Spark中文指南(入门篇)-Spark编程模型(一)
前言
本章将对Spark做一个简单的介绍,更多教程请参考:Spark教程##本章知识点概括 - Apache Spark简介 - Spark的四种运行模式 - Spark基于Standlone的运行流程 - Spark基于YARN的运行流程
Apache Spark是什么?
Spark是一个用来实现快速而通用的集群计算的平台。扩展了广泛使用的MapReduce计算模型,而且高效地支持更多的计算模式,包括交互式查询和流处理。在处理大规模数据集的时候,速度是非常重要的。Spark的一个重要特点就是能够在内存中计算,因而更快。即使在磁盘上进行的复杂计算,Spark依然比MapReduce更加高效。
Spark重要概念
(1)Spark运行模式
目前Spark的运行模式主要有以下几种:
local:主要用于开发调试Spark应用程序Standlone:利用Spark自带的资源管理与调度器运行Spark集群,采用Master/Slave结构,为解决单点故障,可以采用Xookeeper实现高可靠(High Availability, HA)Apache Mesos:运行在著名的Mesos资源管理框架基础之上,该集群运行模式将资源管理管理交给Mesos,Spark只负责运行任务调度和计算Hadoop YARN:集群运行在Yarn资源管理器上,资源管理交给YARN,Spark只负责进行任务调度和计算
Spark运行模式中Hadoop YARN的集群方式最为常用,前面一章关于Spark集群搭建就是采用的YARN模式。
(2)Spark组件(Components)
一个完整的Spark应用程序,如前面一章当中的SparkWorkdCount程序,在提交集群运行时,它涉及到如下图所示的组件:

每个Spark应用都由一个驱动器程序(drive program)来发起集群上的各种并行操作。驱动器程序包含应用的main函数,驱动器负责创建SparkContext,SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop YARN,Mesos进行通信,获取到集群进行所需的资源后,SparkContext将
得到集群中工作节点(Worker Node)上对应的Executor(不同的Spark程序有不同的Executor,他们之间是相互独立的进程,Executor为应用程序提供分布式计算以及数据存储功能),之后SparkContext将应用程序代码发送到各Executor,最后将任务(Task)分配给executors执行
- ClusterManager:在Standalone模式中即为Master节点(主节点),控制整个集群,监控Worker.在YARN中为ResourceManager
- Worker:从节点,负责控制计算节点,启动Executor或Driver。在YARN模式中为NodeManager,负责计算节点的控制。
- Driver:运行Application的main()函数并创建SparkContect。
- Executor:执行器,在worker node上执行任务的组件、用于启动线程池运行任务。每个Application拥有独立的一组Executor。
- SparkContext:整个应用的上下文,控制应用的生命周期。
- RDD:Spark的计算单元,一组RDD可形成执行的有向无环图RDD Graph。
- DAG Scheduler:根据作业(Job)构建基于Stage的DAG,并提交Stage给TaskScheduler。
- TaskScheduler:将任务(Task)分发给Executor。
- SparkEnv:线程级别的上下文,存储运行时的重要组件的引用。
SparkEnv内构建并包含如下一些重要组件的引用。
1、MapOutPutTracker:负责Shuffle元信息的存储。
2、BroadcastManager:负责广播变量的控制与元信息的存储。
3、BlockManager:负责存储管理、创建和查找快。
4、MetricsSystem:监控运行时性能指标信息。
5、SparkConf:负责存储配置信息。
Spark的整体流程
1、Client提交应用。
2、Master找到一个Worker启动Driver
3、Driver向Master或者资源管理器申请资源,之后将应用转化为RDD Graph
4、再由DAGSchedule将RDD Graph转化为Stage的有向无环图提交给TaskSchedule。
5、再由TaskSchedule提交任务给Executor执行。
6、其它组件协同工作,确保整个应用顺利执行。
图片:
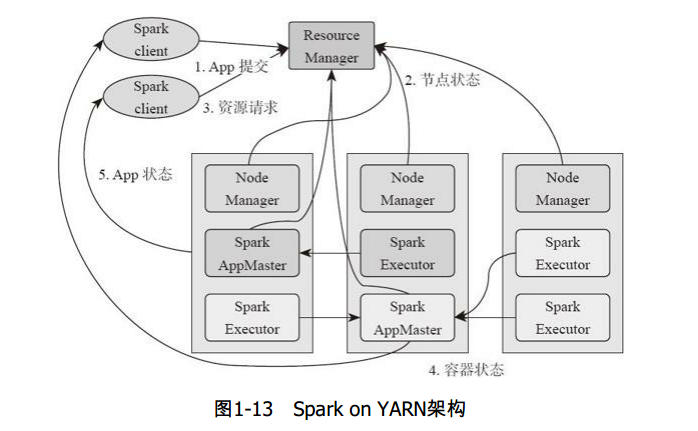
Spark on Yarn流程:
1、基于YARN的Spark作业首先由客户端生成作业信息,提交给ResourceManager。
2、ResourceManager在某一NodeManager汇报时把AppMaster分配给NodeManager。
3、NodeManager启动SparkAppMaster。
4、SparkAppMastere启动后初始化然后向ResourceManager申请资源。
5、申请到资源后,SparkAppMaster通过RPC让NodeManager启动相应的SparkExecutor。
6、SparkExecutor向SparkAppMaster汇报并完成相应的任务。
7、SparkClient会通过AppMaster获取作业运行状态。
参考文档
问题
- 针对SparkContext和Drive program还没有解释清楚
- 关于Driver向Master请求资源这一块还没搞懂
- 关于Spark的整体流程图还是不太准确,以后找到好的再补上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号