66
1。尽管数据库的事务和查询机制较好胡满足胃各类商业公司胡业务数据管理需求,但关系数据库在大数据时代不能满足各类新增的用户需求,用户需要从不同胡数据源执行各种操作,用户需要执行高级分析,比如机器学习和图像处理,而spark sql的出现填补了这个鸿沟,spakr可以提供DataFrame API,可以对内部以及外部胡数据源执行各种关系操作,支持大量胡数据源和数据分析算法,组合使用SQL和Spark MLlib,有效的满足各种复杂的应用需求。
2。spark.read.text('people.txt'),spark.read.json('people.json'),spark.read.format('people.parquet'),spark.read.format('text').load('people.txt'),spark.read.format('json').load('people.json'),spark.read.format('parquet').load('people.parquet'')
3.使用txt文件创建的DataFrame数据没有结构,使用json文件创建的DataFrame数据有结构
4.Pandas中DataFrame是可变的,Spark中RDDs是不可变的,因此DataFrame也是不可变的;pands通过list,dict,ndarray转换,spark从已有的RDDs转换;pandas有diff操作,处理时间序列数据,spark没有diff操作;pandas行,列结构Series结构,属于Pandas DataFrame结构,spark行结构Row结构,属于Spark DataFrame,列结构结构Column结构,属于Spark DataFrame结构
Spark SQL DataFrame的基本操作
spark.read.text()

spark.read.json()

打印数据
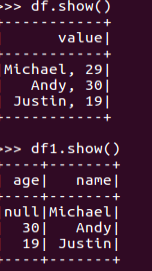
df.show()默认打印前20条数据,df.show(n)
打印概要
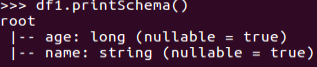
df.printSchema()

查询总行数
df.count()
df.head(3) #list类型,list中每个元素是Row类


输出全部行
df.collect() #list类型,list中每个元素是Row类

查询概况
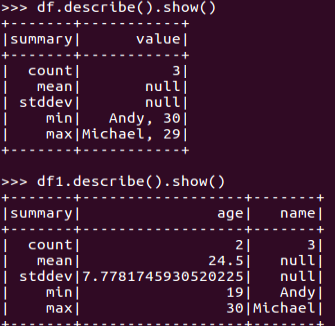
df.describe().show()
取列
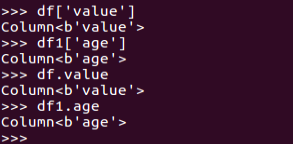
df[‘name’]
df.name
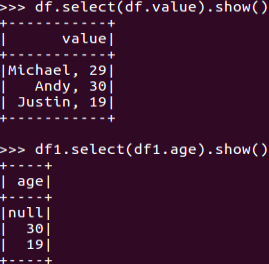
df.select()
df.filter()

df.groupBy()

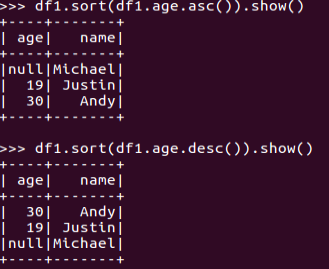
df.sort()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号