Linux网络IO模型浅析(一)阻塞IO
题记
提到Linux网络IO,相信大家都不陌生。
最初学习进程间通信的时候,我们通常都会用socket实现一个简单的c-s通信模型,其实那个时候已经初探了网络编程的门径,我们用socket实现了一个简单的数据收发,其实也内含一种基本的网络IO模型(阻塞IO)。
随着学习的深入,我们了解到更多的网络IO处理方法,但基本来说都可以分为以下几类:
- 阻塞IO(blocking IO)
- 非阻塞IO(non-blocking IO)
- 多路复用(IO multiplexing :select,epoll等)
- 信号驱动IO(SIG IO)
- reactor模型
接下来,我们花一点时间,耐心的了解下这五种网络IO模型,以便在将来的工作中讲原理与实践完美结合,写出高可用的项目工程代码。
阻塞IO
一个典型的阻塞IO收发过程如下:
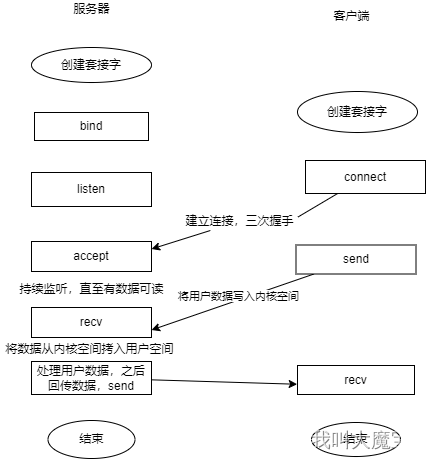
可见,服务器在处理一次网络数据接入时,会有两个阶段的阻塞:
- 等待kernel有数据写入accept返回的fd文件描述符
- 将数据从kernel写入用户空间
即等待数据和拷贝数据两个过程,都被阻塞了。
几乎所有的程序员第一次接触到网络编都是从listen()、send() 、recv() 等接口开始的,实际上这些接口都是阻塞型的,即通过这些接口触发系统调用后,整个线程就被阻塞了,直到获得结果或者超时出错时才会返回结果。这就给网络编程带来一个很大的问题,即进行阻塞的系统调用时,无法做数据处理或者及时处理其他IO请求。
比如我们调用send()进行数据发送时,线程阻塞。此时我们无法进行内存读写或者处理另一个network input。这是对cpu资源的浪费。
阻塞IO的改进方案与掣肘
改进方案
一个比较简单的改进方案是利用并发技术规避掉一部分线程阻塞时间:
比如利用多线程pthread_create()或者多进程fork()来处理当次网络请求。具体采取哪种方式需要结合具体的场景进行分析,没有绝对的方案。
- 多线程开销要远远低于多进程,适合同时为多个客户机提供服务。
- 多进程相较多线程更安全,如果单个服务执行体需要消耗较多的CPU资源,譬如要进行大规模的数据处理或者长时间的文件访问。
此刻就有了如下模型:
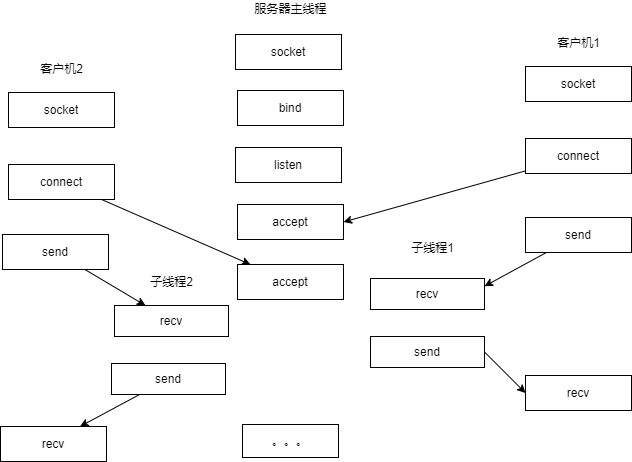
上述模型较好的解决了处理某个网络接入时,无法及时处理其他响应的问题。但是当我们再发散思维,多线程或者多进程会额外带来系统资源消耗,如果同时要响应成百上千路的连接请求,频繁地进行线程和进程的创建和销毁就会占用不少时间,降低了系统对外界的响应效率,线程和进程本身也会更容易进入假死状态。
遇到这种情景,我们很容易想到使用线程池,连接池等池化技术规避频繁创建和销毁带来的负面影响。
- 线程池即自己维护一定数量的线程,让空闲的线程快速重新承担处理任务,处理完毕的线程加入到空闲队列,直到被调度继续处理下一个任务。
- 连接池则维护连接的缓存池,尽量重用已有的连接,减少频繁创建和销毁连接。
这两种技术确实可以降低系统开销,实际上也已经广泛应用于很多大型系统,如websphere,tomcat等各种数据库。
但是池化技术本质上只是对已有系统资源进行调度,其优化上限不会超过主机本身的处理能力。当请求很大程度的超过主机本身能力的上限,其实和不用“池”的整体表现无异。所以使用“池”必须考虑其面临的响应规模,并根据响应规模调整“池”的大小。
掣肘
对应上例中的所面临可能同时出现千甚至万级的客户端请求,“线程池 ”或“连 接池 ”或许可以缓解部分压力,但是不能解决所有问题。
总之多线程或者多进程模型可以方便高效的解决小规模的服务请求,但面对大规模的服务请求,多线程模型也会遇到瓶颈。由于阻塞的耗时问题,我们不得不采取并发技术缓解压力,但是如果压力无法缓解,我们需要想办法避开压力,即直接避开阻塞的影响!此时可以尝试用非阻塞接口来解决这个问题。
(...)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号