11-布隆过滤器
产生背景
如何查看一个东西是否在有大量数据的池子中?
一般做法是通过维护一个数据结构来保存池子中的数据,在池子中找被检测数据是否存在。类似黑白名单功能一样。
数据量非常大时存在的问题:
第一:大量数据的存储消耗很多系统资源
第二:检索性能不好。
线性表存储,检索时间复杂度为O(n)
平衡二叉树存储,时间复杂度为O(logn)
哈希表存储,需要用链表或二叉树解决Hash冲突问题,类似HashMap。时间复杂度为O(log(n / m)),m为哈希分桶数
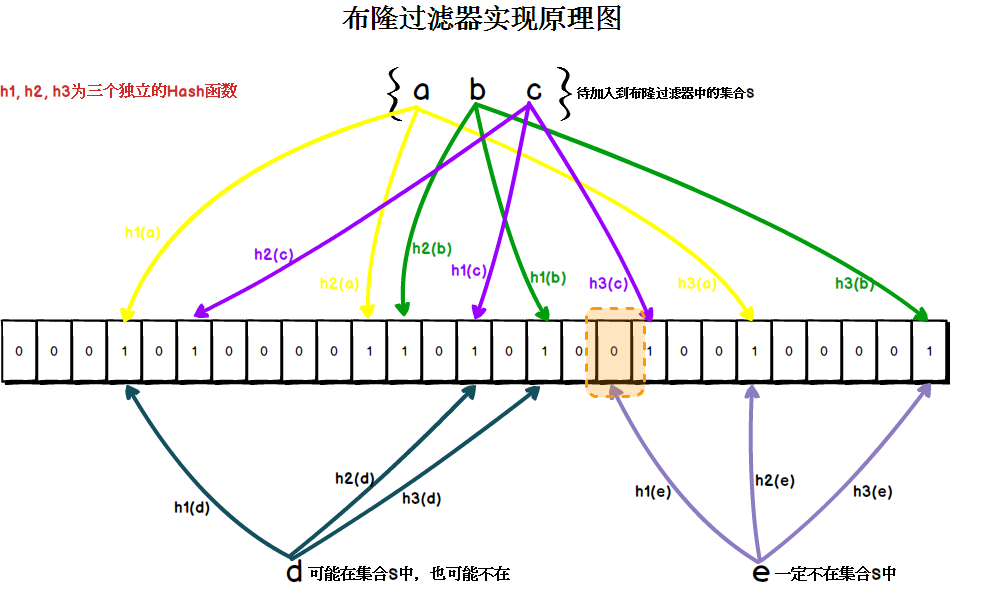
实现原理
布隆过滤器由一个比特类型的数组和一组互相独立的Hash函数构成。
插入元素过程:
被添加元素经过各Hash函数运算,计算出一组正整数的HashCode值
将比特数组中HashCode值对应位置设置为1
检索元素过程:
同样经过各Hash函数计算被检测值,生成一组正整数的HashCode值
在比特数组中查询各HashCode值对应的位置是否为1
如果各位置均为1,说明被检测值可能在集合中
如果有一个位置为0,说明被检测值肯定不在集合中
优缺点分析
布隆过滤器优点:
不需要存储数据本身,只使用比特表示。空间占用率小,并且可以对信息保密。
时间效率高,插入和查找的时间复杂度均为O(k)。k为Hash函数个数。
Hash函数之间相互独立,可以在硬件指令层面并行计算。
布隆过滤器缺点:
存在假阳性概率,不适用于任何要求100%准确率的场景。
只能插入和查询元素,不能删除元素。主要是不能判断要删除的元素是否一定在集合中。
应用场景
网络爬虫里,一个网址是否被访问过
字处理软件中,需要检查一个英语单词是否拼写正确
垃圾邮件过滤功能
Google Guava工具集中布隆过滤器的使用
Guava工具集为我们提供了一个单机版的布隆过滤器,使用方式如下:
1 import com.google.common.hash.BloomFilter; 2 import com.google.common.hash.PrimitiveSink; 3 import org.junit.Test; 4 5 /** 6 * @description: 布隆过滤器 7 */ 8 public class BloomFilterTest { 9 10 @Test 11 public void bloomFilter(){ 12 BloomFilter<Integer> bloomFilter = BloomFilter.create( 13 //将任意类型数据Java基础数据类型,默认转化为byte数组 14 (Integer from, PrimitiveSink primitiveSink) -> 15 primitiveSink.putInt(from), 16 //预计插入的元素总数 17 10000L, 18 //期望误判率(0.0~1.0) 19 0.5 20 ); 21 22 //向布隆过滤器中添加元素 23 for (int i = 0; i < 10000; i++) { 24 bloomFilter.put(i); 25 } 26 27 //检查给定元素是否 可能 存在布隆过滤器中 28 //如果不在,那元素肯定不在 29 boolean might = bloomFilter.mightContain(66666); 30 System.out.println("是否存在? " + might); 31 } 32 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号