解释器模式
begin 2023年04月15日16:49:35
引子
本科软件工程专业有这么一门课叫《编译原理》,课程内容已经忘了七七八八,但尤为清楚的是上机大作业是拷贝的,课程分数92。
定义
Given a language, define a representation for its grammar along with an interpreter that uses the representation to
interpret sentences in the language.
给定一个语言,定义其语法的表示以及一个用该表示来解释该语言中的句子的解释器。——《设计模式:可复用面向对象软件的基础》
解释器模式是一种行为型设计模式。
使用场景
Use the Interpreter pattern when there is a language to interpret, and you can represent statements in the language as
abstract syntax trees.The Interpreter pattern works best when
the grammar is simple. For complex grammars, the class hierarchy for the grammar becomes large and unmanageable.
Tools such as parser generators are a better alternative in such cases. They can interpret expressions without
building abstract syntax trees, which can saves pace and possibly time.efficiency is not a critical concern. The most efficient interpreters are usually not implemented by interpreting
parse trees directly but by first translating them into another form. For example, regular expressions are often
transformed into state machines. But even then,the translator can be implemented by the Interpreter pattern, so the
pattern is still applicable.
当有语言要解释时,请使用解释器模式,您可以将语言中的语句表示为抽象语法树。解释器模式在以下情况下效果最佳:
- 语法很简单。对于复杂语法,语法的类层次结构变得很大且难以管理。在这种情况下,解释器生成器等工具是更好的选择。
他们可以在不构建抽象语法树的情况下解释表达式,这可以节省速度和可能的时间。 - 效率不是一个关键问题。最有效的解释器通常不是通过直接解释解释树来实现的,而是首先将它们转换为另一种形式来实现的。
例如,正则表达式通常转换为状态机。但即便如此,翻译器也可以通过解释器模式实现,因此该模式仍然适用。
图示
解释器模式结构图:
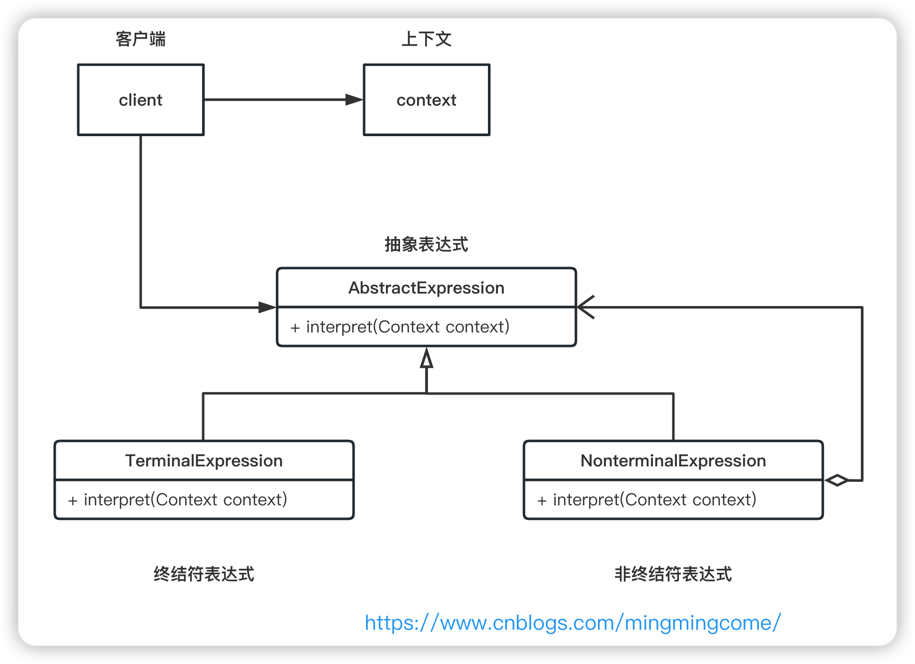
角色
抽象表达式(AbstractExpression):
- 声明抽象语法树中所有节点通用的抽象解释操作。
终结符表达式(TerminalExpression):
- 实现与文法中的终结符关联的解释操作。
- 句子中的每个终结符都需要一个实例。
非终结符表达式(NonterminalExpression):
- 对文法中每一条规则R->R1R2...Rn都需要一个具体的非终结符表达式类。
- 维护每个符号 R1 到 Rn 的抽象表达式类型的实例变量。
- 实现语法中非终结符的解释操作。解释通常在表示 R1 到 Rn 的变量上递归调用自身。
上下文(Context):
- 包含对解释器全局的信息
客户端(Client):
- 构建(或给定)一个抽象语法树,表示语法定义的语言中的特定句子。
抽象语法树由 NonterminalExpression 和 TerminalExpression 类的实例组装而成。 - 调用解释(interpreter)操作
代码示例
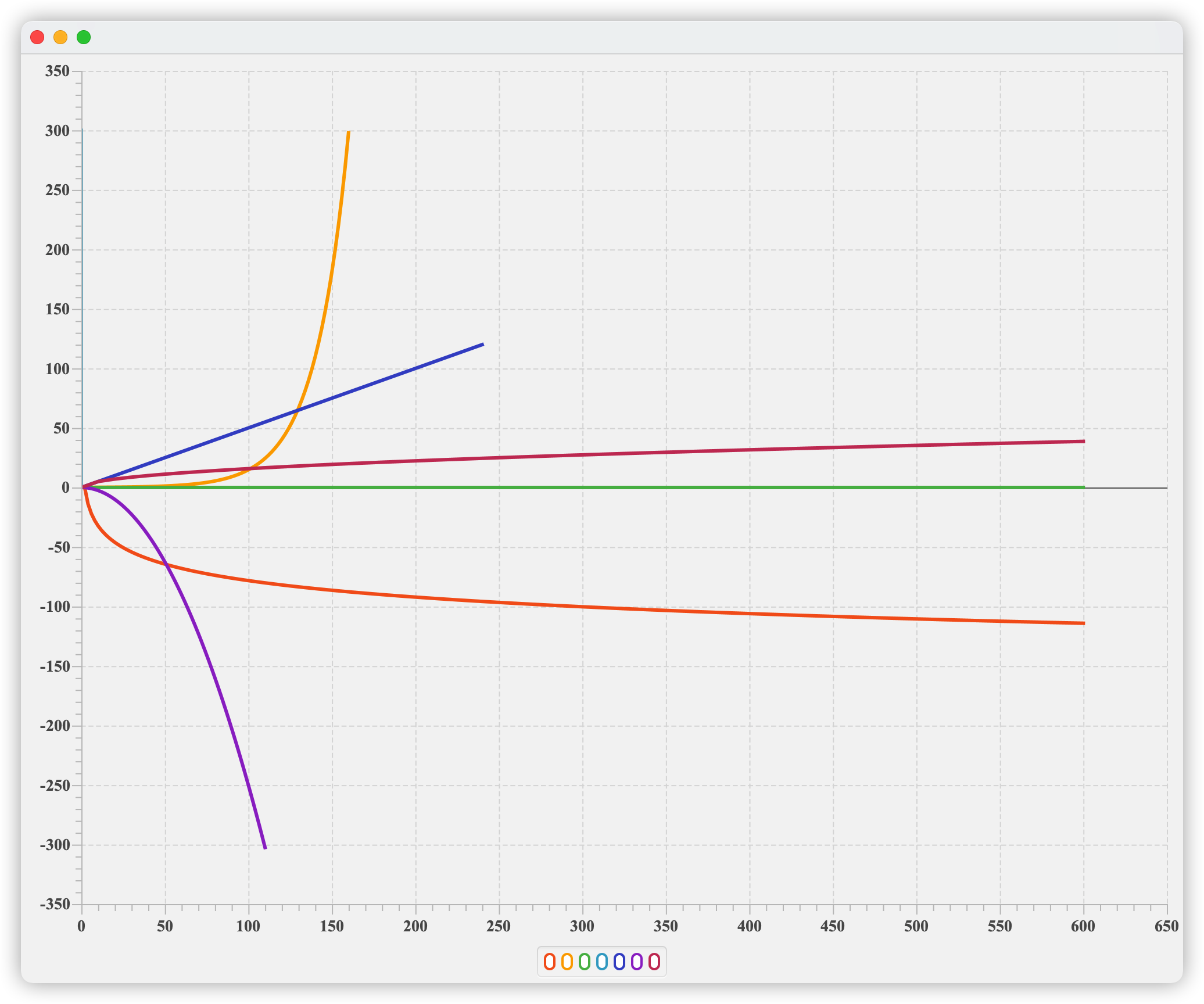
实现一个简单函数绘图语言解释器,解释下面代码:
rot is 0;
origin is (0, 0);
scale is (2,20);
for T from 1 to 300 step 1 draw (t,-ln(t));
scale is (20,0.1);
for T from 0 to 8 step 0.1 draw (t,exp(t));
scale is (2,1);
for T from 0 to 300 step 1 draw (t,0);
for T from 0 to 300 step 1 draw (0,t);
for T from 0 to 120 step 1 draw (t,t);
scale is (2,0.1);
for T from 0 to 55 step 1 draw (t,-(t*t));
scale is (10,5);
for T from 0 to 60 step 1 draw (t,sqrt(t));
- ROT语句:该语句的作用是控制逆时针角度旋转,如上述代码中的rot is 0的意思便是逆时针旋转0°的含义
- ORIGIN语句:该语句的作用是将坐标系原点平移到横坐标和纵坐标规定的点处,
如上述代码汇总的origin is (0, 0)便是规定坐标(0, 0)为原点的含义。 - SCALE语句:该语句的作用是设置横坐标和纵坐标的比例,并将其按照相关比例因子进行缩放,
如上述代码中的scale is (2, 20)的含义是将横坐标和纵坐标的比例设置为1:10并放大2倍。 - FOR-DRAW语句:该语句是绘图的核心语句,主要作用是在坐标图上描点并绘图,通过step指定步长,
如上述代码中的for T from 1 to 300 step 1 draw (t,-ln(t));便是令T从1到300变化,步长为1,绘制出一系列坐标(t, -ln(t))
当然,我们的解释器还需要具备识别注释、出错处理等基本功能,下面是我实现过程中遵循的一些小的原则:
- 语句以分号结尾,处理过程中按从上到下的顺序进行处理
- 大小写不敏感,不管是关键字还是变量名都是如此(在读入时都转换成大写)
- 默认ROT旋转的方向为逆时针旋转
编译原理相关知识
解释器模式常用于对简单语言的编译或分析实例中,为了掌握好它的结构与实现,必须先了解编译原理中的“文法、句子、语法树”等相关概念。
1、文法
文法是用于描述语言的语法结构的形式规则。如:rot is 0;origin is (0, 0);scale is (2,20);用文法表示:
<句子> -> <主语><谓语><表语>
<主语> -> <代词> | <名词>
<谓语> -> <动词>
<表语> -> <名词> | <形容词>
<名词> -> rot|origin|scale
<动词> -> is
<形容词> -> 0|(0,0)|(2,20)
注:这里的符号"->"表示“定义为”的意思,用"<"和">"括住的是非终结符,没有括住的是终结符。
2、句子
句子是语言的基本单位,是语言集中的一个元素,它由终结符构成,能由“文法”推导出。
如,上面的文法可以推导出rot is 0;origin is (0, 0);scale is (2,20);,所以这些都是句子。
3、语法树
语法树是句子结构的一种树型表示,它代表了句子的推导结果,它有利于理解句子语法结构的层次。
rot is 0;的语法树如下:
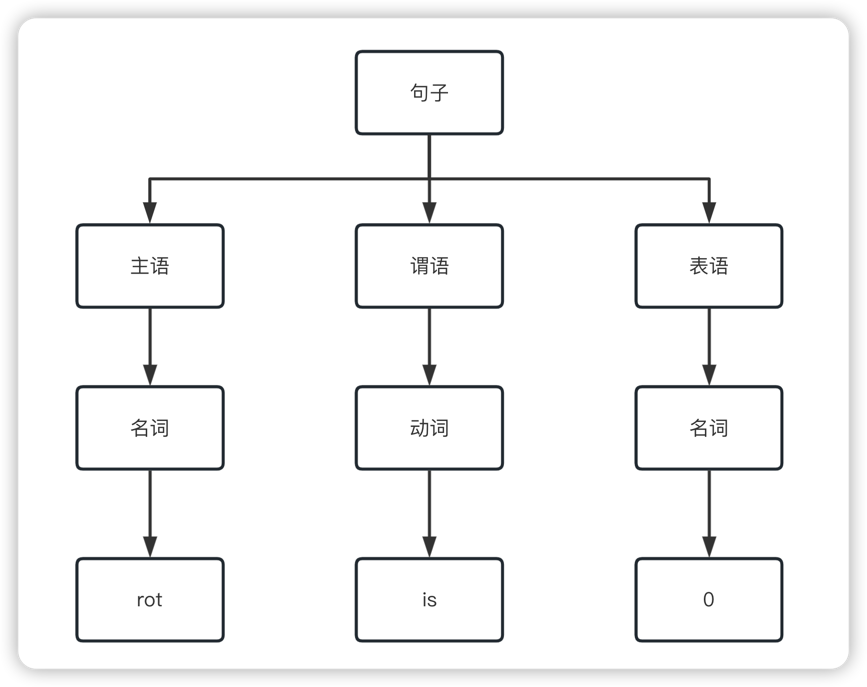
代码示例
本代码示例代码相对于本文来说过于冗长,下面带有有所省略,有兴趣请参考我的github:interpreter。
代码示例主要流程:
- 1.读取需要解释的文件
- 2.使用词法分析器,一个一个依次读取标识符,识别为一个终结符。
- 3.使用语法分析器,识别具体语句如旋转语句、比例缩放语句等非终结符的开始符号,并对语句进行语法分析
- 4.调用画图工具,画图
抽象表达式:
// 语法
public interface Grammar {
void interpret(Parser parser);
}
终结符表达式:
// 终结符类型
public enum TokenType {
ROT, IS, ORIGIN, SCALE, FOR, FROM, TO, STEP, DRAW, // 保留字
T, // 参数
SEMICOLON, COMMA, LEFT_BRACKET, RIGHT_BRACKET, // 分隔符
EOF, // 文件结束符
PLUS, MINUS, MUL, DIV, // 运算符
LN, EXP, SQRT, SIN, COS, POWER, // 函数
NUMBER // 数字
}
// 具体终结符
public class Token implements Grammar {
public static final Map<String, Token> TOKEN_MAP;
static {
Map<String, Token> tokenMap = new HashMap<>();
tokenMap.put("ROT", new Token(TokenType.ROT, "ROT"));
tokenMap.put("IS", new Token(TokenType.IS, "IS"));
tokenMap.put("ORIGIN", new Token(TokenType.ORIGIN, "ORIGIN"));
tokenMap.put("SCALE", new Token(TokenType.SCALE, "SCALE"));
tokenMap.put("FOR", new Token(TokenType.FOR, "FOR"));
tokenMap.put("FROM", new Token(TokenType.FROM, "FROM"));
tokenMap.put("TO", new Token(TokenType.TO, "TO"));
tokenMap.put("STEP", new Token(TokenType.STEP, "STEP"));
tokenMap.put("DRAW", new Token(TokenType.DRAW, "DRAW"));
tokenMap.put(";", new Token(TokenType.SEMICOLON, ";"));
tokenMap.put("(", new Token(TokenType.LEFT_BRACKET, "("));
tokenMap.put(")", new Token(TokenType.RIGHT_BRACKET, ")"));
tokenMap.put(",", new Token(TokenType.COMMA, ","));
tokenMap.put("NUMBER", new Token(TokenType.NUMBER, null));
tokenMap.put("EOF", new Token(TokenType.EOF, null));
tokenMap.put("T", new Token(TokenType.T, "T"));
tokenMap.put("+", new Token(TokenType.PLUS, "+"));
tokenMap.put("-", new Token(TokenType.MINUS, "-"));
tokenMap.put("*", new Token(TokenType.MUL, "*"));
tokenMap.put("/", new Token(TokenType.DIV, "/"));
tokenMap.put("LN", new Token(TokenType.LN, null));
tokenMap.put("EXP", new Token(TokenType.EXP, null));
tokenMap.put("SQRT", new Token(TokenType.SQRT, null));
tokenMap.put("SIN", new Token(TokenType.SIN, null));
tokenMap.put("COS", new Token(TokenType.COS, null));
tokenMap.put("^", new Token(TokenType.POWER, null));
TOKEN_MAP = tokenMap;
}
private TokenType type;
private Object value;
public Token(TokenType type, Object value) {
this.type = type;
this.value = value;
}
public TokenType getType() {
return type;
}
public Object getValue() {
return value;
}
public Token setValue(Object value) {
this.value = value;
return this;
}
@Override
public void interpret(Parser parser) {
// do nothing
}
}
非终结符表达式(部分代码省略):
// 非终结符
// 旋转语句
public class RotateStatement implements Grammar {
@Override
public void interpret(Parser parser) {
/**
* 解释ROT IS NUMBER,即旋转角度,将角度存入上下文中,供后续语句使用。
* 语法分析:先识别ROT,然后再识别IS,最后识别NUMBER。
**/
parser.matchToken(TokenType.ROT);
parser.matchToken(TokenType.IS);
parser.setRot((Double) parser.getCurrentToken().getValue());
parser.matchToken(TokenType.NUMBER);
parser.matchToken(TokenType.SEMICOLON);
}
}
上下文(部分代码已省略):
// 解释器
public class Parser {
// 语法规则
private Lexer lexer;
// 当前token
private Token currentToken;
// 输出
private String output;
// 旋转角度
private double rot;
// 原点坐标
private double originX;
private double originY;
// 缩放比例
private double scaleX;
private double scaleY;
private double from;
private double to;
private double step;
private ExprNode xNode;
private ExprNode yNode;
// 语句解释映射
private Map<TokenType, Grammar> statementMap;
public Parser(Lexer lexer) {
this.lexer = lexer;
this.output = "";
this.rot = 0;
this.originX = 0;
this.originY = 0;
this.scaleX = 1;
this.scaleY = 1;
statementMap = new HashMap<>();
statementMap.put(TokenType.ROT, new RotateStatement());
statementMap.put(TokenType.ORIGIN, new OriginStatement());
statementMap.put(TokenType.SCALE, new ScaleStatement());
statementMap.put(TokenType.FOR, new ForStatement());
}
}
//
客户端:
public class Client {
public static void main(String[] args) throws IOException {
Semantic semantic = new Semantic();
semantic.analyze();
}
}
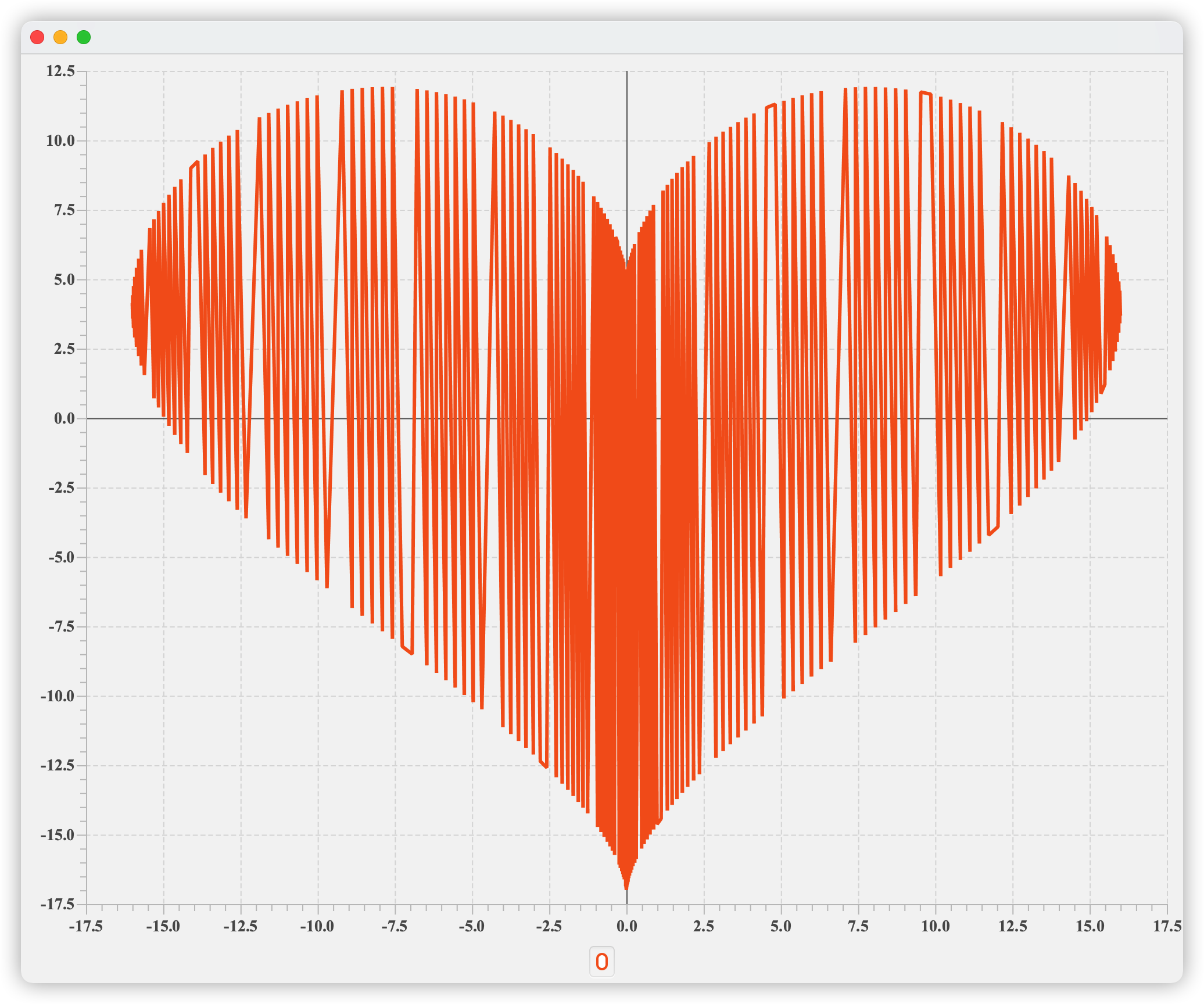
解释器执行结果:
因为写画图代码的时间正值520,所以随手查找了心形坐标函数,执行结果如下,祝天下所有有情人终成眷属。
优点
- 扩展性好。由于在解释器模式中使用类来表示语言的文法规则,因此可以通过继承等机制来改变或扩展文法。
- 容易实现。在语法树中的每个表达式节点类都是相似的,所以实现其文法较为容易。
缺点
- 执行效率较低。解释器模式中通常使用大量的循环和递归调用,当要解释的句子较复杂时,其运行速度很慢,且代码的调试过程也比较麻烦。
- 会引起类膨胀。解释器模式中的每条规则至少需要定义一个类,当包含的文法规则很多时,类的个数将急剧增加,导致系统难以管理与维护。
- 可应用的场景比较少。在软件开发中,需要定义语言文法的应用实例非常少,所以这种模式很少被使用到。
总结
当你需要解释某种语言,无论这种语句是否通用,也许只有你自己能解释,并且该语言能表示为语法树,有不会太复杂,可以使用解释器模式。
参考
完
2023年05月21日17:32:23
由于博主水平有限,如果本文有什么错漏,请不吝赐教
感谢阅读,如果您觉得本文对你有帮助的话,可以点个推荐
posted on 2023-05-21 18:09 mingmingcome 阅读(223) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号