
【Coursera GenAI with LLM】 Week 2 Fine-tuning LLMs with instruction Class Notes
GenAI Project Lifecycle: After picking pre-trained models, we can fine-tune!
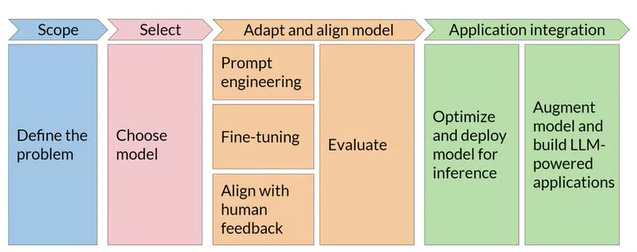
In-context learning (ICL): zero / one / few shot inference. Including a few models in the prompt for model to learn and generate a better complement (aka output). Its drawbacks are:
- for smaller models, it doesn't work even when a lot of examples are included
- take up context window
Pre-training: you train the LLM using vast amounts of unstructured textual data via self-supervised learning
Fine-tuning: supervised learning process where you use a data set of labeled examples to update the weights of the LLM.
Two types of fine-tuning
- Instruction fine-tuning (full fine-tuning: very costly!)
It trains the model using examples that demonstrate how it should respond to a specific instruction.
Prepare instruction dataset --> split the dataset into training, validation, and test --> calculate the loss between training completion and the provided label --> use the loss to calculate the model weights in standard backpropagation - PEFT (Parameter Efficient Fine-tuning: cheaper!)
PEFT is a set of techniques that preserves the weights of the original LLM and trains only a small number of task-specific adapter layers and parameters.
ex. LoRA
Catastrophic forgetting: full fine-tuning process modifies the weights of the original LLM, which can degrade performance on other tasks
--> To solve catastrophic forgetting, we can use PEFT!
Multi-task instruction: it can instruct the fine tuning on many tasks, but it requires a lot of data and examples
FLAN: fine-tuned language net, is a specific set of instructions used to fine-tune different models. Like the yummy dessert

Terms
- Unigram: a single word
- Bigram: two words
- n-gram: n words
Model Evaluation Metrics
- **Accuracy **= Correct Predictions / Total Predictions
- ROUGE (recall oriented under study for jesting evaluation): assess the quality of automatically generated **summaries **by comparing them to human-generated reference summaries.
- BLEU (bilingual evaluation understudy): an algorithm designed to evaluate the quality of machine-**translated **text by comparing it to human-generated translations.



Benchmarks:
tests that evaluate the capabilities of models. ex. GLUE, SuperGLUE, MMLU (Massive Multitask Language Understanding), Big-bench Hard, HELM (Holistic Evaluation of Language Models)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号