对比自监督学习
A Framework For Contrastive Self-Supervised Learning & Designing A New Approach
注:本文参考作者的介绍博文,绝大部分内容为博文的直译,着色文字为个人记录(TDS上的论文介绍图文并茂,写得非常详细)

对比学习:批量输入
在过去的一年里,人工智能研究领域中一系列“新颖”的自监督学习算法取得了先进的成果:如AMDIM(这是DIM的延伸工作,引入了数据增强)、CPC、SimCLR、BYOL、Swav等等。
本论文制定了一个概念框架来描述对比自监督的学习方法。作者使用这一框架分析了上述主要方法中的三个示例:SimCLR、CPC和AMDIM,并表明,尽管这些方法表面上看起来不同,但实际上它们是彼此的微调版本。
本博客主要包括以下内容:
- 回顾自监督学习;
- 回顾对比学习;
- 提出一个框架,用于比较最近的学习方法;
- 使用该框架比较CPC、AMDIM、MOCO、SimCLR和BYOL;
- 使用该框架制定一种新方法—YADIM;
- 描述部分结果;
- 描述实现这些结果的计算需求。
1. 代码实现(Implementations)
本文中描述的所有增强方式及方法都是在PyTorch Lightning中实现的,它可以在任意硬件上进行训练,并使各个方法间的并行比较变得更加容易。
2. 自监督学习(Self-Supervised Learning)
回想在监督学习中,给定系统输入 (x) 和标签 (y),

监督学习:左边是输入,右边是标签
在自监督学习中,则只给系统输入 (x)。没有标签 (y) 的情况下,系统需要“从输入的其他部分学习预测输入的某一部分” [参考]
(这篇参考是一篇推文,作者引用了推文中的原句:learns to predict part of its input from other parts of its input)

在自监督学习中,输入既是源(Source)又是目标对象(Target)
事实上,这种提法颇为笼统,以至于你可以创造性地“分割”输入。这些策略被称为前置任务(pretext tasks),研究者们尝试了各种各样的方法。这里有三个例子:(1)预测两个图像块(patch)的相对位置;(2)解决拼图问题;(3)给图像着色。

前置任务的例子
虽然以上方法充满了创造力,但它们实际上并不能很好地应用于实践。然而,最近一系列使用对比学习的方法已经显著地缩小ImageNet上监督学习之间的差距。
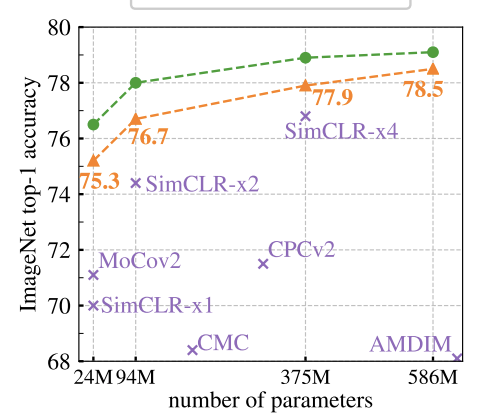
最新的方法(Swav)正在缩小ImageNet上监督训练之间的变异差距(来源论文:Swav作者)
3. 对比学习(Contrastive Learning)
大多数机器学习算法背后的一个基本思想是,相似的示例应该在同一个分组中,并远离其他相关示例所在的集群。
对比学习早期研究的基本想法即来源于此,Learning a Similarity Metric Discriminatively, with Application to Face Verification By Chopra et al in 2004
下面的动画说明了这个主要思想:

对比学习通过使用三个关键成分(key ingredients)来实现这一点:正例(positive)、锚(anchor)以及负例(negatives)表示(representation)。构成正例对(positive pair)需要两个相似的示例;对于负例对,我们则使用另一个(第三个)不相似的无关示例。

然而,在自我监督学习中,我们不知道示例的标签。因此,我们无法得知两幅图像是否相似。(这个转折预示着决我对自监督学习的困惑)
不过,如果我们假设每个图像都自成一类(class),我们就可以使用各种方法构成这上述三张图片(正例对和负例对共需要三张图片,原文中用的是triplets,即三胞胎)。这意味着在一个大小为N的数据集中,我们有N个标签!

现在我们(差不多)知道了每张图像的标签,我们可以使用数据增强来生成这三张图片。
4. 特性1:数据增强管道(Characteristic 1: Data Augmentation pipeline)
描述对比自监督学习方法的第一种方式:定义一个数据增强管道。
数据增强管道 A(x) 对同一输入应用一系列随机变换。

应用于某一输入的随机数据增强管道 A(x)
在深度学习中,数据增强的目的是建立一种表示,能对原始输入中的噪声保持不变性。例如,神经网络应该将上图中的猪识别为“猪”,即使图像被旋转、去色、或者像素产生抖动。
在对比学习中,数据增强管道还有一个次要目标,即生成锚、正例和负例,它们将被输入给编码器,并被用于提取表示。
- 4.1 CPC管道(CPC Pipeline)
CPC引入了一个管道,可以应用诸如颜色抖动、随机灰度、随机翻转……等变换。同时,它还引入了一个特殊的变换,可以将图像分割成重叠的(overlaying)子块(sub patches)。
(看下列动图就可以发现各子块之间的重叠关系,不过这样做有什么好处呢?为什么一定要重叠?)

CPC的主要变换
利用这一管道,CPC可以生成多组正样本和负样本。在实际运用中,我们将这一过程应用至批量示例(a batch of examples)中,并使用示例中的其它示例作为负样本。

从批量图像中生成正例、锚以及负例对(批大小 = 3)
[横向看,第一行即为以第一张图中部作为锚点,其余两张图片的图像块作为负样本(可以有多个负样本)]
- 4.2 AMDIM 管道(AMDIM pipeline)
AMDIM采用了一种稍微不同的方法。通过对同一幅图像应用两次数据增强管道,在执行了标准变换(抖动、翻转……等)之后就可以得到一张图像的两个版本。

这个想法实际上是2014年 Dosovitski 等人的一篇论文中提出的。其想法是使用一张“种子”图像("seed" image)来生成同一图像的多个版本。
- 4.3 SimCLR、Moco、Swav、BYOL管道(SimCLR, Moco, Swav, BYOL pipelines)
AMDIM中的增强管道效果很好,因此之后的各种方法都选择使用相同的管道,但是它们对事先发生的转换做了轻微的调整(一些添加抖动,一些则加入高斯模糊……等等)。然而,与AMDIM中引入的主要思想相比,这些变换大多数都是无关紧要的。
在论文中,我们对这些变换的影响进行了分析,发现如何选择变换对方法性能而言至关重要。事实上,我们认为这些方法成功的驱动力,主要来自于选择了特定变换。
这些发现与SimCLR和BYOL中的类似结果保持一致。
YouTube有一则视频详细地说明了SimCLR管道(SimCLR pipeline)。
5. 特性2:编码器(Characteristic 2: Encoder)
描述对比自监督学习方法的第二种方式:编码器的选择。上述大多数方法使用不同宽度和深度的ResNets。
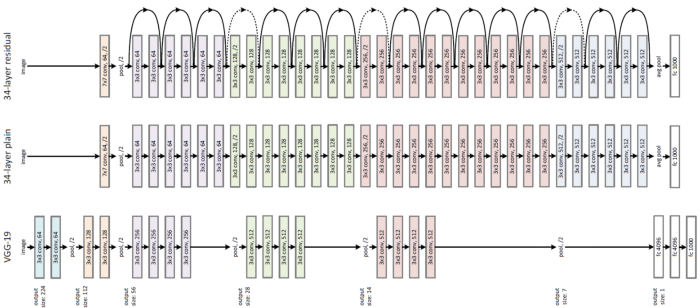
ResNet架构(来源:原ResNet论文)
当这些方法出现时,CPC和AMDIM实际上设计了自定义编码器。我们的对比实验(ablation study)发现,AMDIM并没有得到很好的推广,而CPC受编码器变化影响较小。
(这里原文用的是ablations,查询了一下ablation study代表控制变量法/对比实验,英文释义:An ablation study typically refers to removing some “feature” of the model or algorithm, and seeing how that affects performance.)
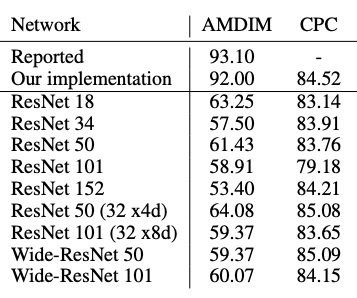
CIFAR-10数据集上编码器的鲁棒性
自CPC之后,各方法都采用ResNet-50架构。虽然这一架构可能仍有优化空间,但规范使用ResNet-50架构,意味着我们可以专注于改进其他特性,通过更好的训练方法(而不是更优的架构)来推动改进。
对于每一次对比实验,有一个事实是明确的:编码器网络宽度越宽(wider encoders),在对比学习中表现得越好。
特性3. 表示提取(Characteristic 3: Representation extraction)
描述对比自监督学习方法的第二种方式:用于提取表示的策略。这就是所有这些方法的“魔力”所在,也是它们最与众不同的地方。
为了理解它的重要性,让我们先定义一下表示的含义。表示是一组独特的特征,让系统(和人类)理解是什么使得对象成为对象本身(makes that object, that object),而非其它对象。
这篇Quora问答使用了一个形状分类的例子。要想成功地对形状进行分类,形状中角的数量可能是一种比较好的表示。

在对比学习的一系列方法中,表示可以用不同的方式提取出来。
- CPC
CPC学习表示的主要思想是:预测潜在空间中的“未来”(predicting the “future” in latent space)。实际上这意味着两件事:
1)将图像视为时间轴,左上角是“过去”(past),右下角是“未来”(future)。

2)预测并非在像素级(pixel level)进行,相反,CPC使用的是编码器的输出(即:潜在空间)

从像素空间到潜在空间
最后,通过将编码器的输出(H),作为由映射层头部(projection head,作者称之为上下文编码器)所生成的上下文向量的目标y,构建一个预测任务来进行表示提取。

CPC表示提取
(这段话太绕了,结合动图理解一下:原图通过编码器后,输出H,即图中的蓝色向量;蓝色向量经过映射后得到了上下文向量,即图中的红色向量。我们把红色向量作为预测任务的输入x,蓝色向量作为目标y,构造一个预测任务)
(其中,预测就是前文中所提到的从“过去”(左上角)预测“未来”(右下角),不过这里我也存疑?)
在本文中,我们发现只要数据增强管道足够强大,这种预测任务则是不必要的。虽然有很多关于如何定义一个管道是否足够好的假设,但我们认为,一个强大的管道能够产生这样的正例对:具有相似全局结构,以及不同的局部结构。
- AMDIM
另一方面,AMDIM使用了在视图(view)间比较各表示的想法,这些视图来源于卷积神经网络(CNN)中间层所提取的特征图(feature map)。让我们把它分成两部分,1)一张图像的多个视图,2)CNN网络的中间层。
1)回忆前文,AMDIM的数据增强管道会生成同一幅图像的两个版本。

2)所生成的每个版本的图像,都被输入至同一个编码器,以提取图像的特征图。AMDIM并不丢弃由编码器生成的中间特征图,而是使用它们进行跨空间尺度(spatial scales)的比较。回想一下,当一个输入经过CNN的各层时,感受野(Receptive Fields)会为该输入编码不同尺度的信息。
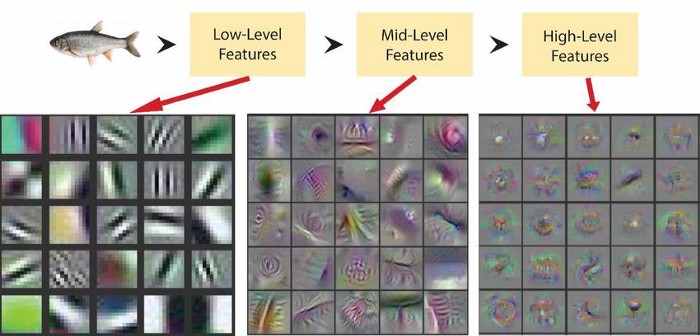
AMDIM通过比较CNN中间层的输出来实现这一想法。下面的动画演示了如何在编码器生成的三个特征图之间进行比较:

AMDIM表示提取:AMDIM使用同一个编码器提取3组特征图,然后对特征图进行比较。
下文中的其它方法都只是对AMDIM提出的想法进行了微调。
- SimCLR
SimCLR使用与AMDIM相同的想法,但做了2处调整:
A)只使用最后一张特征图;
B)将该特征图通过映射层头部(projection head),并比较两个向量(类似于CPC上下文映射,context projection)。
- Moco
正如我们前面提到的,对比学习需要负样本才得以工作。通常,这是通过比较批处理中的一张图像与其他图像(images,复数)来实现的。
Moco与AMDIM做同样的事情(仅使用最后一个特征图),但MoCo保留了所有批次的历史记录,并增加了负样本的数量。其效果是,用于提供对比信号的负样本的数量增加,超过了单个批大小。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号