],) print(tu, type(tu))
结果:

从上可以看出,对于元祖中只有一个元素的情况,在初始化定义时,一定要在该元素后面加个“,”。
这个问题很好理解的,因为在这里程序中的()有两种含义,一是表示()里面内容是个整体,二是表示()是个元祖,为了不产生歧义,自然是只能有一种意思,而第一种意思肯定是要先考虑的啦,所以第二种就得换个表示方法了啦
3、enumerate()
对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值
enumerate多用于在for循环中得到计数
像之前想在for循环得到索引,一直用的是for i in range(len(li)),i能表示索引,但这只是一种变通方法,循环的也只是数字,得到列表的值还需要用li[i]。有了enumerate()后,可以使用如下方法:
li = ['豆浆', '油条', '包子', '烧麦', '油饼', '鸡蛋'] for index, i in enumerate(li, 2): print(index, i)
结果:
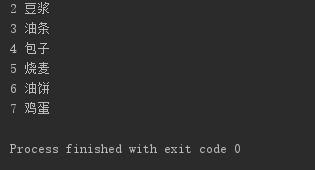
可以看到,enumerate(iterable, start=0) ,第一个为循环内容(必须可迭代),第二个为起始序号,默认为0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号